
- 1算法面经小米篇_大模型面经
- 2C# OpenCvSharp 读取rtsp流_c# rtsp
- 3iOS常用下拉刷新上拉加载库MJRefresh使用说明_triggerautomaticallyrefreshpercent
- 4机器学习_论文笔记_1: A few useful things to know about machine learning
- 5[OpenHarmony RK3568](四)WIFI芯片适配_sdio_pwrseq
- 6nginx使用教程,在k8s上的安装部署,代理内网mysql/docker
- 7Harmony OS应用开发的HiLog日志打印
- 8Mac华为鸿蒙配置开发环境之设置npm代理_鸿蒙开发配置代理怎么开
- 9排序算法——归并排序的相关问题_归并算法一组个数远小于另一组
- 10vSphere 6.X 的证书导致的vcenter无法登录问题_vc身份验证过程出错怎么办
Stable Diffusion学习指南【图生图篇】_stable diffusion值得学吗
赞
踩
即使之前在Midjourney中有过图生图的使用经验,但大部分人对该功能的印象仅限于喂图,通过它可以让模型了解更多我们要传达的信息,从而达到准确出图的目的。但在Stable Diffusion中的图生图还要强大的多,除了控图还包含了手动涂鸦、局部重绘、图像扩展等更多功能。
今天的文章里我会为你详细介绍图生图的工作原理、工具解析和图像重绘的应用方向,如果没有看过【文生图篇】的朋友建议先去学习下,以便你更好的理解今天的内容。
Stable Diffusion学习指南系列文章:
图生图功能初识
1.1 传统意义上的喂参考图
我们都知道,模型在运算时是根据我们提供的提示内容来确定绘图方向,如果没有提示信息,模型只能根据此前的学习经验来自行发挥。在之前的文生图篇,我们介绍了如何通过提示词来控制图像内容,但想要实现准确的出图效果,只靠简短的提示词是很难满足实际需求的。
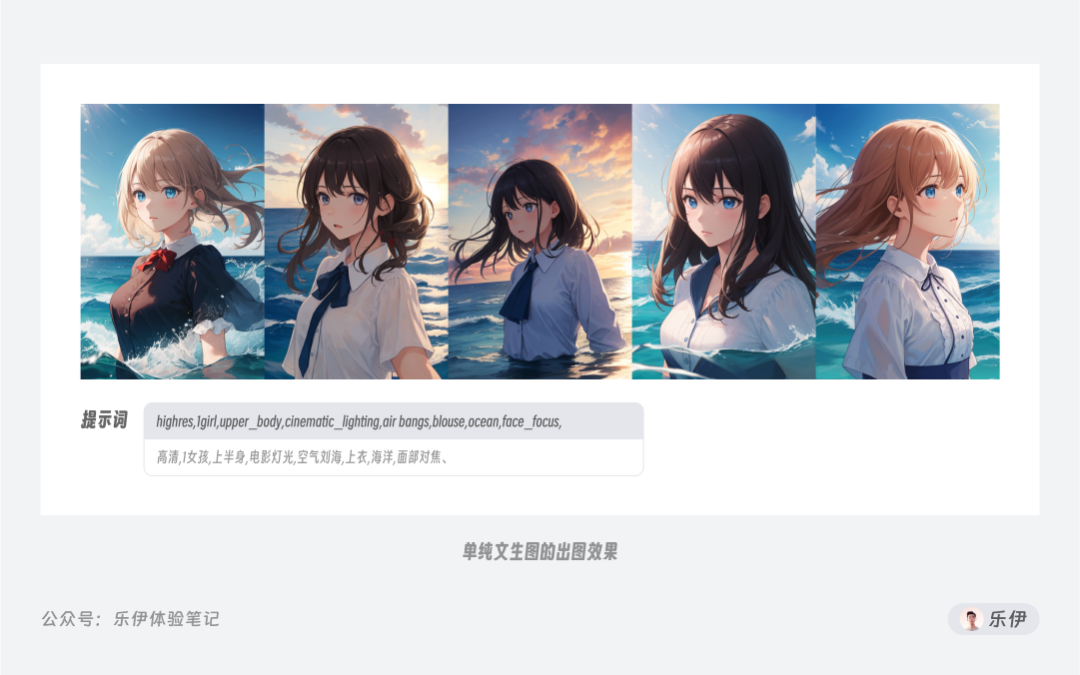
AI绘画的随机性导致我们使用大段的提示词来精确描述我们想要的画面内容,但毕竟文字能承载的信息量有限,即使我们写了一大段咒语,模型也未必能准确理解,不排除有时候还会出现前后语义冲突的情况。其实这个过程就像甲方给我们明确设计方向,除了重复沟通想要的画面内容外,有没有什么比口述更高效的沟通方式呢?这个时候,有经验的甲方会先去找几张目标风格的竞品图,让我们直接按照参考图的感觉走。
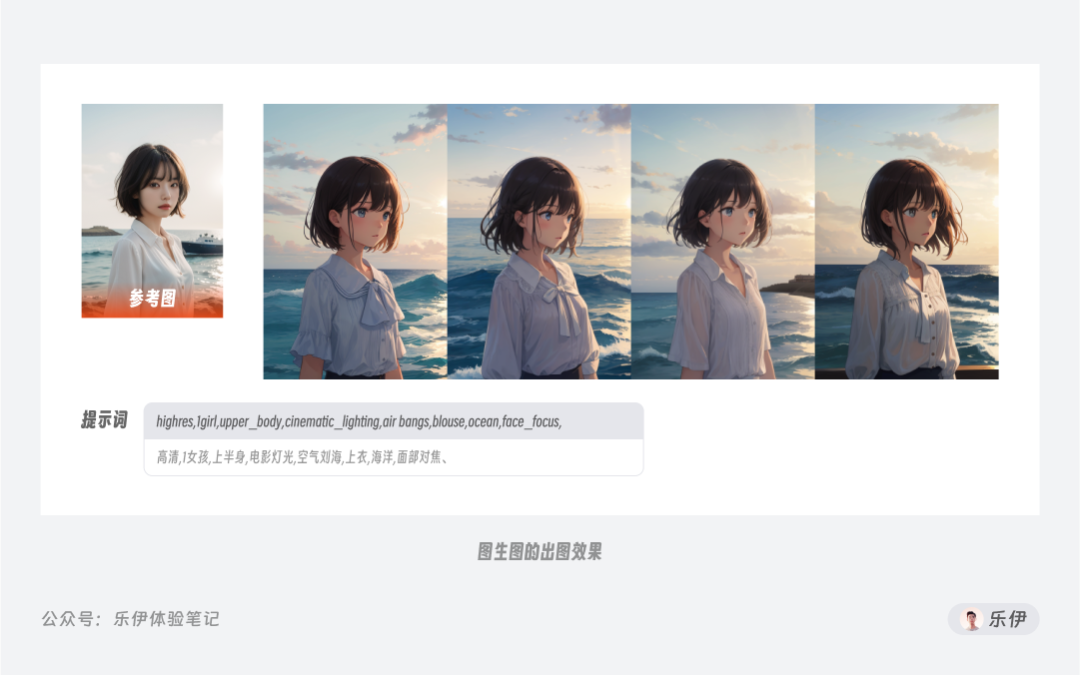
【感觉】这个词听起来似乎虚无缥缈,但在AI绘画领域是有实际道理的,因为图像能承载的信息要比文字多得多。以上面这张图为例,如果用提示词描述,可能写上几百字都难以向模型解释清楚画面的内容,但图生图不同,模型会自动从参考图上提取像素信息,并将其作为特征向量准确映射到最终的绘图结果上,通过这样的方式能最大程度还原参考图中的提示信息,实现更稳定准确的出图效果。
因此,传统意义上的图生图就是将提示词和参考图中的图像信息进行综合考虑并进行绘图的过程。
1.2 真正强大的图像重绘
当然,如果仅仅是喂图功能,Stable Diffusion的图生图板块并不值得我们单独花一篇文章来讲解,它的真正价值在于提供了丰富的操作工具将图像可控性提升到了新的层次。
我们先来回顾下平时使用文生图进行AI绘画的过程:编写提示词进行绘图,然后根据出图结果再不断优化提示词和各类参数进行抽奖,最终得到一张比较满意的图片。而图生图则是直接根据现有图片进行优化调整,因此图生图的操作过程可以简单理解成省去了前期文生图的抽奖过程,直接在现有图像约束的基础上进行的二次重绘。

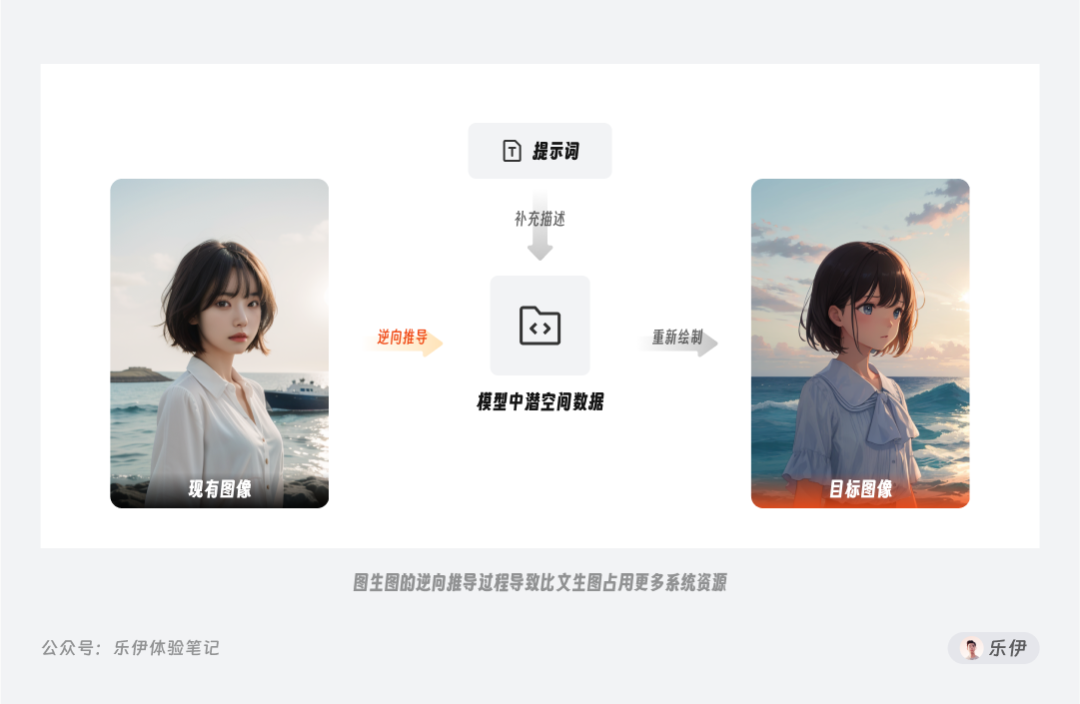
需要注意的是,配合参考图进行图生图的过程是需要将参考图先逆向推导为潜空间的数据,再和提示词综合考虑绘制成图像。因此相比没有逆向推导过程的文生图,图生图的绘制会占用更多的系统资源,根据这个原理,我们也就能理解使用参考图的尺寸越大,在逆向推导的过程中消耗的资源也会越多。
在Stable Diffusion中,我们可以通过蒙版和局部重绘等功能来控制只对图像特定部分的区域进行重绘,并设置各类参数来控制重绘的效果。此外通过选择不同的绘图模型和调整图像尺寸,我们也能甚至还能实现画风转换、图像无损放大等更多玩法。相较于其他AI绘画工具,Stable Diffusion中的图生图并非单纯的喂参考图,而是可以在现有图片的基础上通过人工干预来实现更加稳定可控的图像重绘。
图生图工具解析
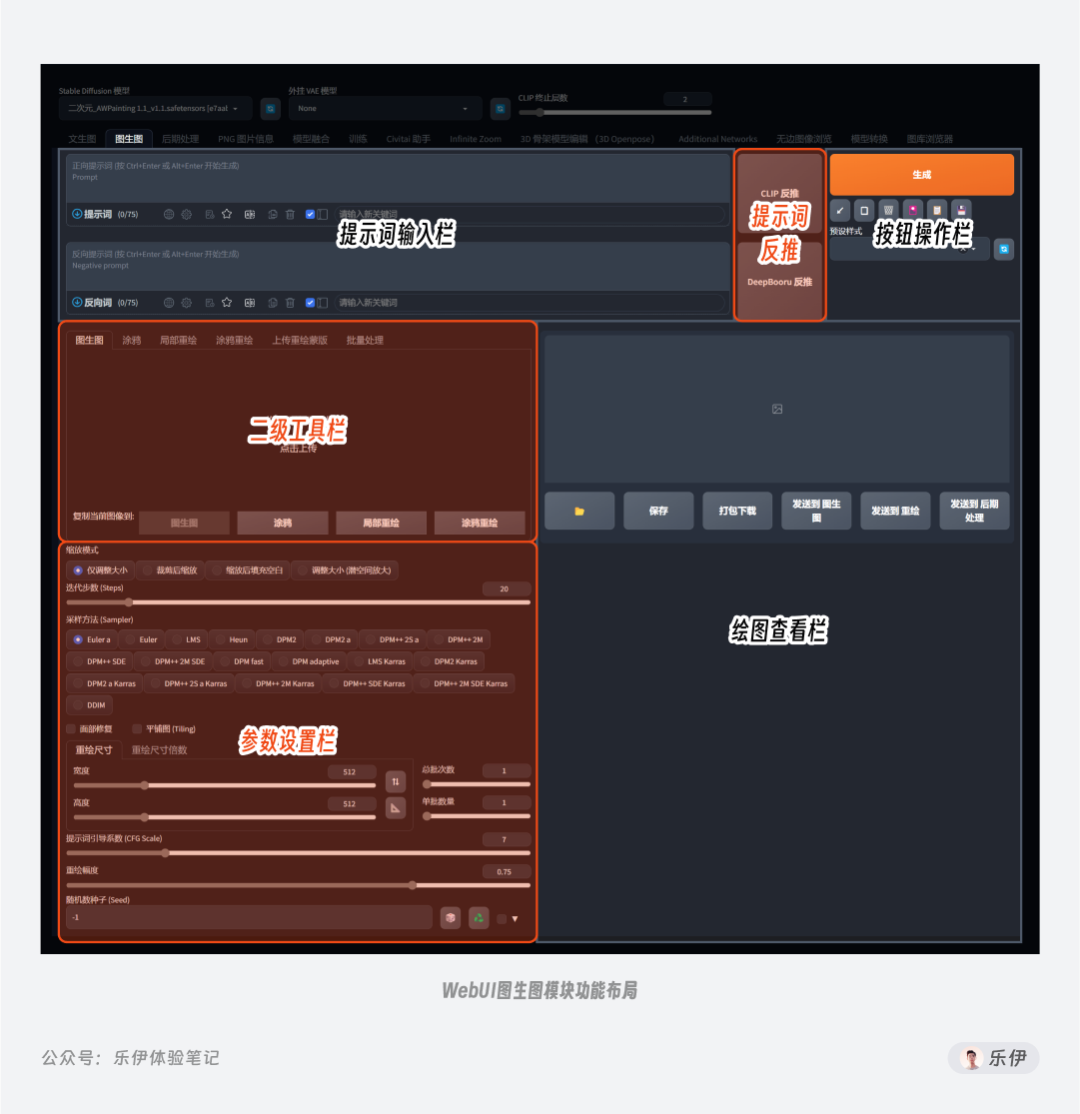
在WebUI的功能导航栏中选择图生图模块,我们可以看到它的页面布局和文生图基本类似,同样有提示词输入框、操作按钮和参数设置项,不同的是这里多了提示词反推、支持上传图片的二级功能模块和对应的参数设置项。
2.1 提示词反推
先来看提示词反推的功能:即根据提供的图片自动反推出匹配的文本关键词,也就是我们俗称的图生文功能。WebUI这里提供了Clip反推和DeepBooru反推2种反推操作,其区别在于:
-
Clip反推:推导出的文本倾向于自然语言的描述方式,即完整的描述短句,该功能的特点是可以描述出画面中对象间的关系
-
DeepBooru反推:推导结果更多的是单词或短句,比较类似我们平时书写提示词的方式,该功能更倾向于描述对象特征
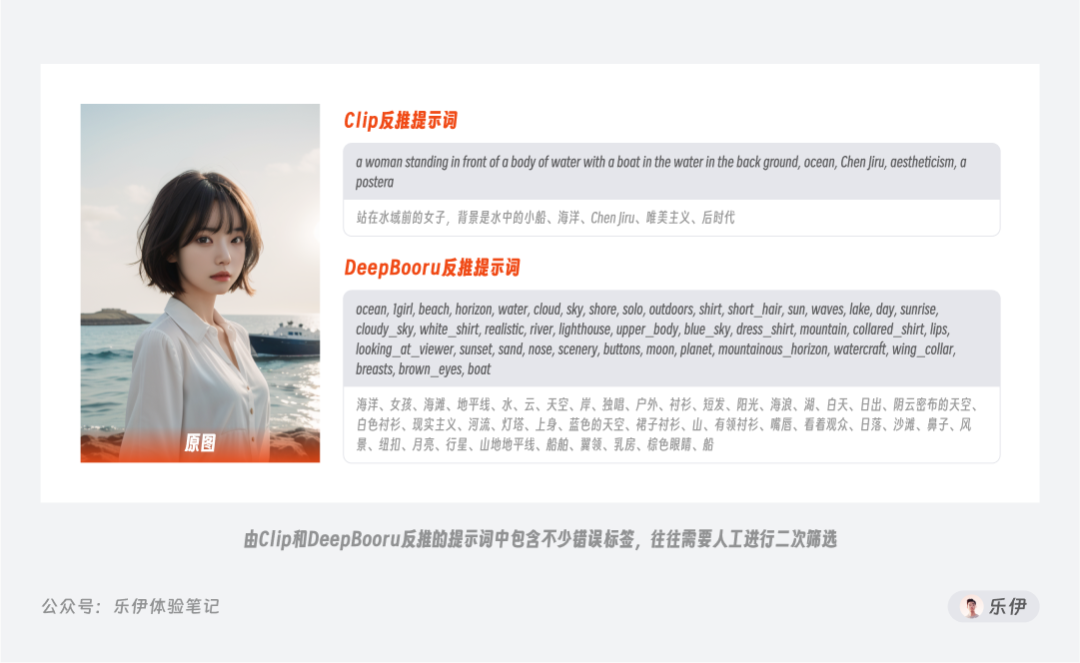
不难看出,通过Clip和DeepBooru反推的提示词中包含不少错误标签,需要人工进行二次筛选。其实,WebUI在图生图模块内置提示词反推是为了在上传图片后可直接获取相应的参考关键词,以便后面更好的通过提示词来控制重绘图像内容。但实际上我们平时反推提示词时更常使用的是秋叶整合包中自带的Tagger插件,该插件除了生成的提示词准确度和稳定更高,还提供了关键词分析和排名展示,属于Stable Diffusion的必备插件之一。
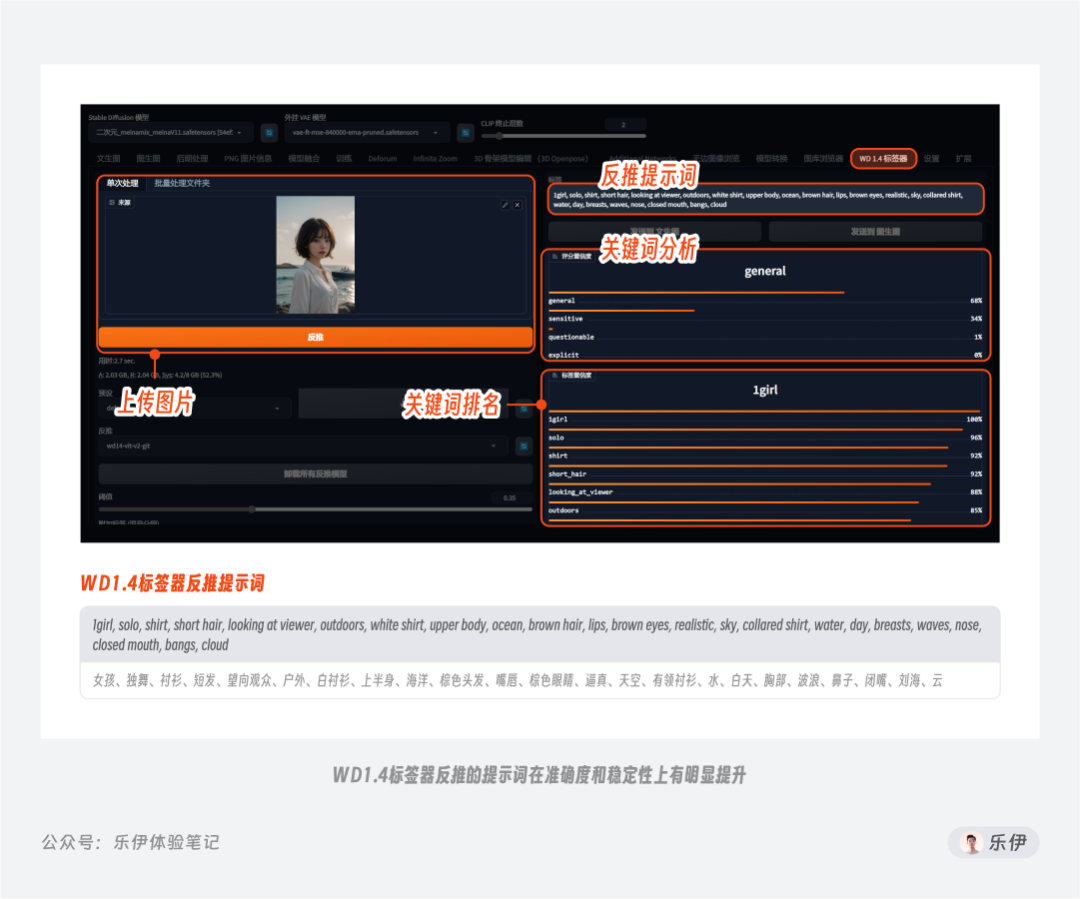
在Stable Diffusion中有非常多类似的开源插件可以有效提升绘图效率,但不属于本篇文章重点,这里就不过多介绍了。
2.2 二级工具栏概览
在图生图模块中为我们内置了许多二级工具栏,很多朋友看到这样可能会担心学习起来很复杂。但其实这里每款工具其实都是在上一个工具基础上进行的衍生,比如涂鸦和局部重绘是在原生图生图基础上增加了手绘和蒙版,而涂鸦重绘又是这2款工具的结合。系统来看,所有的二级工具都是围绕图像重绘、手绘涂鸦和蒙版选区这3个基础功能所进行的重组,而WebUI作者是为了方便我们使用将实际操作场景进行了细分。
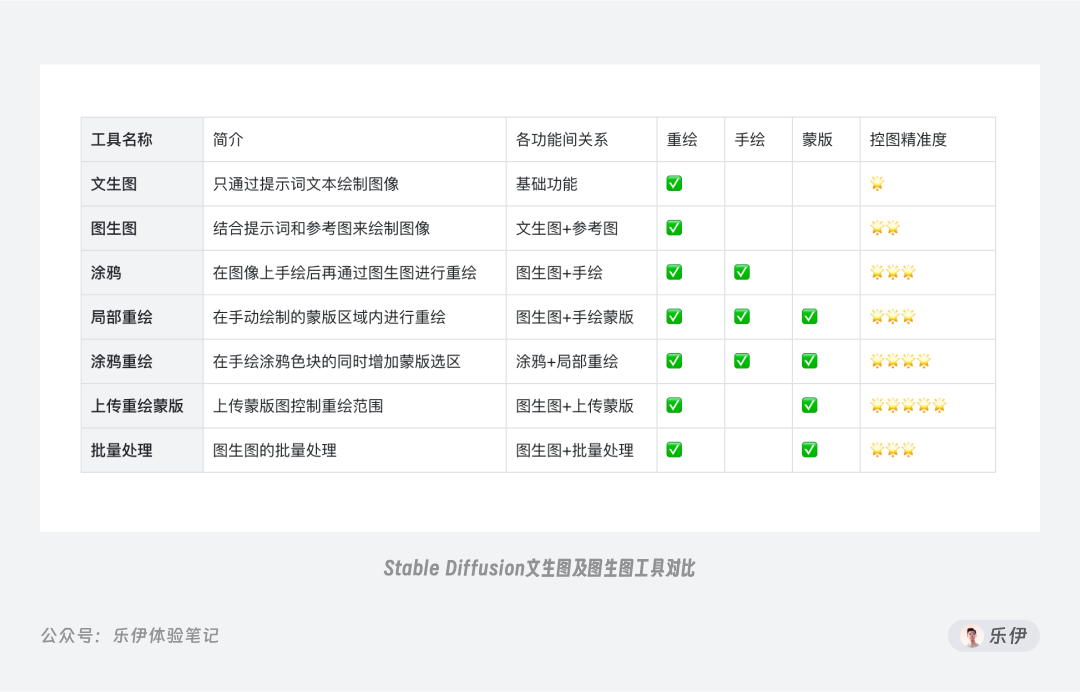
上图中整理了不同工具的简介和差异对比,下面针对每款工具和相关参数为大家进行详细介绍。
2.3 图生图工具
这部分的操作和文生图基本相同,区别在于支持额外上传参考图并增加了几项图生图专属的参数。下面介绍几项影响图生图效果的重要参数,这也是所有二级模块都需要用到的参数,其中和文生图模块中相同的参数这里就不再赘述了,大家可以回顾下【文生图篇】的相关内容。

2.3.1 重绘幅度
重绘幅度可以说是图生图中最重要的参数,它的功能有点类似Midjourney中的iw参数。前面介绍图生图的原理是在原图基础上绘制一张新的图片,而重绘幅度就是用来控制在原图基础上重绘的发散性程度,数值越高,说明模型重绘过程中更加自由,绘制结果和原参考图的差异性越大,生成的图像也就更倾向于模型自身的绘图风格。
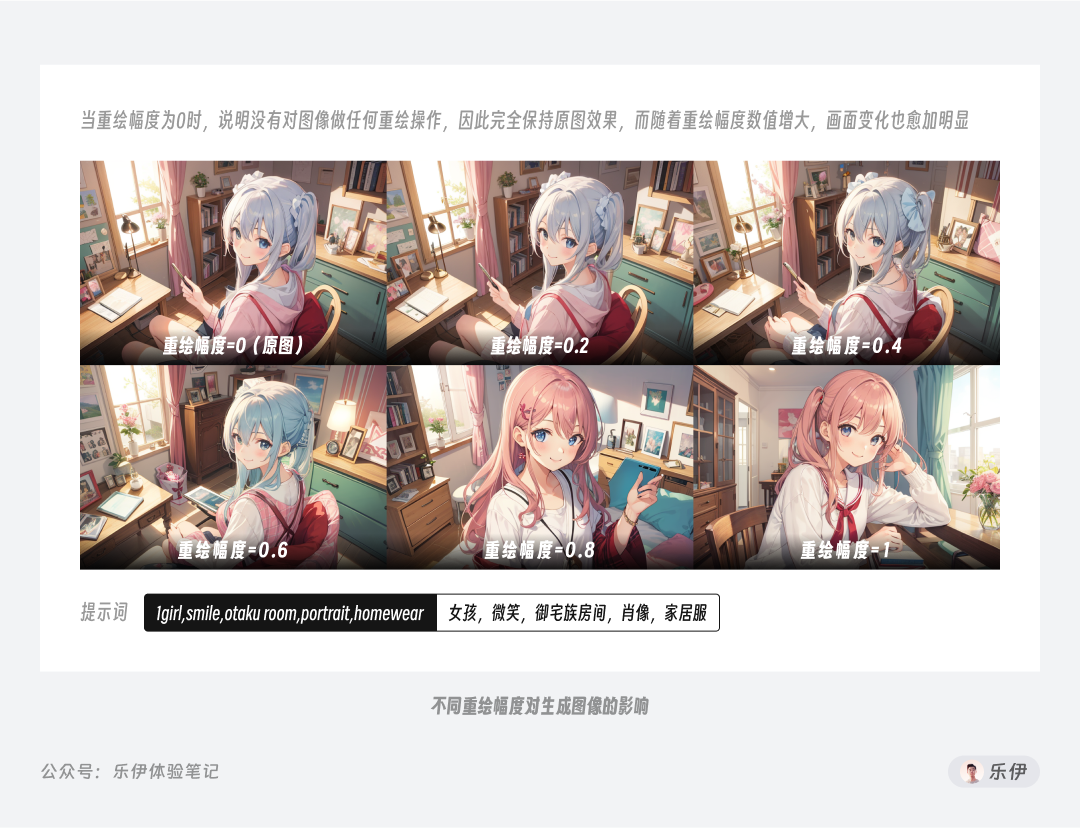
可以看到当重绘幅度过高时,绘制的图像内容和原图基本就很难进行关联了,因此我们通常将重绘幅度的数值控制在0.4~0.8之间,这样既能维持参考图的控图效果,又能保证重绘后不会发生太强烈的变化。但从重绘幅度角度来看图像可操作的范围并不大,该参数的更多场景是配合其他功能项进行灵活调节,在下面的内容中我会配合各类工具进行详细介绍。
2.3.2 重绘尺寸
故名思义,该参数用于设置重绘后的图像尺寸,可以分为直接设置图像宽高和设置图像缩放倍数2种调节方式。

默认情况下重绘尺寸会自动带入当前参考图的宽高数值,而当我们拖动尺寸滑块时,可以直观的在参考图上预览重绘后的图像范围。
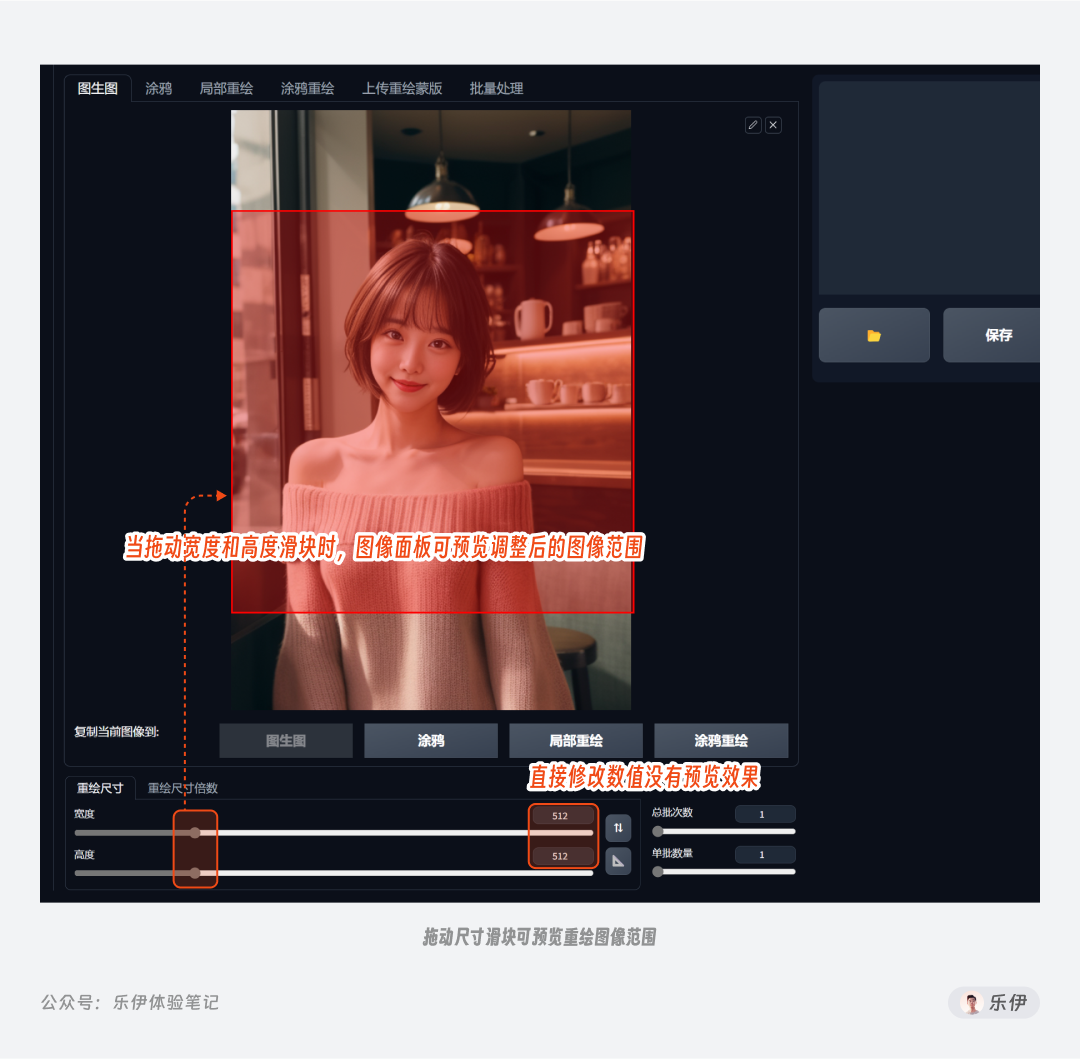
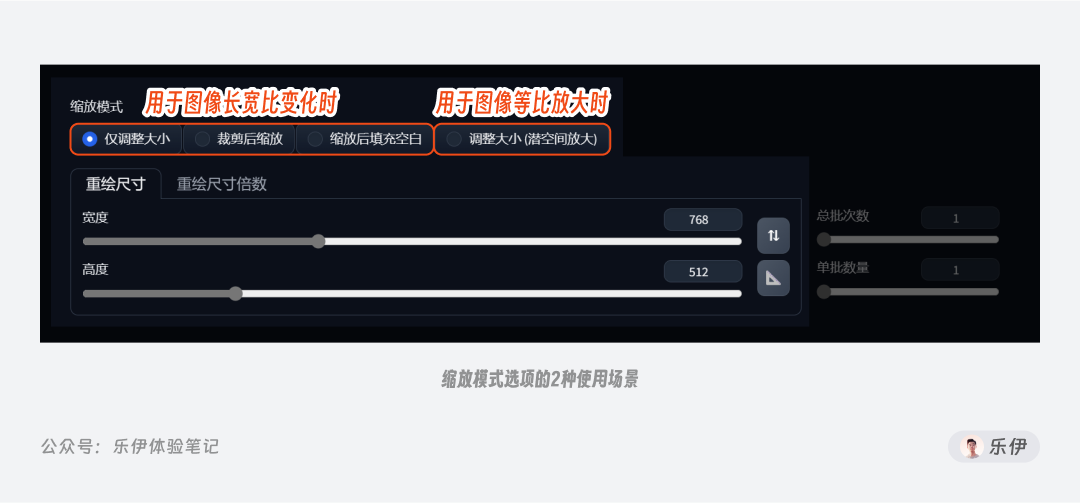
2.3.3 缩放模式
很多时候我们的参考图和重绘后的图片尺寸并不一致,而缩放模式就是用来选择采用何种变形方式来处理图像。这里虽然提供了4个按钮,但是可以分为2类场景来使用。一种是图像长宽比发生变化时使用,这里提供了3种我们常见的处理方式:拉伸、裁剪、填充(由于汉译插件不同,在名称上存在一定差异)。另一种是图像长宽比例不变时使用,多数情况下用于图像等比放大。
换句话说,如果重绘后的图像尺寸和原图完全一样,这几种缩放模式使用起来并没有区别。
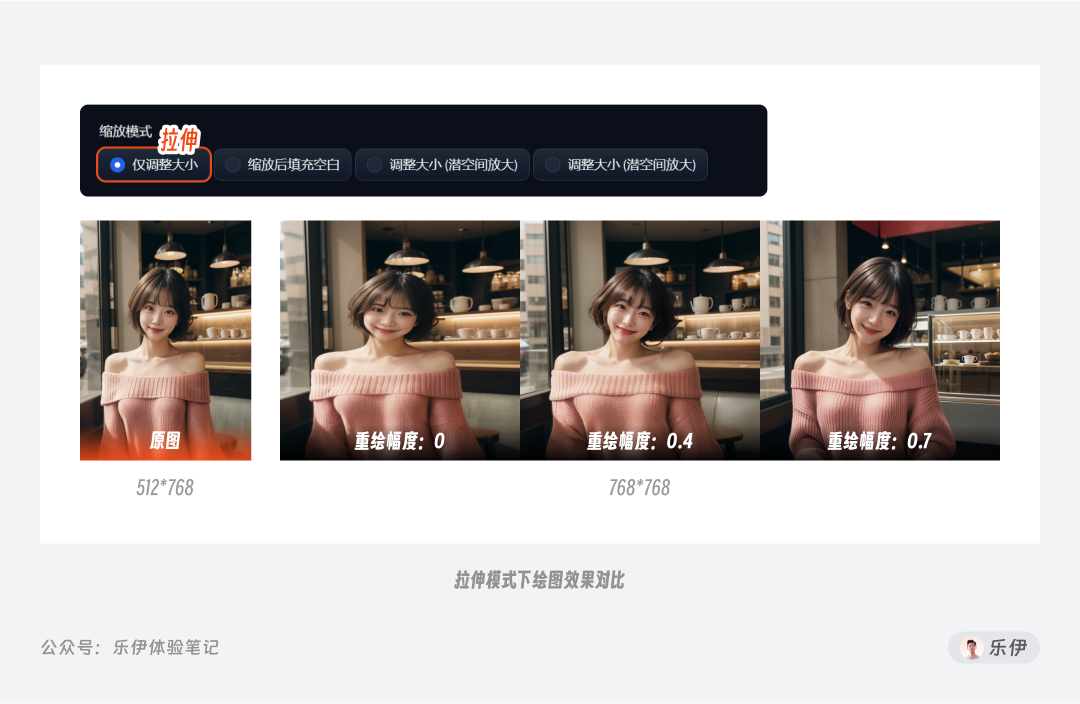
下面我们来挨个介绍不同缩放模式的效果差异。首先是拉伸模式(仅调整大小),它的效果是将原图直接变形拉伸至新设定的尺寸。在下面的图中可以看到,在重绘幅度参数设置为0时,图像被直接变形拉伸为正方形,而随着提升重绘幅度,变形效果逐渐得到缓解,但同样也会导致和原图差异过大。
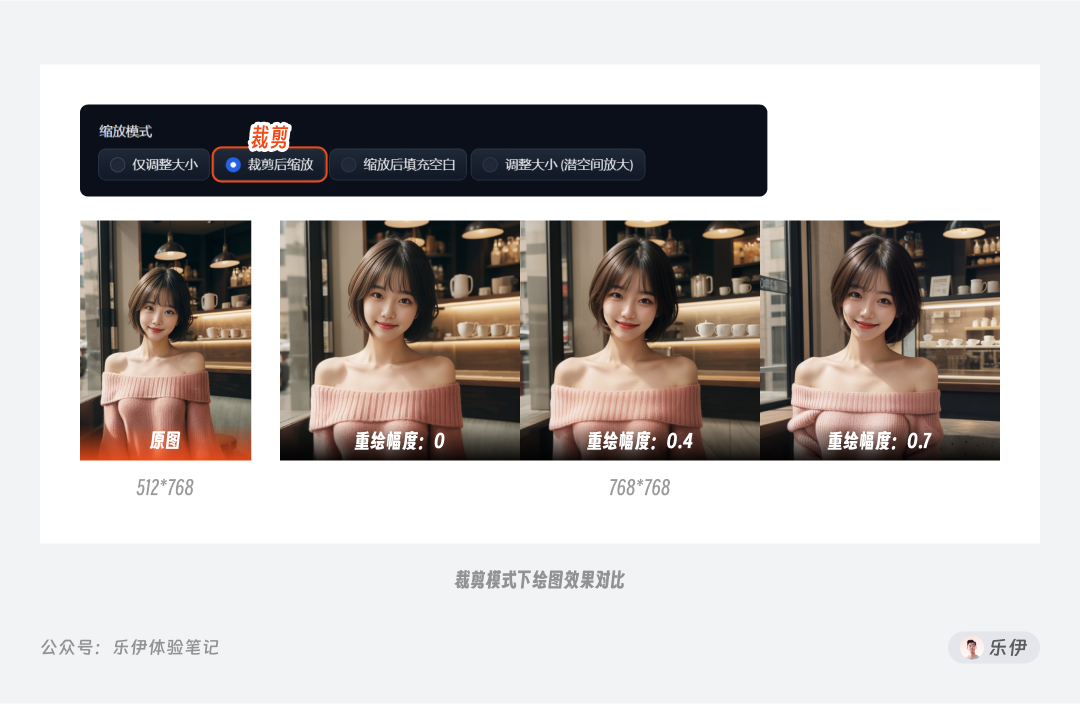
第二种裁剪模式(即裁剪后缩放)是根据新设定图像的长宽比,对原参考图的内容进行裁切。重绘后尺寸由矩形变为正方形,上下部分内容被裁切,这里的重绘幅度参数不会对图像的长宽比例产生影响。
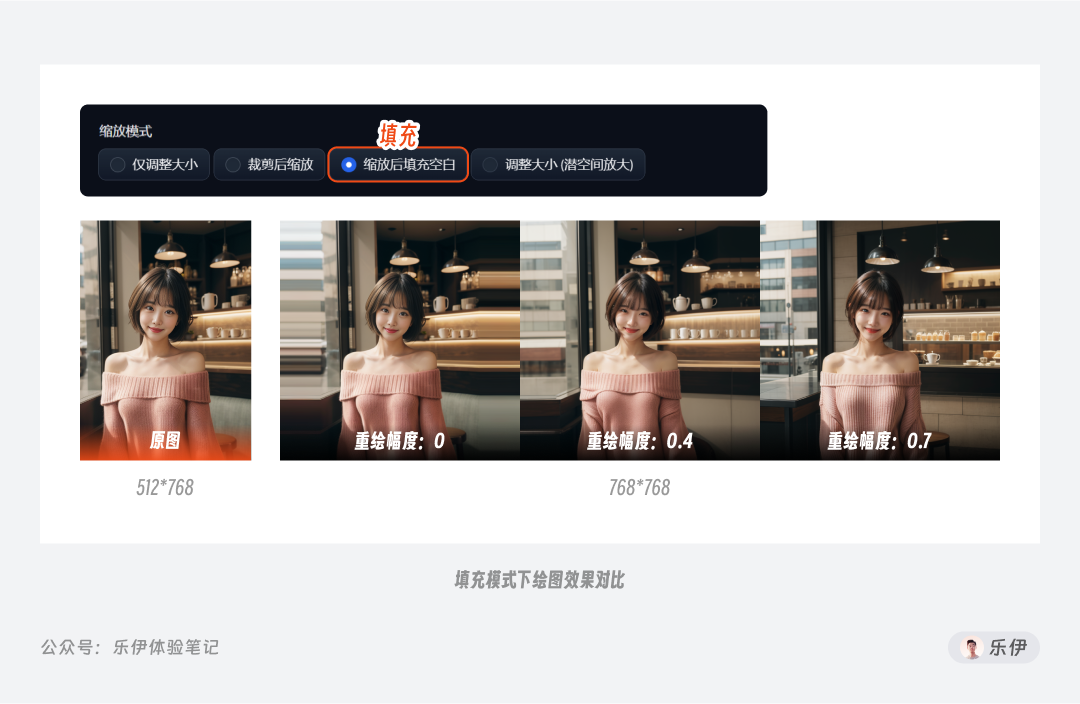
第三个填充模式(缩放后填充空白)的效果根据新设定的长宽比例,将原图缺失的部分进行绘制填充。比如当图像从原图的512*768重绘为768*768时,下图的效果就是向左右填充了新的背景内容,且随着重绘幅度数值越大,填充部分和原图的融合效果越好。
最后一种缩放模式叫调整大小(潜空间放大),有的地方也叫直接缩放,该功能主要用于对图像进行等比放大,实现“小图转大图”的效果。当然如果重绘尺寸比例和原图比例不一致,则默认会采用拉伸的方式进行处理,但由于是反馈到潜空间中进行运算,因此图像出现了模糊变形的效果。
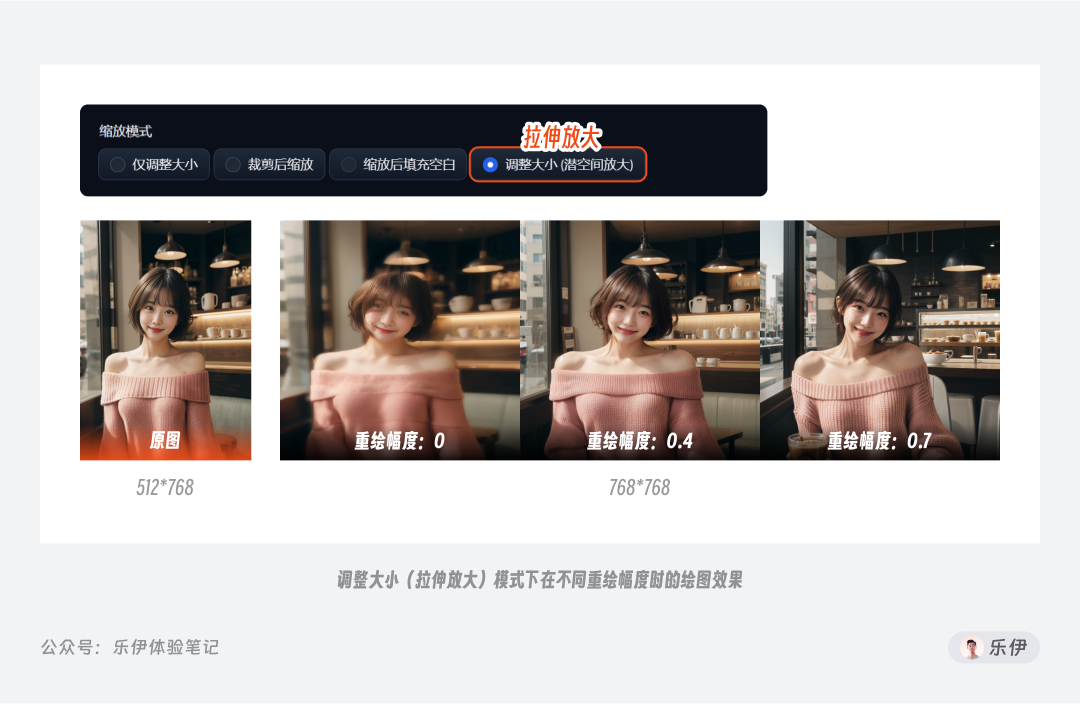
相较于单纯增加分辨率的放大做法,图生图中使用调整大小模式有重绘幅度参数可供调节,少量的重绘幅度可以为原图增加更多细节。

当然添加重绘幅度的弊端是不可避免的会导致图像发生改变,想要实现更好的效果还有更多定制插件可以实现低显存绘制高清大图,此处先按下不表。
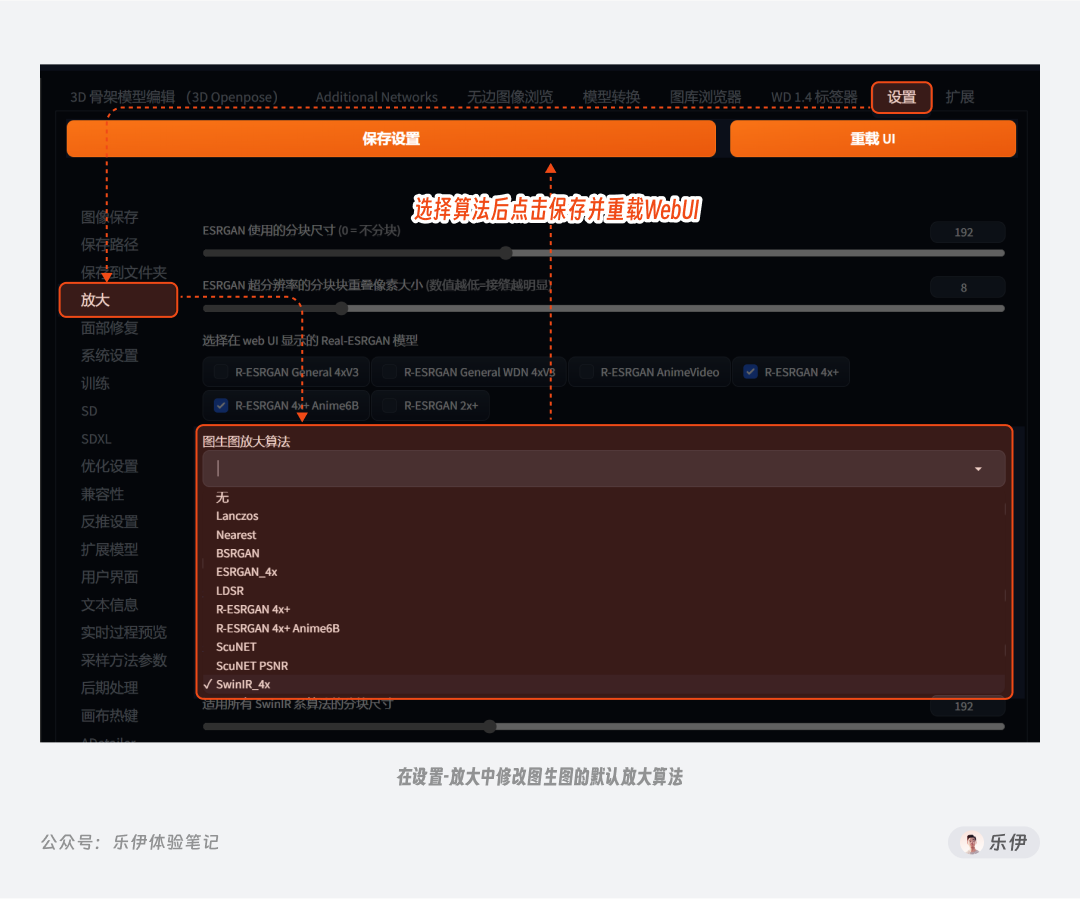
对于调整大小功能的潜空间放大算法,我们可以在设置-放大-图生图放大算法中进行切换,选择之后记得保存设置并重启webUI界面。
综合使用场景来看,除非是需要对图像进行画布拓展,否则多数情况下还是建议先将参考图裁剪到目标比例再导入图生图中使用,这样的出图效果会更加可控。
下面我们再来看看图生图模块下的其他二级工具及参数,由于汉化差异,二级工具的名称可能不同,比如涂鸦重绘有的翻译插件下也被称作有色蒙版重绘。
2.4 涂鸦工具
再来看看第二个涂鸦工具,涂鸦工具的参数项和图生图完全相同,唯一区别是上传图像后右上角多了画笔工具,支持我们对图像进行涂抹。涂鸦工具相当于增加了我们传统的手绘过程,在图片上涂抹色块后再进行全图范围的图生图,同时配合提示词可以实现更加多样的重绘效果。
其中画笔支持调整调整笔触大小和切换颜色,自带的吸色工具也可以进行全屏幕范围内的取色。
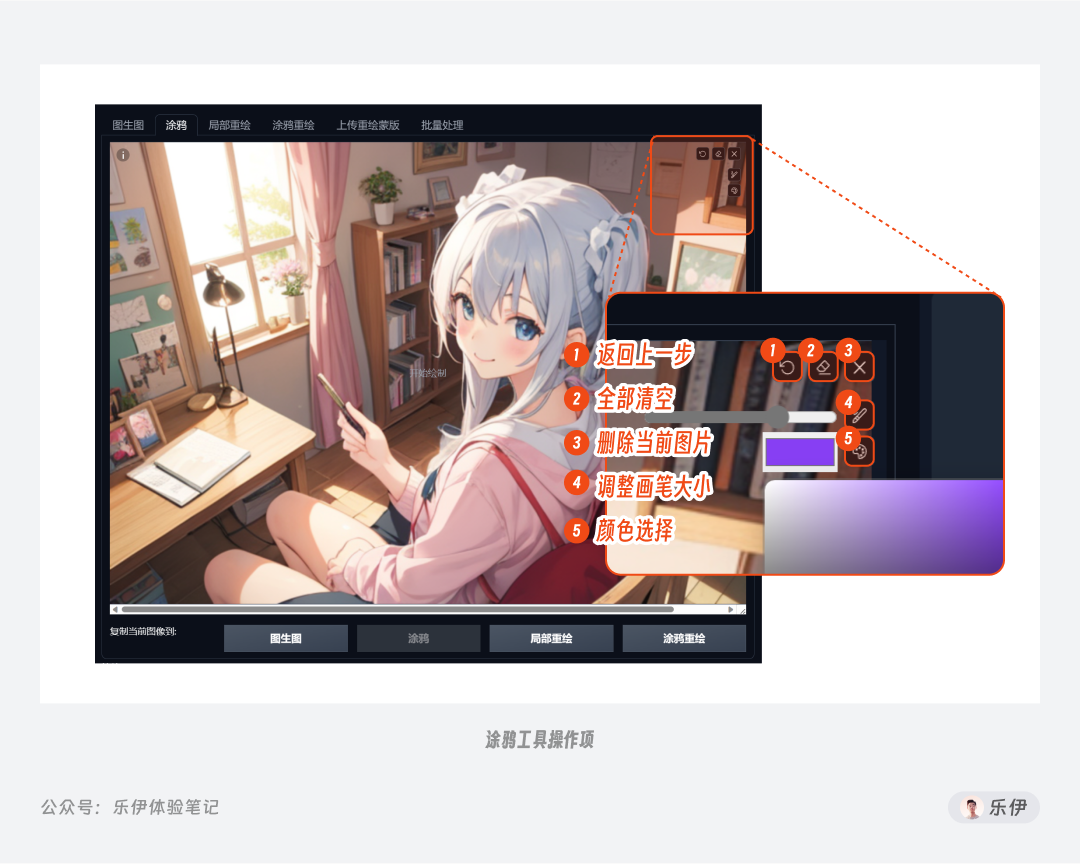
在这几个操作工具中,返回上一步的按钮目前还存在bug,有时候并不会逐步撤回而是将整个涂鸦笔触全部清空。并且由于不知名原因,上传的图片有时候会出现报错或失效等情况,需要删除当前图片后重新上传才能。
涂鸦工具的操作很简单,使用画笔在图像上涂抹颜色后点击生成,Stable Diffusion会将手绘后的图像进行整体重绘,同时控制重绘幅度和增加描述关键词可以实现非常神奇的融图效果。在下图中可以看到女孩的衣服会根据涂鸦部分重绘成紫色的运动服,当重绘幅度设置为0.5左右时达到比较自然的融合效果。
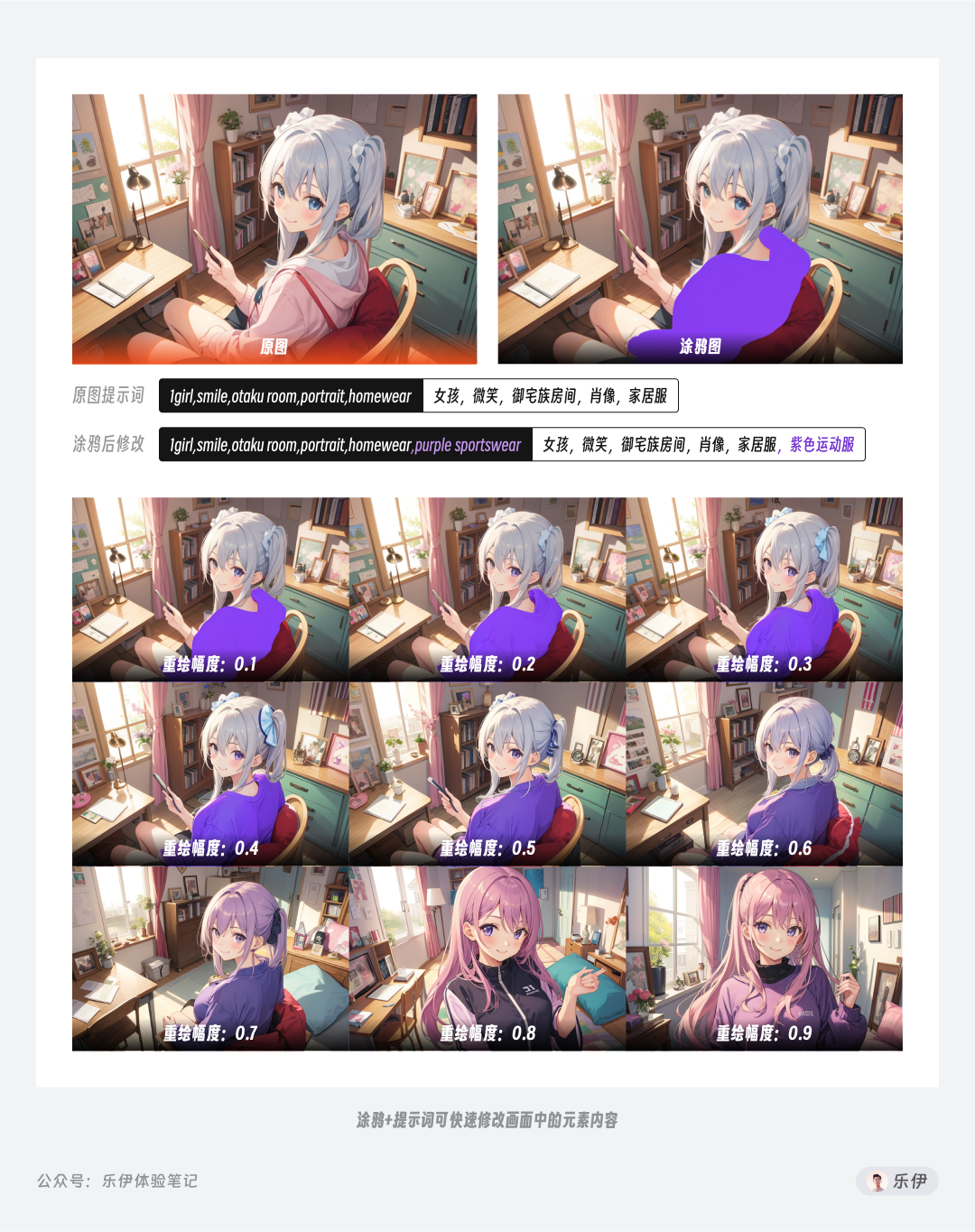
需要注意的是通过涂鸦工具来重绘图像时,由于重绘幅度的影响,画面中未被涂鸦的部分也会发生变化,因此涂鸦工具是针对画面整体进行重绘。

由于鼠标涂鸦的绘制效果不够准确,而且涂抹的颜色不支持透明度等细节调整,因此涂鸦工具平时使用并不多,一般都是导入PS中进行细致的绘制操作,这里就不做过多赘述了。
2.5 局部重绘工具
再来看看局部重绘工具,在前几天,Midjourney终于上架了大家期待已久的局部重绘功能,应该算得上是Midjourney目前在控图方向上最大的一次迈步,而Stable Diffusion在这块算得上是深耕已久。简单来说,局部重绘就是在图像中设定一块区域,在图生图过程中只针对该区域部分进行重绘,而其他部分保持不变,从而实现精准控制改变图像特定部分的效果。该功能通常用于对画面大部分内容都基本满意,但需要调整部分细节元素的场景。
在下图中可以看到,局部重绘同样是使用画笔进行涂抹,但这里涂抹的颜色只有黑色,因为被涂抹区域表示的是蒙版,而不是实际的颜色色块。
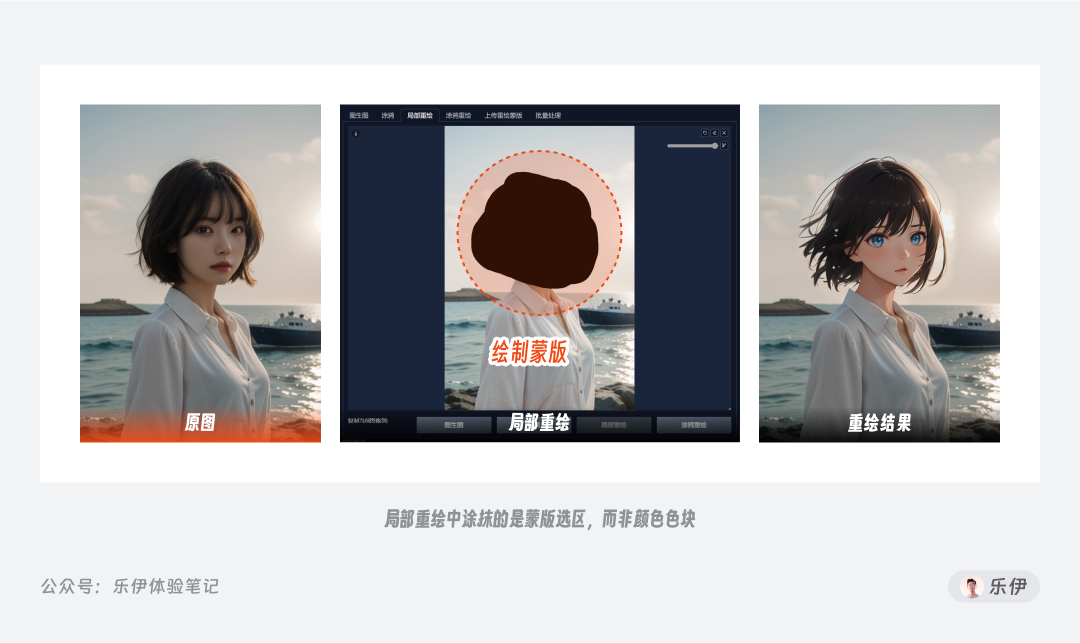
下面我们来看看局部重绘的各项参数。
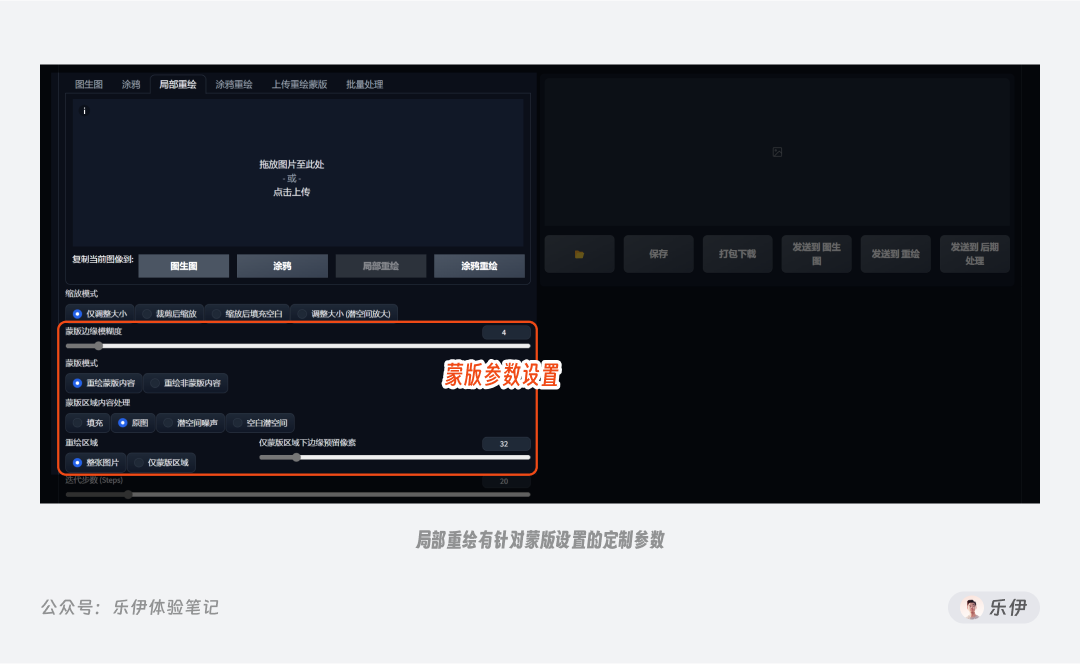
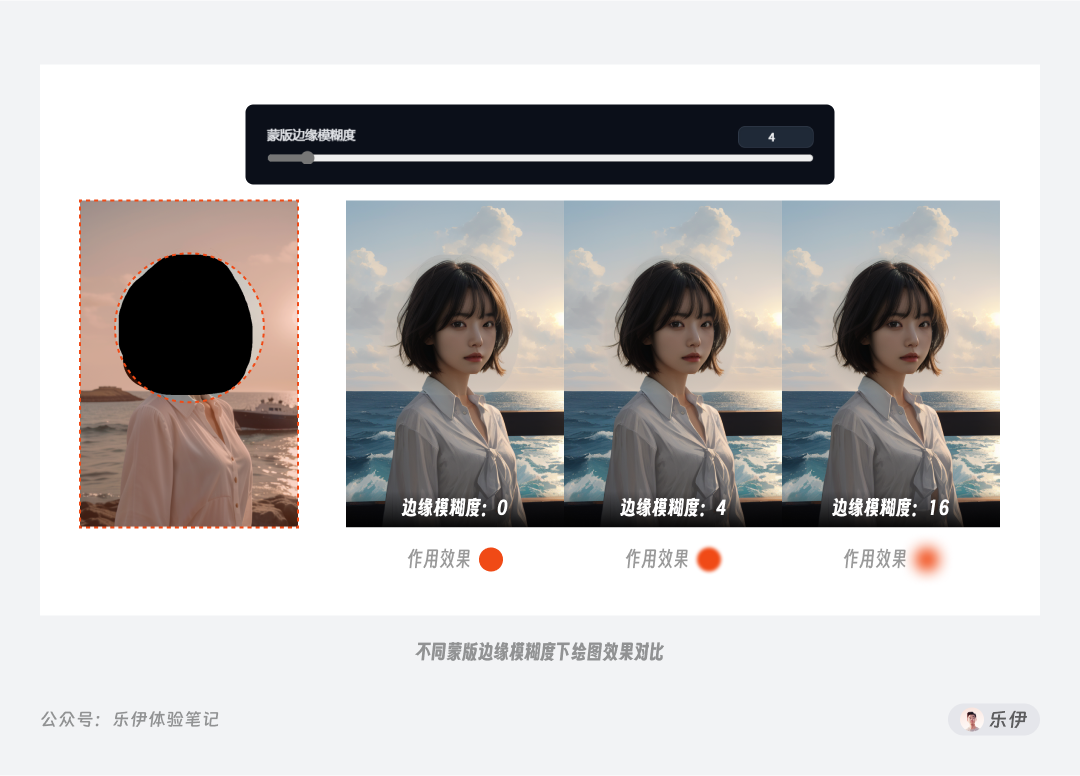
蒙版边缘模糊度:该参数用于设置重绘区域和原图的融合程度,效果可以简单理解为PS中的选区羽化。边缘模糊度太小会导致边缘衔接过于生硬,而数值太高会削弱蒙版的区域限制效果,导致蒙版不精确或直接失效。默认情况下数值是4,我们可以根据图像的融合效果来进行适度调节。
为方便对比蒙版效果,在下图的案例中我选择重绘黑色蒙版之外的区域,可以发现当边缘模糊度为0时,蒙版边缘非常生硬,而随着数值变大,重绘区域和原图的融合过渡也变得更加自然。
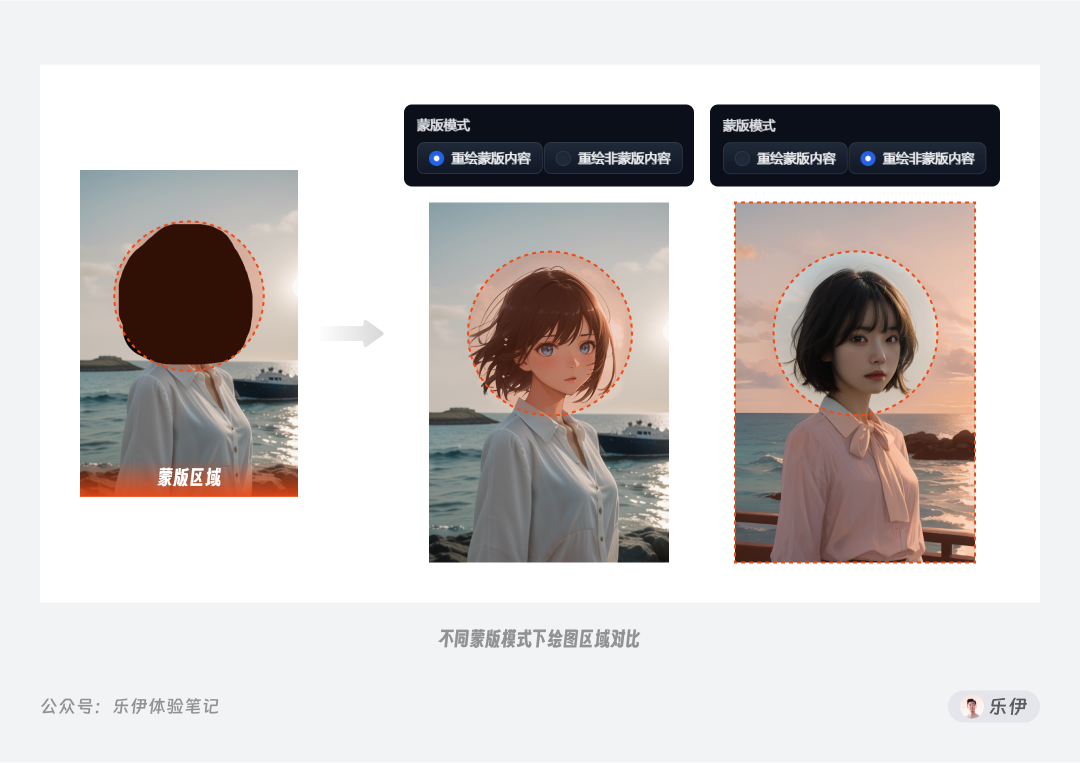
蒙版模式:【重绘蒙版区域】表示重绘涂抹过的蒙版区域,【重绘非蒙版区域】表示涂抹区域不变,而是重绘画面中的其他区域。该参数类似PS中的选区反转,在实际使用时根据重绘区域大小自由选择是涂抹需要重绘的部分还是剩余的背景部分。
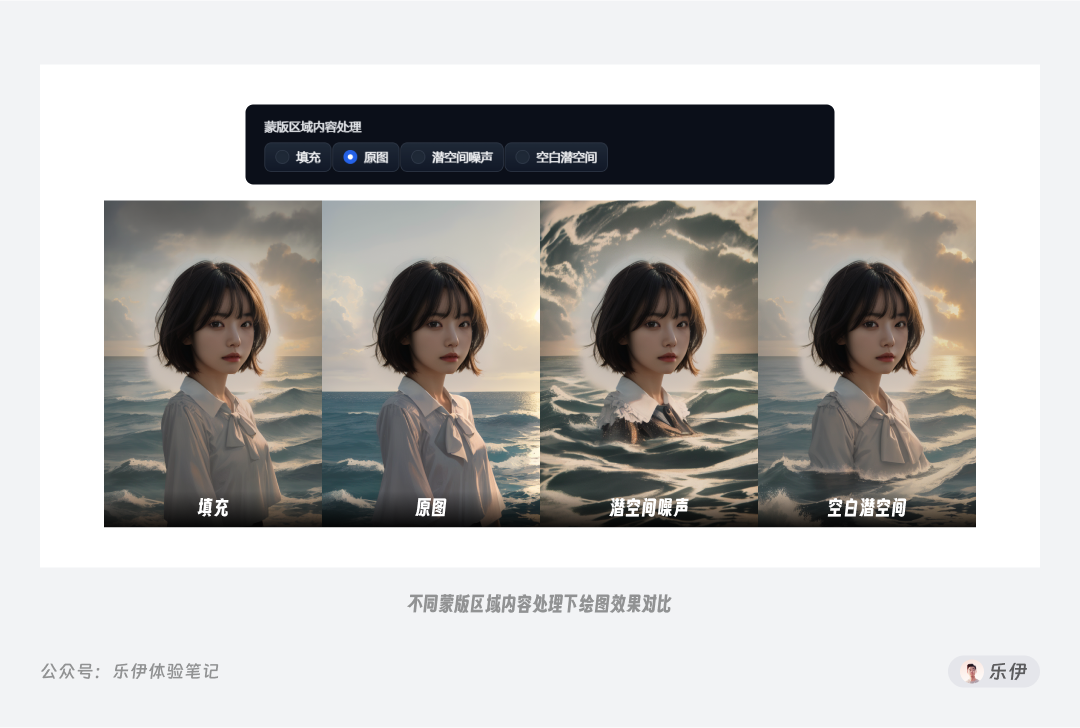
蒙版区域内容处理:该选项用于设置重绘时的图像处理方式,这里提供了4个选项:填充、原图、潜空间噪声、空白潜空间,具体的效果可以看下图,相较之下潜空间噪声会比其他几项产生出更多变化,而原图的效果比较稳定。
该参数对绘图结果的影响不太稳定,一般情况下保持默认的【原图】即可。
重绘区域:指的是重绘过程中用于参考的图像范围。在下图中可以清楚的看到,当重绘区域设置为【仅蒙版区域】时,绘制的部分只有涂抹的蒙版部分区域的元素,相当于把涂抹区域切割下来单独进行重绘,该选项下会打断选区和参考图其他部分的联系,最终画面的融合效果可能会下降。
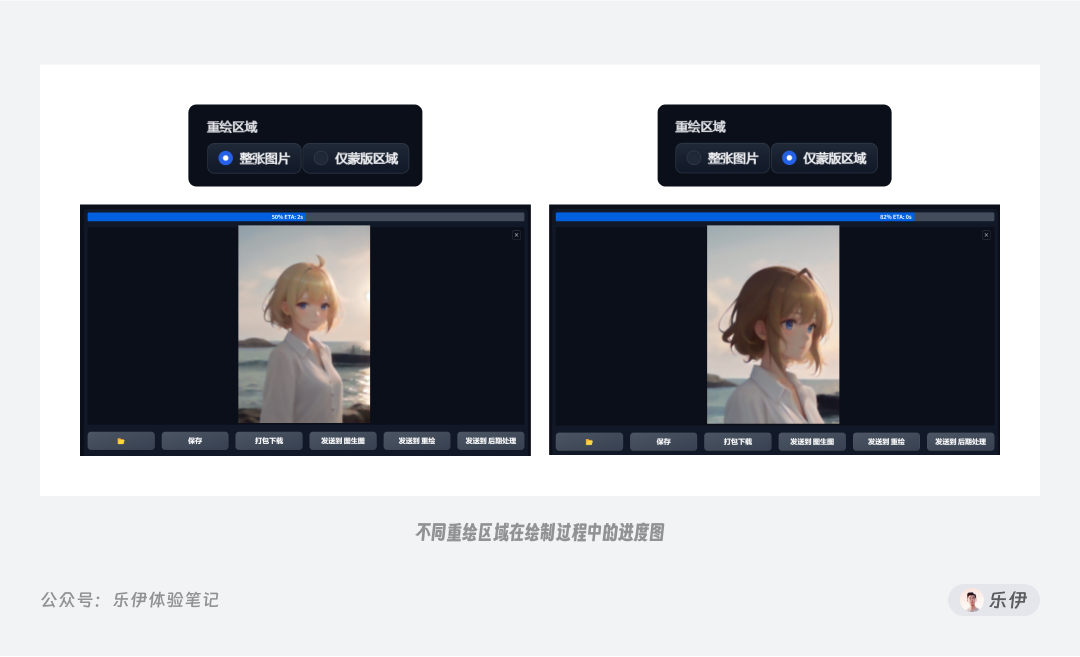
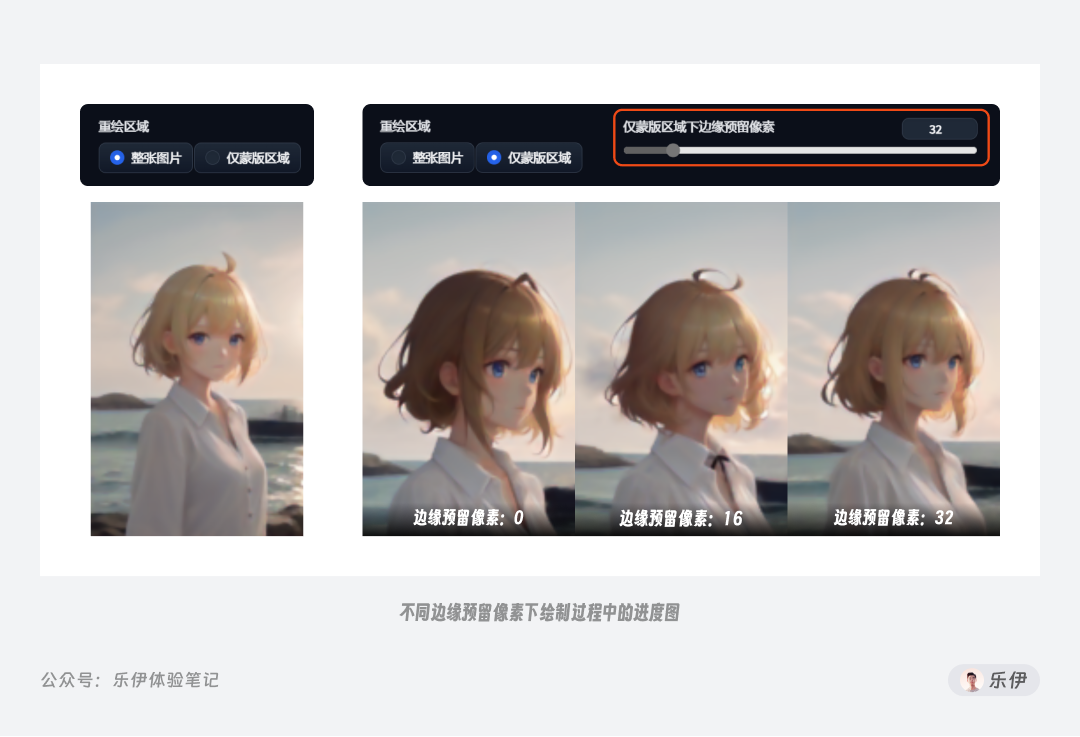
仅蒙版区域下边缘预留像素:该参数只在重绘区域选择了【仅蒙版区域】时生效,用于控制切割下来重绘部分向外扩展的范围大小。观察下面重绘过程的进度图可以发现,边缘预留像素的数值越大,则绘制过程中会向四周裁剪更多的内容进行整体重绘。
在默认情况下局部重绘会参考全图进行绘制,并且被涂抹的范围并不代表都会发生变化,所以通常我们会在目标区域基础上对外再涂抹一部分区域,以保证重绘后更好的融合效果,而提高边缘预留像素也是同样的原理。
总结来看,由于手涂蒙版的方式比较方便也很自由,因此局部重绘被广泛用于图像的局部调整,比如常见的脸部修复、手部修复等。
2.6 涂鸦重绘工具
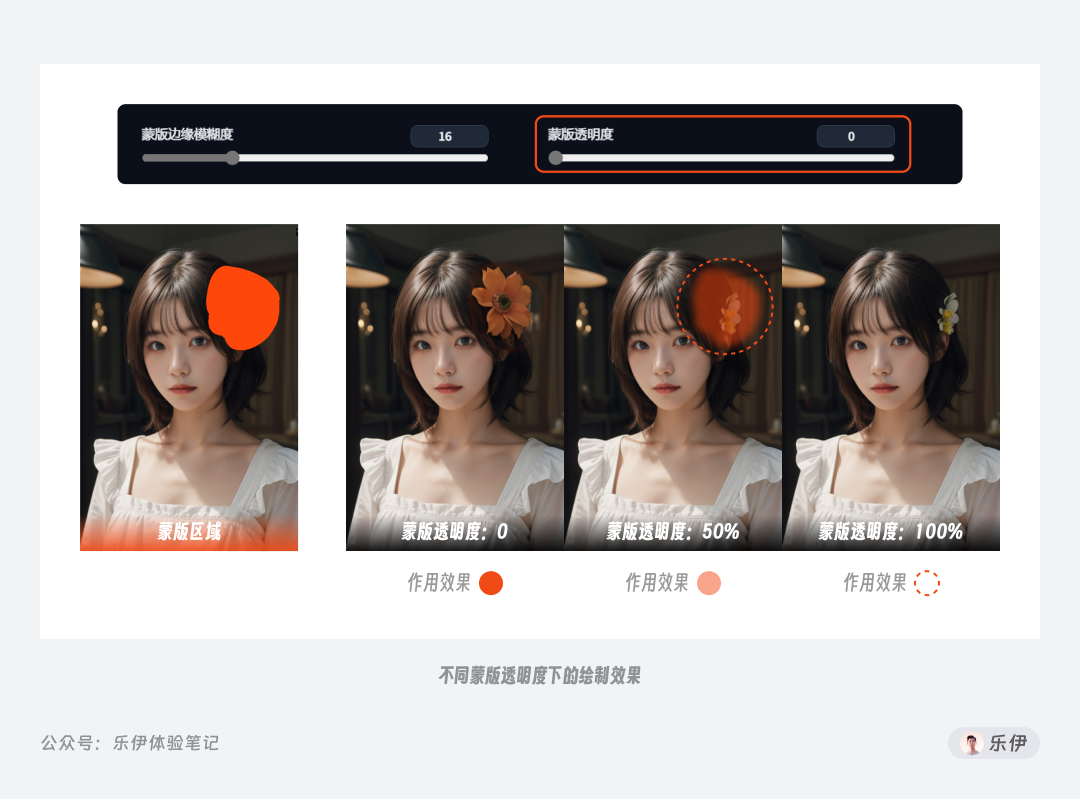
涂鸦重绘工具可以理解为涂鸦+蒙版的结合,相当于在涂抹颜色的同时加上了局部重绘的蒙版,只不过这个过程中颜色涂抹和蒙版绘制是同时进行的。因此和局部重绘相比,涂鸦重绘多了一个参数项:蒙版透明度。
蒙版透明度设置的是涂抹色块在画面中的呈现效果:当透明度设置为0时涂抹颜色完全覆盖下方图片,此时等同于涂鸦工具的效果,50%时相当于半透明色块,而达到100%时蒙版完全透明,相当于色块消失。需要注意的是,当透明度过高时涂抹色块可能无法被Stable Diffusion准确识别,绘制结果中会直接呈现出半透明色块效果(如下图中的50%透明度时)。
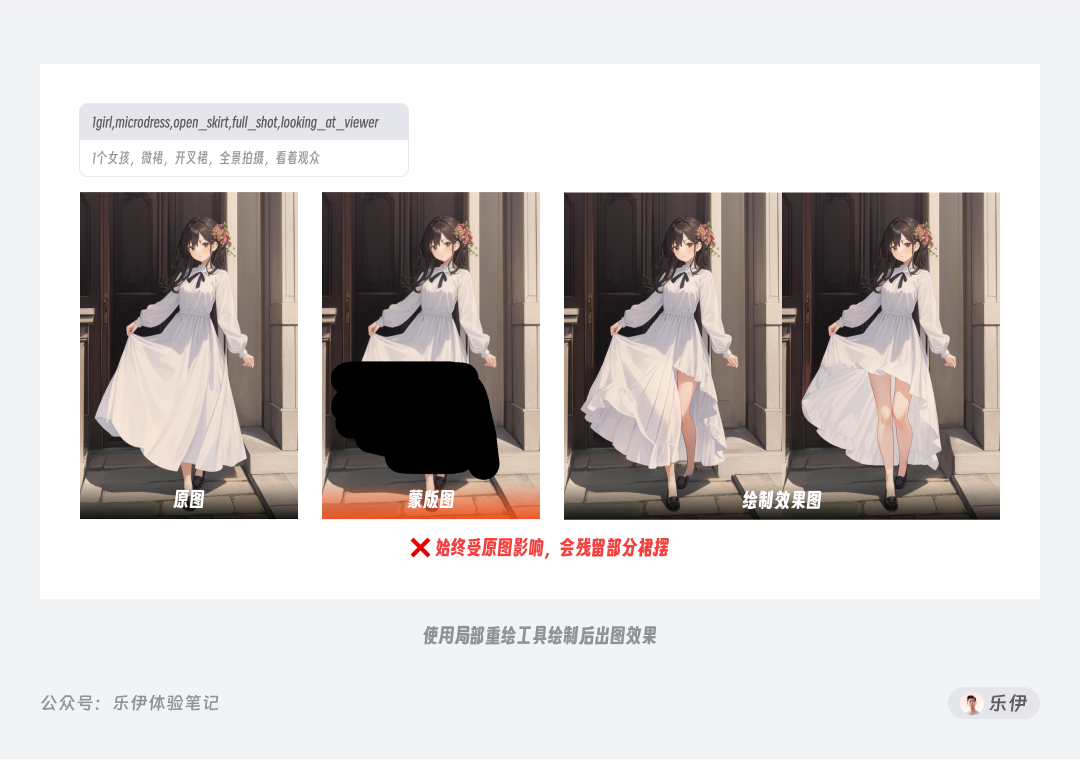
下面举个实际案例,我们希望实现长裙变短裙的效果。如果只是单纯的局部重绘,重绘的部分始终会受到原图其他部分的影响出现裙摆,但这里的重绘幅度又不能调整过高,否则和原图会产生明显的割裂感。
但使用了涂鸦重绘相当于给Stable Diffusion提供了大概的范围参考,并且由于可以自由设置绘制色块的不透明度,不用担心完全覆盖原图内容,在整个重绘操控上更加准确和稳定。
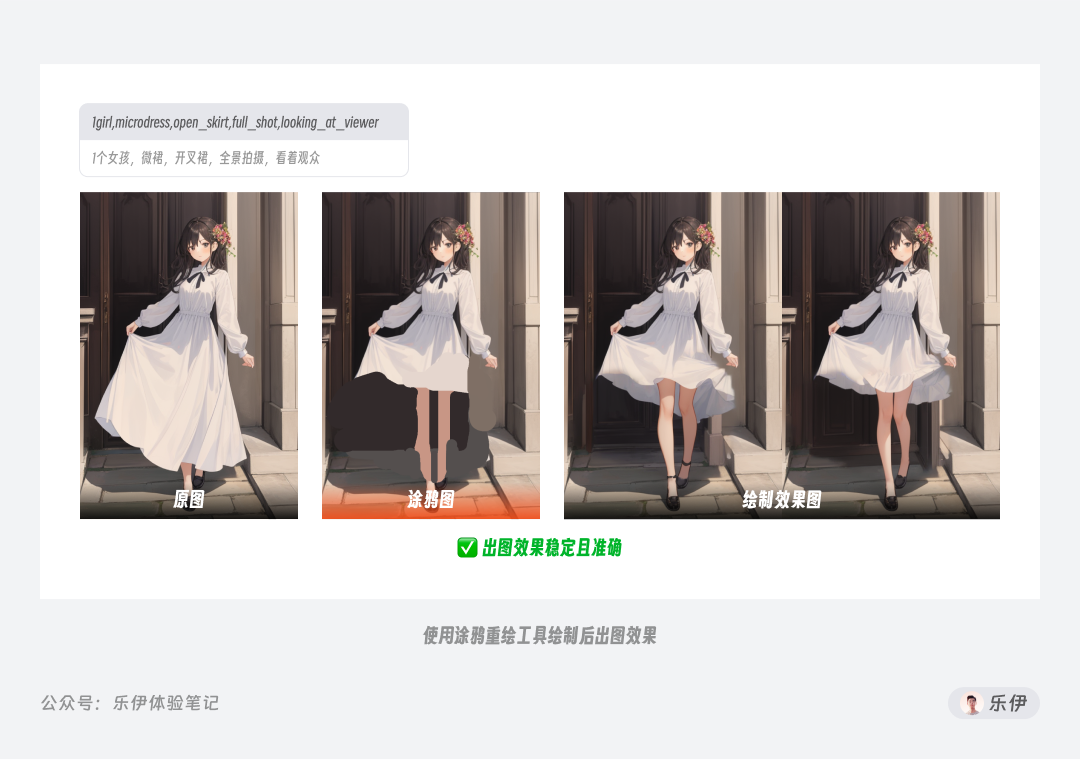
对比来看,涂鸦重绘比单纯的涂鸦工具多了蒙版的局部控图效果,又比局部重绘工具多了颜色的指导作用,可以说是两款工具的结合体。
2.7 上传重绘蒙版工具
虽然涂鸦重绘效果很好,但毕竟手动涂抹的方式不够准确,因此WebUI也提供了自行上传蒙版的方法来精准控制重绘区域。上传重绘蒙版和局部重绘的页面基本相同,区别在于支持额外上传一张已绘制好的蒙版图。
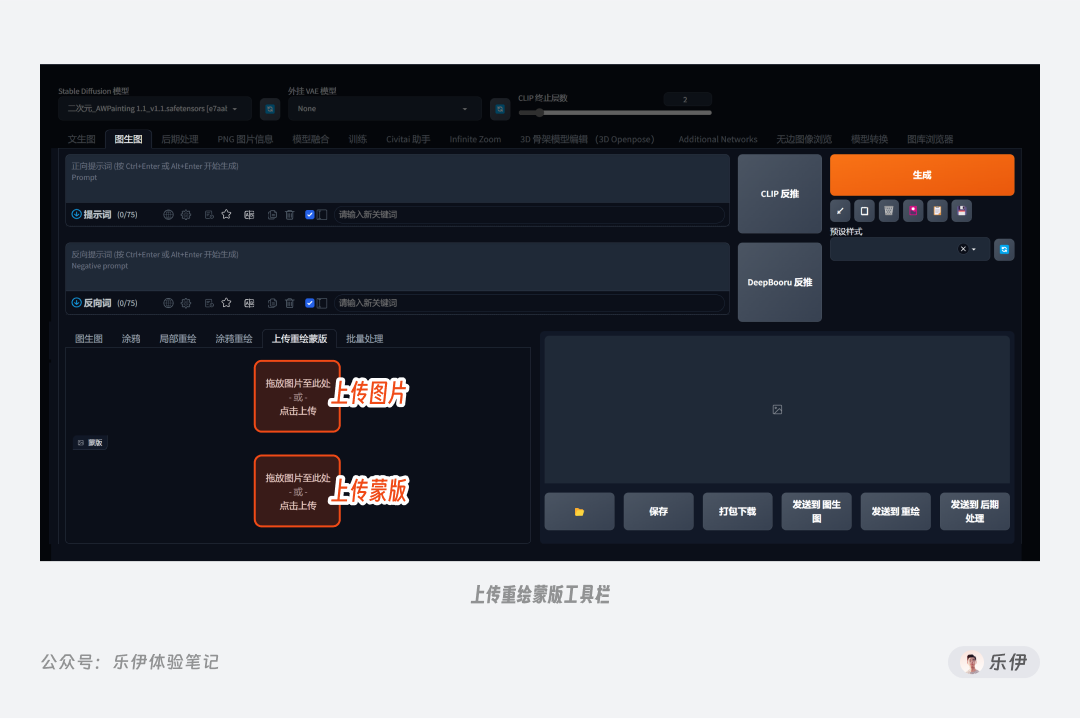
这里蒙版图片的颜色含义和PS中的蒙版相同,白色表示有内容,黑色表示为空,因此白色区域内的图像会被进行重绘。相信很多朋友都出现过黑白蒙版傻傻分不清楚的情况,这里给大家分享个小妙招。我们只要将蒙版图想象成黑板即可,黑色表示默认的空白,白色即粉笔填充后的内容。
需要注意的是,在Stable Diffusion中表示半透明蒙版的灰色并不适用,因此像黑白渐变的蒙版图不起效果,我们平时用黑白纯色即可。

上传蒙版的优势在于我们可以精准控制蒙版范围,通常在PS中进行抠图并填充成黑白蒙版图,再上传到Stable Diffusion中进行使用。
2.8 批量处理工具
最后还有个批量处理工具,顾名思义可以批量对图像进行重绘操作。只需设置到相关参数和提示词,设置到参考图文件夹和输出文件夹就能实现批量重绘。我们平时在抖音上看到那种用拍摄视频转换AI绘图视频也是同样的原理,通过将视频拆解成逐帧图片再进行重绘,但目前开源社区中有用于制作动态视频更好用的插件,这里就不再赘述了。
关于图生图的更多知识
由于各款工具的名称都比较相似,加上不同功能项的调节参数和使用方法都不同,新手在学习图生图模块时很容易把各类功能弄混淆。因此,在学习这类AI绘画工具时,我更建议大家按照下面重绘应用方向的思路来理解,而不是单纯的从工具角度学习。
3.1 重绘的3个应用方向
我们前面提到图生图的本质是进行图像的二次重绘,根据绘制区域的差异,可以将重绘功能划分为整体重绘、局部重绘和图像扩展三个方向:
-
整体重绘 Img2img:按照原图的比例进行整体重绘,即传统意义上的基于参考图进行图生图,需要注意的是图像比例不变,但尺寸可以等比例调整。
-
局部重绘 Inpaint:通过手动涂鸦或上传蒙版等方法控制只针对指定区域进行重新绘制。
-
图像拓展 Outpaint:在原画布尺寸基础上向其他方向拓展,添加更多原画布外的内容。
回过头来看,文生图、图生图、涂鸦都相当于整体重绘功能,而局部重绘、涂鸦重绘和上传重绘蒙版则是局部重绘功能,至于图像扩展则是在图像比例发生变化且缩放模式选择填充时启用。

我们横向对比其他工具来看,整体重绘、局部重绘和图像扩展可以说是所有图像处理工具的基础功能,毕竟可控性在商业领域的价值很多时候比创意性更加重要,而可以将两者结合起来灵活使用的AI绘画工具才称得上是行业翘楚。这也是为什么PS的创意生成和画布拓展绘制功能刚一推出就引起广泛热议,而像Midjourney近期更新的Zoom Out图像扩展和Vary(Region)局部重绘等功能同样也是在向控图稳定性方向发展。

3.2 图生图中的提示词
前面提到图生图本质是增加了参考图的约束,虽然提示词的信息权重被参考图削弱了一部分,但并不意味着提示词就没用了。相反,很多时候还是需要通过提示词来告诉Stable Diffusion我们希望绘制的内容。这时候有朋友会问,那我们是只填写需要重绘部分的内容还是将画面全部内容进行完整描述呢?其实,图生图的提示词填写要根据实际的出图效果来调整。
当我们只希望更改画面中的部分元素而其他部分不变时,就需要在提示词中将不更改的部分进行保留,并对修改部分进行调整或补充描述,为了保证出图效果还可以灵活增加对应关键词的权重。
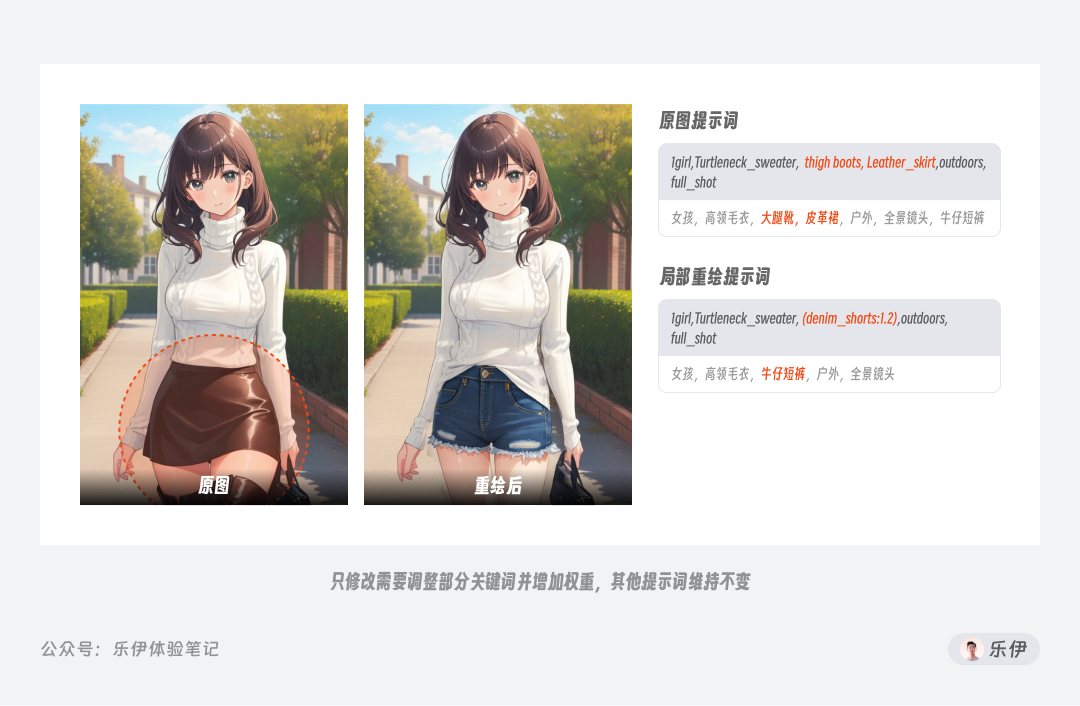
而当局部重绘时,如果绘制部分和原有图像的融合效果不佳,我们可以增加蒙版部分之外的内容描述来加强和画面其他部分的联系,比如下面的图中通过交互动作来增加重绘后手部和环境的融合效果。
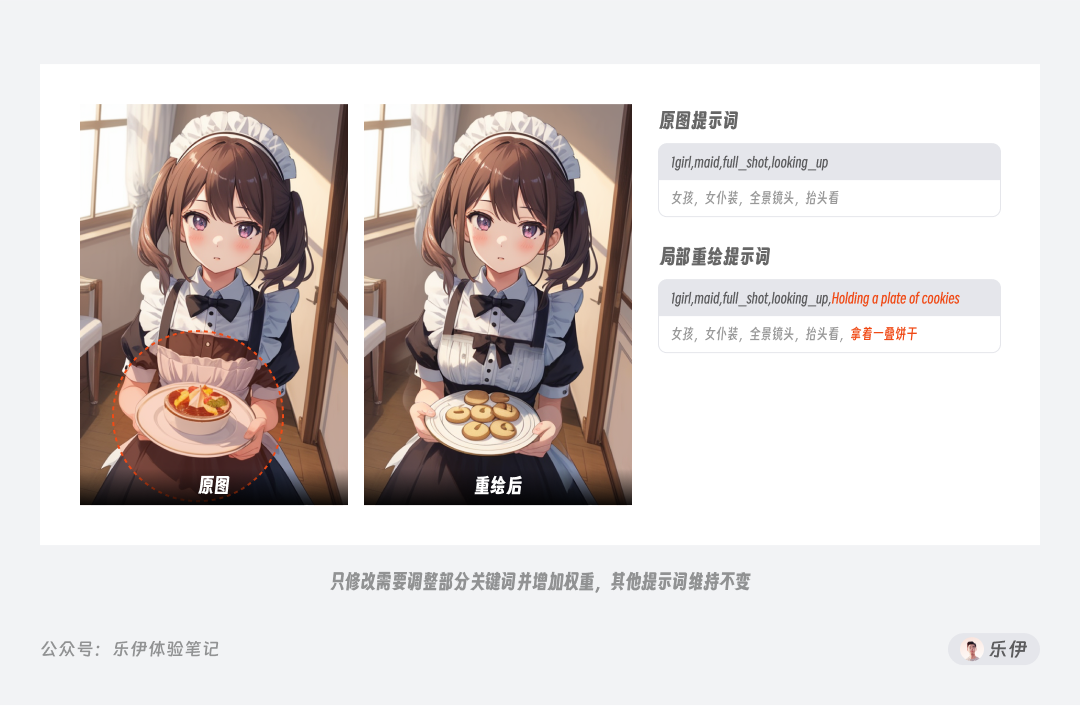
以上案例只针对提示词进行了调整,实际使用时像seed值、重绘幅度、绘图模型等因素也要进行灵活考虑。
3.3 图生图和高清修复
如果有仔细观察的小伙伴应该已经发现了,图生图中并没有提供文生图中的高清修复选项,这是因为高清修复的本质就是进行了一次额外图生图操作,同样是先生成小图再进行放大,所以在图生图中想实现高清修复,只需将图像尺寸调大进行重绘即可,此外高清修复这一特性在图生图中有更多使用场景。
不知道大家平时是否发现过这样的现象,当人物在画面中占比越小,出图结果中出现脸部崩坏的情况就越常见,而当对人物脸部特写时很少出现崩坏情况。这是因为Stable Diffusion模型在逆向扩散的过程中对大区域的图像去噪处理会更加清晰,因此更擅长绘制画面中占比大的事物,通过利用这一点我们可以将图像中不清晰的小图截取出来进行放大重绘,然后再放回原图位置,即可有效修复局部变形的情况。
在今天文章里,我为大家介绍了Stable Diffusion中图像重绘的作用、各类工具和参数的功能解析以及关于图像重绘的学习思路。相比于文生图的一步成型,图生图更多是碎片化的使用思路,需要通过不断的修饰和调整局部细节来得到我们想要的图片。
回顾近几篇的文章内容,从文生图到图生图,从局部重绘再到上传重绘蒙版,不难发现我们对Stable Diffusion的学习是从发散向可控的方向逐渐递进,而聊到可控性就不得不提Stable Diffusion中大名鼎鼎的ControlNet,在下篇文章中我会为你详细介绍这款真正让Stable Diffusion立足AI绘画之巅的神级插件。今天文章就到这里结束啦,我们下期再见
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

