
- 1Qt调试问题记录(持续更新)_error: c++11
is required and is missing o - 2【9】微信小程序开发_小程序一键整理代码格式
- 3vuex的五个属性及使用方法示例
- 4PostgreSQL数据库导入、导出dmp格式的数据_dmp怎么导入pg数据库
- 5Andriod实现简易计算器功能(适配横屏数据传输)_android计算器功能实现
- 6AI 绘画工具 Stable Diffusion 本地安装使用_sd网站
- 7基于注意力机制的时间卷积神经网络TCN-Attention实现数据预测附 Matlab代码
- 8Pytorch——GPT-2 预训练模型及文本生成_pytorch gpt2预训练模型
- 9进阶数据库系列(二十):PostgreSQL 数据库备份与恢复
- 10java 判断一个日期是否在昨天17点之后_java 当前日期17点
Deep Learning中如何选择GPU?(一)_如何评估深度学习需要的显卡
赞
踩
作者:Redflashing
文中图片均来自于NVIDIA官方文档或NVIDIA社区博客
深度学习通常需要大规模的计算需求,作为主要运算硬件的GPU的选择决定了深度学习的体验。但是如何去选择新的GPU,哪些GPU特性十分重要?GPU RAM,核心(Core)数量,张量核心(Tensor Core)数量?如何做出最具性价比的选择?本文通过深入探讨这些问题,主要针对Ampere系列显卡为选购适用于深度学习GPU的小伙伴们给出最合适的建议。
总结
-
避免在矿潮期间购置价格高昂的显卡。同样,在矿难后避免买到翻新矿卡
-
尽量避免使用笔记本进行深度学习训练,同种显卡型号下台式机和笔记本会有明显差距
-
总体最好的 GPU:RTX 3080 和 RTX 3090。
-
对于个人用户而言避免使用的 GPU: 任何 Tesla 卡;任何专业绘图显卡(如Quadro 卡);任何 Founders Edition 卡;Titan RTX、Titan V、Titan XP,除此之外无Tensor Core(rtx20系显卡之前)的二手消费级显卡需要斟酌。
-
颇具成本效益而价格高昂:RTX 3080。
-
颇具成本效益而价格较便宜:RTX 3070、RTX 2060 Super。
-
预算不够的情况下: 购买二手卡,RTX 2070($400)、RTX 2060($300)、GTX 1070($220)、GTX 1070 Ti($230)、GTX 1650 Super($190)。
-
没钱: 百度的AI Studio ,Kaggle等均有免费GPU算力提供
-
Kaggle竞赛:RTX 3070
-
计算机视觉(CV)、预训练或机器翻译研究人员:4路RTX 3090(推荐涡轮显卡)。注意配备相应的大功率电源以及扇热设备
-
自然语言处理(NLP) 研究人员: 如果不从事机器翻译、语言建模或任何类型的预训练工作,那么 RTX 3080 就足够了而且颇具性价比。
-
相关专业学生/从业者: 从一块 RTX 3070 开始。进一步学习,卖掉你的 RTX 3070,并购买多路RTX 3080。根据下一步选择的领域(初创公司、Kaggle、研究、深度学习应用),卖掉你的 GPU,三年后再买更合适的(下一代 RTX 40s GPU)。
-
尝鲜小白:RTX 2060 Super 就很好,但可能需要使用新电源。如果你的主板有一个 PCIe x16 插槽,并且有一个大约 300W 的电源,那么 GTX 1050 Ti 是一个很好的选择。
-
用于模型并行化的、少于 128 个 GPU 的 GPU 集群: 如果你可以为你的集群购买 RTX GPU:66% 的 8路RTX 3080 和 33% 的 8路RTX 3090(要确保能有效地冷却)。如果解决不了 RTX 3090 的冷却问题,那么可以购买 33% 的 RTX 6000 GPU 或 8路Tesla A100。如果不能购买 RTX GPU,那么可能会选择 8路A100 Supermicro 节点或 8路RTX 6000 节点。
-
用于模型并行化的、128 个 GPU 的 GPU 集群: 考虑下 8路Tesla A100 设置。如果你使用超过 512 个 GPU,那么你应该考虑配置一个 DGX A100 SuperPOD 系统,以匹配你的规模。
1. 相比于CPU,为什么GPU更适合深度学习?为什么要选择Nvidia GPU?
对于深度学习训练来说,GPU已经成为加速器的最佳选择。大多数计算本质上是并行的浮点计算,即大量的矩阵乘法,其最佳性能需要大量的内存带宽和大小,这些需求与HPC的需求非常一致,GPU正好可以提供高精度浮点计算、大量VRAM和并行计算能力,NVIDIA的CUDA可谓恰逢其时。
CUDA和NVIDIA的计算业务的发展与机器学习的研究进展相吻合,机器学习在2006年左右才重新成为“深度学习”。GPU加速神经网络模型相比CPU可提供数量级的加速,反过来又将深度学习重新推广到如今的流行词汇。与此同时,NVIDIA的图形竞争对手ATI在2006年被AMD收购;OpenCL 1.0在2009年才发布,同年AMD剥离了他们的GlobalFoundries晶圆厂。
随着Deep Learning的研究人员和学者们成功地使用CUDA来更快地训练神经网络模型,NVIDIA才发布了他们的cuDNN库的优化深度学习原语,其中有很多以HPC为中心的BLAS(基本线性代数子例程)和相应的cuBLAS先例,cuDNN将研究人员创建和优化CUDA代码以提高DL性能的需求抽象出来。至于AMD的同类产品MIOpen,2017年才在ROCm保护伞下发布,目前依据支持并不全面。
所以从这个意义上讲,尽管NVIDIA和AMD的底层硬件都适合DL加速,但NVIDIA GPU最终成为了深度学习的参考实现。
Nvidia曾经有一个非常直观的科普视频(原视频地址:https://www.youtube.com/watch?reload=9&v=-P28LKWTzrI&feature=emb_title&ab_channel=NVIDIA),这里搬运了过来。
Demo GPU vs CPU
正如某些科普文章提到过,GPU之所以快的原因是因为高效的并行计算,对矩阵乘法和卷积具有极大的计算优势。但鲜有对其进行解释,其真正的原因是在于内存带宽,但不一定是并行计算。
首先,CPU是延迟优化的,而GPU是带宽优化的。通常我们会打这样的比方。把CPU比作一辆法拉利,而GPU则为货运卡车。两者的任务是从任意位置A取货,并将这些货物运输到另一个任意位置B。CPU(法拉利)可以在RAM中快速获取一些内存数据(货物),而GPU(货运卡车)执行速度较慢(延迟更高)。然而CPU(法拉利)需要来回多次运输完成工作
( L o c a t i o n A → p i c k u p 2 p a c k a g e s → L o c a t i o n B . . . R e p e a t Location\ A \rightarrow \ pick \ up\ 2\ packages \rightarrow Location\ B\ ...\ Repeat Location A→ pick up 2 packages→Location B ... Repeat)
然而GPU(货运卡车)则可以一次获取更多内存数据进行运输
( L o c a t i o n A → p i c k u p 100 p a c k a g e s → L o c a t i o n B . . . R e p e a t Location\ A\ \rightarrow\ pick\ up\ 100\ packages\ \rightarrow Location\ B\ ...\ Repeat Location A → pick up 100 packages →Location B ... Repeat)
换句话说,CPU更倾向于快速快速处理少量数据(例如算术运算: 5 ∗ 3 ∗ 7 5*3*7 5∗3∗7),而GPU更擅长处理大量数据(例如矩阵运算: ( A ∗ B ) ∗ C (A*B)*C (A∗B)∗C),最好的CPU内存带宽大约50GB/s,而常见的GPU(RTX2060)内存带宽为336GB/s(RTX3090的GDDR6X显存更是高达912GB/s-1006GB/s)。因此,计算操作需要的内存空间越大,GPU优势就越显著。但是,在GPU的情况下,最大的问题在于延迟对性能的影响。结合CPU的低延迟和GPU的高带宽可以有效隐藏延迟充分发挥互补优势。但对于深度学习的典型任务场景,数据一般占用大块连续的内存空间,GPU可以提供最佳的内存带宽,并且线程并行带来的延迟几乎不会造成影响。
除此之外,GPU还存在其他优势。除了第一步数据从主存(RAM)上提取到L1缓存和寄存器的性能优势。第二步虽然对性能不太重要,但依旧会增加GPU的领先优势。通常来说与执行单元(指的是CPU的核心或者GPU的流处理器)的距离越近,则访问速度越快,其中寄存器和L1缓存与CPU距离最近。**GPU的优势在于:GPU为每个处理单元(流处理器或者SM)均配备了一些寄存器,而GPU成百上千个处理单元就使得寄存器总的数量非常多(为CPU的30倍,高达14MB)且速度达到80TB/s。**相比之下,CPU的寄存器大小通常为64-128KB,运行速度为10-20TB/s。当然以上的比较在数值上会有欠缺,并且CPU寄存器和GPU寄存器并不相同。两者的大小和速度的差异是主要关键点。
最后一点GPU的优势在于:**大量且快速的寄存器和L1缓存的易于编程性,使得GPU非常适合用于深度学习。**这一点就不展开细说了,具体可以参考资料(https://www.quora.com/Why-are-GPUs-well-suited-to-deep-learning/answer/Tim-Dettmers-1)
2.用于深度学习处理深度重要的GPU参数
2.1. 张量核心(Tensor Core)
下图(来源:Nvidia)为帕斯卡架构和第二代Tensor Core(图灵架构)进行比较

首先总结出以下结论:
- Tensor Core将计算乘法和加法操作所需的计算周期减少到 1 16 \frac{1}{16} 161。正如对于 32 ∗ 32 32*32 32∗32矩阵,从128个周期缩短到8个周期。
- Tensor Core减少了对重复共享内存访问的依赖,从而节省了额外的内存访问。
- Tensor Core的高速使得计算不再是性能瓶颈。唯一的瓶颈是将数据载入到Tensor Cores。
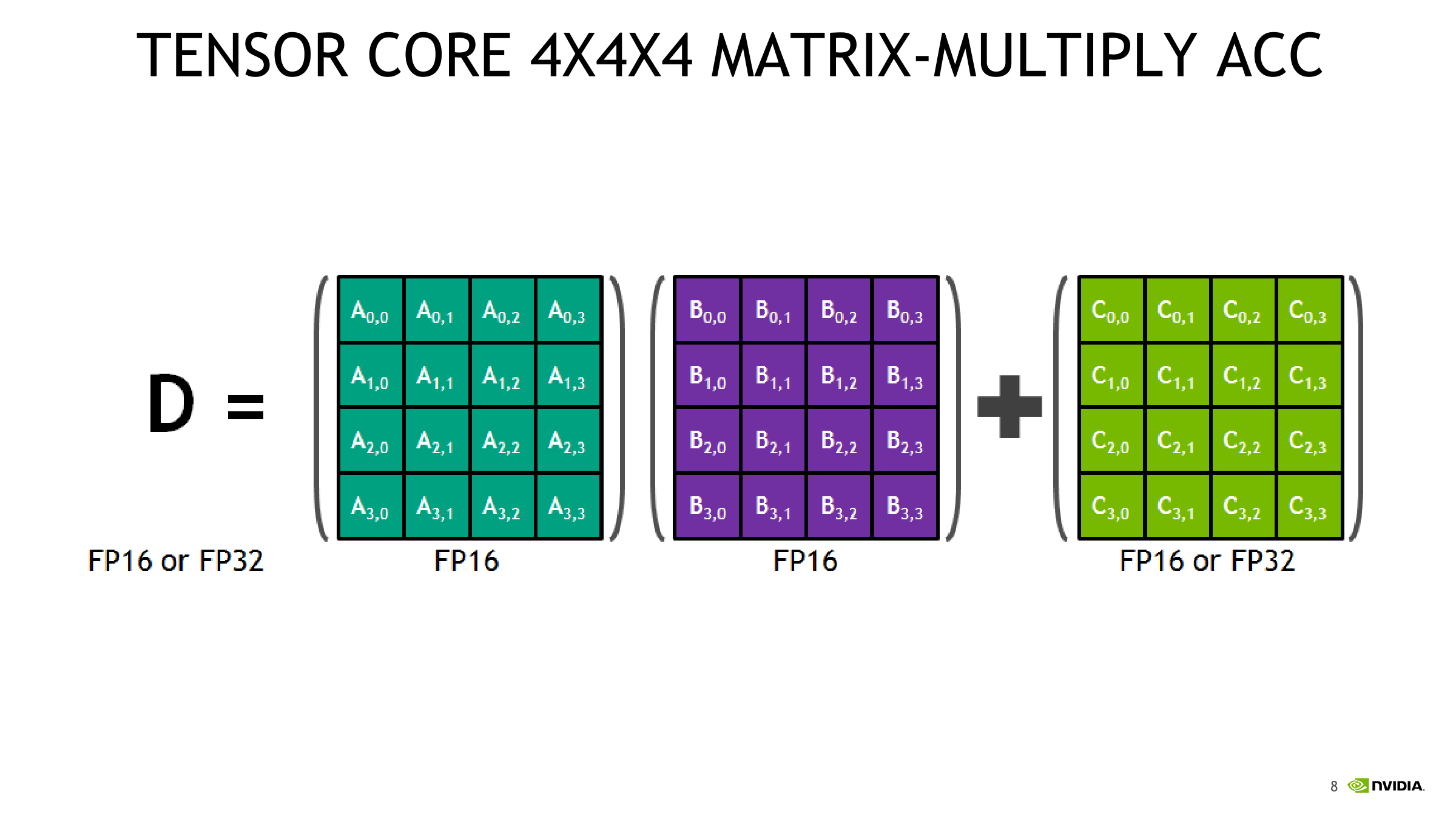
了解Tensor Core是如何执行计算任务是非常有帮助的。在这里我们举一个简单的例子–计算 A ∗ B + C A*B+C A∗B+C的矩阵乘法示例(其中矩阵均为 32 ∗ 32 32*32 32∗32)。我们讨论矩阵乘法在是否有Tensor Core的两种情境下是什么样子的。当然这是个简单的例子,并不是高性能矩阵乘法的真正执行情况,但它可以形象展示所有的知识。通常来说编写CUDA程序的软件工程师会以此为基础,加上诸如双缓冲/寄存器优化/占用优化/指令层面并行性等方法进行进一步的优化,这里就不再做过多叙述。
要想展示例子前,我们必须了解计算机中周期的概念。如果一个处理器运行在1GHz的频率下,则该处理器每秒进行 1 0 9 10^9 109个周期,每个周期代表一次运算机会。通常来说,一个操作所需的执行时间都超过一个周期。因此,将创建一个管线(Pipeline),其中一个操作启动所需要等待前一个操作完成所需的周期数称为操作的延迟。
以下是一些重要的操作周期数(以GA100显卡为例):
- 全局内存访问(高达48GB):约200个周期
- 共享内存访问(每个SM最多164KB):约20个周期
- Fused multiplication and addition (FFMA):4个周期
- Tensor Core矩阵乘法:1个周期
此外,GPU上最小线程单元是32个线程的组合-被称为Warp。Warp通常以同步模式运行-Warp中的线程必须相互等待。GPU上所有的内存操作都针对Warp进行了优化。例如,从全局内存加载的粒度为 32 ∗ 4 32*4 32∗4字节,正好32个单精度浮点,正好是Warp中每个线程分得一个浮点。在SM中最多有32个Warp=1024个线程,SM的资源在活动的Warp中分配。这意味着有时候我们会希望去运行较少的Warp以便每个Warp获得更多寄存器/共享内存/Tensor Core资源。
对于下面的两个示例,假定在相同的计算资源的情况下,对于 32 ∗ 32 32*32 32∗32矩阵乘法的例子,我们使用了8个SM(大约为RTX 3090的10%)每个SM调用8个Warp。
2.1.1.不使用Tensor Core的矩阵乘法
对于 A ∗ B = C A*B=C A∗B=C(其中矩阵均为 32 ∗ 32 32*32 32∗32)的矩阵乘法,那么我们会将重复访问的数据加载到共享内存中,因为在它的延迟低了10倍左右(200个周期与20个周期的差距)。加载2个 32 ∗ 32 32*32 32∗32的单精度浮点到共享内存块能用 2 ∗ 32 2*32 2∗32个Warp进行并行工作。共调用8个SM,每个SM8个Warp,因为是并行工作,我们只需要将这些数据单个顺序加载到共享内存中,消耗200个周期。
然后我们进行矩阵乘法,我们需要从共享内存A和共享内存B加载含32个向量,并执行FFMA(Fused multiply-and-accumulate)运算。最后将输出存储在寄存器C中。我们将工作划分每个SM执行 8x 点乘( 32 ∗ 32 32*32 32∗32)以计算C的8个输出。为什么正好是8(在旧算法中为4)是非常技术性的。这里有关于通用矩阵乘法(GEMM,General Matrix Multiplication)的博客文章加深理解(https://github.com/NervanaSystems/maxas/wiki/SGEMM)。这意味着8次的共享内存访问空间(每次访问耗时20个周期)并执行8次FFMA操作(访问耗时4个周期)。总的来说一共所需的周期数为:
200 c y c l e s ( 全 局 内 存 ) + 8 ∗ 20 c y c l e s ( 共 享 内 存 ) + 8 ∗ 4 c y c l e s ( F F M A ) = 392 c y c l e s 200cycles(全局内存)+8*20cycles(共享内存)+8*4cycles(FFMA)= 392cycles 200cycles(全局内存)+8∗20cycles(共享内存)+8∗4cycles(FFMA)=392cycles
2.1.2.使用Tensor Core的矩阵乘法
使用Tensor Core,我们可以在一共周期内执行 4 ∗ 4 4*4 4∗4矩阵乘法。为此,我们首先需要把数据载入Tensor Core。与上述类似,我们需要从全局内存(200个周期)读取数据并存储在共享内存中。要执行 32 ∗ 32 32*32 32∗32矩阵乘法,我们需要执行 8 ∗ 8 = 64 8*8=64 8∗8=64次Tensor Core操作。单个SM具有8个Tensor Core,使用8个SM,我们有64个Tensor Core恰好是我们所需的Tensor Core数量。我们可以通过一次内存传输(20个周期)将数据从共享内存传输到张量核,然后进行64次并行Tensor Core操作(1个周期)。这意味着,在这种情况下,Tensor Core矩阵乘法的总开销为:
200 c y c l e s ( 全 局 内 存 ) + 20 c y c l e s ( 共 享 内 存 ) + 1 c y c l e s ( T e n s o r C o r e ) = 221 c y c l e s 200cycles(全局内存)+20cycles(共享内存)+1cycles(Tensor \ Core)= 221cycles 200cycles(全局内存)+20cycles(共享内存)+1cycles(Tensor Core)=221cycles
因此,我们通过张量核将矩阵乘法的开销从 392 个 cycle 大幅降低到 221 个 cycle。在这种情况下,张量核降低了共享内存访问和 FFMA 操作的成本。
在这个例子中,有和没有张量核都大致遵循相同的计算步骤,请注意,这是一个非常简化的例子。在实际情况下,矩阵乘法涉及到更大的共享内存块,计算模式也稍微不同。不过我相信,通过这个例子,我就很清楚为什么内存带宽对于配备张量核的 GPU 来说如此重要。在使用张量核进行矩阵乘法时,全局内存是 cycle 开销中最重要的部分,如果可以降低全局内存延迟,我们甚至可以拥有速度更快的 GPU。要做到这一点,我们可以通过增加内存的时钟频率(增加每秒 cycle 数,但也会增加发热和电量消耗)或增加每次可以转移的元素数量(总线宽度)。
2.2. 内存带宽
Tensor Core的速度如此之快,以至于在实际的执行过程中Tensor Core在大多数时间都是闲置状态。例如在BERT的大规模训练期间,Tensor Core使用率大约在30%,这意味着70%的时间Tensor Core处于闲置。
这意味着,将两个GPU的Tensor Core进行比较时,每个GPU性能的最佳指标之一是它们的内存带宽。例如,A100 GPU的内存带宽为1555GB/s,而V100的内存带宽为900GB/s。因此可以粗略地计算A100于V100的加速比为 1555 / 900 = 1.73 1555/900=1.73 1555/900=1.73倍。
2.3. 共享内存/L1缓存/寄存器
由于向Tensor Core的数据传输是性能的限制因素。而共享内存/L1缓存/寄存器数量与内存传输密切相关。若要了解内存层次结构如何实现更快的内存传输,它有助于了解矩阵乘法如何在GPU上执行。
要了解GPU的内存层次结构,我们先来聊聊A100的SM架构(SM,相当于 GPU 上的一个“CPU 内核”)。下图为Nvidia GPU GA100及其SM结构(来源:Nvidia)。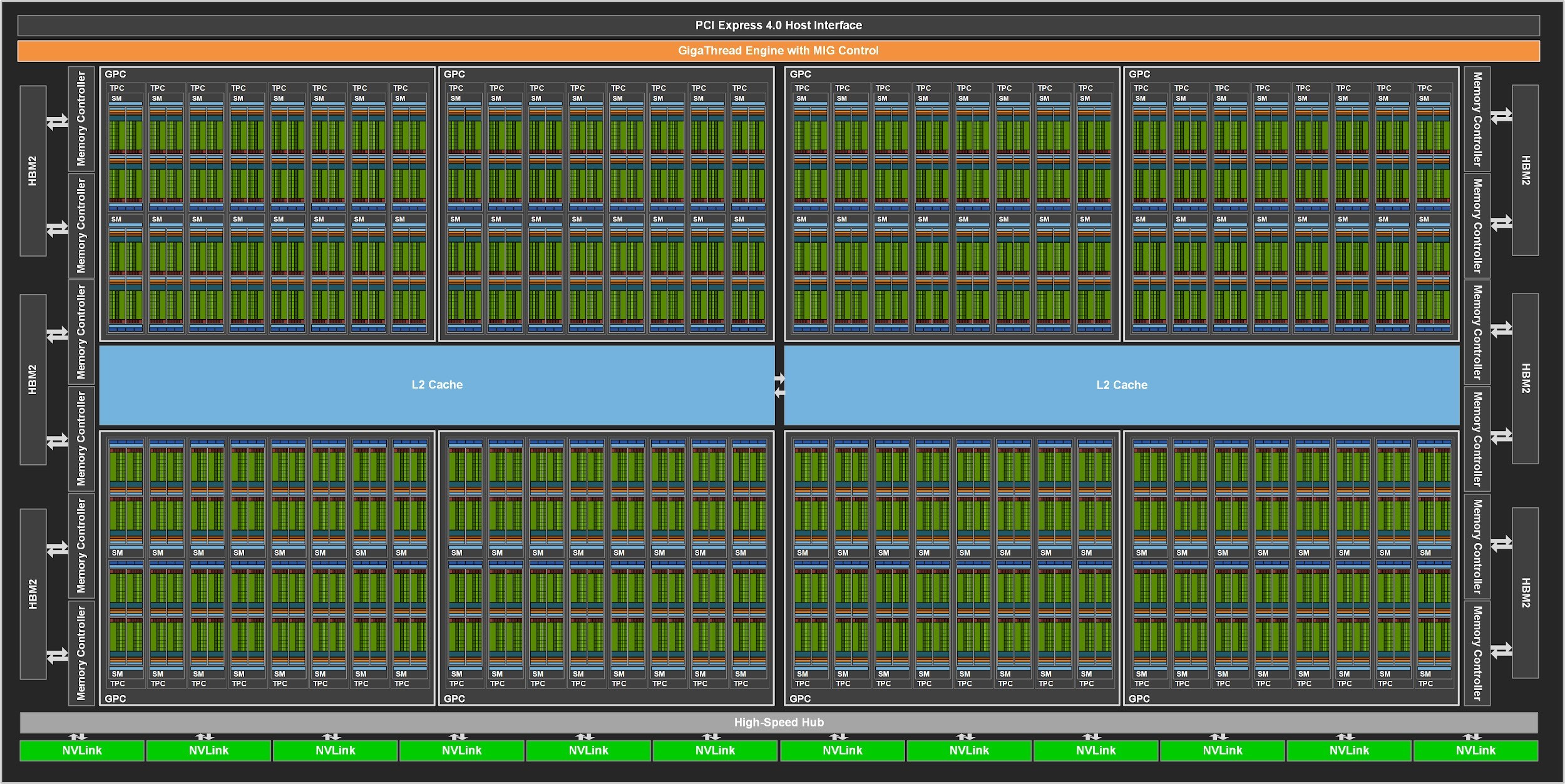
 新的GA100 SM显著提高了性能,除了Volta和Turing架构引入的功能之外还增加了许多新功能和增强功能。相比于Volta和Turing每SM有8个Tensor Core(每个Tensor Core每个时钟周期执行64个FP16/FP32 FMA操作,
64
∗
8
=
512
64*8=512
64∗8=512),而GA100 每个SM包括4个第三代的Tensor Core(每个Tensor Core每个时钟周期执行256个FP16/FP32 FMA操作,
256
∗
4
=
1024
256*4=1024
256∗4=1024),与Volta和Turing相比SM的算力增加2倍。共享内存大小:
新的GA100 SM显著提高了性能,除了Volta和Turing架构引入的功能之外还增加了许多新功能和增强功能。相比于Volta和Turing每SM有8个Tensor Core(每个Tensor Core每个时钟周期执行64个FP16/FP32 FMA操作,
64
∗
8
=
512
64*8=512
64∗8=512),而GA100 每个SM包括4个第三代的Tensor Core(每个Tensor Core每个时钟周期执行256个FP16/FP32 FMA操作,
256
∗
4
=
1024
256*4=1024
256∗4=1024),与Volta和Turing相比SM的算力增加2倍。共享内存大小:
- Volta:96kb 共享内存/32kb L1缓存
- Turing:64kb 共享内存/32kb L1缓存
- Ampere(A100):192kb 共享内存/L1缓存
GPU的内存层次结构,从相对缓慢的全局内存到快速共享内存,再到闪电般的寄存器。但由于成本因素的制约,内存越快,其容量越小。因此我们需要将大矩阵分成较小的矩阵。在共享内存中的切片执行矩阵乘法,该操作十分快速。进一步将这些切片的一部分加载到Tensor Core中。由上文可知SM共享内存的矩阵Memory Tile比GPU全局内存快大约10-50倍,而Tensor Core的寄存器比GPU全局内存快200倍。拥有更大的Tile意味着可以复用更多的内存。实际上,你可以将 TPU 看作是每个张量核都有非常非常大的 Tile。因此,TPU 在每次从全局内存传输数据时都可以重用更多的内存,这使得它们在矩阵乘法计算方面比 GPU 更有效率。每个块的大小是由每个SM的内存大小决定的。
由上可得,Ampere架构的共享内存更大,块大小也就更大,这就减少了全局内存访问延迟。因此,Ampere可以更好地利用GPU存储的总体内存带宽。这将提高约2~5%的性能。对于大型矩阵矩阵,性能的提升尤其明显。
Ampere架构的Tensor Core的另一个优点在于线程间共享更多数据。这减少了寄存器的使用。通常来说,GPU寄存器被限制为每个SM为64K或者每个线程 255 。比较Volta和Ampere架构的Tensor Core,在相同情况下Ampere架构仅需1/3的寄存器,这允许共享内存的每个Tile有更多Tensor Core活动。然而性能的瓶颈还是在于带宽,所以以实际的TFLOPS(每秒所执行的浮点运算万亿次数)和理论TFLOPS相比,只会有微小的提高。Ampere架构的Tensor Core提高了大约1~3%的性能。
总的来说,我们可以看到,Ampere 的架构经过优化,它使用改进后的存储层次结构(从全局内存到共享内存块,再到张量核寄存器),使可用内存带宽更加有效。
3. Ampere架构的深度学习性能
要点:
- 根据内存带宽和Ampere GPU改进的存储结构来估计,理论上,其提升1.78倍到1.87倍。
- NVIDIA提供了Tesla A100和V100 GPU的准确测试数据。虽然数据存在营销目的,但可以通过这些数据建立去偏差模型。
- 去偏基准测试的数据显示,Tesla A100在NLP方面比V100快1.70倍,在CV方面比V100快1.45倍。
如果你想了解更多关于A100的技术细节,可以参考NVIDIA官方文档(https://www.nvidia.com/content/dam/en-zz/Solutions/Data-Center/nvidia-ampere-architecture-whitepaper.pdf)
3.1. Ampere速度的理论估计
综上所述,我们可以得到结论,两种配备Tensor Core的GPU架构之间的差异主要在于内存带宽。除此之外,使用Tensor Core的还能拥有更多共享内存/L1缓存以及更好的寄存器。
如果我们将Tesla A100GPU带宽与Tesla V100 GPU带宽相比较,我们得到的提升为1555/900=1.73倍。此外,从更大的共享内存中得到 2-5% 的加速,从第三代的Tensor Core得到1-3%的加速。这使得速度提升在1.78和1.87倍之间。用类似的推理方法,我们就可以估计Ampere架构GPU同其他GPU(尤其是Tesla V100)的速度提升。
3.2. Ampere速度的实际估计
NVIDIA已经在A100和V100进行了基准测试。但NVIDIA使用了不同的Batch Size和GPU数量,使得这些数据无法直接进行比较(NVIDIA的基准测试有意使得结果有利于A100)。所以在某种意义上,这些基准数据是真实的。通常来说,我们可能会认为更大的Batch Size才公平,因为A100有更多的内存,但为了比较GPU架构,我们应该评估Batch Size相同时的无偏差内存性能。
为了得到无偏估计,我们可以通过两种方式对V100和A100结果进行缩放:
-
(1).考虑Batch Size差异
-
(2).考虑使用1个GPU和8个GPU的差异。
这我们能在NVIDIA提供的数据中找到对这两种偏差的估计。
Batch Size增加一倍使得吞吐量增加13.6%(CNN,以每秒图像数为单位)。在RTX Titan上针对同样的问题测试了Transformer,得到可靠的估计值13.5%,在结果上出奇地一致。
当我们将 Network 放在更多 GPU 并行化时,由于网络的开销,我们会损失性能。与 V100 8路并行系统(通过 NVLink 2.0 )相比,A100 8路并行系统有更好的GPU互连技术(通过 NVLink 3.0)–这使得无法进行控制变量来进行直接比较。通过直接查看 NVIDIA 的数据,我们可以发现,对于 CNN 任务而言,8路 A100 系统比 8路 V100 系统开销低5%。这意味着,从 1x A100 到 8x A100可以获得7倍的速度提升,而从 1x V100 到 8x A100可以获得 6.67 倍。对于 Transformer 任务而言,这个数值是 7%。
使用这些数据,我们可以从 NVIDIA 提供的直接数据中估算其对于一些特定深度学习架构的速度提升。与 Tesla V100 相比,Tesla A100 可以提供以下速度提升:
- SE-ResNeXt-101:1.43 倍
- Masked-R-CNN:1.47 倍
- Transformer(12 层,机器翻译模型 WMT4 en-de):1.70 倍
因此,对于计算机视觉来说,这些数值比理论估计要低一些。这可能是由于张量维数较小,准备矩阵乘法(如 img2col 或快速傅里叶计算(FFT))所需的操作开销,或者操作无法充分利用 GPU(最后的层通常相对较小)。它也可以是特定架构的工件(分组卷积)。
Transformer 实际估计值与理论估计值非常接近。这可能是因为大型矩阵的算法非常简单。将使用这些实际的估计来计算 GPU 的成本效率。
3.3. 估计中可能存在的偏差
上面是针对 A100 和 V100 的对比估计。过去,NVIDIA消费级显卡出现了性能偷偷下降的问题:
- 降低 Tensor Core 的利用率
- 风扇散热
- 阉割 NVLink(如30系显卡,仅有 RTX 3090 保留了 NVLink)
与 Ampere A100 相比,RTX 30系列显卡可能有未公布性能下降的嫌疑。
4. Ampere / RTX 30 系列的其他考虑因素
要点:
- Ampere 可以用于稀疏网络训练,它最高可以将训练速度提高 2 倍。
- 稀疏网络训练仍然很少使用,但将使 Ampere 可以经受住未来的考验。
- Ampere 有新的低精度数据类型,这使得使用低精度数值更容易,但不一定比以前的 GPU 更快。
- 新的风扇设计非常棒,如果你的 GPU 之间有间隙的话,但不清楚如果多个 GPU 之间没有间隙,它们是否能有效冷却。
- RTX3090 的 3 插槽设计使得 4x GPU 构建成为问题。可能的解决方案是 2 插槽转换或使用 PCIe 扩展器。
- 4x RTX 3090 需要的功率已经超过目前市场上任何标准电源单元所能提供的功率。
与 NVIDIA Turing RTX 20 系列相比,新的 NVIDIA Ampere RTX30 系列具有额外的优点,如稀疏网络训练和推理。其他特性,比如新的数据类型,更多的是易用性特性,因为它们提供了和 Turing 一样的性能提升,但是不需要任何额外的编程。
4.1. 稀疏网络训练
神经网络由于其参数规模的不断增加,以期待用相似的网络架构去捕捉不同的特征,因此,也造成了模型的稀疏性。研究人员们一直在研究利用深度学习的稀疏性,例如常见的剪枝(pruning),本质上就是对稀疏模型的一个压缩。
我们可以想象一下,从生物学角度看,人脑里面的神经元也不是稠密连接的。而神经网络中的稀疏性主要是由于模型训练中会产生很多非常小的参数值(weight),而像ReLU这样的激活函数,也会使得输入输出(activations)中很多值为零。因此,weight 和 activation 都会有大量零值(或接近0)存在,这是模型稀疏化的根源。
大家可能会问,有稀疏性,我们就不保存 0 值或者不保存 0 值。这个里面需要解决的问题主要是两点,我们需要保证模型的精度,另外需要保证考虑稀疏化后能在硬件上获得加速。各类硬件都有其偏好的数据格式和排布,并不是暴力减少计算量就一定有收益的。因此,结构化的稀疏是一个很好的选择。
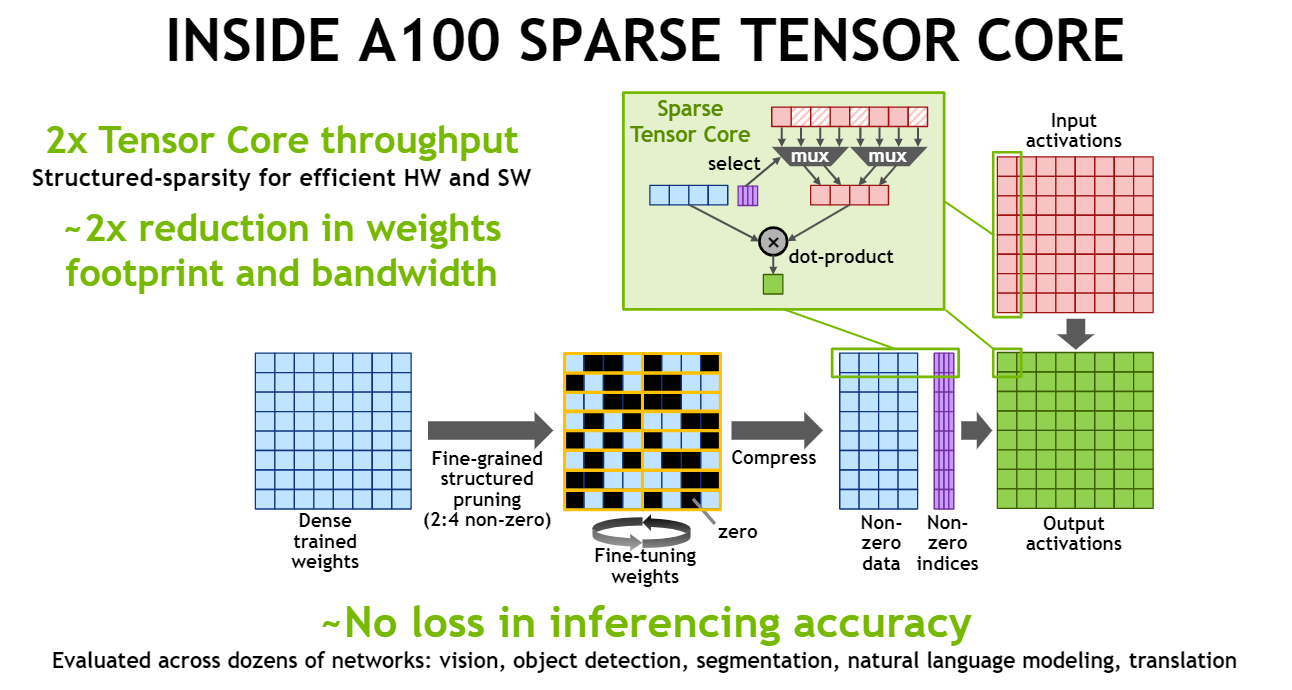
在A100的Tensor Core上支持 2 : 4 2:4 2:4的稀疏计算,也就是 M ∗ N ∗ K M*N*K M∗N∗K 的K维度上每连续四个元素,保持其中两个元素为零值。计算的时候,可以将4个元素表达为2个元素,加上一个 2bit 的标识符(标示非零元素的位置)。而Tensor Core支持通过这2个元素和2bit的标识符来计算最终的结果。
我们还是以Tensor Core上的FP16进行计算为例,Tensor Core可以在2个时钟周期内完成 16 ∗ 32 16*32 16∗32与 32 ∗ 8 32*8 32∗8 的矩阵乘法,使用sparsity之后,只需要1个时钟周期,理论加速达到两倍。(下图为 16 ∗ 32 16*32 16∗32与 32 ∗ 8 32*8 32∗8 稀疏计算示意图)

Ampere 架构可以以稠密矩阵的速度进行细粒度结构自动稀疏矩阵乘法(ASP,Automatic SParsity)。简要地说它的工作原理是:将矩阵分割成4个部分,现在稀疏矩阵Tensor Core特性允许这4个矩阵中的2个为零矩阵。这样就带来了2倍数的速度提升(瓶颈在于数据带宽),因为矩阵乘法的带宽需求减半了。
对于稀疏网络的训练,通常存在一种批评“虽然减少了网络所需的FLOPS,但却没能带来速度的提升,因为 GPU 并不能做快速稀疏矩阵乘法。”所以 Ampere 架构的主动稀疏矩阵乘法特征(还处于实验阶段,且稀疏矩阵的训练并不普遍)可以对稀疏矩阵训练算法提供2倍的速度提升。
4.2. 低精度计算
新的数据类型可以提高低精度反向传播的稳定性。目前,如果你想要实现 16 位浮点数(FP16)的稳定反向传播,主要问题是普遍 FP16 数据类型只支持 [ − 65504 , 65504 ] [-65504,65504] [−65504,65504]区间内的数值。如果梯度超出这个范围,就会变成NaN类型。为了防止 FP16 训练期间发生这种情况,我们通常会进行损失缩放,即在反向传播之前将损失乘以一个小数值,以防止梯度爆炸。
Brain Float 16 格式(BF16)使用更多的位作为指数,这样,其可能的数值范围与 FP32 相同: [ − 3 ∗ 1 0 38 , 3 ∗ 1 0 38 ] [-3*10^{38},3*10^{38}] [−3∗1038,3∗1038]。BF16 的精度较低,但梯度精度对机器学习来说并不是那么重要。所以 BF16 所做的就是你不再需要做任何损失缩放或者担心梯度迅速膨胀。因此,我们可以看到使用 BF16 格式时训练稳定性的提高,只是精度稍有降低。
这意味着:使用 BF16 精度,训练可能比 FP16 精度更稳定,而提供了同等的速度提升。使用 TF32 精度,可以得到接近 FP32 的稳定性,接近 FP16 的速度提升。好的方面是,要使用这些数据类型,只需将 FP32 替换为 TF32,将 FP16 替换为 BF16——而不需要修改代码。再总结一下就是针对深度学习数据类型对精度和范围的需求进行重新设计,适当降低了精度,提高了数值范围。
这里再介绍一下 TF32(TensorFloat-32) 数据类型,,相比FP32,指数位(涉及浮点数表示范围,Range)保留了和FP32相同的bit,而尾数位(涉及浮点数的精度,Precision)保留了和FP16相同的bit。它同时兼顾了范围(Range)和精度(Precision)的要求。在使用上,使用FP32作为输入输出,也使得TF32的加速和现有程序接口保持一致。在各个深度学习框架里面,TF32都是开箱即用,直接替代FP32,带来相比V100 最高10倍的性能提升。NVIDIA也针对常见的深度学习模型,进行了验证,在CV,NLP,推荐系统等各类AI应用中,TF32都表现出了与FP32相同的收敛精度。

不过,总的来说,这些新数据类型可以被视为懒惰数据类型,因为通过一些额外的编程工作(适当的损失缩放、初始化、归一化、使用 Apex),使用旧数据类型就可以获得所有这些好处。因此,这些数据类型并不提供速度提升,而是提高了低精度训练的易用性。
参考文档
- Which GPU(s) to Get for Deep Learning: My Experience and Advice for Using GPUs in Deep Learning
- Why are GPUs well-suited to deep learning?
- What is a GPU and do you need one in Deep Learning?
- NVIDIA A100 Tensor Core GPU Architecture whitepaper
- Nvidia Ampere GA102 GPU Architecture whitepaper
- s21929 Tensor Core performance on nvidia gpus the ultimate guide
- https://github.com/NervanaSystems/maxas/wiki/SGEMM
- Nvidia’s Tensor Cores for Machine Learning and AI – Explained
- NVIDIA深度学习Tensor Core全面解析(上篇)
- NVIDIA深度学习Tensor Core全面解析(下篇)
- https://www.zhihu.com/question/394863138/answer/1275510947

