
- 1智能语音助手调研【简单可行方案及开源代码】_下载语音助手开源
- 2Android10导入系统证书的方法。_安卓10导入系统证书
- 3一行代码检测XP/调试/多开/模拟器/root的android库_easyprotectorlib
- 4云计算是否正在“杀死”运维
- 5《postgresql指南--内幕探索》第六章 清理过程_pg_freespacemap download
- 6Navicat 快捷键 | 大全
- 7AI绘图:教你几个提示词 100%生成美丽小姐姐-第三弹_ai文生图提示词模板
- 8如何使用graphpad做柱形图_Graphpad Prism 8作图教程(2):XY图的属性设置
- 9机器学习—数据压缩(PCA)—特征值分解、奇异值分解+代码理解_奇异值分解代码
- 10【详解】Pycharm 关联 Git管理项目_pycharm 关联git
图像修复神器!带上口罩都能还原!DDPM:用去噪扩散概率模型极限修复图像,效果太牛了!...
赞
踩
点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
转载自:机器之心 | 编辑:杜伟、陈萍
无论掩码类型如何多变,苏黎世联邦理工学院计算机视觉实验室(CVL)的图像修复方法都能还原出逼真的图像。
图像修复旨在填充图像中的缺失区域,被修复区域需要与图像的其余部分协调一致,并且在语义上是合理的。为此,图像修复方法需要强大的生成能力,目前的修复方法依赖于 GAN 或自回归建模。
近日,来自苏黎世联邦理工学院计算机视觉实验室(CVL)的研究者提出了 RePaint,这是一种基于 DDPM(Denoising Diffusion Probabilistic Model,去噪扩散概率模型)的修复方法,该方法还可以适用于极端情况下的蒙版。

RePaint: Inpainting using Denoising Diffusion Probabilistic Models
论文地址:https://arxiv.org/pdf/2201.09865.pdf
代码连接:https://github.com/andreas128/RePaint
它的修复效果是这样的,RePaint 使用扩散模型填充缺失的图像部分:下面示例中,蓝色部分是图像缺失部分,也就是需要 RePaint 修复的部分,RePaint 会根据已知的部分生成缺失的部分。它的修复过程是这样的:首先从纯粹的噪音开始,然后对图像逐级降噪,中间的每一步使用图像已知部分来填充未知部分。

RePaint 还能重新绘制不同内容和形状的缺失区域,创建许多有意义的填充物。如面部表情和特征,如耳环或痣:

RePaint 在极端情况下修复质量也比较好:输入图像的每隔一行(例如只留下高度和宽度维度上 stride= 2 的像素)都是未知的,大多数修复方法都失败了,但是 RePaint 可以很好的进行修复:

上述图像修复过程采用预训练的无条件 DDPM 作为生成先验。为了调节生成过程,该研究仅通过使用给定的图像信息对未掩码区域进行采样来改变反向扩散迭代。由于该技术不会修改或调节原始 DDPM 网络本身,因此该模型可以为任何修复形式生成高质量和多样化的输出图像。
在实验部分,该研究使用标准和极端蒙版验证了面部和通用图像修复方法。RePaint 在六种掩码分布中至少有五种优于 SOTA 自回归和 GAN 方法。
预备知识:去噪扩散概率模型(DDPM)
研究者使用扩散模型作为生成模型。与其他生成模型一样,DDPM 学习给定训练集中图像的分布。在推理过程中,首先采样一个随机噪声向量 x_T 并逐步对其进行去噪,直到它生成高质量输出图像 x_0。在训练过程中,DDPM 方法定义一个扩散过程,从而在 T 个时间步内将图像 x_0 转换为高斯白噪声(white Gaussian noise) x_T ∼ N (0, 1)。前向中的每一步如下公式 (1) 所示:
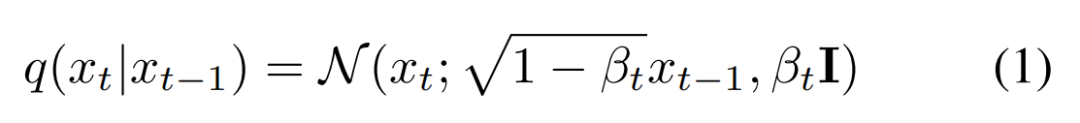
训练 DDPM 以反转公式 (1) 中的过程。反转过程通过一个「预测高斯分布参数 µ_θ(x_t, t)和Σ_θ(x_t, t)」的神经网络进行建模。具体如下公式 (2) 所示:
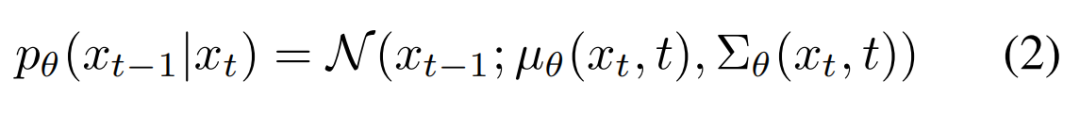
公式 (2) 中模型的学习目标通过变分下界(variational lower bound)得到,具体如下公式 (3) 所示:
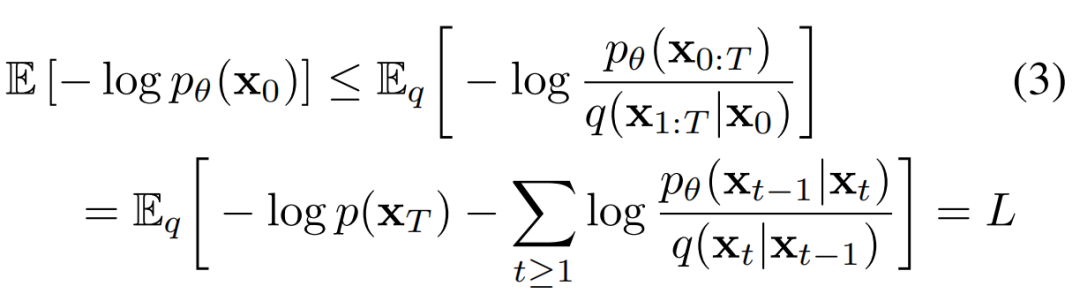
根据 Jonathan Ho 等人在论文《Denoising Diffusion Probabilistic Models》中的扩展,损失(loss)可以进一步分解为如下公式 (4) 所示:
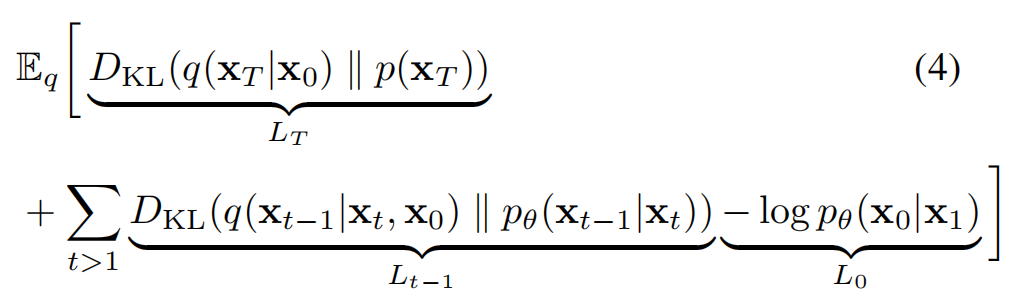
在 Jonathan Ho 等人的这篇论文中,他们认为参数化模型的最佳方法是对添加到当前中间图像 x_t 的累积噪声ϵ_0 预测。如下公式 (5) 所示,研究者对预测的平均值 µ_θ(x_t, t)进行参数化表示。
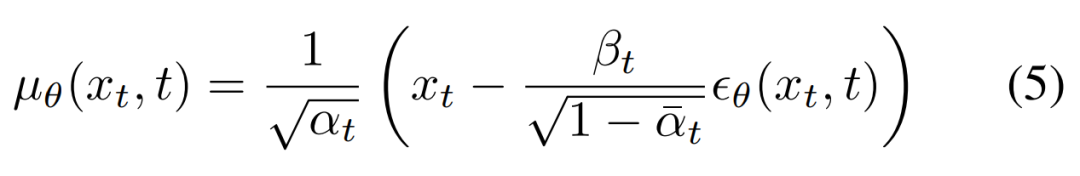
为了训练 DDPM,研究者需要一个样本 x_t 以及相应的用于将 x_0 转换为 x_t 的噪声。最后,他们可以对公式 (1) 进行重写,作为一个单步执行,具体如下公式 (7) 所示
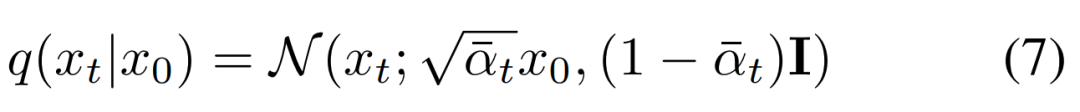
方法
已知区域的条件作用
图像修复的目标是,通过将掩码区域用作条件,预测一个图像的缺失像素。如前所述,研究者在本文中使用了一个训练过的非条件去噪扩散概率模型。
由于前向过程通过添加的高斯噪声的马尔可夫链(Markov Chain)来定义,研究者可通过定义 (7) 在任意点上采样中间图像 x_t。这使得他们在任意时间步 t 采样已知区域 m⊙x_t。因此,通过公式 (2) 处理未知区域和公式 (7) 处理已知区域,研究者得到了如下所示的反转步(reverse step)的表达式。
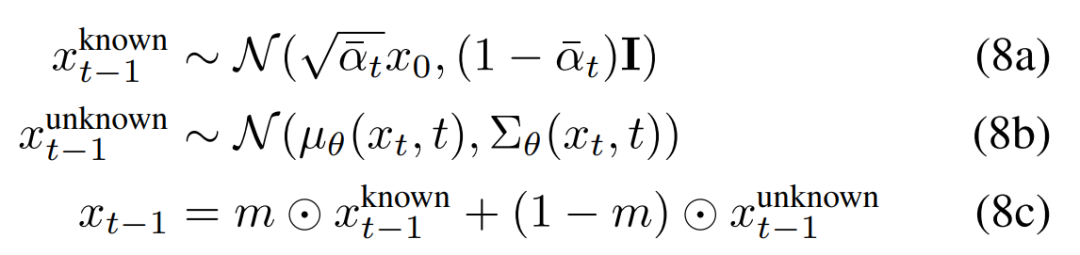
因此,研究者使用给定图像 m⊙x_0 中的已知像素对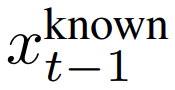 进行采样,同时在给定上次迭代 x_t 时,
进行采样,同时在给定上次迭代 x_t 时,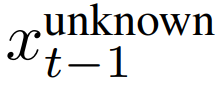 从模型中采样。
从模型中采样。
如下为使用 RePaint 方法进行图像修复的算法 1:

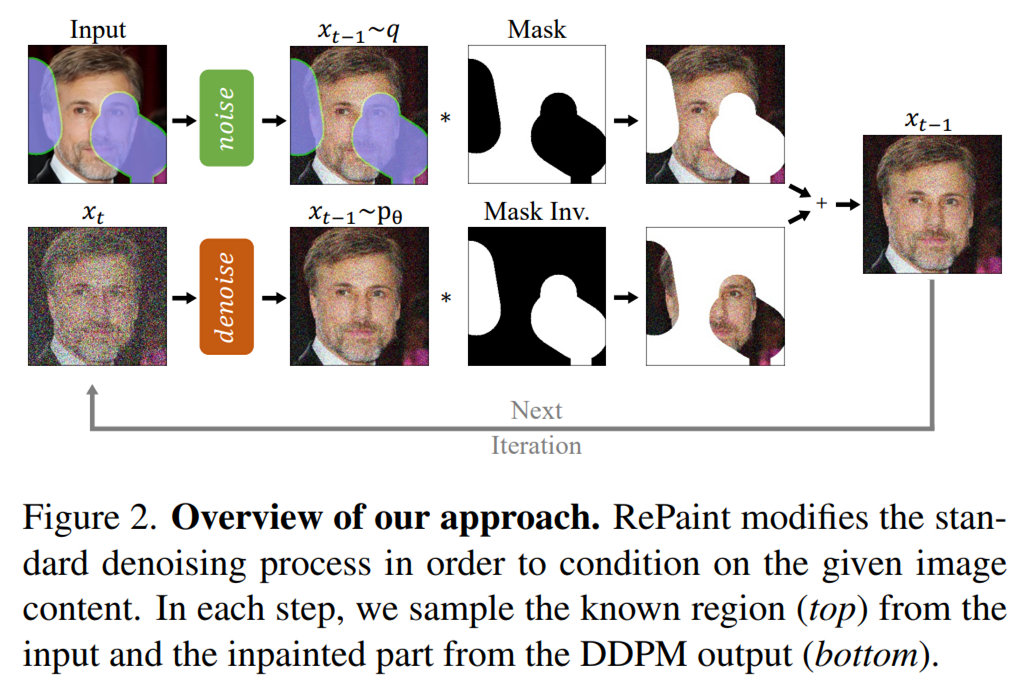
RePaint 方法的概览如下图 2 所示
重采样
当直接应用上述方法时,研究者观察到:只有内容类型(content type)与已知区域匹配。比如,在下图 3 中,当 n 为 1 时,图像修复的区域是与原始输入图像狗狗的皮毛相匹配的皮毛纹理。尽管图像修复的区域与邻近区域的纹理相匹配,但在语义上显然是不正确的。因此,虽然 DDPM 利用了已知区域的上下文,但它并没有很好地协调图像的其他部分。

由于 DDPM 被训练生成一个位于数据分布中的图像,它自然地想要生成一致性的结构。在研究者的重采样方法中,他们利用 DDPM 的这种特性来协调模型的输入。
实验结果
实验采用 V100 GPU,在 CelebA-HQ 和 Imagenet 数据集上进行了实验。表 1 中报告了定量结果,图 4 和图 5 中报告了视觉结果。
比较方法:该研究将 RePaint 与几种 SOTA 性能的基于自回归或基于 GAN 的方法进行比较。自回归方法包括 DSI 和 ICT,GAN 方法包括 DeepFillv2、AOT 和 LaMa。
宽和窄蒙版(Wide and Narrow masks):为了在标准图像修复场景中验证 RePaint,该研究使用 LaMa 设置宽和窄蒙版。在 CelebA-HQ 和 ImageNet 中,对于 Wide 和 Narrow 设置,RePaint 以 95% 的显着性裕度(margin)优于所有其他方法。
厚蒙版:类似于最近邻超分辨率问题,「Super-Resolution 2×」蒙版只留下高度和宽度维度上 stride= 2 的像素,而「Alternating Lines」蒙版每隔一行删除图像中的像素。如图 4 和 5 所示,AOT 修复完全失败,而其他的要么产生模糊的图像,要么产生可见的伪影,或者两者兼而有之。RePaint 获得了 73.1% 到 99.3% 的用户投票(一种评估方法)。
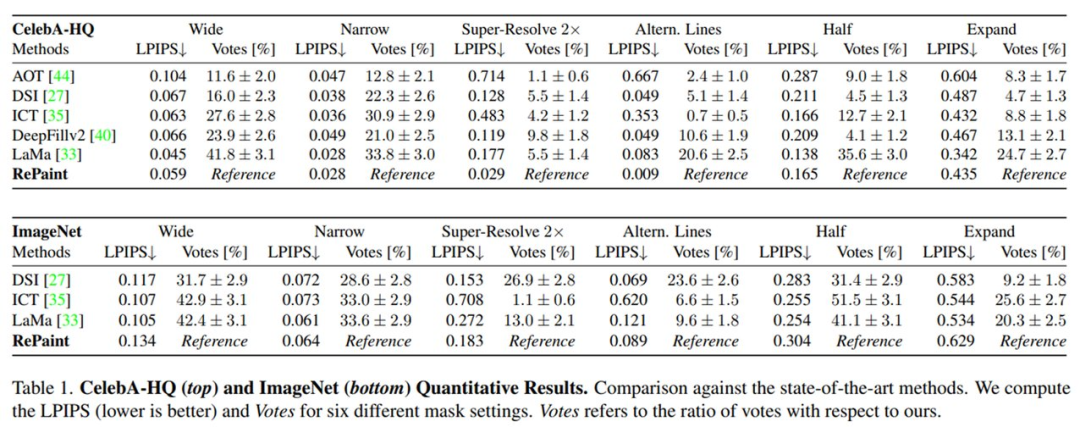


图 1 展示了 RePaint 修复的多样性和灵活性。如面部修复(下图第一行),RePaint 可以修复人物表情和特征(如耳环或痣);RePaint 还能修复电脑屏幕显示的不同图像、文本、标志等。

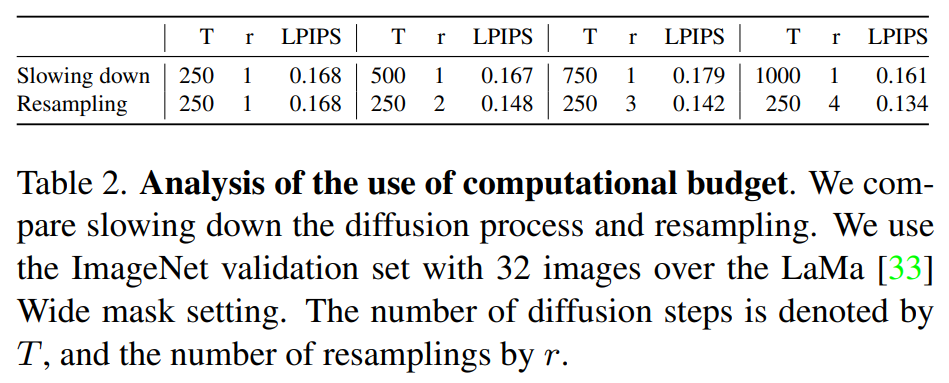
为了分析增加的计算预算是否会提高重采样性能,该研究将其与第 4.2 节中描述的缓慢扩散过程中常用技术进行了比较。图 6 和表 2 中展示了对每个设置使用相同计算预算的重采样和缓慢扩散。该研究观察到重采样使用额外的计算预算来协调图像,而在缓慢扩散过程方面没有明显的改进。

- ICCV和CVPR 2021论文和代码下载
-
- 后台回复:CVPR2021,即可下载CVPR 2021论文和代码开源的论文合集
-
- 后台回复:ICCV2021,即可下载ICCV 2021论文和代码开源的论文合集
-
- 后台回复:Transformer综述,即可下载最新的3篇Transformer综述PDF
- CVer-Transformer交流群成立
- 扫码添加CVer助手,可申请加入CVer-Transformer 微信交流群,方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch和TensorFlow等群。
- 一定要备注:研究方向+地点+学校/公司+昵称(如Transformer+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群
-
- ▲长按加小助手微信,进交流群
- ▲点击上方卡片,关注CVer公众号
整理不易,请点赞和在看

