
热门标签
热门文章
- 1SQL基础——数据更新_更新产品表的价格使用sql语句
- 2【DevOps】全流程记录:CentOS7安装Gitlab服务器_recipe: gitlab:gitlab-rails
- 3javaee初阶———多线程(三)
- 4ubuntu18.04 下slowfast网络环境安装及模型测试( python3.9)_importerror: cannot import name 'cat_all_gather' f
- 5【测评】互联网校招技术岗&非技术岗测评题型(认知测试,性格测试,心理测试)_技术岗的测评
- 6kafka常用控制台命令集合_kafka-console-consumer.sh 如何看到key
- 7Vscode中css样式书写提示的插件及使用方法_vscode中css提示插件 bc为backgound-color
- 8【Git】git diff提示old mode 100644、new mode 10075_old mode 100644 new mode 100755
- 9Day1-正则表达式在NLP中的基本应用_第1关:正则表达式在 nlp 中的应用
- 10使用 proxySQL 来代理 Mysql
当前位置: article > 正文
【Pytorch】NLP|文本数据分析代码实现_pytorch 中文nlp
作者:AllinToyou | 2024-04-17 14:30:05
赞
踩
pytorch 中文nlp
1、文本数据分析方法
- 常用的几种文本数据分析方法:
- 标签数量分布
- 句子长度分布
- 词频统计与关键词词云
2、标签数量分布
2.1 获取训练集和验证集的标签数量分布
# 导入工具包 import seaborn as sns import pandas as pd import matplotlib.pyplot as plt import jieba import jieba.posseg as pseg from itertools import chain from wordcloud import WordCloud # 设置显示风格 plt.style.use('fivethirtyeight') # 1、分别读取训练tsv和验证tsv train_data = pd.read_csv("./cn_data/train.tsv", sep="\t") valid_data = pd.read_csv("./cn_data/dev.tsv", sep="\t") # 2、获得训练数据标签数量分布 sns.countplot("label", data=train_data) plt.title("train_data") plt.show() # 3、获取验证数据标签数量分布 sns.countplot("label", data=valid_data) plt.title("valid_data") plt.show()

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
-
训练集标签数量分布:

-
验证集标签数量分布:

-
分析:
在深度学习模型评估中, 我们一般使用ACC作为评估指标, 若想将ACC的基线定义在50%左右, 则需要我们的正负样本比例维持在1:1左右, 否则就要进行必要的数据增强或数据删减. 上图中训练和验证集正负样本都稍有不均衡, 可以进行一些数据增强.
2.2 获取训练集和验证集的句子长度分布
# 1、在训练数据中添加新的句子长度列, 每个元素的值都是对应的句子列的长度 train_data["sentence_length"] = list(map(lambda x: len(x), train_data["sentence"])) # 2、绘制句子长度列的数量分布图 sns.countplot("sentence_length", data=train_data) # 主要关注count长度分布的纵坐标, 不需要绘制横坐标, 横坐标范围通过dist图进行查看 plt.xticks([]) plt.show() # 3、绘制dist长度分布图 sns.distplot(train_data["sentence_length"]) # 主要关注dist长度分布横坐标, 不需要绘制纵坐标 plt.yticks([]) plt.show() # 4、在验证数据中添加新的句子长度列, 每个元素的值都是对应的句子列的长度 valid_data["sentence_length"] = list(map(lambda x: len(x), valid_data["sentence"])) # 5、绘制句子长度列的数量分布图 sns.countplot("sentence_length", data=valid_data) # 主要关注count长度分布的纵坐标, 不需要绘制横坐标, 横坐标范围通过dist图进行查看 plt.xticks([]) plt.show() # 6、绘制dist长度分布图 sns.distplot(valid_data["sentence_length"]) # 主要关注dist长度分布横坐标, 不需要绘制纵坐标 plt.yticks([]) plt.show()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 训练集句子长度分布:


- 验证集句子长度分布:
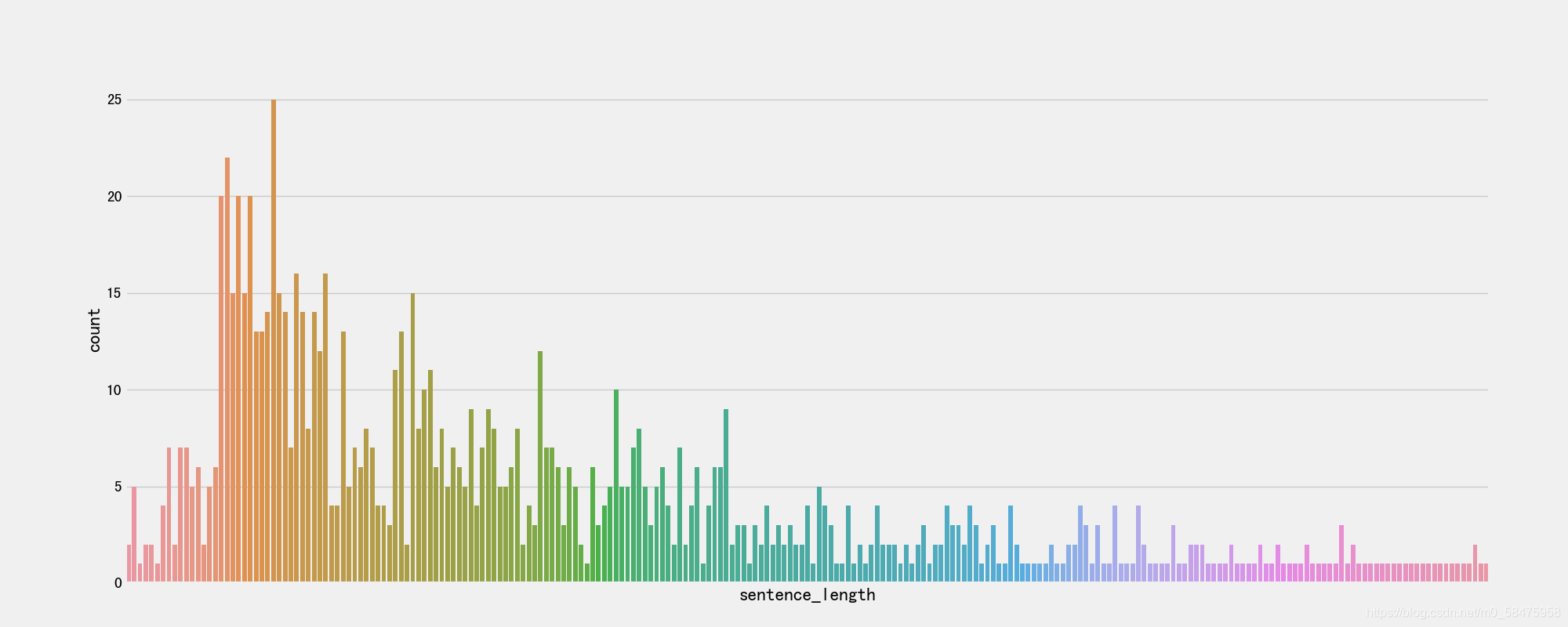
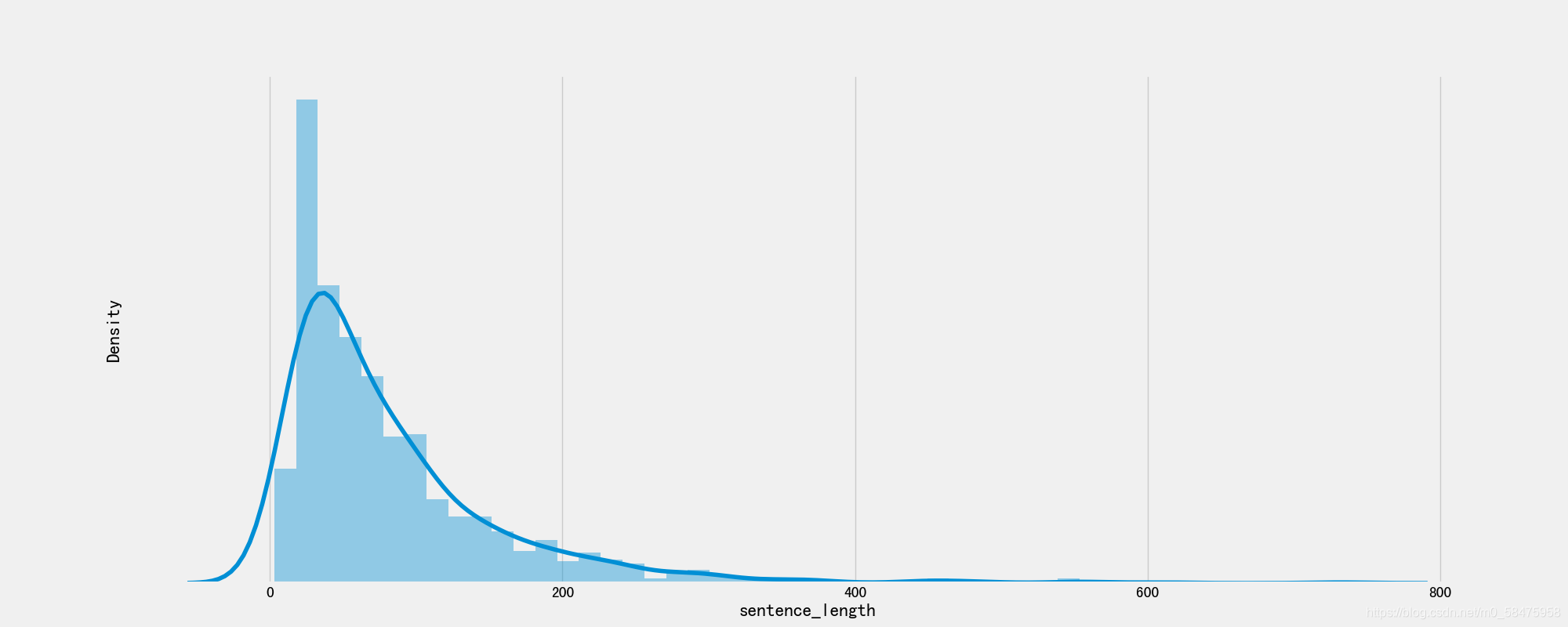
- 分析:
通过绘制句子长度分布图, 可以得知我们的语料中大部分句子长度的分布范围, 因为模型的输入要求为固定尺寸的张量,合理的长度范围对之后进行句子截断补齐(规范长度)起到关键的指导作用. 上图中大部分句子长度的范围大致为20-250之间.
2.3 获取训练集和验证集的正负样本长度散点分布
# 1、绘制训练集长度分布的散点图
plt.figure(figsize=(20, 8), dpi=100)
sns.stripplot(y='sentence_length', x = 'label', data = train_data)
plt.show()
# 2、绘制测试集长度分股的散点图
plt.figure(figsize=(20, 8), dpi=100)
sns.stripplot(y='sentence_length', x = 'label', data = valid_data)
plt.show()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 训练集上正负样本的长度散点分布:

- 验证集上正负样本的长度散点分布:

- 分析:
通过查看正负样本长度散点图, 可以有效定位异常点的出现位置, 帮助我们更准确进行人工语料审查. 上图中在训练集正样本中出现了异常点, 它的句子长度近3500左右, 需要我们人工审查.
2.4 获取训练集和验证集不同词汇总数统计
# 对训练集的句子进行分词,并统计出不同词汇的总数
train_vocab = set(chain(*map(lambda x: jieba.lcut(x), train_data['sentence'])))
print("训练集词汇总数:", len(train_vocab))
valid_vocab = set(chain(*map(lambda x: jieba.lcut(x), valid_data['sentence'])))
print("验证集词汇总数:", len(valid_vocab))
- 1
- 2
- 3
- 4
- 5
输出结果:
训练集词汇总数: 12162
验证集词汇总数: 6857
- 1
- 2
2.5 获得训练集上正负的样本的高频形容词词云
# 1、获取形容词列表 def get_a_list(text): # 使用jieba的词性标注方法切分文本,获得具有词性属性的flag词汇属性word的对象 # 判断flag是否是形容词,返回对应的词汇 r = [] for g in pseg.lcut(text): if g.flag == 'a': r.append(g.word) return r # 2、创建词云函数 def get_word_cloud(keywords_list): """ 实例化绘制词云的类,其中参数font_path是字体路径,显示中文 max_words指词云图像最多显示多少个词,background_color为背景颜色 """ wordcloud = WordCloud(font_path='./SimHei.ttf', max_words=100, background_color='white') # 将传入的列表转化成词云生成器需要的字符串形式 keywords_string = ''.join(keywords_list) # 生成词云 wordcloud.generate(keywords_string) # 绘制图像 plt.figure() plt.imshow(wordcloud, interpolation='bilinear') plt.axis('off') plt.show() # 3、获得训练集上正样本 p_train_data = train_data[train_data['label'] == 1]['sentence'] # 3.1 提取正样本中每个句子的形容词 p_a_train_vocab = chain(*map(lambda x: get_a_list(x), p_train_data)) # 4、获取训练集上负样本 n_train_data = train_data[train_data['label'] == 0]['sentence'] # 4.1 提取负样本中每个句子的形容词 n_a_train_vocab = chain(*map(lambda x: get_a_list(x), n_train_data)) # 5、调用get_word_cloud函数 get_word_cloud(p_a_train_vocab) get_word_cloud(n_a_train_vocab)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 训练集正样本形容词词云:

- 训练集负样本形容词词云:

2.6 获得验证集上正负的样本的形容词词云
# 1、获取验证集上的正样本
p_valid_data = valid_data[valid_data['label' == 1]]['sentence']
# 提取张样本中每个句子的形容词
p_a_valid_vocab = chain(*map(lambda x: get_a_list(x), p_valid_data))
# 2、获取验证集上的负样本
n_valid_data = valid_data[valid_data['label' == 0]]['sentence']
# 提取负样本中每个句子的形容词
n_a_valid_vocab = chain(*map(lambda x: get_a_list(x), n_valid_data))
# 3、调用get_word_cloud函数
get_word_cloud(p_a_valid_vocab)
get_word_cloud(n_a_valid_vocab)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 验证集正样本形容词词云:

- 验证集负样本形容词词云:

- 分析:
根据高频形容词词云显示, 我们可以对当前语料质量进行简单评估, 同时对违反语料标签含义的词汇进行人工审查和修正, 来保证绝大多数语料符合训练标准。上图中的正样本大多数是褒义词, 而负样本大多数是贬义词, 基本符合要求, 但是负样本词云中也存在"便利"这样的褒义词, 因此可以人工进行审查。
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/AllinToyou/article/detail/440692
推荐阅读
相关标签

