
- 1计算机辅助教学在教育教学中有哪些作用,计算机辅助教学在课堂中的应用
- 2【PyQt5】Python在PyQt5中使用ECharts绘制图表
- 3vue+element作用域插槽_el-tree slot
- 4mysql添加datetime字段_添加DATE和TIME字段以在MySQL中获取DATETIME字段?
- 5ubuntu16.04系统gcc下降和升级_ubuntu 升级gcc
- 6如何解决国标GB28181视频平台EasyGBS运行中端口不够用的情况?_视频控制器输出口不够如何解决
- 7微信小程序接入阿里云直播_小程序嵌入三方直播需要什么条件
- 8ROS | ROS机器人开发案例(古月)学习
- 9鸿蒙 DevEco-Studio 运行报错 Error while Deploying HAP_deveco error while deploying hap
- 10ios学习临时笔记-NSLocalizedString使用_nslocalizedstring 调用
使用CNN和经过判别式训练的域变换进行任务特定边缘检测的语义图像分割——Semantic Image Segmentation with Task-Specific Edge Detection Us_dtvgg
赞
踩
0.摘要
深度卷积神经网络(CNNs)是最先进的语义图像分割系统的基础。最近的研究表明,将CNNs与全连接的条件随机场(CRFs)结合可以显著提高目标定位的准确性,然而密集CRF推理计算代价很高。我们提出用域变换(DT)替代全连接的CRF,域变换是一种现代的边缘保持滤波方法,其平滑程度由参考边缘图控制。域变换滤波比密集CRF推理快几倍,并且我们证明它产生可比较的语义分割结果,准确地捕捉物体边界。重要的是,我们的公式允许从中间CNN特征中学习参考边缘图,而不是像标准的DT滤波那样使用图像梯度幅度。这样可以在端到端可训练的系统中产生任务特定的边缘,优化目标语义分割质量。
1.引言
深度卷积神经网络(CNNs)在语义图像分割中非常有效,即为图像中的每个像素分配语义标签的任务。最近的研究表明,用全连接的CRF对CNN的输出进行后处理可以显著提高靠近物体边界的分割准确性[5]。如[26]所解释的那样,全连接CRF模型中的均值场推理相当于对双边滤波器的迭代应用,双边滤波器是一种常用的边缘感知滤波技术。这鼓励将在位置和颜色上相邻的像素分配相同的语义标签。实际上,这产生了与图像中的物体边界对齐的语义分割结果。采用全连接CRF的一个关键障碍是底层双边滤波步骤的计算成本相对较高。双边滤波器在5维双边(2维位置,3维颜色)空间中相当于高维高斯滤波,即使使用先进的算法技术,也在内存和CPU时间方面代价高昂。在本文中,我们提出用域变换(DT)[16]替换全连接CRF及其相关的双边滤波器,这是一种替代的边缘感知滤波器。域变换的递归公式相当于对信号的自适应递归滤波,其中不允许信息在某个参考信号的边缘上传播。这导致了一种极其高效的方案,其速度比具有相同质量的双边滤波器的最快算法快一个数量级。域变换也可以等效地看作是一种递归神经网络(RNN)。特别地,我们展示了域变换是最近提出的带门控循环单元的RNN的特例。这种联系使我们能够共享见解,更好地理解这两种看似不同的方法,正如我们在第3.4节中解释的那样。
域变换中的平滑程度由参考边缘图在空间上调制,而在标准域变换中,参考边缘图对应于图像梯度幅度。相反,我们将从产生语义分割分数的相同CNN的中间层特征中学习参考边缘图,如图1所示。关键是,这使我们能够在端到端可训练的系统中学习一个针对语义图像分割调整的任务特定边缘检测器。我们在具有挑战性的PASCAL VOC 2012语义分割任务上评估了所提出方法的性能。在这个任务中,域变换滤波比密集CRF推理快几倍,而在平均交并比(mIOU)指标方面的表现几乎和密集CRF推理一样好。此外,尽管我们只训练了语义分割,但学习到的边缘图在BSDS500边缘检测基准上的表现也具有竞争力。

图1. 一个统一的CNN同时生成粗糙的语义分割分数和边缘图,分别作为多通道图像的输入和域变换边缘保持滤波器的参考边缘。滤波后的语义分割分数与物体边界很好地对齐。完整的架构通过反向传播(红色虚线箭头)进行判别式训练,以优化目标语义分割。
2.相关工作
语义图像分割中的深度卷积神经网络(CNNs)已经在语义图像分割任务上展现出了出色的性能。然而,由于使用了最大池化层和下采样,这些网络的输出往往具有定位不准确的物体边界。为了解决这个问题,已经采用了几种方法。[31,19,5]提出从深度网络的中间层提取特征以更好地估计物体边界。[45,33]提出了使用反卷积层和反池化层来恢复最大池化层的“空间不变性”效果的网络。[14,32]使用超像素表示,实际上是利用低级分割方法来定位任务。全连接条件随机场(CRF)[26]已经应用于捕捉像素之间的长程依赖性,在[5,28,30,34]中取得了进一步的改进。当通过CRF进行反向传播以细化分割CNN时,在[46,38]中展示了更好的性能。相反地,我们采用了基于域变换[16]的另一种方法,并展示了除了对分割CNN进行改进之外,我们还可以同时学习检测物体边界,将任务特定的边缘检测嵌入到所提出的模型中。
边缘检测边缘/轮廓检测任务有着悠久的历史[25,1,11],我们只简要回顾一下。最近,一些研究通过使用CNNs [2,3,15,21,39,44]在边缘检测任务上取得了出色的性能。我们的工作与[44,3,24]的工作最相关。Xie和Tu [44]也利用了深层网络[40]中间层的特征进行边缘检测,但他们没有将学习到的边缘应用于语义图像分割等高级任务。另一方面,Bertasius等人[3]和Kokkinos [24]利用学习到的边界来提高语义图像分割的性能。然而,边界检测和语义图像分割被认为是两个独立的任务。他们优化了边界检测的性能,而不是高级任务的性能。相反,我们学习对象边界,以直接优化语义图像分割的性能。
具有长短期记忆(LSTM)单元[20]或门控循环单元(GRUs)[8,9]的循环神经网络(RNNs)已经被证明对于建模序列数据(例如文本和语音)中的长期依赖关系非常成功。Sainath等人[37]将CNNs和RNNs结合成一个统一的架构用于语音识别。一些最近的工作尝试使用循环网络来建模计算机视觉任务中的空间长期依赖性[17,41,35,4,43]。我们的工作将CNNs和域变换(DT)与递归滤波[16]相结合,与ReNet [43]有一定的相似之处,它在水平和垂直方向上都执行递归操作以捕捉整个图像中的长期依赖关系。在这项工作中,我们展示了DT和GRU之间的关系,并证明了通过DT利用长期依赖性对语义图像分割的有效性。虽然[42]先前采用了DT(用于联合对象-立体标记),但我们提出通过DT的两个输入进行反向传播,以共同学习分割分数和边缘图的端到端可训练系统。我们展示了与[42]或早期的DT文献[16]中使用的标准图像梯度幅度相比,这些学习到的边缘图带来了显著的改进。
3.提出的模型
3.1.模型概述
我们提出的模型由三个组件组成,如图2所示。它们被联合训练,以优化输出的语义分割质量。第一个组件是基于公开可用的DeepLab模型[5]的粗糙语义分割评分预测。DeepLab修改了VGG-16网络[40]以成为FCN [31]。该模型从VGG-16 ImageNet [36]预训练模型初始化。我们采用了[5]的DeepLab LargeFOV变体,它在滤波器中引入零以扩大其视野,我们简称为DeepLab。我们添加了第二个组件,称为EdgeNet。EdgeNet通过利用DeepLab的中间层特征来预测边缘。在连接之前,通过双线性插值将特征调整为相同的空间分辨率。使用1×1的卷积层和一个输出通道来生成边缘预测。使用ReLU函数使得边缘预测值在零到正无穷的范围内。我们系统中的第三个组件是域变换(DT),它是一种边缘保留滤波器,通过在行和列之间进行可分离的一维递归滤波,非常高效。虽然DT传统上用于图形应用[16],但我们使用它来过滤原始的CNN语义分割得分,以更好地与对象边界对齐,由EdgeNet生成的边缘图进行引导。
在第3.2节中,我们回顾了标准的DT方法,然后在第3.3节中将其扩展为一个完全可训练的系统,其中包括学习到的边缘检测。最后,在第3.4节中,我们讨论了与最近提出的门控循环单元网络的联系。
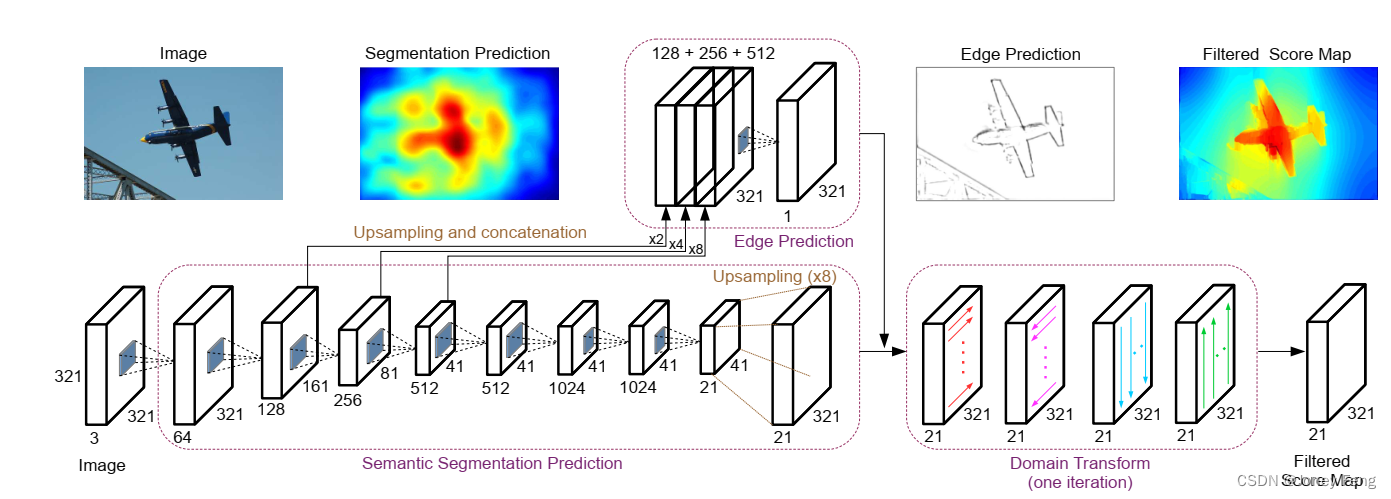
图2.我们提出的模型有三个组件:(1)用于语义分割预测的DeepLab,(2)用于边缘预测的EdgeNet,以及(3)用于准确对齐分割得分与对象边界的域变换。EdgeNet重用了来自DeepLab中间层的特征,这些特征在边缘预测之前经过调整大小和连接。域变换接收原始的分割得分和边缘图作为输入,并在行和列之间进行递归滤波,产生最终的滤波分割得分。
3.2.具有递归滤波的域变换
域变换接受两个输入:(1)要进行滤波的原始输入信号x,在我们的情况下对应于粗糙的DCNN语义分割得分,以及(2)一个正的“域变换密度”信号d,我们在下一节中会详细讨论其选择。域变换的输出是一个滤波后的信号y。我们将使用递归的形式来实现域变换,因为它具有速度和效率,尽管该滤波器也可以通过其他技术来应用[16]。对于长度为N的1-D信号,输出的计算方式为设置y1 = x1,然后逐步递归计算i = 2,...,N。
权重wi取决于域变换密度di。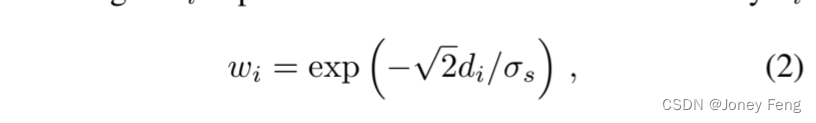 其中,σs是滤波器核在输入空间域上的标准差。直观地说,域变换密度di ≥0的强度通过控制在计算当前位置yi的滤波信号时,原始输入信号xi对前一位置yi−1的贡献相对于滤波信号值的扩散/平滑量。wi ∈(0,1)的值起到了门的作用,控制了从像素i−1传播到i的信息量。当di非常小时,我们有完全扩散,结果为wi =1和yi =yi−1。另一方面,如果di非常大,则wi =0,扩散停止,结果为yi =xi。
其中,σs是滤波器核在输入空间域上的标准差。直观地说,域变换密度di ≥0的强度通过控制在计算当前位置yi的滤波信号时,原始输入信号xi对前一位置yi−1的贡献相对于滤波信号值的扩散/平滑量。wi ∈(0,1)的值起到了门的作用,控制了从像素i−1传播到i的信息量。当di非常小时,我们有完全扩散,结果为wi =1和yi =yi−1。另一方面,如果di非常大,则wi =0,扩散停止,结果为yi =xi。
根据公式(1)进行滤波是不对称的,因为当前输出仅取决于先前的输出。为了克服这种不对称性,我们对1-D信号进行两次滤波,首先从左到右,然后从右到左,得到从左到右传递的输出。对于2-D信号的域变换滤波以可分离的方式进行,沿着每个信号维度顺序地进行1-D滤波。也就是说,在每一行上进行水平传递(从左到右和从右到左),然后在每一列上进行垂直传递(从上到下和从下到上)。在实践中,两次1-D滤波处理的K >1次迭代可以抑制由于对2-D信号进行1-D滤波而产生的“条纹”伪影[16,图4]。我们在每次迭代中减小DT滤波核的标准差,要求总方差的和等于所需的方差σ2s,按照[16,公式14]的方法进行。
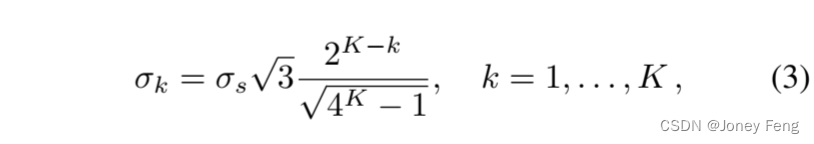 在第k次迭代中,通过在公式(2)中将σk代替σs来计算权重wi。域变换密度值di定义如下:
在第k次迭代中,通过在公式(2)中将σk代替σs来计算权重wi。域变换密度值di定义如下: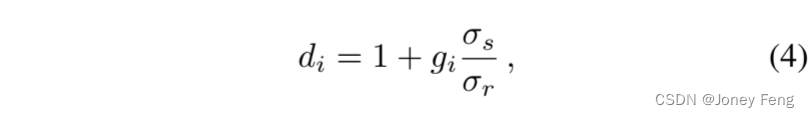 其中,gi ≥0是“参考边缘”,σr是在参考边缘图的范围上的滤波器核的标准差。需要注意的是,gi的值越大,模型认为像素i处存在强边缘的信心就越大,从而抑制扩散(即di →∞和wi =0)。标准的DT [16]通常使用彩色图像梯度。
其中,gi ≥0是“参考边缘”,σr是在参考边缘图的范围上的滤波器核的标准差。需要注意的是,gi的值越大,模型认为像素i处存在强边缘的信心就越大,从而抑制扩散(即di →∞和wi =0)。标准的DT [16]通常使用彩色图像梯度。 但我们接下来将展示,通过使用经过训练的深度卷积神经网络(DCNN)计算参考边缘图可以获得更好的结果。
但我们接下来将展示,通过使用经过训练的深度卷积神经网络(DCNN)计算参考边缘图可以获得更好的结果。

图3.域变换递归滤波的计算树:(a)前向传递。从yi节点向上箭头表示向后续层的馈送。(b)后向传递,包括来自后续层的贡献∂y/∂Li。
3.3.可训练的域变换滤波
我们提出方法的一个新颖方面是通过DT将DT输出y的分割误差反向传播到其两个输入。这使我们能够将DT作为CNN中的一层使用,从而使我们能够共同学习在x中计算粗分割得分图和在g中计算参考边缘图的DCNN。我们展示了如何通过DT反向传播来完成公式(1)的1-D滤波过程,其前向传递如图3(a)中的计算树所示。我们假设每个节点yi不仅影响后续节点yi+1,还馈送到后续层,因此在反向传播过程中还会接收来自该层的梯度贡献∂L/∂yi。类似于标准的时域反向传播,我们将公式(1)的递归展开反向传播,如图3(b)所示,对i = N,...,2进行更新关于y的导数,并计算关于x和w的导数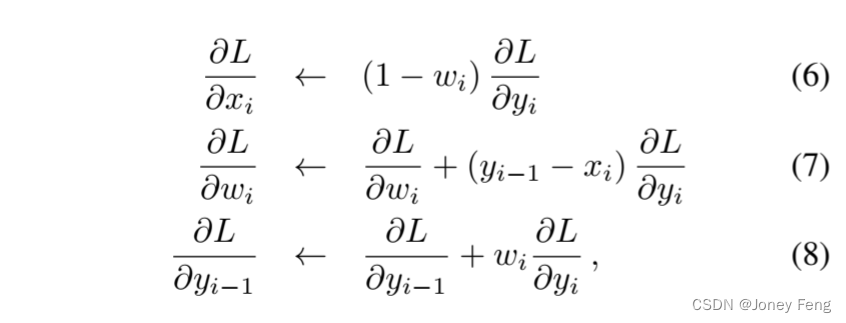 其中,∂L/∂xi和∂w/∂Li被初始化为0,而∂y/∂Li最初设置为后续层发送的值。需要注意的是,权重wi在所有滤波阶段(即水平传递中的从左到右/从右到左和垂直传递中的从上到下/从下到上)和K次迭代中是共享的,每次传递都对偏导数有贡献。利用这些偏导数,我们可以得到关于参考边缘gi的导数。将公式(4)代入其中。
其中,∂L/∂xi和∂w/∂Li被初始化为0,而∂y/∂Li最初设置为后续层发送的值。需要注意的是,权重wi在所有滤波阶段(即水平传递中的从左到右/从右到左和垂直传递中的从上到下/从下到上)和K次迭代中是共享的,每次传递都对偏导数有贡献。利用这些偏导数,我们可以得到关于参考边缘gi的导数。将公式(4)代入其中。 然后,根据链式法则,关于gi的导数是
然后,根据链式法则,关于gi的导数是 这个梯度进一步传播到生成边缘预测并用作DT输入的深度卷积神经网络上。
这个梯度进一步传播到生成边缘预测并用作DT输入的深度卷积神经网络上。
3.4.与门控循环单元网络的关系
公式1将DT滤波定义为递归操作。将其与其他最近的RNN形式建立联系是有趣的。在这里,我们与最近提出的用于建模序列文本数据的门控循环单元(GRU)RNN架构[8]建立了精确的联系。GRU采用了更新规则。

与公式(1)进行比较,我们可以将GRU的“更新门”zi和“候选激活”y˜i与DT的权重和原始输入信号联系起来,如下所示:zi =1 −wi和y˜i =xi。GRU的更新门zi定义为zi =σ(fi),其中fi是一个激活信号,σ(t)=1/(1+e−t)。与公式(9)进行比较可以得到DT参考边缘图gi和GRU激活fi之间的直接对应关系。

4.实验评估
4.1.实验协议

4.2.实验结果
我们首先在验证集上探索了提出模型的超参数,包括(1)用于EdgeNet的特征,(2)用于域变换的超参数(即迭代次数、σs和σr)。我们还尝试了不同的方法来生成边缘预测。之后,我们对模型进行分析,并在官方测试集上进行评估。 EdgeNet的特征 我们所使用的EdgeNet利用了来自DeepLab的中间特征。我们首先研究了在DT超参数固定的情况下,哪些VGG-16 [40]层在性能上表现更好。如表1所示,基准DeepLab在PASCAL VOC 2012验证集上获得了62.25%的mIOU。我们开始利用来自conv3 3的特征,其感受野大小为40。这个大小与通常用于边缘检测的块大小相似[11]。结果模型的性能达到了65.64%,比基准模型提高了3.4%。当使用来自conv2 2、conv3 3和conv4 3的特征时,性能进一步提高到了66.03%。然而,如果还利用来自conv1 2或conv5 3的特征,我们并没有观察到明显的改善。在涉及EdgeNet的其他实验中,我们使用来自conv2 2、conv3 3和conv4 3的特征。 域变换迭代次数 域变换需要多次迭代进行双通道一维滤波过程,以避免“条纹”效应[16,图4]。我们在域变换中使用K次迭代训练提出的模型,并在测试过程中执行相同的K次迭代。由于还有两个超参数σs和σr(参见公式(9)),我们也改变它们的值来研究变化的K次迭代对域变换的影响。如图4所示,在我们提出的模型中使用K=3次迭代对于多个不同的σs和σr值来说已经足够获得大部分收益。
不同的σs和σr值的影响。变化的域变换σs、σr和与其他边缘检测器的比较 我们研究了变化σs和σr对域变换的影响。我们还比较了用于域变换的替代方法的边缘预测效果:(1)DT-Oracle,使用真实的对象边界作为上界,这是我们方法的一个上界。(2)所提出的DT-EdgeNet,其中边缘由EdgeNet生成。(3)DT-SE,其中边缘由Structured Edges (SE)[11]找到。(4)DT-Gradient,其中使用公式(5)的图像(颜色)梯度幅度,与标准域变换[16]相同。我们寻找这些方法的最佳σs和σr值。首先,我们固定σs = 100,变化σr如图5(a)所示。我们发现,DT-Oracle、DT-SE和DT-Gradient的性能在不同的σr值下受到很大影响,因为它们是由其他“插入”模块生成的(即没有进行联合微调)。我们还展示了基准DeepLab和使用密集CRF的DeepLab-CRF的性能。然后,我们固定找到的最佳σr值,变化σs如图5(b)所示。我们发现,只要σs ≥ 90,DT-EdgeNet、DT-SE和DT-Gradient的性能变化不大。在找到每个设置的最佳σr和σs值后,我们将它们用于剩余的实验。我们在图6中进一步可视化了我们的DT-EdgeNet学习到的边缘。如第一行所示,当σr增加时,学习到的边缘开始包括对象边界和背景纹理,这会降低我们方法在语义分割中的性能(即噪声边缘使得在相邻像素之间传递信息变得困难)。如第二行所示,变化的σs并不会对学习到的边缘产生很大的影响,只要其值足够大(即≥90)。
我们在表2中展示了每种方法在验证集上的性能(使用最佳的σs和σr值)。DT-Gradient方法相比基准DeepLab提高了1.7%的性能。虽然DT-SE比DT-Gradient好0.9%,但DT-EdgeNet进一步提升了性能,比基准方法提高了4.1%。尽管DT-EdgeNet比DeepLab-CRF低1.2%,但它的速度快几倍,这一点我们稍后会讨论。此外,我们发现将DT-EdgeNet和密集CRF相结合可以获得最佳性能,比DeepLab-CRF提高了0.8%。在这种混合的DT-EdgeNet+DenseCRF方案中,我们对DT滤波得到的分数图进行额外的全连接CRF后处理。与[23,26,5]类似,我们对提出的模型在目标边界附近的准确性进行了量化。我们使用PASCAL VOC 2012验证集上标注的“void”标签。这些注释通常对应于目标边界。我们计算了位于“void”标签狭窄带(称为trimap)内的像素的平均IOU,并随着带宽的变化进行了展示,如图7所示。我们在图9中展示了一些PASCAL VOC 2012验证集上的语义分割结果。DT-EdgeNet在视觉上比基准DeepLab和DT-SE有所改进。此外,当比较Structured Edges和我们的EdgeNet学习到的边缘时,我们发现EdgeNet更好地捕捉到了目标外部边界,并对内部边缘的响应较少。我们还在图9的底部两行展示了一些失败案例。第一个是由于DeepLab的错误预测,第二个是由于在杂乱的背景中难以定位目标边界。
在找到最佳超参数后,我们在测试集上评估了我们的模型。如表4顶部所示,DT-SE相比基准DeepLab提高了2.7%,而DT-EdgeNet进一步提高了性能,达到69.0%(比基准提高了3.9%),这比使用全连接CRF进行后处理(即DeepLab-CRF)平滑结果略低1.3%。然而,如果我们还将全连接CRF作为后处理加入到我们的模型中,我们可以进一步提高性能至71.2%。使用MS-COCO预训练的模型我们还进行了另一个实验,使用[34]中更强的基线,即DeepLab在MS-COCO 2014数据集[29]上进行了预训练。我们的目标是测试我们的方法是否能在这个更强的基线上获得改进。我们使用与之前相同的超参数最优值,并在验证集上报告结果,如表3所示。我们仍然观察到DT-SE和DT-EdgeNet分别比基准提高了1.6%和2.7%。此外,将全连接CRF添加到DT-EdgeNet可以带来额外的1.8%的改进。然后我们在表4底部对模型进行了测试。我们最好的模型DT-EdgeNet相对于基准DeepLab提高了2.8%,但比DeepLab-CRF低1.0%。当将DT-EdgeNet和全连接CRF结合起来时,我们在测试集上达到了73.6%的性能。需要注意的是,在使用更强的基线时,DT-EdgeNet和DeepLab-CRF之间的差距变小了。结合多尺度输入PASCAL VOC 2012排行榜上的最先进模型通常使用多尺度特征(无论是多尺度输入[10,28,7]还是DCNN的中间层特征[31,19,5])。受此启发,我们进一步将我们提出的经鉴别训练的域变换和[7]的模型结合,测试集上的性能达到76.3%,比当前最好的模型[28](联合训练CRF和DCNN)稍低1.5%。
在BSDS500测试集上进一步评估我们学习到的EdgeNet的边缘检测性能。我们使用标准指标来评估边缘检测的准确性:固定轮廓阈值(ODS F分数)、每张图像最佳阈值(OIS F分数)和平均精度(AP)。我们还对EdgeNet生成的边缘图应用了标准的非极大值抑制技术进行评估。我们的方法在ODS为0.718,OIS为0.731,AP为0.685。如图8所示,有趣的是,我们的EdgeNet在性能上表现相当不错(在ODS F分数方面仅比Structured Edges [11]差3%),而我们的EdgeNet并没有在BSDS500上进行训练,并且在PASCAL VOC 2012的训练过程中没有边缘监督。 与密集CRF的比较 使用全连接CRF是改善分割性能的有效方法。我们的最佳模型(DT-EdgeNet)在使用ImageNet或MS-COCO进行预训练时,在PASCAL VOC 2012测试集上比DeepLab-CRF低1.3%和1.0%。然而,我们的方法在计算时间方面要快得多。为了量化这一点,我们对50个PASCAL VOC 2012验证图像进行了推理计算的计时。如表5所示,在CPU计时方面,在一台搭载Intel i7-4790K CPU的机器上,经过10次均值场迭代的优化良好的密集CRF实现[26]每张图像需要830毫秒,而我们的域变换实现的K=3次迭代(每次迭代由行和列的可分离双通滤波组成)每张图像需要180毫秒(快了4.6倍)。在一块NVIDIA Tesla K40 GPU上,我们的域变换GPU实现进一步将平均计算时间降低到每张图像25毫秒。在我们的GPU实现中,所提出方法(EdgeNet+DT)的总计算成本为每张图像26.2毫秒,与DeepLab所需的145毫秒相比,增加了适度的开销(约18%)。需要注意的是,目前还没有公开可用的GPU实现密集CRF推理。

图4. VOC 2012验证集。域变换迭代次数变化的效果:(a)固定σs,变化σr和K的迭代次数。(b)固定σr,变化σs和K的迭代次数。
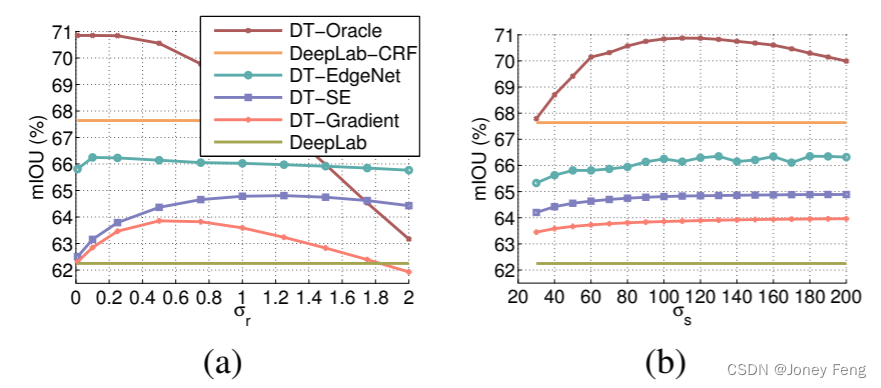 图5. VOC 2012验证集。σs和σr的变化效果。(a)固定σs = 100,变化σr。(b)使用(a)中最佳的σr,变化σs。
图5. VOC 2012验证集。σs和σr的变化效果。(a)固定σs = 100,变化σr。(b)使用(a)中最佳的σr,变化σs。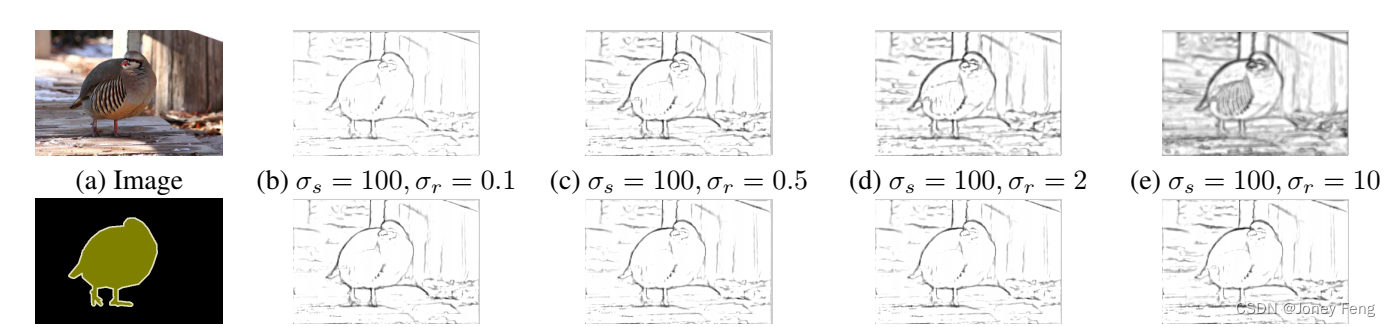
图6. 域变换的σs和σr的变化效果。第一行:当固定σs并增加σr时,EdgeNet开始包括更多的背景边缘。第二行:当固定σr时,改变σs对学习到的边缘几乎没有影响。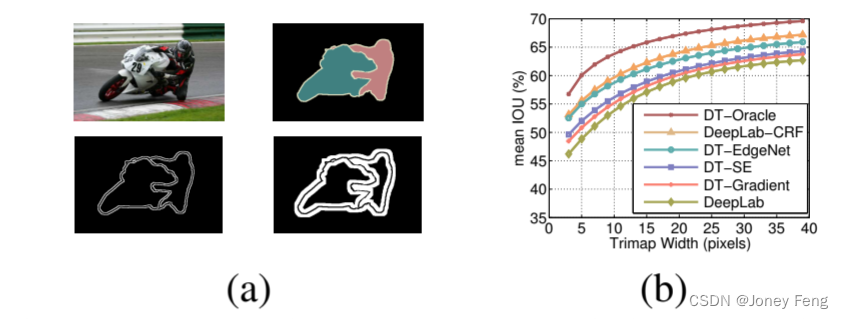 图7. (a)一些trimap示例(左上角:图像。右上角:真值。左下角:2像素的trimap。右下角:10像素的trimap)。(b)在对象边界周围的带状区域内的分割结果(平均IOU)
图7. (a)一些trimap示例(左上角:图像。右上角:真值。左下角:2像素的trimap。右下角:10像素的trimap)。(b)在对象边界周围的带状区域内的分割结果(平均IOU)
表2. PASCAL VOC 2012验证集上的性能。
表3. PASCAL VOC 2012验证集上的性能。这些模型已经在MS-COCO 2014数据集上进行了预训练。
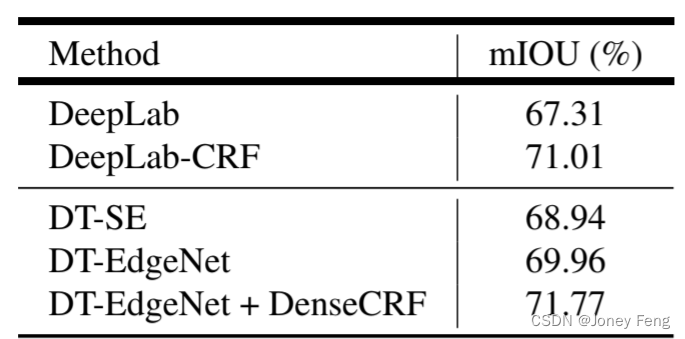
表4. PASCAL VOC 2012测试集上的平均IOU(%)。我们使用两种设置评估我们的模型:(1)在ImageNet上进行预训练,和(2)在MS-COCO上进一步进行预训练。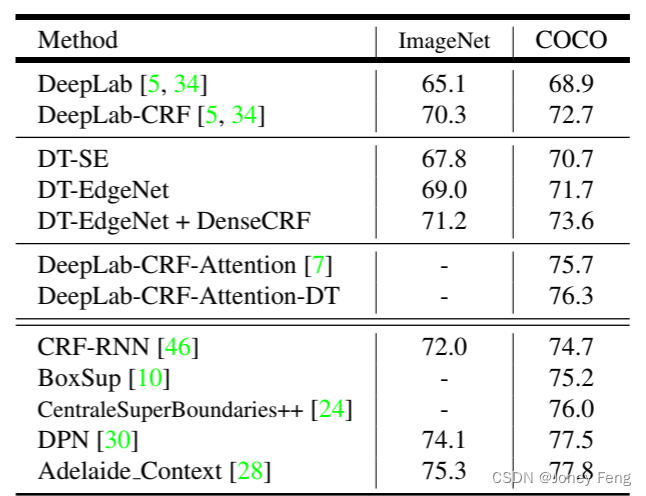
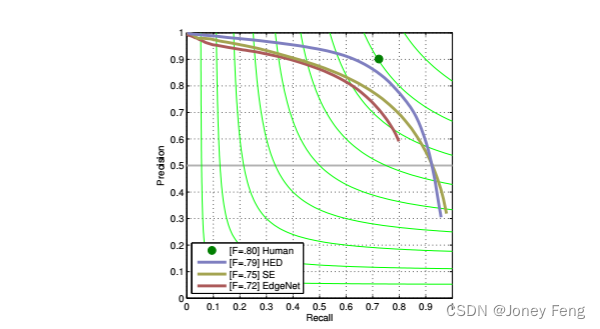
图8. 对BSDS500测试集上我们学习到的EdgeNet的评估。需要注意的是,我们的EdgeNet仅在PASCAL VOC 2012语义分割任务上进行了训练,没有进行边缘监督。
表5. 平均推理时间(毫秒/图像)。括号中的数字是相对于DeepLab计算的百分比。需要注意的是,通过先进行卷积然后上采样,EdgeNet的计算时间得到了改善。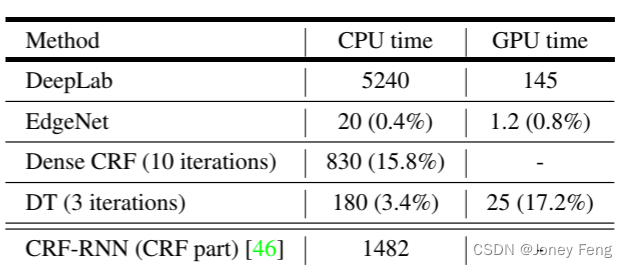
 图9. 在VOC 2012验证集上展示结果。对于每一行,我们展示了(a)图像,(b)基线DeepLab的分割结果,(c)由Structured Edges生成的边缘,(d)使用Structured Edges的分割结果,(e)由EdgeNet生成的边缘,(f)使用EdgeNet的分割结果。需要注意的是,我们的EdgeNet更好地捕捉到了对象边界,并对背景或对象内部的边缘反应较小。例如,在第一张图像中,可以看到左侧第二个人的腿部或第二张图像中的狗的形状。底部的两个失败示例。
图9. 在VOC 2012验证集上展示结果。对于每一行,我们展示了(a)图像,(b)基线DeepLab的分割结果,(c)由Structured Edges生成的边缘,(d)使用Structured Edges的分割结果,(e)由EdgeNet生成的边缘,(f)使用EdgeNet的分割结果。需要注意的是,我们的EdgeNet更好地捕捉到了对象边界,并对背景或对象内部的边缘反应较小。例如,在第一张图像中,可以看到左侧第二个人的腿部或第二张图像中的狗的形状。底部的两个失败示例。
5.结论
我们提出了一种学习边缘图的方法,该方法在一个统一的系统中以端到端的方式进行鉴别训练,对语义图像分割具有实用价值。所提出的方法基于域变换,这是一种传统用于图形应用的保边滤波器。我们展示了通过对域变换进行反向传播,可以学习到针对语义分割进行优化的任务特定边缘图。将深度完全卷积网络生成的原始语义分割图与我们学习到的域变换进行滤波,可以提高对象边界附近的定位准确性。与之前用于此目的的全连接CRF相比,得到的方案速度提高了几倍。
6.参考文献
[1] P.Arbelaez,M.Maire,C.Fowlkes,and J.Malik."轮廓检测和分层图像分割",PAMI,2011年5月。
[2] G.Bertasius,J.Shi,and L.Torresani."Deepedge:一种用于自上而下轮廓检测的多尺度分叉深度网络",CVPR,2015年。
[3] G.Bertasius,J.Shi,and L.Torresani."高对低和低对高:利用深度目标特征进行高级视觉的高效边界检测及其应用",ICCV,2015年。
[4] W.Byeon,T.M.Breuel,F.Raue,and M.Liwicki."使用LSTM循环神经网络进行场景标注",CVPR,2015年。
[5] L.-C.Chen,G.Papandreou,I.Kokkinos,K.Murphy,and A.L.Yuille."使用深度卷积网络和完全连接的CRFs进行语义图像分割",ICLR,2015年。
[6] L.-C.Chen,A.Schwing,A.Yuille,and R.Urtasun."学习深度结构模型",ICML,2015年。
[7] L.-C.Chen,Y.Yang,J.Wang,W.Xu,and A.L.Yuille."关注尺度:尺度感知的语义图像分割",arXiv:1511.03339,2015年。
[8] K.Cho,B.van Merrienboer,D.Bahdanau,and Y.Bengio."关于神经机器翻译的属性:编码器-解码器方法",arXiv:1409.1259,2014年。
[9] J.Chung,C.Gulcehre,K.Cho,and Y.Bengio."针对序列建模的门控循环神经网络的实证评估",arXiv:1412.3555,2014年。
[10] J.Dai,K.He,and J.Sun."Boxsup:利用边界框监督卷积网络进行语义分割",ICCV,2015年。
[11] P.Dollar and C.L.Zitnick."用于快速边缘检测的结构化森林",ICCV,2013年。
[12] J.L.Elman."在时间中寻找结构",认知科学,1990年。
[13] M.Everingham,S.M.A.Eslami,L.V.Gool,C.K.I.Williams,J.Winn,and A.Zisserman."Pascal视觉对象类别挑战赛回顾",IJCV,2014年。
[14] C.Farabet,C.Couprie,L.Najman,and Y.LeCun."学习用于场景标注的分层特征",PAMI,2013年。
[15] Y.Ganin and V.Lempitsky."N4-fields:神经网络最近邻场用于图像变换",ACCV,2014年。
[16] E.S.L.Gastal and M.M.Oliveira."领域变换用于边缘感知图像和视频处理",SIGGRAPH,2011年。
[17] A.Graves and J.Schmidhuber."离线手写识别的多维循环神经网络",NIPS,2009年。
[18] B.Hariharan,P.Arbelaez,L.Bourdev,S.Maji,and J.Malik."通过反向检测器获得语义轮廓",ICCV,2011年。
[19] B.Hariharan,P.Arbelaez,R.Girshick,and J.Malik."用于对象分割和细粒度定位的超级列",CVPR,2015年。
[20] S.Hochreiter and J.Schmidhuber."长短期记忆",神经计算,1997年。
[21] J.-J.Hwang and T.-L.Liu."基于像素的深度学习轮廓检测",ICLR,2015年。
[22] Y.Jia et al."Caffe:用于快速特征嵌入的卷积体系结构",arXiv:1408.5093,2014年。
[23] P.Kohli,P.H.Torr,et al."用于强制标签一致性的鲁棒高阶势",IJCV,2009年。
[24] I.Kokkinos."使用深度学习推动边界检测的边界",ICLR,2016年。
[25] S.Konishi,A.L.Yuille,J.M.Coughlan,and S.C.Zhu."统计边缘检测:学习和评估边缘线索",PAMI,2003年。
[26] P.Krahenbuhl and V.Koltun."用高斯边缘势进行全连接CRF中的高效推理",NIPS,2011年。
[27] Y.LeCun,B.Boser,J.S.Denker,D.Henderson,R.E.Howard,W.Hubbard,and L.D.Jackel."应用于手写邮编识别的反向传播",神经计算,1989年。
[28] G.Lin,C.Shen,I.Reid,et al."用于语义分割的深度结构模型的高效分段训练",arXiv:1504.01013,2015年。
[29] T.-Y.Lin et al."Microsoft COCO:上下文中的常见对象",ECCV,2014年。
[30] Z.Liu,X.Li,P.Luo,C.C.Loy,and X.Tang."通过深度解析网络进行语义图像分割",ICCV,2015年。
[31] J.Long,E.Shelhamer,and T.Darrell."用于语义分割的全卷积网络",CVPR,2015年。
[32] M.Mostajabi,P.Yadollahpour,and G.Shakhnarovich."通过缩放特征的前馈语义分割",CVPR,2015年。
[33] H.Noh,S.Hong,and B.Han."学习反卷积网络进行语义分割",ICCV,2015年。
[34] G.Papandreou,L.-C.Chen,K.Murphy,and A.L.Yuille."弱监督和半监督学习DCNN进行语义图像分割",ICCV,2015年。
[35] P.Pinheiro and R.Collobert."用于场景标注的循环卷积神经网络",ICML,2014年。
[36] O.Russakovsky,J.Deng,H.Su,J.Krause,S.Satheesh,S.Ma,Z.Huang,A.Karpathy,A.Khosla,M.Bernstein,A.C.Berg,and L.Fei-Fei."ImageNet大规模视觉识别挑战赛",IJCV,2015年。
[37] T.N.Sainath,O.Vinyals,A.Senior,and H.Sak."卷积,长短期记忆,完全连接的深度神经网络",ICASSP,2015年。
[38] A.G.Schwing and R.Urtasun."完全连接的深度结构网络",arXiv:1503.02351,2015年。
[39] W.Shen,X.Wang,Y.Wang,X.Bai,and Z.Zhang."Deepcon tour:一种通过正共享损失学习的深度卷积特征进行轮廓检测",CVPR,2015年。
[40] K.Simonyan and A.Zisserman."用于大规模图像识别的非常深的卷积网络",ICLR,2015年。
[41] R.Socher,B.Huval,B.Bath,C.D.Manning,and A.Y.Ng."用于3D对象分类的卷积递归深度学习",NIPS,2012年。
[42] V.Vineet,J.Warrell,and P.H.Torr."基于过滤器的均值场推理用于具有高阶项和乘积标签空间的随机场",IJCV,2014年。
[43] F.Visin,K.Kastner,K.Cho,M.Matteucci,A.Courville,and Y.Bengio."ReNet:基于循环神经网络的卷积网络的替代方案",arXiv:1505.00393,2015年。
[44]谢帅和屠子堂.全面嵌套边缘检测.在ICCV,2015年.
[45]M.D. Zeiler,G.W. Taylor和R. Fergus.自适应去卷积网络用于中高层特征学习.在ICCV,2011年.
[46]郑声,Jayasumana,B.Romera-Paredes,V.Vineet,Z.Su,D.Du,C.Huang和P.Torr.条件随机场作为循环神经网络.在ICCV,2015年.

