
- 1【配置VScode支持编译c++11】_vscode配置c++11
- 2linux-shell命令之mount【挂载命令】_shell mount
- 3Java Socket编程
- 4Docker-Compose 下载安装、卸载步骤_docker-compose下载
- 5Codeforces Round #698 (Div. 2) A. Nezzar and Colorful Balls
- 6使用 Typescript 开发 Nodejs 命令行工具
- 7直方图均衡化实现
- 8H5画布canvas特效(旋转跳跃不停歇)_h5 canvas 加载gif 后左右跳
- 9scss :export 中导出的变量与Vue JavaScript共享无效
- 10基于python Moviepy的视频字幕识别和合成!_moviepy字幕
书生·浦语大模型实战营-学习笔记3_大模型 rag 、 fine-tune、
赞
踩
视频地址:
(3)基于 InternLM 和 LangChain 搭建你的知识库
文档教程:
https://github.com/InternLM/tutorial/tree/main/langchain
(3)基于 InternLM 和 LangChain 搭建你的知识库


1. 大模型开发范式(RAG、Fine-tune)


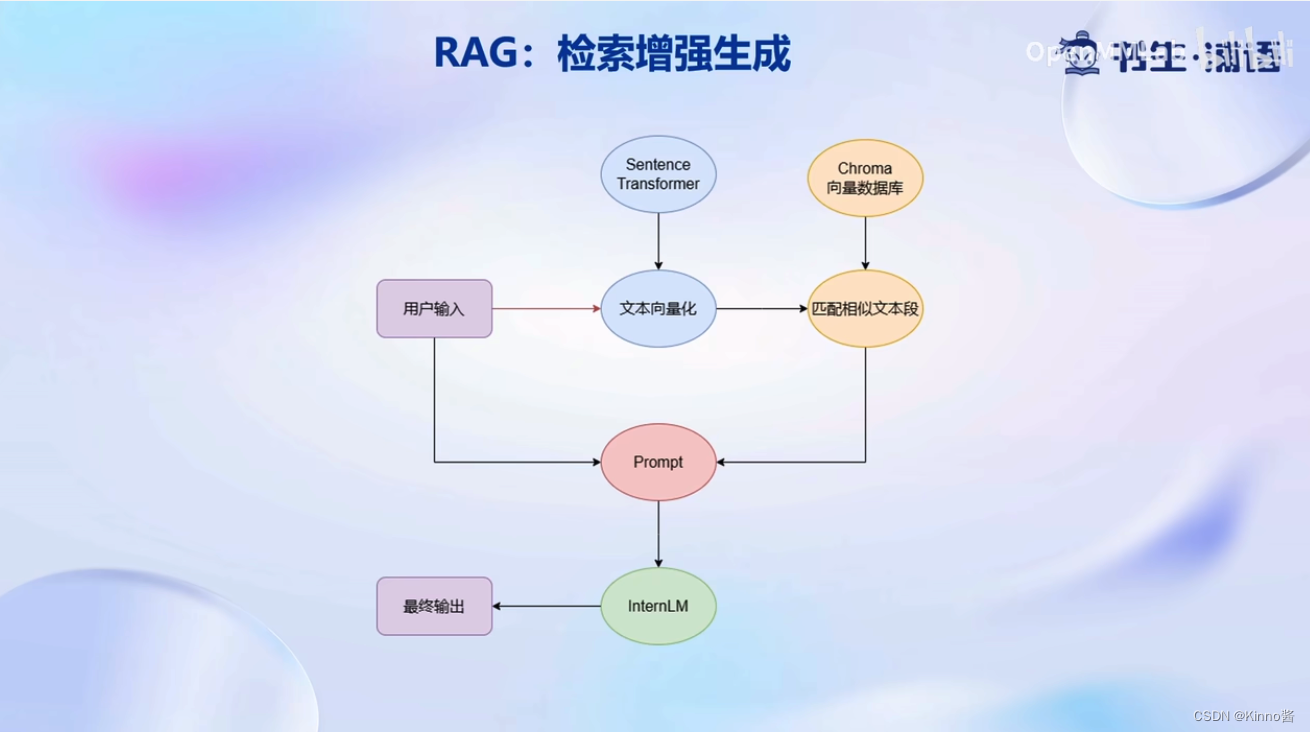
RAG
Retrieval-Augmented Generation (RAG) 检索增强生成
核心思想:给大模型外挂一个知识库,对用户的提问会首先从知识库中匹配到提问对应相关的文档,然后将文档和提问一起交给大模型来生成回答,从而提高大模型的知识储备
优势:
- 无需对大模型进行重新训练
- 不需要GPU算力
- 对于新的知识只需总结加入到外挂数据库中即可
- 加入新知识成本低
- 可以实时更新
不足:
- 将检索到的文档和用户提问一起交给大模型、占用了大量的模型上下文,回答知识有限,对于需要大跨度进行总结的知识表现效果不佳
微调 (传统自然语言处理的方法)
在一个新的较小的训练集上,进行轻量级的训练微调,从而提升模型在这个新数据集上的能力
优势:
- 可个性化微调,充分拟合个性化数据,对于非可见知识(如:回答风格)模拟效果好
- 知识覆盖面广
不足:
- 需要重新训练,成本高昂,需要很多的GPU算力和个性化数据
- 无法解决实时更新问题
2. LangChain简介(RAG开发框架)
如何快速高效的开发RAG应用?

开发者可以直接将私域数据嵌入LangChain中的组件,通过将这些组件进行组合,生成适合来构建适用于自己业务场景的RAG应用
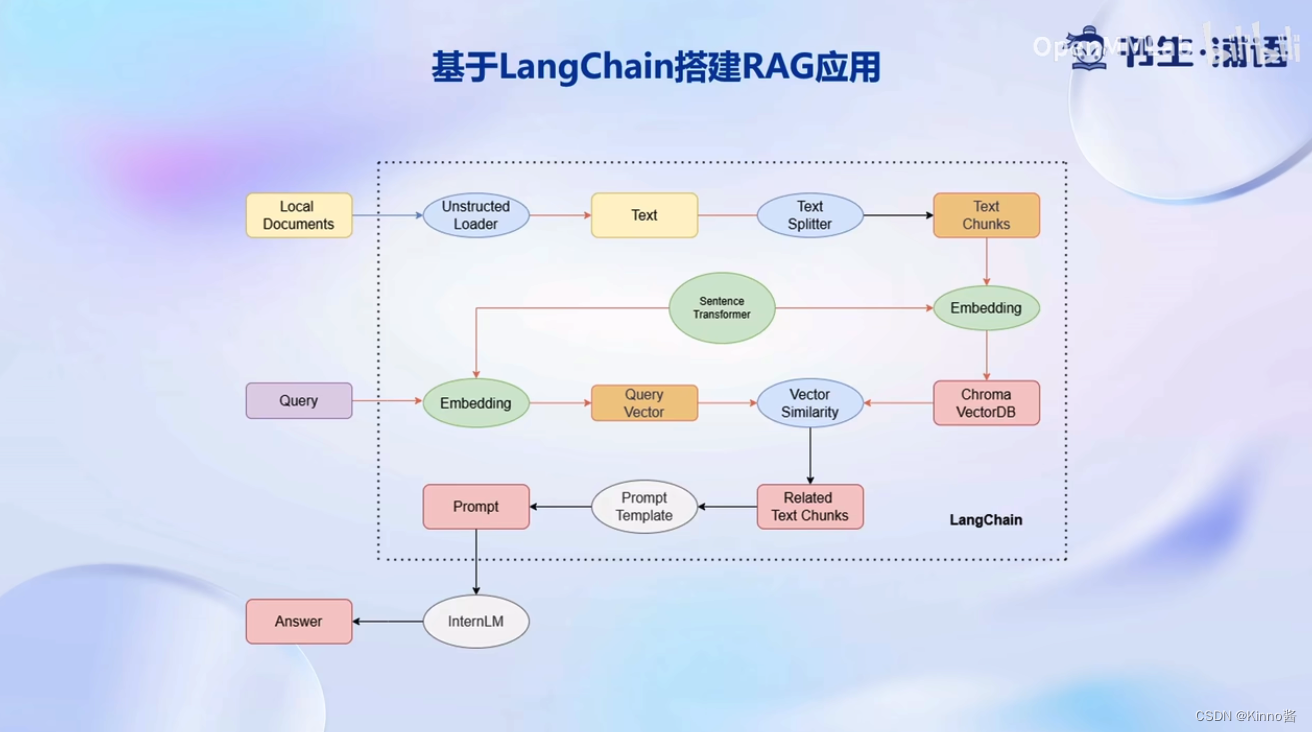
对于以本地文档Local Documents形式存在的个人知识库,会使用Unstructed Loader组建来加载本地文档,这个组件会将不同格式的本地文档统一转换为纯文本格式;然后使用Text Splitter对提取出来的纯文本进行分割成Chunk,再通过开源词向量模型Sentence Transformer将文本段转换为向量格式,存储到基于Chroma的向量数据库VectorDB中。
接下来,对于用户的每一个输入Query,会首先通过Sentence Transformer,将输入转换为同样纬度的向量,通过在向量数据库中进行相似度匹配Vector Similarity找到和用户输入相关的文本段Related Text Chunks,将相关的文本段嵌入到已经写好的Prompt Template中,再交给InternLM进行最后的回答即可。
上述的一整个过程都被封装在检索问答链中,我们可以将个性化的配置引入到检索问答链对象,即可构建属于自己的RAG应用
RAG开发基本流程:
- 构建向量数据库
- 搭建知识库助手
3. 构建向量数据库

个人数据类型(txt, markdown, pdf)转化为无格式的字符串,后续构建向量数据库的输入都是基于无格式的文本
对加载的文本进行切分,将它划分到多个不同的Chunks,后续检索相关的Chunk来实现问答。(例如:设定最长的字符串长度为500,那么每500个字符会被切分为一个Chunk)
后续实战环节会使用开源词向量Sentence Transformer来进行向量化。
4. 搭建知识库助手
在完成向量数据库的构建后,就可搭建知识库助手

上述方法可以高效使用LangChain的检索问答链组件
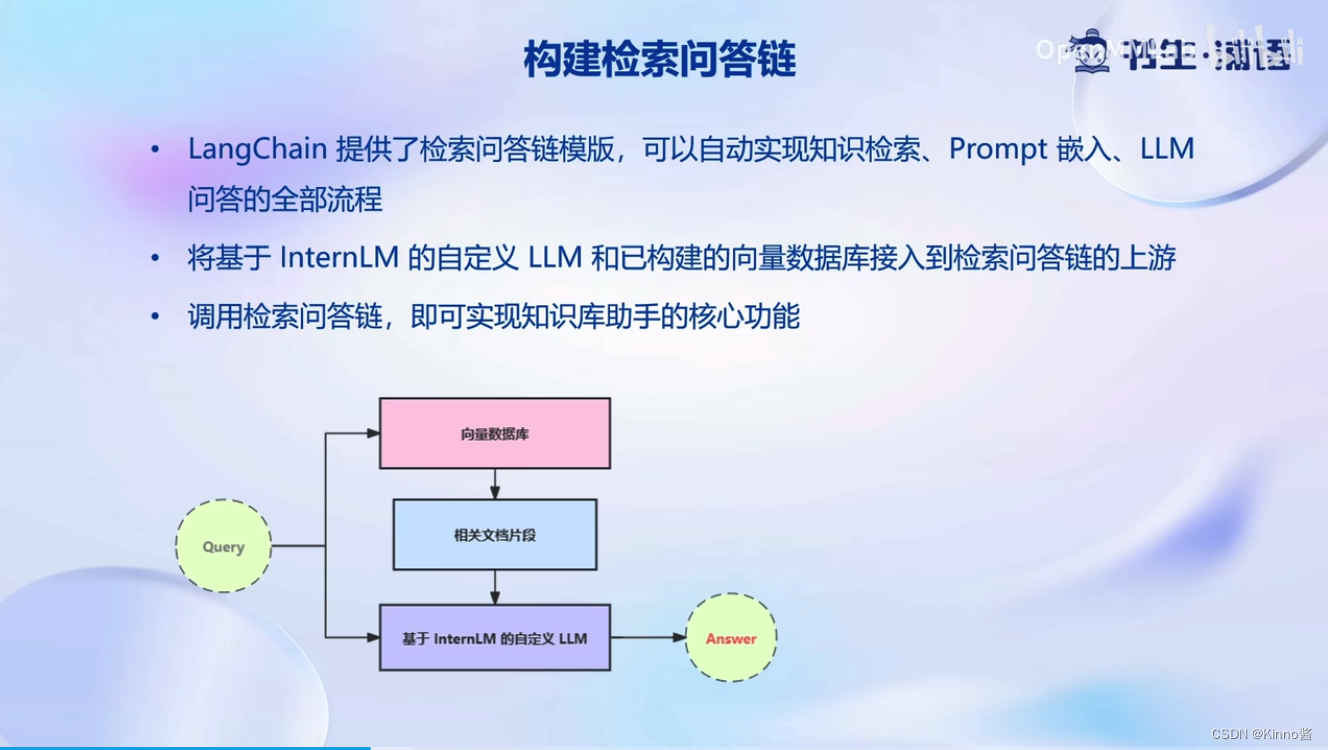
调用检索问答链会自动完成对用户输入进行向量化,在向量数据库中检索相关文档片段,基于internLM的自定义大模型进行检索回答的全部过程。调用这样一个检索问答链就可以实现知识库助手的核心过程。

5. Web Demo部署
6. 动手实战环节
见文档:
https://github.com/InternLM/tutorial/tree/main/langchain

