
热门标签
热门文章
- 1root后怎么刷回官方,recovery刷入root_root的手机怎么刷回去
- 2用vm虚拟机连接xshell,一把过(超详细图文并茂)_vmware fedora 共享网络 xshell
- 3spark 使用python语言操作(基于pycharm的安装使用)_spark python
- 442个来自《 CSS世界》中的实用技巧
- 5C++ 用单、双链实现链表数据结构,LeetCode题_c c++ 双向链表插入一个节点 leetcode
- 6深度学习 | 关于GRU你必须知道的20个知识_加权gru
- 7“数字直角三角形”的循环简化
- 8uniapp开发H5内嵌APP,使用uni.setClipboardData实现复制功能时,安卓没问题,ios会闪一下(底部弹出弹窗)~踩坑之路_uniapp 复制不弹框
- 9深入 Java 调试体系,第 2 部分
- 10微网双层优化 储能 matlab采用matlab编程对冷热电微网系统进行双层优化
当前位置: article > 正文
使用word2vec+tensorflow自然语言处理NLP_tensorflow 完成word2vec
作者:Gausst松鼠会 | 2024-04-05 17:44:34
赞
踩
tensorflow 完成word2vec
目录
介绍:
Word2Vec是一种用于将文本转换为向量表示的技术。它是由谷歌团队于2013年提出的一种神经网络模型。Word2Vec可以将单词表示为高维空间中的向量,使得具有相似含义的单词在向量空间中距离较近。这种向量表示可以用于各种自然语言处理任务,如语义相似度计算、文本分类和命名实体识别等。Word2Vec的核心思想是通过预测上下文或预测目标词来学习词向量。具体而言,它使用连续词袋(CBOW)和跳字模型(Skip-gram)来训练神经网络,从而得到单词的向量表示。这些向量可以捕捉到单词之间的语义和语法关系,使得它们在计算机中更容易处理和比较。Word2Vec已经成为自然语言处理领域中常用的工具,被广泛应用于各种文本分析和语义理解任务中。
- import os
- os.environ['KMP_DUPLICATE_LIB_OK']='True'
-
- #Dataset 10 sentences to create word vectors
-
- corpus = ['king is a strong man',
- 'queen is a wise woman',
- 'boy is a young man',
- 'girl is a young woman',
- 'prince is a young king',
- 'princess is a young queen',
- 'man is strong',
- 'woman is pretty',
- 'prince is a boy will be king',
- 'princess is a girl will be queen']
-
- #Remove stop words
-
- def remove_stop_words(corpus):
- stop_words = ['is', 'a', 'will', 'be']
- results = []
- for text in corpus:
- tmp = text.split(' ')
- for stop_word in stop_words:
- if stop_word in tmp:
- tmp.remove(stop_word)
- results.append(" ".join(tmp))
-
- return results
-
- corpus = remove_stop_words(corpus)
-
- corpus
-
- '''结果:
- ['king strong man',
- 'queen wise woman',
- 'boy young man',
- 'girl young woman',
- 'prince young king',
- 'princess young queen',
- 'man strong',
- 'woman pretty',
- 'prince boy king',
- 'princess girl queen']
- '''

搭建上下文或预测目标词来学习词向量

- words = []
- for text in corpus:
- for word in text.split(' '):
- words.append(word)
-
- words = set(words)
-
- word2int = {}
-
- for i,word in enumerate(words):
- word2int[word] = i
- print(word2int)
- '''结果:
- {'strong': 0,
- 'wise': 1,
- 'man': 2,
- 'boy': 3,
- 'queen': 4,
- 'king': 5,
- 'princess': 6,
- 'young': 7,
- 'woman': 8,
- 'pretty': 9,
- 'prince': 10,
- 'girl': 11}
- '''
-
- sentences = []
- for sentence in corpus:
- sentences.append(sentence.split())
- print(sentences)
-
-
- WINDOW_SIZE = 2#距离为2
-
- data = []
- for sentence in sentences:
- for idx, word in enumerate(sentence):
- for neighbor in sentence[max(idx - WINDOW_SIZE, 0) : min(idx + WINDOW_SIZE, len(sentence)) + 1] :
- if neighbor != word:
- data.append([word, neighbor])
- print(data)
-
- data
- '''结果:
- [['king', 'strong'],
- ['king', 'man'],
- ['strong', 'king'],
- ['strong', 'man'],
- ['man', 'king'],
- ['man', 'strong'],
- ['queen', 'wise'],
- ['queen', 'woman'],
- ['wise', 'queen'],
- ['wise', 'woman'],
- ['woman', 'queen'],
- ['woman', 'wise'],
- ['boy', 'young'],
- ['boy', 'man'],
- ['young', 'boy'],
- ['young', 'man'],
- ['man', 'boy'],
- ['man', 'young'],
- ['girl', 'young'],
- ['girl', 'woman'],
- ['young', 'girl'],
- ['young', 'woman'],
- ['woman', 'girl'],
- ['woman', 'young'],
- ['prince', 'young'],
- ['prince', 'king'],
- ['young', 'prince'],
- ['young', 'king'],
- ['king', 'prince'],
- ['king', 'young'],
- ['princess', 'young'],
- ['princess', 'queen'],
- ['young', 'princess'],
- ['young', 'queen'],
- ['queen', 'princess'],
- ['queen', 'young'],
- ['man', 'strong'],
- ['strong', 'man'],
- ['woman', 'pretty'],
- ['pretty', 'woman'],
- ['prince', 'boy'],
- ['prince', 'king'],
- ['boy', 'prince'],
- ['boy', 'king'],
- ['king', 'prince'],
- ['king', 'boy'],
- ['princess', 'girl'],
- ['princess', 'queen'],
- ['girl', 'princess'],
- ['girl', 'queen'],
- ['queen', 'princess'],
- ['queen', 'girl']]
- '''
搭建X,Y
- import pandas as pd
- for text in corpus:
- print(text)
-
- df = pd.DataFrame(data, columns = ['input', 'label'])
-
-
- word2int
-
- #Define Tensorflow Graph
- import tensorflow as tf
- import numpy as np
-
- ONE_HOT_DIM = len(words)
-
-
- # function to convert numbers to one hot vectors
- def to_one_hot_encoding(data_point_index):
- one_hot_encoding = np.zeros(ONE_HOT_DIM)
- one_hot_encoding[data_point_index] = 1
- return one_hot_encoding
-
- X = [] # input word
- Y = [] # target word
-
- for x, y in zip(df['input'], df['label']):
- X.append(to_one_hot_encoding(word2int[ x ]))
- Y.append(to_one_hot_encoding(word2int[ y ]))
-
- # convert them to numpy arrays
- X_train = np.asarray(X)
- Y_train = np.asarray(Y)
建模1:
- import tensorflow.compat.v1 as tf
- tf.disable_v2_behavior()
-
-
- # making placeholders for X_train and Y_train
- x = tf.placeholder(tf.float32, shape=(None, ONE_HOT_DIM))
- y_label = tf.placeholder(tf.float32, shape=(None, ONE_HOT_DIM))
-
- # word embedding will be 2 dimension for 2d visualization
- EMBEDDING_DIM = 2
-
- # hidden layer: which represents word vector eventually
- W1 = tf.Variable(tf.random_normal([ONE_HOT_DIM, EMBEDDING_DIM]))
- b1 = tf.Variable(tf.random_normal([1])) #bias
- hidden_layer = tf.add(tf.matmul(x,W1), b1)
-
- # output layer
- W2 = tf.Variable(tf.random_normal([EMBEDDING_DIM, ONE_HOT_DIM]))
- b2 = tf.Variable(tf.random_normal([1]))
- prediction = tf.nn.softmax(tf.add( tf.matmul(hidden_layer, W2), b2))
-
- # loss function: cross entropy
- loss = tf.reduce_mean(-tf.reduce_sum(y_label * tf.log(prediction), axis=[1]))
-
- # training operation
- train_op = tf.train.GradientDescentOptimizer(0.05).minimize(loss)
-
-
- sess = tf.Session()
- init = tf.global_variables_initializer()
- sess.run(init)
-
- iteration = 20000
- for i in range(iteration):
- # input is X_train which is one hot encoded word
- # label is Y_train which is one hot encoded neighbor word
- sess.run(train_op, feed_dict={x: X_train, y_label: Y_train})
- if i % 3000 == 0:
- print('iteration '+str(i)+' loss is : ', sess.run(loss, feed_dict={x: X_train, y_label: Y_train}))
-
- # Now the hidden layer (W1 + b1) is actually the word look up table
- vectors = sess.run(W1 + b1)
- print(vectors)
-
-
-
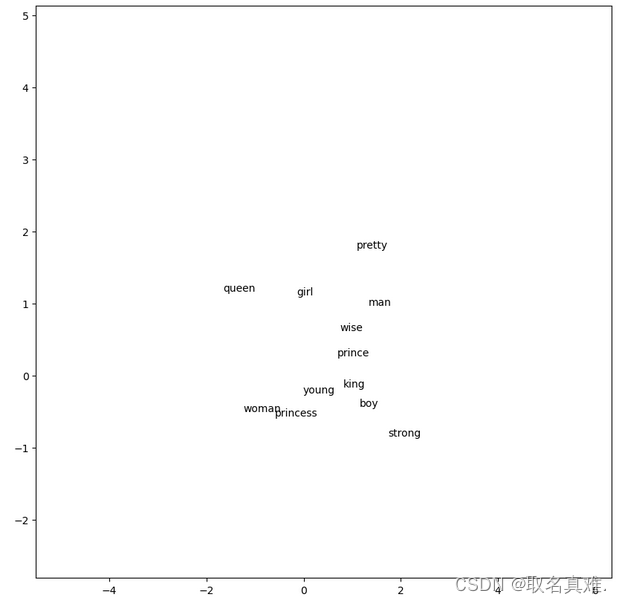
- import matplotlib.pyplot as plt
-
- fig, ax = plt.subplots()
-
- for word, x1, x2 in zip(words, w2v_df['x1'], w2v_df['x2']):
- ax.annotate(word, (x1,x2 ))
-
- PADDING = 1.0
- x_axis_min = np.amin(vectors, axis=0)[0] - PADDING
- y_axis_min = np.amin(vectors, axis=0)[1] - PADDING
- x_axis_max = np.amax(vectors, axis=0)[0] + PADDING
- y_axis_max = np.amax(vectors, axis=0)[1] + PADDING
-
- plt.xlim(x_axis_min,x_axis_max)
- plt.ylim(y_axis_min,y_axis_max)
- plt.rcParams["figure.figsize"] = (10,10)
-
- plt.show()

建模2:
- # Deep learning:
- from tensorflow.python.keras.models import Input
- from keras.models import Model
- from keras.layers import Dense
-
- # Defining the size of the embedding
- embed_size = 2
-
- # Defining the neural network
- #inp = Input(shape=(X.shape[1],))
- #x = Dense(units=embed_size, activation='linear')(inp)
- #x = Dense(units=Y.shape[1], activation='softmax')(x)
- xx = Input(shape=(X_train.shape[1],))
- yy = Dense(units=embed_size, activation='linear')(xx)
- yy = Dense(units=Y_train.shape[1], activation='softmax')(yy)
- model = Model(inputs=xx, outputs=yy)
- model.compile(loss = 'categorical_crossentropy', optimizer = 'adam')
-
- # Optimizing the network weights
- model.fit(
- x=X_train,
- y=Y_train,
- batch_size=256,
- epochs=1000
- )
-
- # Obtaining the weights from the neural network.
- # These are the so called word embeddings
-
- # The input layer
- weights = model.get_weights()[0]
-
- # Creating a dictionary to store the embeddings in. The key is a unique word and
- # the value is the numeric vector
- embedding_dict = {}
- for word in words:
- embedding_dict.update({
- word: weights[df.get(word)]
- })
-
-
- import matplotlib.pyplot as plt
-
- fig, ax = plt.subplots()
-
- #for word, x1, x2 in zip(words, w2v_df['x1'], w2v_df['x2']):
- for word, x1, x2 in zip(words, weights[:,0], weights[:,1]):
- ax.annotate(word, (x1,x2 ))
-
- PADDING = 1.0
- x_axis_min = np.amin(vectors, axis=0)[0] - PADDING
- y_axis_min = np.amin(vectors, axis=0)[1] - PADDING
- x_axis_max = np.amax(vectors, axis=0)[0] + PADDING
- y_axis_max = np.amax(vectors, axis=0)[1] + PADDING
-
- plt.xlim(x_axis_min,x_axis_max)
- plt.ylim(y_axis_min,y_axis_max)
- plt.rcParams["figure.figsize"] = (10,10)
-
- plt.show()
预测:
- X_train[2]
- #结果:array([1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.]) strong
-
- model.predict(X_train)[2]
- '''结果:
- array([0.07919139, 0.0019384 , 0.48794392, 0.05578128, 0.00650001,
- 0.10083131, 0.02451131, 0.03198219, 0.04424168, 0.0013569 ,
- 0.16189449, 0.00382716], dtype=float32) 预测结果:man
- '''
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/Gausst松鼠会/article/detail/367113
推荐阅读
相关标签

