
- 1数学建模常用算法—马尔可夫预测_马尔可夫算法
- 2PHP(9):将上传的Word文件保存到MS SQL Server数据库_上传word文件到数据库
- 3C++ lambda表达式_c++ lambda 表达式
- 4Salesforce系列(0):Salesforce导入数据!_sales force inspector安装
- 5Langchain 的 Structured output parser_langchain structuredoutputparser
- 6软件测试-工作流程(需求分析评审、测试计划、测试用例、用例评审、执行测试、跟踪定位bug、测试报告、缺陷报告)_1.获取需求分析书 2.进行需求评审 3.编写测试用例 4.进行测试用例的执行 5.进行bu
- 7基于SSM的红色文化展示小程序系统设计与实现【包调试】_文化展示小程序论坛界面
- 8重磅!教育部再次审批179所高校新增本科AI专业
- 9基于蜣螂算法改进的DELM分类-附代码_蜣螂优化算法深度极限学习机
- 10Xcode - VALID_ARCHS_xcode valid_archs
6种java垃圾回收算法_Java垃圾回收算法
赞
踩
主要根据以下3篇博客做的整理
http://blog.csdn.net/zsuguangh/article/details/6429592
http://www.cnblogs.com/ywl925/p/3925637.html
http://blog.csdn.net/zouxinfox/article/details/1594216
总的来说分为两大类,引用计数法和跟踪法
1、引用计数法
使用引用计数器来区分活对象和不再使用的对象。
堆中的每个对象对应一个引用计数器。每当创建一个对象并赋给一个变量时,引用计数器置为1。当对象被赋给任意变量时,引用计数器加1;当对象出了作用域后(该对象丢弃不再使用),引用计数器减1;一旦引用计数器为0,对象就满足了垃圾收集的条件。
优点:垃圾收集快,试用于实时环境。
缺点:无法检测出循环引用。
2、跟踪法
tracing算法是为了解决引用计数法无法检测出循环引用的问题而提出,它使用了根集的概念。
这种方法把每个对象看作图中一个节点,对象之间的引用关系为图中各节点的邻接关系。从根集开始扫描,识别出哪些对象可达,哪些对象不可达,并用某种方式标记可达对象。
优点:能检测出循环引用,较为常用。
下面是一些常用的垃圾回收算法
1、标记-清除收集器
这种收集器首先遍历对象图并标记可到达的对象,然后扫描堆栈以寻找未标记对象并释放它们的内存。这种收集器一般使用单线程工作并停止其他操作。并且,由于它只是清除了那些未标记的对象,而并没有对标记对象进行压缩,导致会产生大量内存碎片,从而浪费内存。
2、标记-压缩收集器
有时也叫标记-清除-压缩收集器,与标记-清除收集器有相同的标记阶段。在第二阶段,则把标记对象复制到堆栈的新域中以便压缩堆栈。这种收集器也停止其他操作。
3、复制收集器
该算法的提出是为了克服句柄的开销和解决堆碎片的垃圾回收。它开始时把堆分成一个对象区和多个空闲区,程序从对象区为对象分配空间,当对象满了,基于coping算法的垃圾回收就从根集中扫描活动对象,并将每个活动对象复制到空闲区(使得活动对象所占的内存之间没有空闲间隔),这样空闲区变成了对象区,原来的对象区变成了空闲区,程序会在新的对象区中分配内存。
一种典型的基于coping算法的垃圾回收是stop-and-copy算法,它将堆分成对象区和空闲区域区,在对象区与空闲区域的切换过程中,程序暂停执行。
4、增量收集器
增量收集器把堆栈分为多个域,每次仅从一个域收集垃圾。这会造成较小的应用程序中断。
5、分代收集器
stop-and-copy垃圾收集器的一个缺陷是收集器必须复制所有的活动对象,这增加了程序等待时间,这是coping算法低效的原因。在程序设计中有这样的规律:多数对象存在的时间比较短,少数的存在时间比较长。因此,generation算法将堆分成两个或多个,每个子堆作为对象的一代 (generation)。由于多数对象存在的时间比较短,随着程序丢弃不使用的对象,垃圾收集器将从最年轻的子堆中收集这些对象。在分代式的垃圾收集器运行后,上次运行存活下来的对象移到下一最高代的子堆中,由于老一代的子堆不会经常被回收,因而节省了时间。
6、自适应收集器
在特定的情况下,一些垃圾收集算法会优于其它算法。基于Adaptive算法的垃圾收集器就是监控当前堆的使用情况,并将选择适当算法的垃圾收集器。
7、并发收集器
并发收集器与应用程序同时运行。这些收集器在某点上(比如压缩时)一般都不得不停止其他操作以完成特定的任务,但是因为其他应用程序可进行其他的后台操作,所以中断其他处理的实际时间大大降低。
8、并行收集器
并行收集器使用某种传统的算法并使用多线程并行的执行它们的工作。在多CPU机器上使用多线程技术可以显著的提高java应用程序的可扩展性。
例子:火车算法
垃圾收集算法一个很大的缺点就是难以控制垃圾回收所占用的时间,以及何时需要进行垃圾回收。火车算法是分代收集器所用的算法,目的是在成熟对象空间中提供限定时间的渐进收集。目前应用于Hotspot虚拟机上。
在火车算法中,内存被分为块,多个块组成一个集合。为了形象化,一节车厢代表一个块,一列火车代表一个集合,见图一
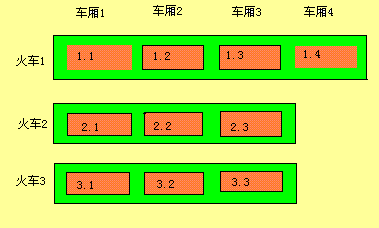
注意每个车厢大小相等,但每个火车包含的车厢数不一定相等。垃圾收集以车厢为单位,收集顺序依次为。这个顺序也是块被创建的先后顺序。
垃圾收集器先从块开始扫描直到,如果火车四个块中的所有对象没有被火车的对象引用,而只有火车内部的对象相互引用,则整个火车都是垃圾,可以被回收。
如图二,车厢,可见,火车没有引用火车的对象,则整个火车都是垃圾。
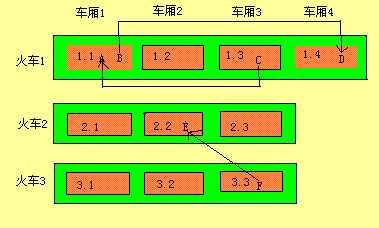
中有对象被其它火车引用,见图三,扫描车厢时发现对象引用,则将对象转移到车厢,然后扫描引用的对象也转移到车厢,然后扫描是否引用其它对象,如果引用了其它对象则也要转移,依次类推。扫描完火车的所有对象后,剩下的没有转移的对象都是垃圾,可以把整个火车都作为垃圾回收。注意如果在转移时,如果车厢空间满了,则要在火车末尾开辟新的车厢,将新转移的对象都放到,即火车的尾部)
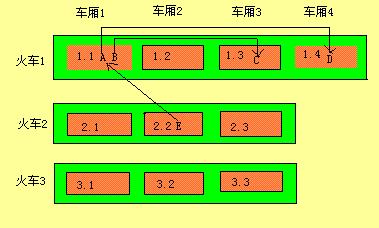
补充说明:垃圾回收器一次只扫描一个车厢。图三中的对象B与C并不是立即被回收,而是先会被转移到火车1的尾部车厢。即扫描完1.1后,B被转移到火车1尾部,扫描完1.3后,C被转移到车尾。等垃圾收集器扫描到火车1尾部时,如果仍然没有外部对象引用它们,则B和C会被收集。
火车算法最大的好处是它可以保证大的循环结构可以被完全收集,因为成为垃圾的循环结构中的对象,无论多大,都会被移入同一列火车,最终一起被收集。还有一个好处是这种算法在大多数情况下可以保证一次垃圾收集所耗时间在一定限度之内,因为一次垃圾回收只收集一个车厢,而车厢的大小是有限度的。
程序中减少gc开销的措施
根据上述GC的机制,程序的运行会直接影响系统环境的变化,从而影响GC的触发。若不针对GC的特点进行设计和编码,就会出现内存驻留等一系列负面影响。为了避免这些影响,基本的原则就是尽可能地减少垃圾和减少GC过程中的开销。具体措施包括以下几个方面:
(1)不要显式调用System.gc()
此函数建议JVM进行主GC,虽然只是建议而非一定,但很多情况下它会触发主GC,从而增加主GC的频率,也即增加了间歇性停顿的次数。
(2)尽量减少临时对象的使用
临时对象在跳出函数调用后,会成为垃圾,少用临时变量就相当于减少了垃圾的产生,从而延长了出现上述第二个触发条件出现的时间,减少了主GC的机会。
(3)对象不用时最好显式置为Null
一般而言,为Null的对象都会被作为垃圾处理,所以将不用的对象显式地设为Null,有利于GC收集器判定垃圾,从而提高了GC的效率。
(4)尽量使用StringBuffer,而不用String来累加字符串
由于String是固定长的字符串对象,累加String对象时,并非在一个String对象中扩增,而是重新创建新的String对象,如Str5=Str1+Str2+Str3+Str4,这条语句执行过程中会产生多个垃圾对象,因为对次作“+”操作时都必须创建新的String对象,但这些过渡对象对系统来说是没有实际意义的,只会增加更多的垃圾。避免这种情况可以改用StringBuffer来累加字符串,因StringBuffer是可变长的,它在原有基础上进行扩增,不会产生中间对象。
(5)能用基本类型如Int,Long,就不用Integer,Long对象
基本类型变量占用的内存资源比相应对象占用的少得多,如果没有必要,最好使用基本变量。
(6)尽量少用静态对象变量
静态变量属于全局变量,不会被GC回收,它们会一直占用内存。
(7)分散对象创建或删除的时间
集中在短时间内大量创建新对象,特别是大对象,会导致突然需要大量内存,JVM在面临这种情况时,只能进行主GC,以回收内存或整合内存碎片,从而增加主GC的频率。集中删除对象,道理也是一样的。它使得突然出现了大量的垃圾对象,空闲空间必然减少,从而大大增加了下一次创建新对象时强制主GC的机会。

