
热门标签
热门文章
- 1Gartner:2015年启动的企业级区块链项目90%会失败,它们犯了这十大常见错误
- 2Python 使用smtp发送邮件失败 在Windows Server R2012上发送失败的问题_smtplib.smtpdataerror: (550, b'the "from" header i
- 3若依分离版的文件上传_若依文件上传
- 4Java生态系统的进化:从JDK 1.0到今天_java1.0
- 5刷题——蓝桥杯 BASIC-6杨辉三角形_杨辉三角形又称pascal三角形,它的第i+1行是(a+b)i的展开式的系数。
- 6华为OD机试 - 螺旋数字矩阵
- 7人工智能系统的技术架构_人工智能技术架构
- 8虚拟机安装ubuntu22.04后的一些初始化配置_00-installer-config.yaml
- 9重庆小程序开发:自助棋牌室小程序开发的优势分析_uniapp共享棋牌室源码
- 10【网安播报】GitHub上的恶意Visual Studio 项目推送 Keyzetsu 恶意软件
当前位置: article > 正文
ViT——nlp和cv进行了统一,使多模态成为可能
作者:很楠不爱3 | 2024-04-16 10:51:14
赞
踩
ViT——nlp和cv进行了统一,使多模态成为可能
题目:AN IMAGE IS WORTH 16X16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE
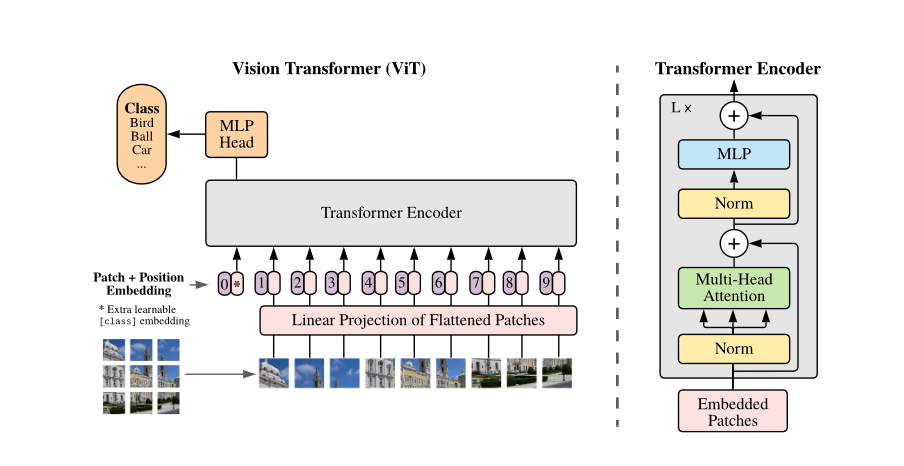 1.概述
1.概述
之前的transformer在cv中应用,大部分是将CNN模型中部分替换成transformer block(整体网络结构不变)或者用transformer将不同网络连接起来,而本文提出:一个针对图像patch的纯的transformer可以很好地完成图像分类任务,无需CNN的参与,这无疑打通了nlp和cv的壁垒。除此之外,相比于相同效果的CNN网络,VIT只需更少的计算资源。
transformer之所以只应用于部分代替,原因是:需要每个token进行两两计算关系,其复杂度是O(n^2)
,如果使用逐像素输入,则无法承担这么大的计算量,故为了降低输入序列的长度,之前的做法有:(文中提及的处理序列太长问题的方法)
- 对Feature Map进行transfomer,如 14×14的特征图也就是1×196的序列长度,可以承受。
- Stand-Alone Attention(孤注意力):使用一个local window进行输入,再进行平滑。利用这种局部多头点积自注意力块完全替代卷积。
- Sparse Transformer:采用可
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/很楠不爱3/article/detail/433736
推荐阅读


相关标签

