
- 1TikZ作图教程图论篇:一个复杂的有向树图_tikz画图
- 2BST的后序遍历序列
- 3《Clock Domain Crossing》 翻译与理解(4)快时钟到慢时钟数据传输_快时钟采样慢时钟
- 4EmoElicitor: An Open Domain Response Generation Model with User Emotional Reaction Awareness论文翻译_t-cvae
- 5YOLOv8-ROS-noetic+USB-CAM目标检测
- 6vue中的插槽详细介绍_ant design of vue的树结构如何使用插槽
- 7android studio gradle下载_android studio官网.gradle下载
- 8ping kali的网络为什么不可达_kailping百度显示网络不可达
- 9vue3+vite的axios的封装与全局使用_vue3 项目怎么全局使用axios 不报类型错误
- 10最近邻搜索|Nearest neighbor search
【python】绘图代码模板_python画图代码
赞
踩
pandas.DataFrame.plot( )画图函数
DataFrame.plot(x=None, y=None, kind='line', ax=None, subplots=False,
sharex=None, sharey=False, layout=None,figsize=None,
use_index=True, title=None, grid=None, legend=True,
style=None, logx=False, logy=False, loglog=False,
xticks=None, yticks=None, xlim=None, ylim=None, rot=None,
xerr=None,secondary_y=False, sort_columns=False, **kwds)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
以下是DataFrame.plot()方法的参数以及它们的作用和可选值:
-
x:横轴的列名或位置索引,用于指定绘图时使用的横轴数据。 -
y:纵轴的列名或位置索引,用于指定绘图时使用的纵轴数据。 -
kind:绘图类型,可以是以下选项:'line':折线图'bar':垂直条形图'barh':水平条形图'hist':直方图'box':箱线图'kde':核密度估计图'density':与'kde'相同'area':面积图'pie':饼图'scatter':散点图'hexbin':六边形散点图
-
ax:Matplotlib Axes对象,用于在已有的图形上添加新的图层。 -
subplots:布尔值,如果为True,则为每个列绘制单独的子图。 -
sharex:布尔值,如果subplots为True,则共享x轴。 -
sharey:布尔值,如果subplots为True,则共享y轴。 -
layout:元组,用于指定子图的行列布局。 -
figsize:元组,图形的尺寸,以英寸为单位。 -
use_index:布尔值,默认为True,使用行索引作为x轴。 -
title:字符串,图形的标题。 -
grid:布尔值,控制是否显示网格线。 -
legend:布尔值或者字符串’reverse’,控制是否显示图例。 -
style:列表或字典,用于指定每列折线图的线条样式。 -
logx:布尔值,是否使用对数坐标轴(x轴)。 -
logy:布尔值,是否使用对数坐标轴(y轴)。 -
loglog:布尔值,是否同时使用对数坐标轴(x轴和y轴)。 -
xticks:序列,用于自定义x轴刻度值。 -
yticks:序列,用于自定义y轴刻度值。 -
xlim:列表或元组,自定义x轴显示范围。 -
ylim:列表或元组,自定义y轴显示范围。 -
rot:整数,设置刻度标签的旋转角度。 -
fontsize:整数,设置刻度标签的字体大小。 -
colormap:字符串或Matplotlib colormap对象,默认为None,用于选择图的区域颜色。 -
colorbar:布尔值,如果为True,则在柱状图和散点图上添加颜色条。 -
position:浮点数,用于指定条形图布局的相对对齐位置(0表示左端/底端,1表示右端/顶端)。 -
table:布尔值、Series或DataFrame,默认为False,如果为True,则根据DataFrame的数据绘制表格。 -
yerr和xerr:DataFrame、Series、数组或字典,用于绘制带有误差条的图表(详情请参考绘图带有误差条的方法)。 -
stacked:布尔值,在折线图和柱状图中默认为False,在面积图中默认为True,用于创建堆叠图。 -
sort_columns:布尔值,默认为False,以字母表顺序绘制各列,默认使用前列顺序。 -
secondary_y:布尔值或序列,默认为False,是否在右侧添加第二个y轴。如果是序列,指定要在右侧绘制的列。 -
mark_right:布尔值,默认为True,当使用第二个y轴时,是否自动在图例中标记列标签为"(right)"。 -
**kwds:其他传递给Matplotlib绘图方法的关键字参数。
返回值:
axes:Matplotlib AxesSubplot对象或其数组。
示例:
import pandas as pd
import matplotlib.pyplot as plt
# 创建示例数据
data = {
'Year': [2015, 2016, 2017, 2018, 2019, 2020, 2021],
'Sales': [100, 120, 150, 180, 200, 230, 250],
'Expenses': [80, 90, 100, 110, 120, 130, 140]
}
df = pd.DataFrame(data)
# 绘制折线图
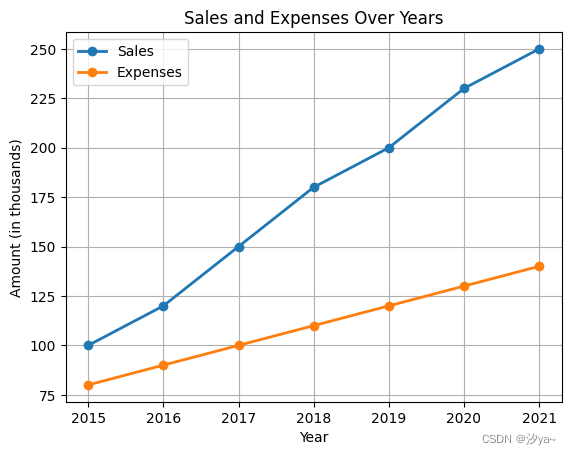
df.plot(x='Year', y=['Sales', 'Expenses'], kind='line', marker='o', linewidth=2)
plt.title('Sales and Expenses Over Years')
plt.xlabel('Year')
plt.ylabel('Amount (in thousands)')
plt.grid(True)
plt.legend(['Sales', 'Expenses'])
plt.show()
# 绘制条形图
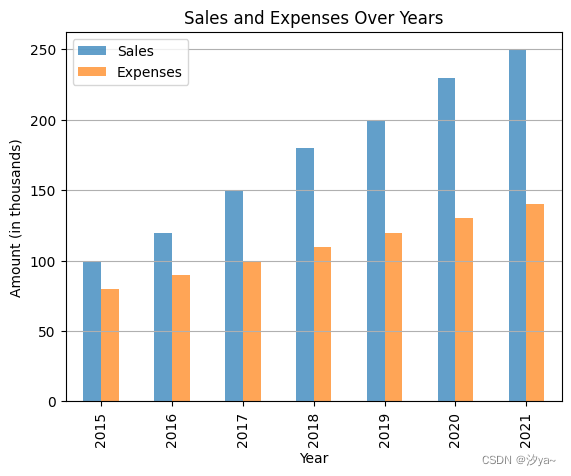
df.plot(x='Year', y=['Sales', 'Expenses'], kind='bar', alpha=0.7)
plt.title('Sales and Expenses Over Years')
plt.xlabel('Year')
plt.ylabel('Amount (in thousands)')
plt.grid(axis='y')
plt.legend(['Sales', 'Expenses'])
plt.show()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
Seaborn绘图 -数据可视化必备
官方示例:https://seaborn.pydata.org/tutorial.html
Seaborn是一个构建在matplotlib之上的一个非常完美的Python可视化库。
与Matplotlib的低级接口相比,Seaborn具有高级接口。适合处理数据流
主题样式
Seaborn 有五个预设的主题样式:darkgrid、whitegrid、dark、white 和 ticks。这些主题样式可通过 sns.set(style='样式名') 或 sns.set_style('样式名') 命令切换
darkgrid 主题,显示灰色背景带网格线,无坐标轴刻度线。# 默认主题,可简写为 sns.set()
whitegrid 主题,显示白色背景带网格线,无坐标轴刻度线。
dark 主题,显示灰色背景无网格线,无坐标轴刻度线。
white 主题,显示白色背景无网格线,无坐标轴刻度线。
ticks 主题,显示白色背景无网格线,有坐标轴刻度线
- 1
- 2
- 3
- 4
- 5
需要导入的包
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pd
from scipy import stats
- 1
- 2
- 3
- 4
- 5
导入数据集
数据来源:https://datahack.analyticsvidhya.com/contest/enigmacodefestmachinelearning1/
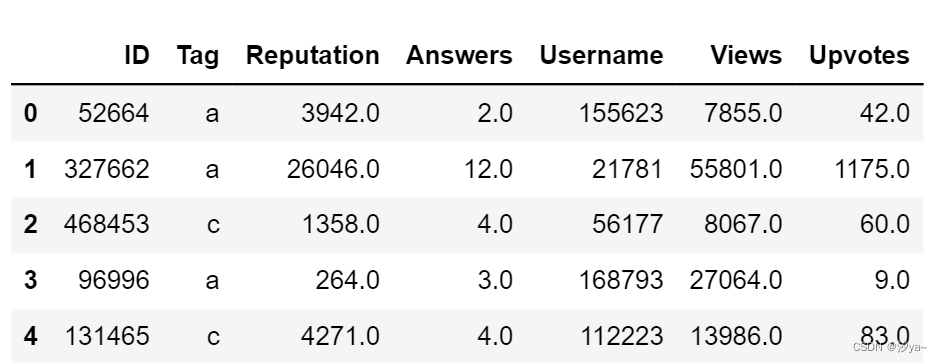
df = pd.read_csv(r"train_NIR5Yl1.csv")
df.head()
- 1
- 2
可视化统计关系
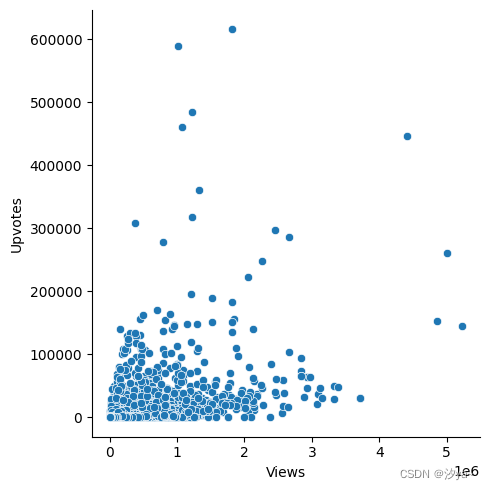
散点图
散点图可以可视化两个变量之间的关系。每个点在数据集中显示一个观察值,这些观察值用点状结构表示。图中显示了两个变量的联合分布。
# 创建图形和轴
sns.relplot(x="Views", y="Upvotes", data = df)
- 1
- 2
- 3
显示与数据相关的标签
sns.relplot(x="Views", y="Upvotes", hue = "Tag", data = df)
# 另外还可以通过参数size = "Tag"或者数size=(15,200)。,改变点大小
- 1
- 2
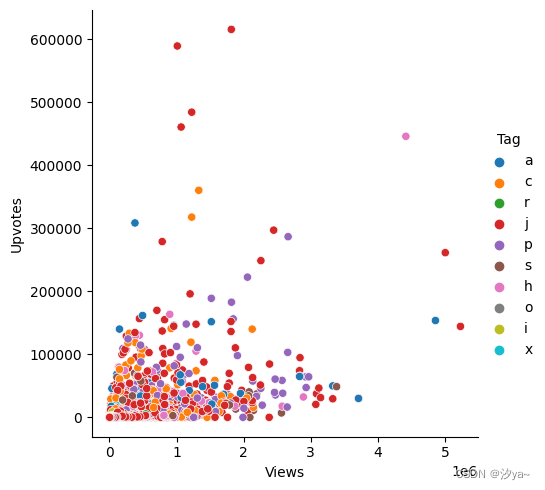
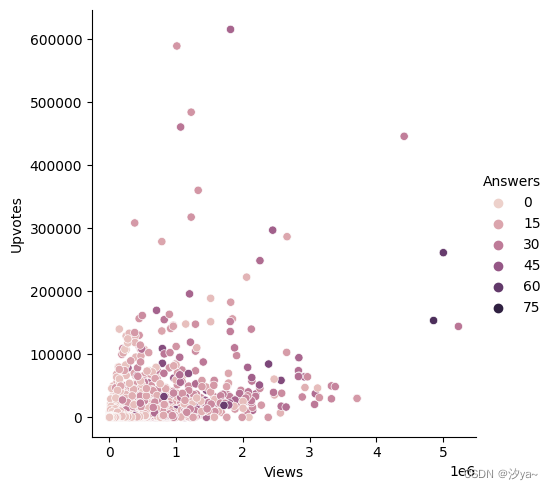
另外可以在色调(Hue)的帮助下在我们的图片中添加另一个维度,通过为点赋予颜色来实现,每种颜色都有一些附加的意义。
sns.relplot(x="Views", y="Upvotes", hue = "Answers", data = df);
- 1
抖动图
使用的数据来源:https://datahack.analyticsvidhya.com/contest/wnsanalyticshackathon20181/
使用catplot()函数查看education列和avg_training_score列之间的关系
sns.catplot(x="education", y="avg_training_score", jitter = False, data=df2)
- 1
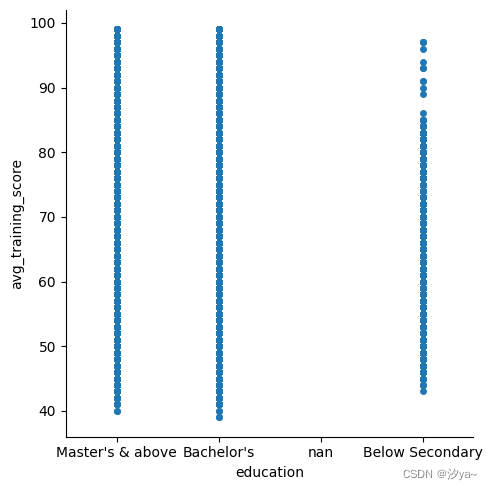
在Seaborn的catplot函数中,jitter参数控制是否对数据点进行抖动(jittering)。抖动是在分类变量上添加一些随机的小偏移量,使得数据点在x轴上稍微分散,从而防止多个数据点重叠在同一个位置,增加可视化的可读性。
-
jitter=True:表示在x轴上对数据进行抖动。这样做可以有效避免数据点的重叠,特别是当数据较密集时,使得图表更易于观察和解读。 -
jitter=False:表示不对数据进行抖动。如果你的数据不太密集,或者你更关心各个数据点的精确位置,可以选择这个选项。
选择是否使用抖动取决于数据的特点和你想要达到的可视化效果。对于大多数情况下,启用抖动是一个好的选择,因为它可以帮助更好地展示数据的分布情况。然而,如果你的数据较少或者有特定需求,可以将jitter设置为False。
Hue图
接下来,如果我们想在我们的图中引入另一个变量或另一个维度,我们可以使用hue参数。假设我们希望看到教育和avg_training_score图中的性别分布
sns.catplot(x="education", y="avg_training_score", hue = "gender", data=df2)
- 1
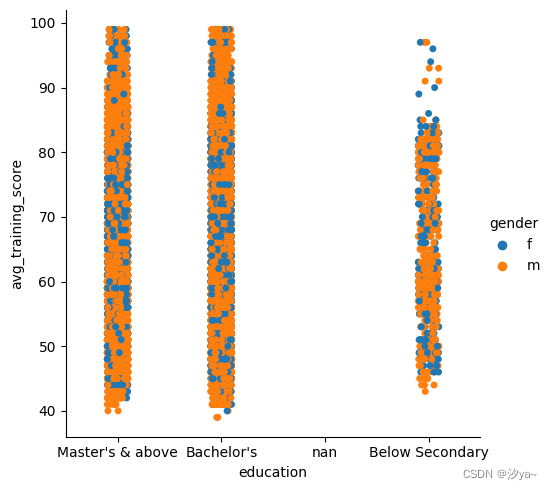
在上面的图中,一些点是相互重叠的,为了消除这种情况,可以设置kind =
“swarm”, swarm使用一种算法来防止这些点重叠,并且沿着分类轴调整这些点。
sns.catplot(x="education", y="avg_training_score", kind = "swarm", data=df2)
- 1
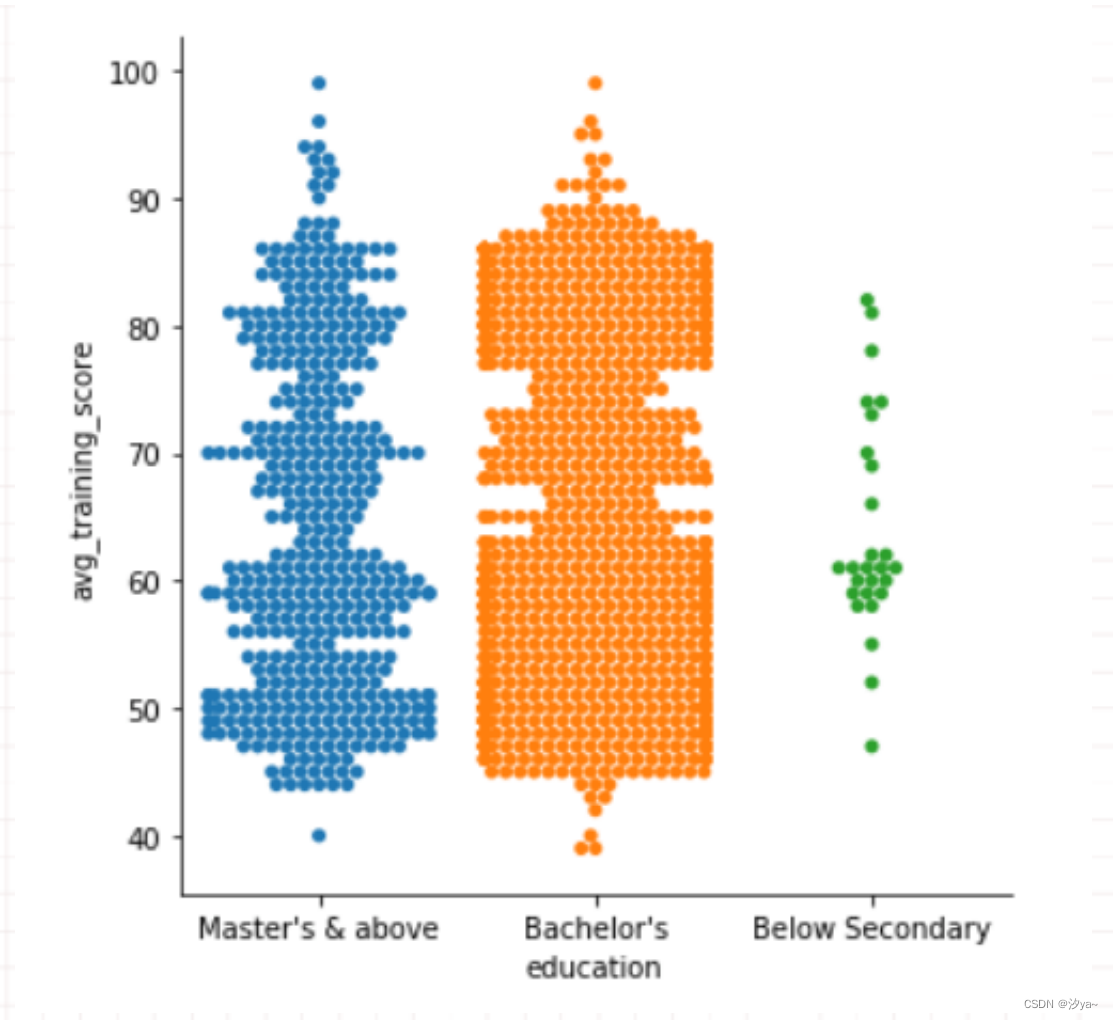
将is_promoted作为一个新变量引入
sns.catplot(x="education", y="avg_training_score", hue = "is_promoted", kind = "swarm", data=df2)
- 1
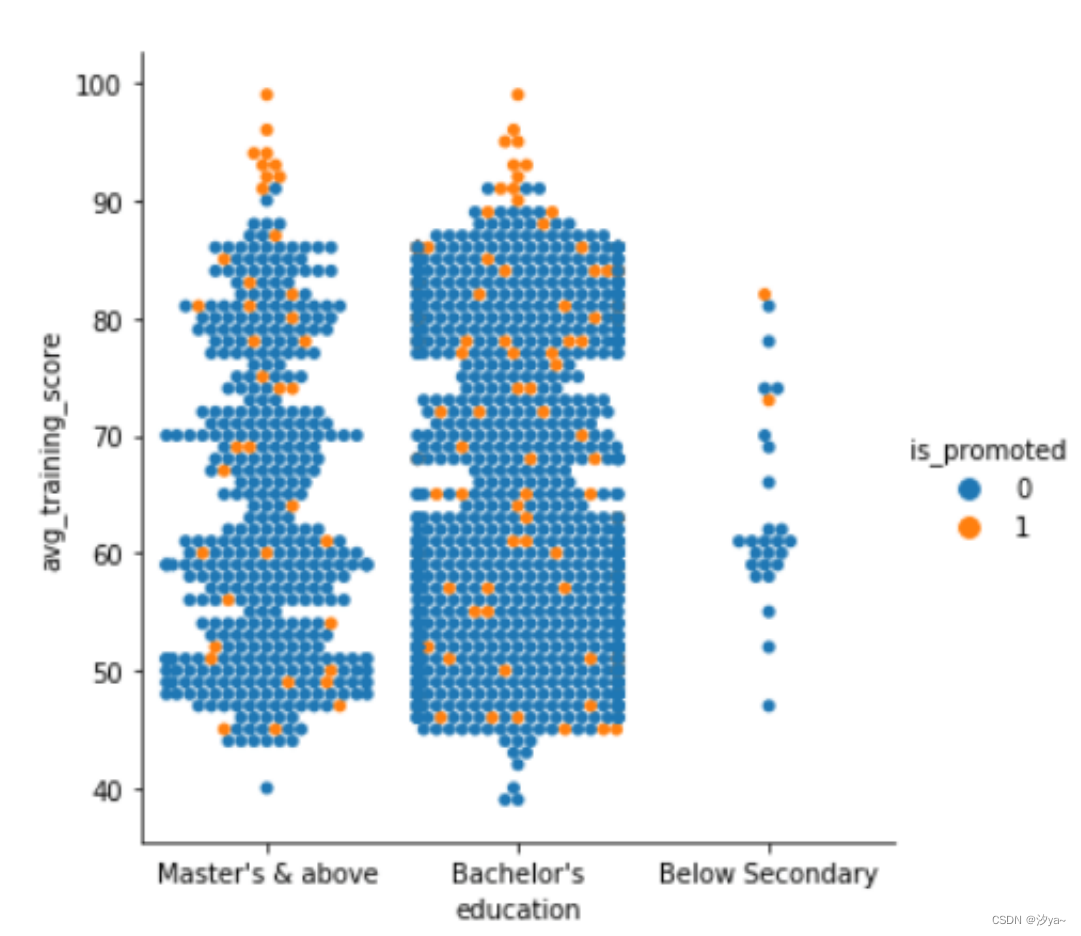
箱线图
箱线图 ,它显示了分布的三个四分位值以及最终值。箱图中的每个值都对应于数据中的实际观察值
sns.catplot(x="education", y="avg_training_score", kind = "box", data=df2)
- 1

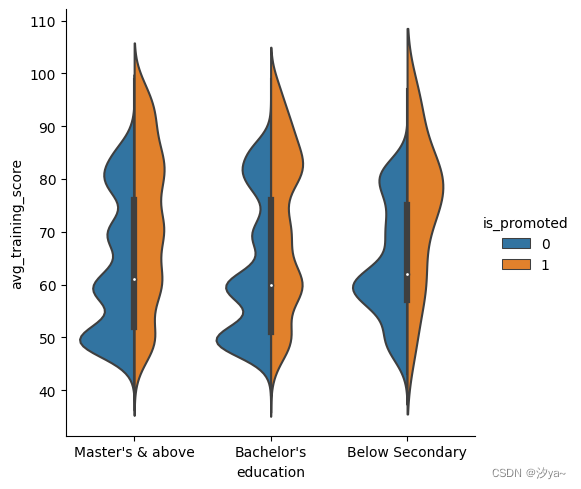
小提琴图
小提琴图结合了箱线图和核密度估计程序,以提供更丰富的值分布描述。四分位数值显示在小提琴内部。
sns.catplot(x="education", y="avg_training_score", hue = "is_promoted", kind = "violin", data=df2)
- 1
- 2
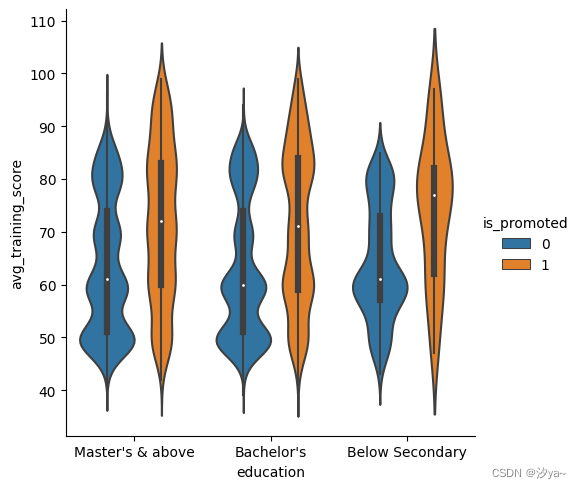
当色调语义参数是二值时,我们还可以拆分小提琴,这也可能有助于节省绘图空间。
sns.catplot(x="education", y="avg_training_score", hue = "is_promoted", kind = "violin",split=True, data=df2)
- 1
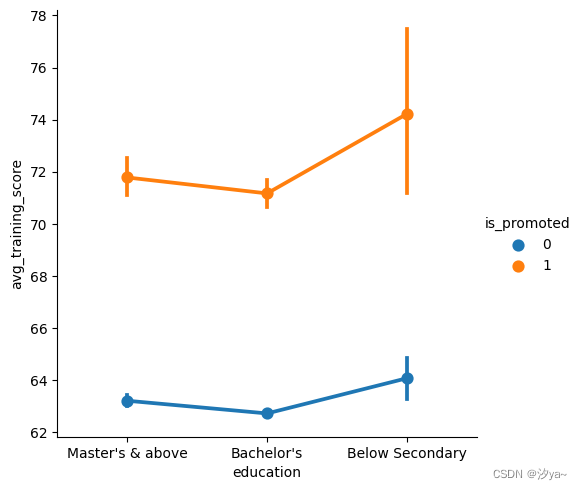
Pointplot
pointplot,这个图指出估计值和置信区间。Pointplot连接来自相同色调类别的数据。这有助于识别特定色调类别中的关系如何变化
sns.catplot(x="education", y="avg_training_score", hue = "is_promoted", kind = "point", data=df2)
- 1
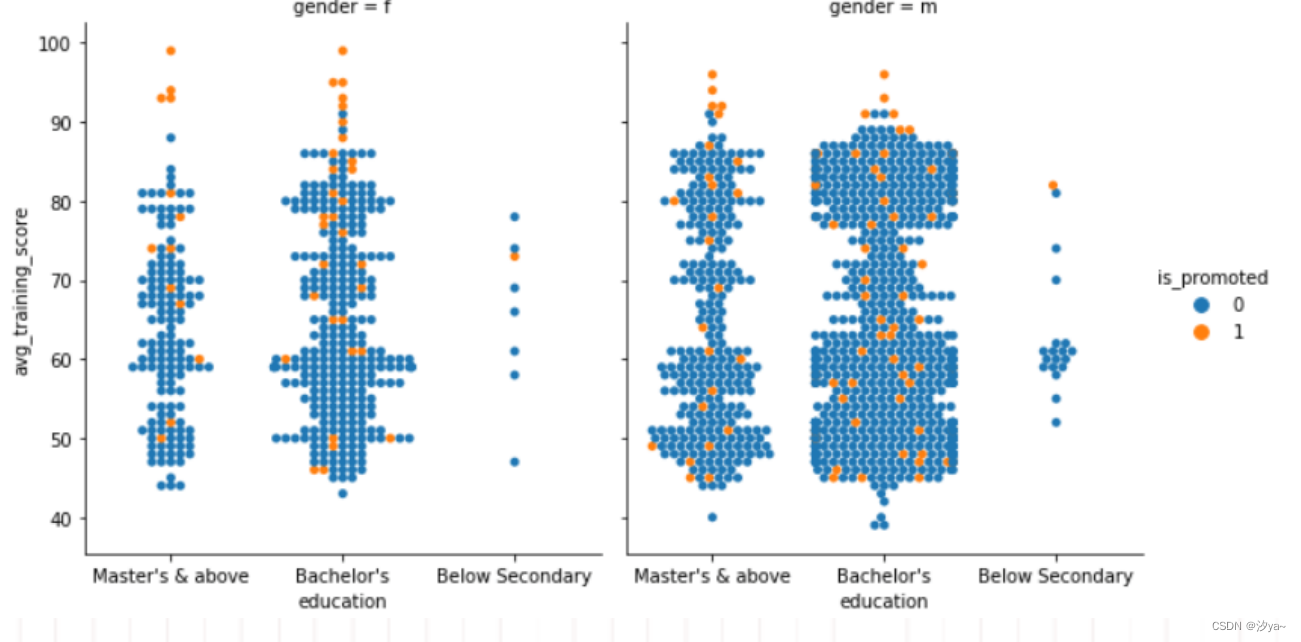
群图
sns.catplot(x="education", # x轴上的分类变量,这里是教育程度
y="avg_training_score", # y轴上的数值变量,这里是平均培训分数
hue="is_promoted", # 按照是否晋升(is_promoted)来给数据点着色
col="gender", # 按照性别(gender)分列绘制图表
aspect=.9, # 控制每个绘图块(facet)的纵横比例
kind="swarm", # 指定绘图类型为分类散点图(swarm plot)
data=df2) # 数据来源,这里是一个DataFrame df2
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
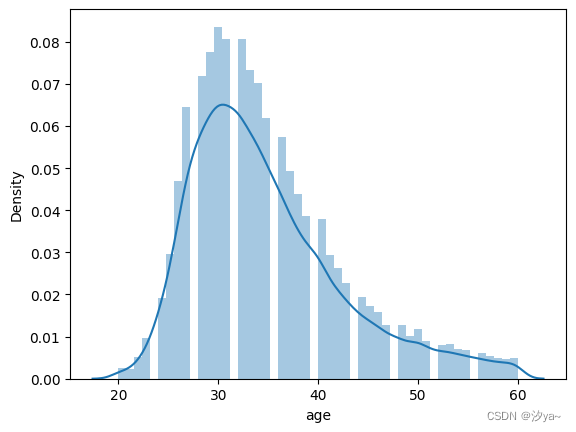
可视化数据集的分布
绘制单变量分布
柱状图
在研究变量分布时,最常见的是柱状图。默认情况下,distplot()函数绘制柱状图并适合内核密度估计
sns.distplot(df2.age)
- 1
直方图
直方图以箱子的形式表示数据的分布,并使用条形图来显示每个箱子下的观察次数。我们还可以在其中添加一个加固图,而不是使用KDE(核密度估计),这意味着在每次观察时,它都会画一个小的垂直标尺。
sns.distplot(df2.age, kde=False, rug = True)
- 1
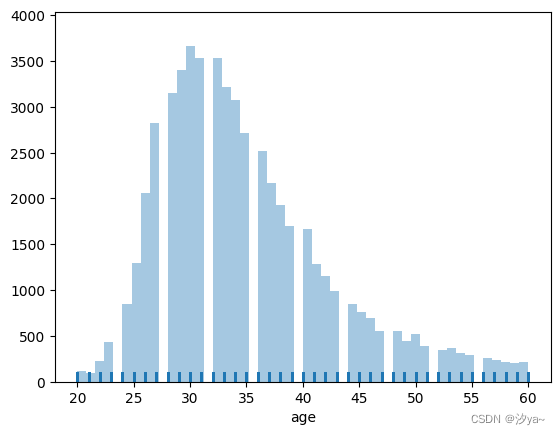
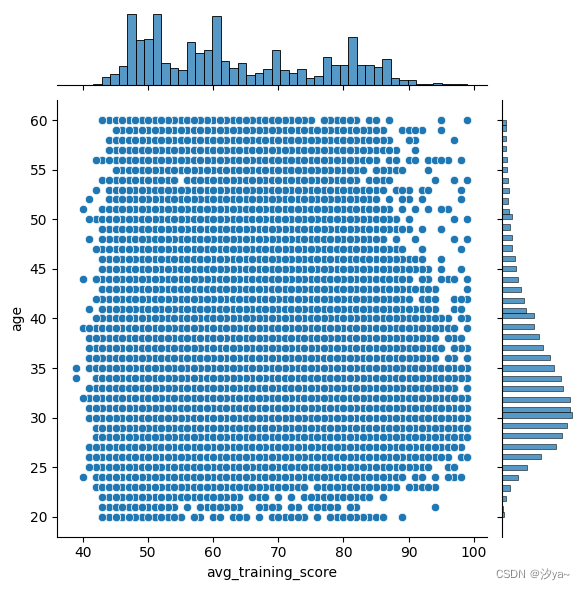
绘制双变量分布
使用了seaborn库的jointplot()函数。默认情况下,jointplot绘制散点图。
sns.jointplot(x="avg_training_score", y="age", data=df2);
- 1
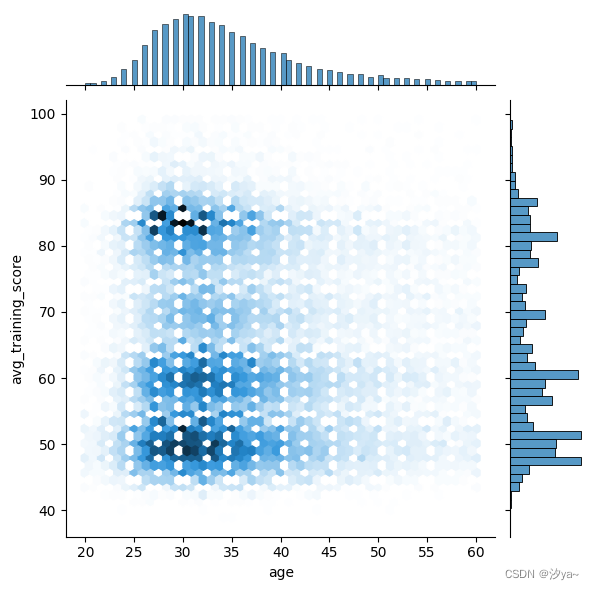
Hex图
Hexplot是一个双变量的直方图,因为它显示了在六边形区域内的观察次数。这是一个非常容易处理大数据集的图。为了绘制Hexplot,我们将把kind属性设置为hex
sns.jointplot(x=df2.age, y=df2.avg_training_score, kind="hex", data = df2)
- 1
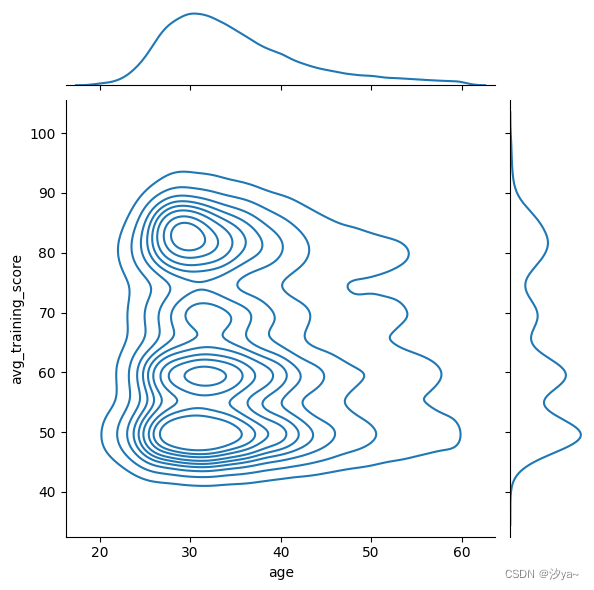
KDE 图
sns.jointplot(x="age", y="avg_training_score", data=df2, kind="kde");
- 1
可视化数据集中的成对关系
sns.pairplot(df2)
- 1

好看的图模板
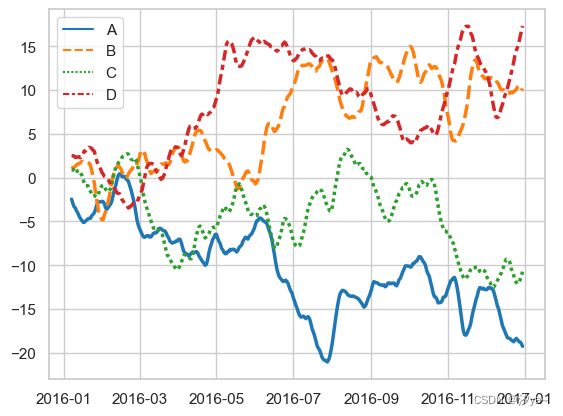
来自宽格式数据集的线图
# 导入必要的库
import numpy as np
import pandas as pd
import seaborn as sns
sns.set_theme(style="whitegrid") # 设置Seaborn绘图的主题和样式
# 创建一个随机种子,以便结果可以复现
rs = np.random.RandomState(365)
# 生成一个包含随机数据的数组,形状为(365, 4),并计算每一列的累积和
values = rs.randn(365, 4).cumsum(axis=0)
# 创建日期范围为2016年1月1日起的365个日期,间隔为1天
dates = pd.date_range("1 1 2016", periods=365, freq="D")
# 使用Pandas将数据和日期合并为DataFrame,并给每列指定名称"A", "B", "C", "D"
data = pd.DataFrame(values, dates, columns=["A", "B", "C", "D"])
# 使用滚动窗口计算每列的7天滚动均值,并更新数据
data = data.rolling(7).mean()
# 使用Seaborn绘制折线图,展示数据中每列的变化趋势
sns.lineplot(data=data, palette="tab10", linewidth=2.5)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
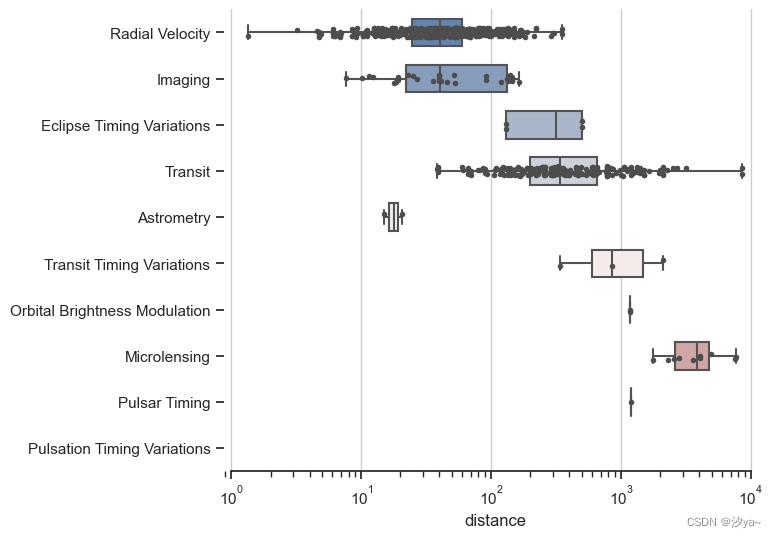
带观察值的水平箱线图
数据来源:https://github.com/mwaskom/seaborn-data/blob/master/planets.csv
# 导入所需的库
import seaborn as sns
import matplotlib.pyplot as plt
# 设置seaborn的主题样式为'ticks'
sns.set_theme(style="ticks")
# 初始化图表,大小为(7,6),并设置x轴为对数刻度
f, ax = plt.subplots(figsize=(7, 6))
ax.set_xscale("log")
# 载入seaborn内置的'planets'数据集
planets = pd.read_csv(r"planets.csv")
# 使用箱形图绘制'distance'为x轴,'method'为y轴
# 设置whis可显示异常值的范围,width调整箱形的宽度
# 使用'vlag'色阶
sns.boxplot(x="distance", y="method", data=planets,
whis=[0, 100], width=.6, palette="vlag")
# 使用散点图绘制'distance'为x轴,'method'为y轴
# 设置点的大小,颜色和线宽
sns.stripplot(x="distance", y="method", data=planets,
size=4, color=".3", linewidth=0)
# 数据可视化美化
# 显示x轴网格线,移除y轴标签,裁剪左边边框
ax.xaxis.grid(True)
ax.set(ylabel="")
sns.despine(trim=True, left=True)
# 显示图表
plt.show()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
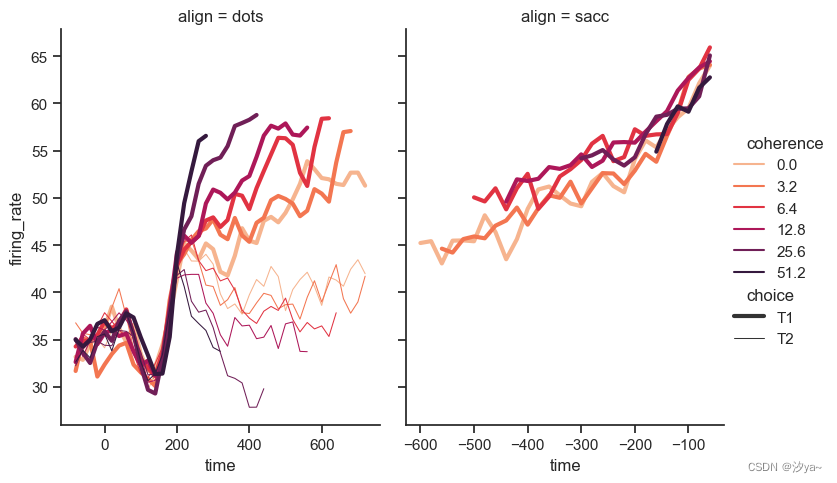
多个面上的线图
import seaborn as sns
# 设置seaborn主题样式为'ticks'
sns.set_theme(style="ticks")
# 加载'sdots'示例数据集
dots = sns.load_dataset("dots")
# 定义调色板的具体颜色值
palette = sns.color_palette("rocket_r")
# 绘制两面多个线图
# x轴为'time',y轴为'firing_rate'
# hue表示颜色区分的变量'coherence'
# size表示点的大小代表的变量'choice'
# col表示按'slign'分面
# kind指定折线图类型
# size_order设置点的大小顺序
# palette定义上面指定的调色板
# height/aspect设置图形大小,facet_kws定义分面参数
sns.relplot(data=dots,
x="time", y="firing_rate",
hue="coherence", size="choice", col="align",
kind="line", size_order=["T1", "T2"], palette=palette,
height=5, aspect=.75, facet_kws=dict(sharex=False))
# 该图的作用是:
# 使用线图展示'dots'数据集中
# 'time','firing_rate'两个变量的关系
# 并利用颜色、点大小、分面等视觉编码显示不同的第三维和第四维信息
# 直观呈现多维数据集的关系
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
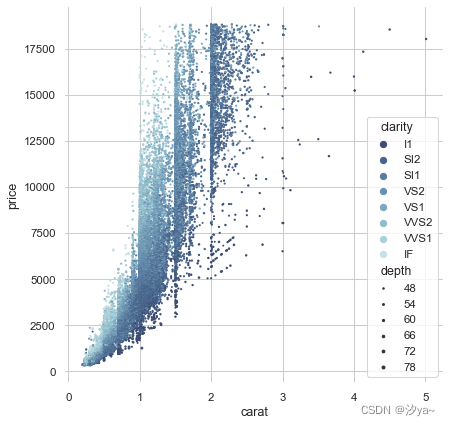
具有多种语义的散点图
import seaborn as sns
import matplotlib.pyplot as plt
# 设置seaborn主题样式为白色网格
sns.set_theme(style="whitegrid")
# 加载内置的钻石数据集
diamonds = sns.load_dataset("diamonds")
# 初始化图像和子图,并移除子图边框
f, ax = plt.subplots(figsize=(6.5, 6.5))
sns.despine(f, left=True, bottom=True)
# 定义钻石clarity的排序
clarity_ranking = ["I1", "SI2", "SI1", "VS2", "VS1", "VVS2", "VVS1", "IF"]
# 绘制散点图
# x轴为carat,y轴为price
# hue为clarity,即颜色区分clarity
# size为depth,即点的大小代表depth
# palette定义颜色渐变
# hue_order指定上面定义的clarity顺序
# sizes设置点的大小范围
# data和ax指定所用的数据及子图
sns.scatterplot(x="carat", y="price",
hue="clarity", size="depth",
palette="ch:r=-.2,d=.3_r",
hue_order=clarity_ranking,
sizes=(1, 8), linewidth=0,
data=diamonds, ax=ax)
# 这是一个组合了多个变量的散点图
# 既展示了carat与price的关系
# 又通过颜色和大小编码呈现了clarity和depth维度的信息
# 可以更清晰地呈现钻石数据集的多维分布情况
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
问题解决方案
解决seaborn绘图无法显示中文等问题
plt.rcParams['font.sans-serif'] = ['SimHei'] # 黑体
plt.rcParams['axes.unicode_minus'] = False # 解决无法显示符号的问题
sns.set(font='SimHei', font_scale=0.8) # 解决Seaborn中文显示问题
- 1
- 2
- 3
- 4


