
- 1Python抠图:使用OpenCV实现背景去除_csdn背景去除
- 2MAC下linux双系统的安装_mac 安装linux
- 3Graphpad Prism10.1.2(324) 安装教程 (含Win/Mac版)_graphpad prism v10.1.2
- 4android studio两个窗口,Android Studio多个项目窗口怎么切换?
- 5Oracle的分组查询以及子查询
- 6原子链真的太可笑了
- 7Android Studio 升级到3.1.2问题小结_dsl element 'annotationprocessoroptions.includecom
- 8计算机网络有关知识点的串接与回顾_计算机的知识怎么串联起来
- 9在马斯克成立xAI之际,有人却在质疑GPT-4变笨,大模型AI前路坎坷
- 10python调用opencv拍摄一张图片并保存到本地_hx, frame = cap.read()图片保存在哪里
用于快速图像检索的深度监督哈希_深度哈希
赞
踩
摘要
在本文中,我们提出了一种新的哈希方法来学习紧凑的二进制代码,以便在大规模数据集上进行高效的图像检索。设计了一种 CNN 架构,将成对的图像(相似/不相似)作为训练输入,并鼓励每个图像的输出接近离散值(例如 +1/-1)。设计了一个损失函数,通过对来自输入图像对的监督信息进行编码,同时对实值输出进行正则化以逼近所需的离散值,从而最大化输出空间的可辨别性。对于图像检索,新出现的查询图像可以通过网络传播轻松编码,然后将网络输出量化为二进制代码表示。
一、论文介绍
近年来,每天有数十万张图片被上传到互联网上,根据不同用户的要求,找到相关图片变得异常困难。例如,基于内容的图像检索检索与给定查询图像相似的图像,其中“相似”可以指视觉上相似或语义上相似。假设数据库中的图像和查询图像都由实值特征表示,寻找相关图像的最简单方法是根据数据库图像在特征空间中与查询图像的距离进行排序,并返回最亲近的。然而,对于如今相当普遍的具有数百万图像的数据库,即使是对数据库进行线性搜索也会耗费大量的时间和内存。
为了解决实值特征的低效率问题,提出了哈希方法将图像映射到紧凑的二进制代码,这些代码近似地保留了原始空间中的数据结构。由于图像由二进制代码而不是实值特征表示,因此可以大大减少搜索的时间和内存成本。然而,大多数现有的哈希方法的检索性能在很大程度上取决于它们使用的特征,这些特征基本上是以无监督的方式提取的,因此更适合处理视觉相似性搜索而不是语义相似性搜索。另一方面,图像分类、目标检测、人脸识别和许多其他视觉任务 的最新进展证明了 CNN 令人印象深刻的学习能力。在这些不同的任务中,CNN 可以被视为由专门为各个任务设计的目标函数引导的特征提取器。CNN 在各种任务中的成功应用意味着 CNN 学习的特征可以很好地捕获图像的潜在语义结构,尽管存在显着的外观变化。
受 CNN 功能稳健性的启发,我们提出了一种利用 CNN 结构的二进制代码学习框架,称为深度监督哈希 (DSH)。在我们的方法中,首先我们设计了一个 CNN 模型,该模型采用图像对以及指示两个图像是否与训练输入相似的标签,并生成二进制代码作为输出,如图 1 所示。在实践中,我们在线生成图像对,因此在训练阶段可以使用更多的图像对。损失函数旨在将相似图像的网络输出拉到一起,将不相似图像的输出推远,从而使学习到的汉明空间能够很好地逼近图像的语义结构。
为了避免优化汉明空间中的不可微损失函数,网络输出放松为实值,同时施加正则化器以鼓励实值输出接近所需的离散值。在这个框架下,图像可以很容易地编码,首先通过网络传播,然后将网络输出量化为二进制代码表示。
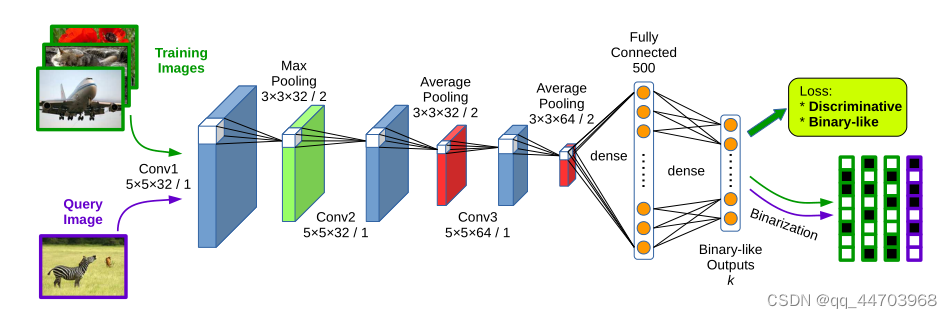
二、相关工作
1.局部敏感哈希
早期,研究人员主要关注与数据无关的哈希方法,例如称为局部敏感哈希 (LSH) [4] 的一系列方法。 LSH 方法使用随机投影来生成散列位。理论上已经证明,随着代码长度的增长,两个二进制代码之间的汉明距离逐渐接近它们在特征空间中的对应距离。然而,LSH 方法通常需要长代码才能达到令人满意的性能,这需要大量内存。
2.无监督方法
无监督方法仅利用未标记的训练数据来学习哈希函数。例如,频谱哈希 (SH) 最小化图像对的加权汉明距离,其中权重定义为图像对的相似性度量;迭代量化(ITQ)试图最小化投影图像描述符的量化误差,以减轻由实值特征空间和二值汉明空间之间的差异引起的信息丢失。
3.监督方法
提出了离散图哈希(DGH)和监督离散哈希(SDH)等方法来直接优化二进制代码,以克服松弛的缺点,并提高检索性能。
三、论文方法
我们的目标是学习图像的紧凑二进制代码,这样:(a)相似的图像应该在汉明空间中编码为相似的二进制代码,反之亦然; (b) 可以有效地计算二进制代码。
1.损失函数
相似图像的代码应尽可能接近,而不同图像的代码应远离。基于这个目标,损失函数自然被设计为将相似图像的代码拉到一起,并将不同图像的代码推开。

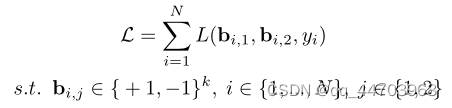
2.Relaxation
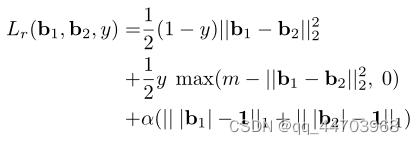
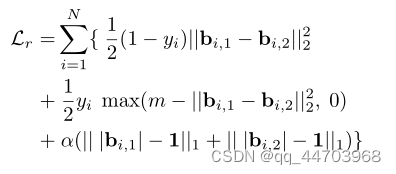
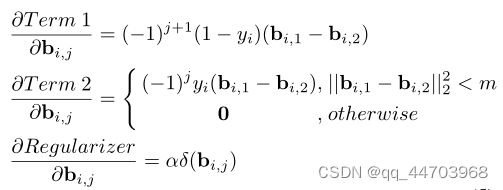
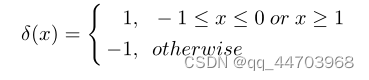
3.实施细节
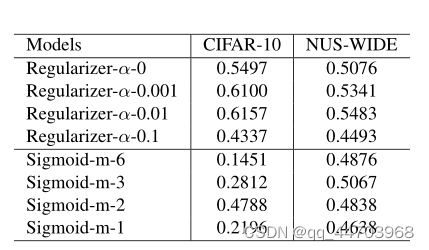
结论
我们将DSH良好的检索性能归功于三个方面。第一,非线性特征学习和哈希编码的耦合,用于提取特定任务的图像表征;第二,提出的正则器,用于减少实值网络输出空间和期望的汉明空间之间的差异;第三,在线生成的密集配对监督,用于很好地描述期望的汉明空间。在效率方面,实验表明,所提出的方法对新来图像的编码甚至比传统的散列方法更快。由于我们目前的框架是相对通用的,更复杂的网络结构也可以很容易地被利用。此外,在这项工作中对 "网络组合 "的初步研究已经证明这是一种有前途的方法,值得我们在今后的研究中进一步提高检索性能。

