
热门标签
热门文章
- 1如何蹭ChatGPT热度发一篇顶会?(附论文+电子书籍)
- 2mac设置环境变量.bash_profile 或 /usr/local_mac .bash_profile在哪里
- 3APP安卓开发之Android Studio从安装到创建项目(一键解决gradle下载缓慢以及写代码没提示问题,包含如何创建手机模拟器)教程_android stuido 搭建一个项目
- 4docker部署访问postgres数据库(一次到位)_用虚拟机安装的docker pull报错 connection reset by peer
- 5MYSQL索引创建时机和不适用的时机
- 6GRU 门控循环单元_gru重置门和更新门
- 7【大模型】大模型发展历程,从GPT开始到Grok-1.5霸榜
- 8国内外各大免费搜索引擎、导航网址提交入口_农夫导航
- 9SpringBoot 实现跨域的六种方式_springboot设置跨域
- 10STM32智能小车(循迹、跟随、避障、测速、蓝牙、wife、4g、语音识别)总结_stm32智能跟随小车
当前位置: article > 正文
进阶大数据架构师学习路线
作者:Gausst松鼠会 | 2024-04-17 08:32:14
赞
踩
大数据架构师学习

- 文末有惊喜
大数据架构师成神之路【持续优化更新】
进阶大数据架构师学习路线
前言
每个人学习需要给自己一个路线图,如何学习大数据,相信下面的学习路线图能对你有帮助。
关注公众号【三帮大数据】回复“大数据” 可领取高清的进阶大数据架构师学习路线图
一、大数据初级架构师之Java生态技术及架构核心技能体系
1、 Java企业级开发必备核心技能之Java SE生态体系
-
1.1、Java SE 体系之Java根基
- 1.1.1、计算机发展历史与Java体系结构
- 1.1.2、Java核心机制之垃圾收集机制原理剖析
- 1.1.3、Java跨平台原理与DOS命令剖析
- 1.1.4、Java 代码编译方式与执行原理
- 1.1.5、Java 数据类型、标识符与关键字详解
https://lansonli.blog.csdn.net/article/details/109687212
- 1.1.6、Java 中各类运算符及案例实战
- 1.1.7、流程控制之判断、循环结构详解
https://lansonli.blog.csdn.net/article/details/109706790
https://lansonli.blog.csdn.net/article/details/109831342
- 1.1.8、数组引用与数组案例实战详解
https://lansonli.blog.csdn.net/article/details/114858785
- 1.1.9、IDEA 代码工具配置、工具模板、断点调试实战
-
1.2、Java SE体系之面向对象
- 1.2.1、Java面相对象之封装、继承、多态
https://lansonli.blog.csdn.net/article/details/115260142
- 1.2.2、Java面相对象之关键字系列详解
- 1.2.3、Java面相对象之继承对象内存分析
- 1.2.4、Java面相对象之容器详解
- 1.2.5、Java面相对象之编译及运行时详解
- 1.2.6、Java面相对象之常用类关键点详细分析
-
1.3、Java SE体系之异常、集合
- 1.3.1、使用try-catch-finally 一招捕获程序异常
- 1.3.2、使用throw声明和抛出异常
- 1.3.3、异常机制关键之异常继承体系
- 1.3.4、异常机制关键之运行编译异常
- 1.3.5、异常机制关键之自定义异常
- 1.3.6、Java实战开发常用类详解
- 1.3.7、Java实战开发集合体系及实战剖析
-
1.4、Java SE体系之IO流及多线程
- 1.4.1、IO流之字节输入及输出流实战应用
- 1.4.2、IO流之字符输入及输出流实战应用
- 1.4.3、IO流之字节流、字符流、缓冲流转换实操
- 1.4.4、IO流之打印流、对象流、序列化流实战应用
- 1.4.5、多线程之线程、进程实现方式
- 1.4.6、多线程之线程生命周期分析
- 1.4.7、多线程之线程同步与死锁分析
- 1.4.8、多线程之实现线程池代码实操
2、 Java企业级开发必备核心技能之Java EE生态体系
- 2.1、Java EE生态体系之数据库
- 2.1.1、数据库核心之SQL实操演练
- 2.1.2、数据库核心之表、约束、索引原理及实操演练
- 2.1.3、数据库核心之JDBC与数据库整合代码分层实操演练
- 2.1.4、数据库核心之反射技术实现与封装原理
- 2.1.5、数据库核心之数据库连接池原理分析
- 2.1.6、数据库核心之Druid&hikariCP索引原理分析
- 2.1.7、数据库核心之日志架构实操演练
- 2.1.8、数据库核心之SQL优化分析
- 2.1.9、数据库核心之分布式数据库事务原理
- 2.1.10、数据库核心之主从复制集群搭建演练
- 2.1.11、数据库核心之shardingsphere原理分析
- 2.2、Java EE生态体系之数据库连接
- 2.2.1、数据库连接之JDBC使用及异常剖析
- 2.2.2、数据库连接之实体封装及查询剖析
- 2.2.3、数据库连接之JDBC攻防测试分析
- 2.2.4、数据库连接之批处理与事务控制
- 2.2.5、数据库连接之数据库连接池配置与实现剖析
- 2.2.6、数据库连接之范式详解与实战案例分析
- 2.3、Java EE生态体系之Maven、GIT
- 2.3.1、高端研发必备技能之Maven原理与项目结构
- 2.3.2、高端研发必备技能之项目类型POM配置解析
- 2.3.3、高端研发必备技能之Maven远程仓库配置实操
- 2.3.4、高端研发必备技能之Maven插件详解
- 2.3.5、高端研发必备技能之Logback原理及配置实操
- 2.3.6、高端研发必备技能之Logback文件、数据库输出实操
- 2.3.7、高端研发必备技能之GIT版本库控制实操
- 2.3.8、高端研发必备技能之GIT远程仓库原理及应用实操
- 2.3.9、高端研发必备技能之GIT分支原理及应用实操
- 2.3.10、高端研发背背技能之GIT标签、建库实战应用
- 2.4、Java EE生态体系之企业级WEB开发
- 2.4.1、企业级开发之MyBatis配置与使用详解
- 2.4.2、企业级开发之MyBatis多级缓存与配置编译详解
- 2.4.3、企业级开发之Spring 原理剖析及代码实操
- 2.4.4、企业级开发之SpringMVC原理剖析及代码实操
- 2.4.5、企业级开发之SpringBoot原理及代码实战
- 2.4.6、企业级开发之SpringBoot与其他框架整合开发实战
3、抽丝剥茧架构底层技术体系深度剖析
- 3.1、底层技术之JVM调优
- 3.1.1、JVM class文件格式核心深度剖析
- 3.1.2、Class加载过程底层核心剖析
- 3.1.3、Java内存模型核心详解
- 3.1.4、内存屏障与JVM指令详解
- 3.1.5、Java运行时数据区和常用指令核心详解
- 3.1.6、JVM调优GC Collector-三色标记详解
- 3.1.7、企业级JVM调优实践
- 3.1.8、JVM实战调优核心点深度剖析
- 3.1.9、JVM实战调优源码级剖析
- 3.1.10、垃圾回收算法剖析
- 3.1.11、JVM常见参数详解
- 3.2、底层技术之多线程与高并发
- 3.2.1、单机高并发核心之线程状态
- 3.2.2、单机高并发核心之异常与锁底层详解
- 3.2.3、解析自旋锁CAS操作核心剖析
- 3.2.4、volatile底层核心深度剖析
- 3.2.5、JUC 同步机制之Latch核心剖析
- 3.2.6、JUC 同步机制之Semaphore核心剖析
- 3.2.7、LockSupport底层核心深度剖析
- 3.2.8、互联网大厂高频面试题详解
- 3.2.9、强软弱虚四种引用以及ThreadLocal的原理与源码
- 3.2.10、线程池高并发容器CopyOnWriteList,BlockingQueue详解
- 3.2.11、自定义线程池、JDK自带线程池、ForkJoin,源码解析详细剖析
- 3.2.12、单机压测工具JMH、单机最快MQ - Disruptor原理解析
- 3.3、底层技术之网络通信与IO
- 3.3.1、虚拟文件系统核心深度剖析
- 3.3.2、文件描述符、IO重定向深度剖析
- 3.3.3、内核中PageCache、mmap原理深度剖析
- 3.3.4、java文件系统io、nio、内存中缓冲区深度剖析
- 3.3.5、Socket编程BIO及TCP参数详解
- 3.3.6、C10K问题及NIO精讲和IO模型性能压测
- 3.3.7、网络编程之多路复用器及Epoll精讲
- 3.3.8、网络编程java API 实战多路复用器开发
- 3.3.9、全手写急速理解Netty模型及IO模型应用企业级实战
- 3.3.10、Netty之IO模型开发本质手写部分实现推导
- 3.3.11、基于Netty的RPC框架自定义协议,连接池
- 3.3.12、基于Netty的RPC框架协议编解码问题 粘包拆包与内核关系
- 3.3.13、基于Netty的RPC框架provider端简单dispatcher实现RPC调用全流程
- 3.3.14、基于Netty的RPC框架简单重构框架分层及RPC传输的本质及有无状态的RPC区别
4、数据结构与算法技术体系
- 4.1、算法高频大厂面试内容
- 4.1.1、数据结构之链表结构与原理
- 4.1.2、数据结构之栈结构与原理
- 4.1.3、数据结构之队列结构与原理
- 4.1.4、数据结构之二叉树结构与原理
- 4.1.5、数据结构之图结构与原理
- 4.1.6、算法核心之算法复杂度
- 4.1.7、算法核心之对数器
- 4.1.8、算法核心之二分法异或运算原理分析
- 4.1.9、算法核心之递归、哈希、有序操作原理
- 4.1.10、算法核心之归并与随机排序区别对比
- 4.1.11、算法核心之贪心算法
- 4.1.12、算法核心之并查集结构
- 4.1.13、算法核心之暴力递归
- 4.1.14、算法核心之动态规划
- 4.1.15、算法核心之kmp算法
- 4.1.16、算法核心之manacher算法
- 4.1.17、算法核心之bfprt算法
- 4.1.18、算法核心之蓄水池算法
- 4.1.19、算法核心之LRU内存替换算法
- 4.1.20、各类算法之详实实战案例详解
- 4.1.21、leetcode高频大厂面试题详解
二、进阶中级大数据架构生态技术体系
1、大数据EB级架构设计之Linux操作系统体系篇
- 1.1、Liunx核心命令及脚本编程实战剖析
- 1.1.1、Linux核心命令
- 1.1.1.1、Linux核心之Linux内核与GUN介绍
- 1.1.1.2、Linux核心之虚拟网络编辑器
- 1.1.1.3、Linux核心之多主机网络通信原理与配置实操
- 1.1.1.4、Linux核心之虚拟化管理快照
- 1.1.1.5、Linux核心之Linux克隆实操
- 1.1.1.6、Linux核心之SSH客户端使用与案例实操演练
- 1.1.1.7、Linux核心命令之help命令与案例实操演练
- 1.1.1.8、Linux核心命令之man命令与案例实操演练
- 1.1.1.9、Linux核心命令之df/du命令与案例实操演练
- 1.1.1.10、Linux核心命令之扩展命令与案例实操演练
- 1.1.1.11、Linux核心命令之文件操作命令与案例实操演练
- 1.1.1.12、Linux核心命令之vi命令与案例实操演练
- 1.1.1.13、Linux核心命令之grep命令与案例实操演练
- 1.1.1.14、Linux核心命令之cut命令与案例实操演练
- 1.1.1.15、Linux核心命令之sort命令与案例实操演练
- 1.1.1.16、Linux核心命令之wc命令与案例实操演练
- 1.1.1.17、Linux核心命令之sed命令与案例实操演练
- 1.1.1.18、Linux核心命令之awk命令与案例实操演练
- 1.1.1.19、Linux核心之日志文件追踪
- 1.1.2、Linux系统管理
- 1.1.2.1、系统管理之服务配置文件详解
- 1.1.2.2、系统管理之用户、组、权限管理详解
- 1.1.2.3、系统管理之多用户资源绑定案例实操演练
- 1.1.2.4、系统管理之网络进程管理详解
- 1.1.2.5、系统管理之后台服务管理详解
- 1.1.2.6、系统管理之操作系统软件安装实战演练
- 1.1.2.7、系统管理之源码编译原理及安装演练
- 1.1.2.8、系统管理之RPM包管理机制详解
- 1.1.2.9、系统管理之YUM仓库管理机制详解
- 1.1.2.10、系统管理之本地、局域网仓库源配置实操
- 1.1.3、Shell脚本编程
- 1.1.3.1、Shell编程核心之Shell原理、命令介绍
- 1.1.3.2、Shell编程核心之解释器的执行方式
- 1.1.3.3、Shell编程核心之函数、内部命令、外部命令实操
- 1.1.3.4、Shell编程核心之文件描述符与重定向
- 1.1.3.5、Shell编程核心之输出重定向各种方式详解
- 1.1.3.6、Shell编程核心之输入重定向各种方式详解
- 1.1.3.7、Shell编程核心之重定向http协议到网站请求案例实战演练
- 1.1.3.8、Shell编程核心之本地、局部变量、特殊变量详解
- 1.1.3.9、Shell编程核心之父子进程、环境变量
- 1.1.3.10、Shell编程核心之linux中for进程原理
- 1.1.3.11、Shell编程核心之管道的子进程执行原理
- 1.1.3.12、Shell编程核心之引用、命令替换扩展
- 1.1.3.13、Shell编程核心之命令状态与逻辑判断
- 1.1.3.14、Shell编程核心之算数表达式及bash扩展
- 1.1.3.15、Shell编程核心之流程控制语句
- 1.1.3.16、Shell编程核心之bash词的拆分扩展
- 1.1.3.17、Shell编程核心之脚本编程代码实操演练
- 1.1.3.18、Shell编程核心之解释器的多种命令扩展
- 1.1.1、Linux核心命令
- 1.2、Linux网络原理及高可用、高负载处理实战剖析
- 1.2.1、Linux 网络
- 1.2.1.1、TCP/IP协议资深讲解之应用层原理
- 1.2.1.2、TCP/IP协议资深讲解之传输控制层原理
- 1.2.1.3、TCP/IP协议资深讲解之TCP协议/报文/三次握手
- 1.2.1.4、TCP/IP协议资深讲解之网络层
- 1.2.1.5、TCP/IP协议资深讲解之路由表和IP协议原理
- 1.2.1.6、TCP/IP协议资深讲解之链路层
- 1.2.1.7、TCP/IP协议资深讲解之ARP协议及交换机协议
- 1.2.1.8、Linux网络之NAT网络原理
- 1.2.1.9、LVS负载之的DNAT模式分析
- 1.2.1.10、LVS负载之DR模式分析
- 1.2.1.11、LVS负载之TUN模式分析
- 1.2.1.12、LVS负载之静态调度算法
- 1.2.1.13、LVS负载之动态调度算法
- 1.2.1.14、LVS负载之内核配置ARP协议
- 1.2.1.15、LVS负载之命令讲解
- 1.2.1.16、LVS负载之LVS的DR模式实验搭建
- 1.2.2、高可用与负载均衡
- 1.2.2.1、高可用之高并发及解决方案概述
- 1.2.2.2、高可用之健康检查及故障迁移策略
- 1.2.2.3、高可用之分布式选主策略
- 1.2.2.4、高可用之keepalived原理
- 1.2.2.5、高可用之keepalived配置文件详解
- 1.2.2.6、基于keepalived的高可用LVS实战演练
- 1.2.2.7、基于keepalived的高可用后端健康检查验证
- 1.2.2.8、单点性能压力下的面向服务开发理论
- 1.2.2.9、反向代理服务器原理
- 1.2.2.10、负载均衡之Nginx介绍
- 1.2.2.11、负载均衡之Nginx和Apache的httpd对比
- 1.2.2.12、IO的阻塞模型和异步非阻塞模型
- 1.2.2.13、Nginx角色框架原理
- 1.2.2.14、负载均衡之Nginx的内核参数配置
- 1.2.2.15、Nginx的内核sendfile零拷贝原理
- 1.2.2.16、Nginx的TCP配置
- 1.2.2.17、Nginx的虚拟服务器原理
- 1.2.2.18、Nginx的location匹配规则
- 1.2.2.19、Nginx的自动索引
- 1.2.2.20、Nginx的反向代理服务器配置
- 1.2.2.21、Nginx的upstream负载均衡配置
- 1.2.2.22、Nginx的DNS负载均衡配置
- 1.2.2.23、Nginx负载均衡下数据一致性解决方案
- 1.2.1、Linux 网络
2、大数据EB级架构设计之Hadoop生态技术体系篇
- 2.1、分布式协调系统Zookeeper实战剖析
- 2.1.1、分布式协调框架Zookeeper
- 2.1.1.1、Zookeeper之分布式协调原理分析
- 2.1.1.2、Zookeeper之设计目的及原理介绍
- 2.1.1.3、Zookeeper之分布式环境准备及分布式部署实操
- 2.1.1.4、Zookeeper之命令实操演练
- 2.1.1.5、Zookeeper之节点类型系统介绍
- 2.1.1.6、Zookeeper之ZAB协议原理详解
- 2.1.1.7、Zookeeper之Paxos协议及变种选举协议原理详解
- 2.1.1.8、Zookeeper之api环境准备及企业级案例实操演练
- 2.1.1.9、Zookeeper之事件注册及节点变更
- 2.1.1、分布式协调框架Zookeeper
- 2.2、分布式文件系统HDFS底层实战剖析
- 2.2.1、分布式文件系统HDFS
- 2.1.1.1、HDFS之如何快速处理1T文件
- 2.1.1.2、HDFS之Hadoop历史介绍
- 2.1.1.3、HDFS之Hadoop架构设计原理分析
- 2.1.1.4、HDFS核心之NameNode详解
- 2.1.1.5、HDFS核心之SecondaryNameNode详解
- 2.1.1.6、HDFS核心之DataNode与副本防治策略详解
- 2.1.1.7、HDFS核心之HDFS权限管理详解
- 2.1.1.8、HDFS核心之HDFS安全模式详解
- 2.1.1.9、HDFS核心之HDFS文件上传流程详解
- 2.1.1.10、HDFS核心之HDFS读文件流程详解
- 2.1.1.11、HDFS之伪分布式集群搭建实操演练
- 2.1.1.12、HDFS核心之完全分布式集群搭建
- 2.1.1.13、HDFS核心之Hadoop新特性详解
- 2.1.1.14、HDFS核心之NameNode的Federation
- 2.1.1.15、NameNode-HA之NameNode-HA集群搭建
- 2.1.1.16、NameNode-HA之NameNode-HA手动、自动切换
- 2.1.1.17、HDFS核心之java客户端操作HDFS
- 2.2.1、分布式文件系统HDFS
- 2.3、分布式资源调度引擎Yarn实战剖析
- 2.3.1、分布式资源调度框架Yarn
- 2.3.1.1、Yarn架构设计思路深度剖析
- 2.3.1.2、Yarn ResourceManager原理深度解析
- 2.3.1.3、Yarn NodeManager原理深度解析
- 2.3.1.4、企业级Yarn分布式集群部署实践
- 2.3.1.5、Yarn 配置文件系统详解及优化设置
- 2.3.1.6、Yarn提交任务执行流程源码跟踪
- 2.3.1.7、Yarn ResourceManager启动源码深度剖析
- 2.3.1.8、Yarn NodeManager启动源码深度剖析
- 2.3.1、分布式资源调度框架Yarn
- 2.4、分布式计算引擎MapReduce实战剖析
- 2.4.1、分布式计算框架MapReduce
- 2.4.1.1、MapReduce之设计原理与原语详解
- 2.4.1.2、MapReduce之执行流程详解
- 2.4.1.3、MapReduce之二次排序原理及实操
- 2.4.1.4、MapReduce之作业提交流程原理及实操
- 2.4.1.5、MapReduce之作业执行流程
- 2.4.1.6、MapReduce之Shuffle机制原理详解
- 2.4.1.7、MapReduce之读取数据与输出数据过程详解
- 2.4.1.8、MapReduce之运行自带的wordcount程序
- 2.4.1.9、MapReduce之手写wordcount程序
- 2.4.2、MapReduce案例剖析
- 2.4.2.1、MR案例之天气案例需求分析/天气案例映射为MR原语
- 2.4.2.2、MR案例之天气案例键值对设计/天气案例开发和运行
- 2.4.2.3、MR案例之天气案例排序比较器分组比较器设计
- 2.4.2.4、MR案例之好友推荐需求分析/好友推荐映射为MR原语
- 2.4.2.5、MR案例之好友推荐键值对设计/好友推荐开发和运行/好友推荐TopN
- 2.4.2.6、MR案例之PageRank简介及算法介绍/PageRank映射为MR原语
- 2.4.2.7、MR案例之PageRank键值对设计/PageRank编码和运行
- 2.4.2.8、MR案例之TFIDF简介及算法/TFIDF映射为MR原语
- 2.4.2.9、MR案例之TFIDF键值对设计/TFIDF编码和运行
- 2.4.2.10、MR案例之itemCF简介及算法/itemCF键值对设计/itemCF编码和运行
- 2.4.1、分布式计算框架MapReduce
- 2.5、分布式数据仓库Hive实战剖析
- 2.5.1、分布式数据仓库Hive架构
- 2.5.1.1、数据仓库之为什么构架数据仓库
- 2.5.1.2、数据仓库之数仓构建方法论系统讲解
- 2.5.1.3、数据仓库与数据库重点区别详解
- 2.5.1.4、数据仓库之分层设计详解
- 2.5.1.5、数据仓库之表类型详解
- 2.5.1.6、Hive架构之架构原理详解
- 2.5.1.7、Hive架构之元数据讲解
- 2.5.1.8、Hive架构之执行引擎分析
- 2.5.1.9、Hive架构之企业级分布式搭建实操演练
- 2.5.2、Hive DDL
- 2.5.2.1、Hive DDL之基础数据类型系统讲解
- 2.5.2.2、Hive DDL之创建管理内部表、外部表实战操作
- 2.5.2.3、Hive DDL之数据读取规则Row Format详解
- 2.5.2.4、Hive DDL之数据读取规则 Serde系统讲解
- 2.5.2.5、Hive DDL之静态、动态分区管理详解
- 2.5.2.6、Hive DDL之动态分区管理
- 2.5.2.7、Hive DDL之删除、修改表实战演练
- 2.5.2.8、Hive DDL之分桶表、视图、索引系统讲解
- 2.5.3、Hive DML
- 2.5.3.1、Hive DML之企业级数据量加载
- 2.5.3.2、Hive DML之实操命令系统讲解
- 2.5.3.3、Hive DML之插入、修改、删除、清空企业级案例实操演练
- 2.5.3.4、Hive DML之事务管理、特性、配置详解
- 2.5.4、Hive Query
- 2.5.4.1、Hive Query之全表、条件、分组企业级案例演示
- 2.5.4.2、Hive Query之运算符系统讲解
- 2.5.4.3、Hive Query之内置函数、自定义函数系统讲解
- 2.5.4.4、Hive Query之表连接、排序方式详细讲解
- 2.5.4.5、Hive Query之企业面试高频SQL试题实战演练
- 2.5.4.6、Hive Query之Hive server2系统讲解
- 2.5.4.7、Hive Query之Hive beeline客户端系统讲解
- 2.5.4.8、Hive Query之JDBC、参数、变量、GUI详细讲解
- 2.5.1、分布式数据仓库Hive架构
- 2.6、分布式数据库HBase实战剖析
- 2.6.1、分布式数据库HBase架构
- 2.6.1.1、HBase之HBase架构设计原理及NoSQL体系详解
- 2.6.1.2、HBase之数据模型与HBase表结构系统讲解
- 2.6.1.3、HBase之HBase角色系统讲解
- 2.6.1.4、HBase之内存结构、存储数据结构LSM树讲解
- 2.6.1.5、HBase之读、写数据流程详细讲解
- 2.6.1.6、HBase之standalone模式、完全分布式企业级部署
- 2.6.1.7、HBase之HBase 高可用原理及企业级部署
- 2.6.2、分布式数据库HBase高级操作
- 2.6.2.1、HBase 之Shell命令系统讲解及实战演练
- 2.6.2.2、HBase API操作之创建表、删除表、插入、更新、删除实操演练
- 2.6.2.3、HBase 之HBase数据寻址与数据读写流程详解
- 2.6.2.4、HBase 之Hbase过滤器系统讲解
- 2.6.2.5、HBase 之Protobuffer安装、配置、API操作
- 2.6.2.6、HBase 之压缩存储原理及企业案例实战分析
- 2.6.2.7、HBase 之协处理器原理与企业案例实战分析
- 2.6.1、分布式数据库HBase架构
- 2.7、离线分布式数据采集系统实战剖析
- 2.7.1、Sqoop离线数据采集系统
- 2.7.1.1、Sqoop之数据采集原理及ETL详解
- 2.7.1.2、Sqoop之架构设计原理剖析
- 2.7.1.3、Sqoop之企业分布式安装及配置详解
- 2.7.1.4、Sqoop之全量、增量导入数据到hdfs
- 2.7.1.5、Sqoop之全量、增量导入数据到hive
- 2.7.1.6、Sqoop之全量、增量导入数据到hbase
- 2.7.1.7、Sqoop之全量、增量导出数据到mysql
- 2.7.1.8、Sqoop之数据迁移job管理
- 2.7.2、Kettle离线数据采集系统
- 2.7.2.1、Kettle之数据采集原理及概念模型详解
- 2.7.2.2、Kettle之核心组件系统讲解
- 2.7.2.3、Kettle之概念术语及相应实操演练
- 2.7.2.4、Kettle之数据ETL实战演练
- 2.7.2.5、Kettle之企业级数据ETL案例分析
- 2.7.1、Sqoop离线数据采集系统
- 2.8、高性能分布式缓存数据库Redis实战剖析
- 2.8.1、高性能分布式缓存库Redis
- 2.8.1.1、Redis之优势、特点及与其他框架对比详解
- 2.8.1.2、Redis之企业级分布式搭建实战演练
- 2.8.1.3、Redis之客户端命令行详解
- 2.8.1.4、Redis之字符串、散列、列表、集合类型系统讲解
- 2.8.1.5、Redis之Java Api实操演练
- 2.8.1.6、Redis之Transaction/Pipeline系统讲解
- 2.8.1.7、Redis之持久化(AOF+RDB)系统讲解
- 2.8.1.8、Redis之sentinel高可用实战应用
- 2.8.1.9、Redis之事务、分片、主从复制系统讲解
- 2.8.1.10、Redis之企业级案例实战分析
- 2.8.1、高性能分布式缓存库Redis
3、大数据EB级架构设计之ELK Stack生态体系篇
- 3.1、万亿级数据分析ELK Stack生态实战剖析
- 3.1.1、分布式搜索引擎Elastic Search
- 3.1.1.1、Elasticsearch之场景介绍及搜索引擎详解
- 3.1.1.2、Elasticsearch之核心概念系统讲解
- 3.1.1.3、Elasticsearch之倒排索引底层数据结构原理详解
- 3.1.1.4、Elasticsearch之FOR和RBM压缩算法原理剖析
- 3.1.1.5、Elasticsearch之Cluster、Index、Shard、Doc核心深入剖析
- 3.1.1.6、Elasticsearch之Mapping、Dynamic Mapping 核心深入剖析
- 3.1.1.7、Elasticsearch之企业级分布式集群安装部署
- 3.1.1.8、Elasticsearch之集群健康值检查实战操作
- 3.1.1.9、Elasticsearch之命令系统讲解及实战应用
- 3.1.1.10、Elasticsearch之Scripting、分词器底层原理剖析
- 3.1.1.11、Elasticsearch之Java Api实操及企业级案例实战分析
- 3.1.2、分布式日志采集系统Logstash
- 3.1.2.1、Logstash企业级集群部署
- 3.1.2.2、Logstash配置文件系统讲解
- 3.1.2.3、Logstash工作原理深入剖析
- 3.1.2.4、Logstash input-file插件原理及实战应用
- 3.1.2.5、Logstash output-elasticsearch插件原理及实战应用
- 3.1.3、可视化分析引擎Kibana
- 3.1.3.1、Kibana之架构体系深入分析
- 3.1.3.2、Kibana之企业级安装部署
- 3.1.3.3、Kibana之配置文件详细讲解
- 3.1.3.4、Kibana之数据导入可视化展示实战应用
- 3.1.3.5、Kibana企业级案例实战分析
- 3.1.1、分布式搜索引擎Elastic Search
4、大数据EB级架构设计之Spark生态体系篇
- 4.1、分布式消息系统Kafka实战剖析
- 4.1.1、分布式消息系统Kafka
- 4.1.1.1、Kafka系统之分布式消息系统及场景应用详解
- 4.1.1.2、Kafka系统之架构模型底层原理分析
- 4.1.1.3、Kafka系统之数据存储与磁盘映射关系原理分析
- 4.1.1.4、Kafka系统之生产者生产消息原理剖析
- 4.1.1.5、Kafka系统之消费者消费消息原理剖析
- 4.1.1.6、Kafka系统之底层消息存储原理剖析
- 4.1.1.7、Kafka系统之Kafka各个角色功能系统讲解
- 4.1.1.8、Kafka系统之topic底层存储原理详解
- 4.1.1.9、Kafka系统之partition逻辑划分详解
- 4.1.1.10、Kafka系统之数据副本规则详解
- 4.1.1.11、Kafka系统之企业级Kafka分布式集群部署
- 4.1.1.12、Kafka系统之不同粒度维护offset流程跟踪
- 4.1.1.13、Kafka系统之Kafka ISR深度剖析
- 4.1.1.14、Kafka系统之Kafka OSR深度剖析
- 4.1.1.15、Kafka系统之Kafka AR深度剖析
- 4.1.1.16、Kafka系统之Kafka LW深度剖析
- 4.1.1.17、Kafka系统之Kafka HW深度剖析
- 4.1.1.18、Kafka系统之Kafka LEO深度剖析
- 4.1.1.19、Kafka系统之Kafka ACK原理理论深度剖析
- 4.1.1.20、Kafka系统之Kafka 时间戳索引原理详解
- 4.1.1.21、Kafka系统之自定义offset偏移量实战演练
- 4.1.1.22、Kafka系统之Kafka 参数配置系统讲解
- 4.1.1.23、Kafka系统之Kafka producer生产消息代码实战演练
- 4.1.1.24、Kafka系统之Kafka consumer消费消息代码实战演练
- 4.1.1.25、Kafka系统之Kafka版本更新特点对比分析
- 4.1.1.26、Kafka 系统之企业级Kafka场景应用案例分析
- 4.1.1、分布式消息系统Kafka
- 4.2、分布式语言Scala实战剖析
- 4.2.1、分布式语言Scala基础
- 4.2.1.1、Scala语言之背景介绍及Scala六大特性剖析
- 4.2.1.2、Scala语言之Scala下载与安装配置
- 4.2.1.3、Scala语言之企业级开发配置
- 4.2.1.4、Scala语言之类型推断机制原理详解
- 4.2.1.5、Scala语言之数据类型、基本语法代码实操演练
- 4.2.1.6、Scala语言之类和对象、String代码实操演练
- 4.2.1.7、Scala语言之Array、可变数组代码实操演练
- 4.2.1.8、Scala语言之List、可变列表代码实操演练
- 4.2.1.9、Scala语言之Set、可变Set代码实操演练
- 4.2.1.10、Scala语言之map、可变map代码实操演练
- 4.2.1.11、Scala语言之元组操作及要点分析
- 4.2.2、分布式语言Scala高级应用
- 4.2.2.1、Scala高级操作之Scala递归、可变参、匿名函数代码实操演练
- 4.2.2.2、Scala高级操作之Scala嵌套、偏应用、高阶、柯里化函数代码实操演练
- 4.2.2.3、Scala高级操作之Scala伴生类及伴生对象原理分析及实操演练
- 4.2.2.4、Scala高级操作之Scala样例类及案例代码实操演练
- 4.2.2.5、Scala高级操作之Trait要点及Trait 案例代码实操演练
- 4.2.2.6、Scala高级操作之match匹配代码实操演练
- 4.2.2.7、Scala高级操作之隐式转换及代码实操演练
- 4.2.2.8、Scala高级操作之通信模型分析
- 4.2.1、分布式语言Scala基础
- 4.3、分布式并行计算框架Spark实战剖析
- 4.3.1、Spark核心基础
- 4.3.1.1、SparkCore之Spark技术原理介绍及技术站深度剖析
- 4.3.1.2、SparkCore之Spark演变历史及Spark与MR的区别深度剖析
- 4.3.1.3、SparkCore之Spark基于开发工具的详细配置讲解
- 4.3.1.4、SparkCore之Spark运行模式系统讲解
- 4.3.1.5、SparkCore之Spark企业级分布式集群搭建
- 4.3.1.6、SparkCore之Spark编程核心RDD原理深度剖析
- 4.3.1.7、SparkCore之SparkRDD五大特性及弹性分布式容错原理剖析
- 4.3.1.8、SparkCore之Spark Transformation类算子详解及代码实操
- 4.3.1.9、SparkCore之Spark Action类算子详解及代码实操
- 4.3.1.10、SparkCore之Spark 持久化类算子详解及代码实操
- 4.3.1.11、SparkCore之企业级综合案例详细分析
- 4.3.2、Spark核心进阶
- 4.3.2.1、Spark核心之Standalone-client模式原理/模式流程详解
- 4.3.2.2、Spark核心之Standalone-cluster模式原理/模式流程详解
- 4.3.2.3、Spark核心之Yarn-client模式原理/Yarn-client模式流程详解
- 4.3.2.4、Spark核心之Yarn-cluster模式原理/Yarn-cluster模式流程详解
- 4.3.2.5、Spark核心之Client模式提交命令和特点分析
- 4.3.2.6、Spark核心之Cluster模式提交命令和特点分析
- 4.3.2.7、Spark核心之ClusterManager原理剖析
- 4.3.2.8、Spark核心之Spark-Driver原理剖析
- 4.3.2.9、Spark核心之Master原理剖析
- 4.3.2.10、Spark核心之Worker原理剖析
- 4.3.2.11、Spark核心之Executor/Spark-线程池原理剖析
- 4.3.2.12、Spark核心之Application/Spark-job原理剖析
- 4.3.2.13、Spark核心之Stage/Spark-task原理剖析
- 4.3.2.14、Spark核心之SparkRDD窄依赖、宽依赖详解
- 4.3.2.15、Spark核心之SparkStage切割划分、计算模式详解
- 4.3.2.16、Spark核心之Stage并行度划分及优化详解
- 4.3.2.17、Spark核心之任务调度角色划分/资源调度角色划分详解
- 4.3.2.18、Spark核心之Spark资源调度、任务调度过程详解
- 4.3.2.19、Spark核心之SparkDAG有向无环图原理分析
- 4.3.3、Spark核心高级
- 4.3.3.1、Spark核心之企业级案例实战演练分析
- 4.3.3.2、Spark核心之二次排序、分组取topN优化分析
- 4.3.3.3、Spark核心之广播变量、累加器原理深度剖析
- 4.3.3.4、Spark核心之自定义累加器/版本对比变化深度剖析
- 4.3.3.5、Spark核心之Spark-WebUI详解及日志查看
- 4.3.3.6、Spark核心之MasterHA高可用原理及配置详解
- 4.3.3.7、Spark核心之Spark-SortShuffle原理深度剖析
- 4.3.3.8、Spark核心之Spark-SortShufflebypass原理深度剖析
- 4.3.3.9、Spark核心之Shuffle文件寻址详解
- 4.3.3.10、Spark核心之Spark内存管理深读剖析
- 4.3.4、SparkSQL
- 4.3.4.1、SSparkSQL之SparkSQL演变历史分析
- 4.3.4.2、SparkSQL之DataFrame与DataSet及实操演练
- 4.3.4.3、SparkSQL之数据源及SparkSQL底层架构深度剖析
- 4.3.4.4、SparkSQL之Json格式数据转DataSet代码实操演练
- 4.3.4.5、SparkSQL之普通RDD和DataSet互操作代码实操演练
- 4.3.4.6、SparkSQL之Parquet数据转DataSet代码实操演练
- 4.3.4.7、SparkSQL之JDBC数据转DataSet代码实操演练
- 4.3.4.8、SparkSQL之序列化问题深度剖析
- 4.3.4.9、SparkSQL之Hive On Spark原理分析
- 4.3.4.10、SparkSQL之Spark On Hive原理分析及配置
- 4.3.4.11、SparkSQL之DataSet存储代码实操演练
- 4.3.4.12、SparkSQL之UDF、UDAF函数代码实操演练
- 4.3.4.13、SparkSQL之over函数企业级实战案例分析
- 4.3.5、SparkStreaming
- 4.3.5.1、SparkStreaming之接收数据原理剖析
- 4.3.5.2、SparkStreaming之Dstream底层结构剖析
- 4.3.5.3、SparkStreaming之foreachRDD算子详解及代码实操演练
- 4.3.5.4、SparkStreaming之transform算子详解及代码实操演练
- 4.3.5.5、SparkStreaming之updateStateByKey算子详解及代码实操演练
- 4.3.5.6、SparkStreaming之reduceByKeyAndWindow详解及代码实操演练
- 4.3.5.7、SparkStreaming之DriverHA原理及搭建实操
- 4.3.5.8、SparkStreaming之Direct模式深度剖析
- 4.3.5.9、SparkStreaming之Direct模式Api代码实操演练
- 4.3.5.10、SparkStreaming之Direct模式并行度设置/Direct模式offset管理
- 4.3.5.11、SparkStreaming之配置参数详解
- 4.3.5.12、SparkStreaming之反压机制原理剖析
- 4.3.5.13、SparkStreaming之Kafka与SparkStreaming参数配置详解
- 4.3.1、Spark核心基础
- 4.4、实时分布式数据采集系统实战剖析
- 4.4.1、实时数据采集Flume
- 4.4.1.1、Flume之日志收集工具架构原理剖析
- 4.4.1.2、Flume之source、channel、sink组价体系讲解
- 4.4.1.3、Flume之企业级分布式集群安装及配置详解
- 4.4.1.4、Flume之高可用原理及配置讲解
- 4.4.1.5、Flume之各类Source实战演练
- 4.4.1.6、Flume之各类Channel实战演练
- 4.4.1.7、Flume之各类Sink实战演练
- 4.4.1.8、Flume之企业级案例配置分析及实操演练
- 4.4.2、实时数据采集Canal
- 4.4.2.1、Canal之实时采集工具详解
- 4.4.2.2、Canal之实时同步数据原理详解
- 4.4.2.3、Canal之下载与搭建部署
- 4.4.2.4、Canal之Canal Server架构原理详解
- 4.4.2.5、Canal之同步MySQL数据实战案例分析
- 4.4.2.6、Canal之HA 高可用原理
- 4.4.3、实时数据采集Maxwell
- 4.4.3.1、实Maxwell工作原理及介绍
- 4.4.3.2、Maxwell同步MySQL数据
- 4.4.3.3、Maxwell断点续传功能详细解析
- 4.4.3.4、Maxwell BootStrap原理分析
- 4.4.3.5、Maxwell 全量同步MySQL数据实战案例分析
- 4.4.1、实时数据采集Flume
- 4.4、任务流调度系统 Azkaban实战剖析
- 4.4.1、任务流调度系统Azkaban
- 4.4.1.1、Azkaban之大数据中的应用场景分析
- 4.4.1.2、AAzkaban之WebServer原理详解
- 4.4.1.3、AAzkaban之ExecutorServer原理详解
- 4.4.1.4、AAzkaban之企业级环境准备及搭建部署
- 4.4.1.5、AAzkaban之服务启动顺序及注意事项
- 4.4.1.6、AAzkaban之集群配置及SSL 配置详解
- 4.4.1.7、AAzkaban之构建设计工作流程实操演练
- 4.4.1.8、AAzkaban之编写Azkaban job任务及任务配置详解
- 4.4.1.9、AAzkaban之提交任务工作流及WEBUI 界面监控工作流任务
- 4.4.1、任务流调度系统Azkaban
- 4.5、数据分析可视化Superset实战剖析
- 4.5.1、BI可视化Superset
- 4.5.1.1、Superset可视化之BI工具介绍及下载
- 4.5.1.2、Superset可视化之基于Windows安装详解
- 4.5.1.3、Superset可视化之基于Linux安装详解
- 4.5.1.4、Superset可视化之WebUI界面详细介绍
- 4.5.1.5、Superset可视化之添加外部数据库及外部表
- 4.5.1.6、Superset可视化之绘制BI图表、柱状图、折线图、饼图实战操作
- 4.5.1、BI可视化Superset
5、大数据EB级架构设计之Flink生态体系篇
- 5.1、实时计算框架Flink实战剖析
- 5.1.1、Flink基础
- 5.1.1.1、Flink基础之有界与无界流详解
- 5.1.1.2、Flink基础之有状态计算架构分析
- 5.1.1.3、Flink基础之Flink应用场景及特点优势
- 5.1.1.4、Flink基础之Flink批流数据读取处理案例剖析
- 5.1.1.5、Flink基础之Flink企业级集群安装部署
- 5.1.1.6、Flink基础之Client客户端详解
- 5.1.1.7、Flink基础之JobManager详解
- 5.1.1.8、Flink基础之TaskManager详解
- 5.1.1.9、Flink基础之Flink on Yarn原理详解
- 5.1.1.10、Flink基础之Session-Cluster原理详解
- 5.1.1.11、Flink基础之Per-Job-Cluster原理详解
- 5.1.1.12、Flink基础之Flink HA原理及搭建
- 5.1.1.13、Flink基础之Flink 并行度和Slot深度剖析
- 5.1.1.14、Flink基础之Source API详解及代码实战演练
- 5.1.1.15、Flink基础之Transformation API详解及代码实战演练
- 5.1.1.16、Flink基础之Sink API详解及代码实战演练
- 5.1.2、Flink高级
- 5.1.2.1、Flink高级之Flink函数类深度剖析
- 5.1.2.2、Flink高级之Flink富函数类深度剖析
- 5.1.2.3、Flink高级之Flink底层ProcessFunctionApi原理及代码实操演练
- 5.1.2.4、Flink高级之侧输出流Side Output原理及代码实操演练
- 5.1.2.5、Flink高级之Flink CEP深度剖析
- 5.1.2.6、Flink高级之Flink 事件定义代码实操演练
- 5.1.2.7、Flink高级之Flink Pattern API代码实操演练
- 5.1.2.8、Flink高级之Flink 模式定义、检测、选择代码实操演练
- 5.1.2.9、Flink高级之Flink CEP企业级案例分析
- 5.1.2.10、Flink高级之Flink 状态管理深度剖析及代码演练
- 5.1.2.11、Flink高级之Flink CheckPoint原理剖析及页面监控详解
- 5.1.2.12、Flink高级之CheckPoint参数和设置实操演练
- 5.1.2.13、Flink高级之Flink StateBackend 状态后端原理剖析
- 5.1.2.14、Flink高级之CheckPoint企业级案例分析
- 5.1.2.15、Flink高级之Flink SavePoint企业级案例分析
- 5.1.3、Flink窗口与Time
- 5.1.3.1、Flink窗口之Flink Window详解及代码实战演练
- 5.1.3.2、Flink窗口之Global Window详解及代码实战演练
- 5.1.3.3、Flink窗口之Keyed Window详解及代码实战演练
- 5.1.3.4、Flink窗口之TimeWindow详解及代码实战演练
- 5.1.3.5、Flink窗口之Sliding Window详解及代码实战演练
- 5.1.3.6、Flink窗口之Session Window详解及代码实战演练
- 5.1.3.7、Flink窗口之Count Window详解及代码实战演练
- 5.1.3.8、Flink窗口之窗口聚合函数详解及代码实战演练
- 5.1.3.9、Flink Time之时间语义深度剖析
- 5.1.3.10、Flink Time之WaterMark水位线原理剖析
- 5.1.3.11、Flink Time之乱序问题场景实战演练
- 5.1.3.12、Flink Time之周期性WaterMark原理深度剖析
- 5.1.3.13、Flink Time之间断性WaterMark原理深度剖析
- 5.1.3.14、Flink Time之企业级WaterMark案例实战演练
- 5.1.3.15、Flink Time之AllowedLateness深度剖析
- 5.1.4、FlinkSQL及优化
- 5.1.4.1、Flink SQL之Table Environment原理及实战演练
- 5.1.4.2、Flink SQL之Table API原理及实战演练
- 5.1.4.3、Flink SQL之Table查询与过滤原理及代码实战演练
- 5.1.4.4、Flink SQL之Table分组与聚合原理及代码实战演练
- 5.1.4.5、Flink SQL之Table自定义UDF原理及代码实战演练
- 5.1.4.6、Flink SQL之Table Window原理及代码实战演练
- 5.1.4.7、Flink SQL之Flink SQL企业级案例分析
- 5.1.4.8、Flink优化之CheckPoint优化及参数详解
- 5.1.4.9、Flink优化之内存优化及参数详解
- 5.1.4.10、Flink优化之网络缓存优化及参数详解
- 5.1.1、Flink基础
- 5.2、分布式列式存储库Clickhouse实战剖析
- 5.2.1、分布式列式存储ClickHouse
- 5.2.1.1、ClickHouse之ClickHouse特性及OLAP场景分析
- 5.2.1.2、ClickHouse之数据压缩、向量化执行底层原理分析
- 5.2.1.3、ClickHouse之企业级分布式集群部署安装
- 5.2.1.4、ClickHouse之ClickHouse数据类型系统讲解
- 5.2.1.5、ClickHouse之数据库引擎原理及实操演练
- 5.2.1.6、ClickHouse之Log系列表引擎原理及实操演练
- 5.2.1.7、ClickHouse之Special系列表引擎原理及实操演练
- 5.2.1.8、ClickHouse之MergeTree表引擎原理及实操演练
- 5.2.1.9、ClickHouse之Integration表引擎原理及实操演练
- 5.2.1.10、ClickHouse之DDL、DML实战操作
- 5.2.1.11、ClickHouse之临时表、普通视图、物化视图原理及实操演练
- 5.2.1.12、ClickHouse之导入导出数据案例分析
- 5.2.1.13、ClickHouse之Java Api实战演练
- 5.2.1.14、ClickHouse之ClickHouse&Spark整合及代码实战演练
- 5.2.1.15、ClickHouse之ClickHouse&Flink整合及代码实战演练
- 5.2.1.16、ClickHouse之ClickHouse可视化工具 tabix、DBeaver实战应用
- 5.2.1、分布式列式存储ClickHouse
- 5.3、实时OLAP分析存储库Druid实战剖析
- 5.3.1、实时OLAP分析Druid
- 5.3.1.1、Druid之架构原理及优缺点分析
- 5.3.1.2、Druid之Druid Segent原理剖析
- 5.3.1.3、Druid之Druid RealTime Node原理剖析
- 5.3.1.4、Druid之Druid Coodinator Node原理剖析
- 5.3.1.5、Druid之Druid Historical Node原理剖析
- 5.3.1.6、Druid之Druid Broker Node原理剖析
- 5.3.1.7、Druid之Druid Metadata Storage原理剖析
- 5.3.1.8、Druid之Druid Deep Storage原理剖析
- 5.3.1.9、Druid之数据写入及读取原理详解
- 5.3.1.10、Druid之企业级集群搭建实战演练
- 5.3.1.11、Druid之加载离线数据文件实战演练
- 5.3.1.12、Druid之加载实时Kafka数据实战演练
- 5.3.1.13、Druid之Druid WebUI 实操
- 5.3.1.14、Druid之JDBC Api 企业级代码操作
- 5.3.1.15、Druid之数据全量更新原理及实操演练
- 5.3.1.16、Druid之与其他OLAP框架对比选型分析
- 5.3.1、实时OLAP分析Druid
三、进阶高级大数据架构生态技术体系
1、大数据EB级架构设计之数据采集技术体系篇
- 1.1、离线数据分布式采集技术深度剖析
- 1.1.1、数据采集系统Sqoop
- 1.1.1.1、Sqoop架构设计思路系统剖析
- 1.1.1.2、Sqoop全量、增量数据同步流程核心剖析
- 1.1.1.3、Sqoop与外部框架深度整合原理剖析
- 1.1.1.4、Sqoop在一线大厂数据采集设计思路
- 1.1.1.5、Sqoop数据迁移深度解读
- 1.1.2、数据采集系统DataX
- 1.1.2.1、DataX架构设计思路系统剖析
- 1.1.2.2、DataX插件体系设计原理剖析
- 1.1.2.3、DataX调度流程核心点剖析
- 1.1.2.4、DataX与常用外部框架整合思路关键点剖析
- 1.1.3、数据采集系统kettle
- 1.1.3.1、Kettle 概念模型及核心组件深度解读
- 1.1.3.2、Kettle 底层架构设计思路系统剖析
- 1.1.3.3、Kettle 核心组件核心点系统讲解
- 1.1.3.4、Kettle 设计、转换、作业流程思路设计剖析
- 1.1.3.5、Kettle 企业级数据采集场景生产实践
- 1.1.1、数据采集系统Sqoop
- 1.2、实时数据分布式采集技术深度剖析
- 1.2.1、数据采集系统Flume
- 1.2.1.1、Flume架构思路系统剖析
- 1.2.1.2、Flume Source设计思路详解
- 1.2.1.3、Flume Channel设计思路详解
- 1.2.1.4、Flume Sink设计思路详解
- 1.2.1.5、Flume 实时采集系统构建方法论
- 1.2.1.6、Flume 一线互联网大厂应用场景深度剖析
- 1.2.1.7、Flume 企业级场景实战深度剖析
- 1.2.2、数据采集系统maxwell
- 1.2.2.1、Maxwell 底层架构设计思路剖析
- 1.2.2.2、Maxwell应用场景及优势详解
- 1.2.2.3、Maxwell实时同步数据流程剖析
- 1.2.2.4、Maxwell Bootstrap全量同步数据底层原理剖析
- 1.2.2.5、Maxwell企业级数据同步场景实践
- 1.2.3、数据采集系统canal
- 1.2.3.1、Canal实时数据采集架构设计解读
- 1.2.3.2、Canal配置原理深度剖析
- 1.2.3.3、Canal 同步MySQL数据企业级实践
- 1.2.3.4、Canal 如何搭建HA高性能的架构思路指导
- 1.2.4、数据采集系统NiFi
- 1.2.4.1、传统流数据解决方案深度剖析
- 1.2.4.2、NiFi架构核心点深度解读
- 1.2.4.3、NiFi单机与分布式集群异同点剖析
- 1.2.4.4、NiFi核心Processors体系分析
- 1.2.4.5、NiFi WebUI功能域详细解读
- 1.2.4.6、NiFi数据提取、转换、发送流程底层原理分析
- 1.2.4.7、NiFi数据库访问核心点剖析
- 1.2.4.8、NiFi变量及表达式实战演练
- 1.2.4.9、NiFi Connection底层深度剖析
- 1.2.4.10、一线大厂如何使用NiFi同步MySQL数据
- 1.2.4.11、NiFi与HDFS、Hive、Kafka深度整合原理
- 1.2.1、数据采集系统Flume
2、大数据EB级架构设计之数据中间件技术体系篇
- 2.1、分布式协调系统Zookeeper深度剖析
- 2.1.1、分布式协调框架Zookeeper
- 2.1.1.1、Zookeeper实现分布式协调底层核心剖析
- 2.1.1.2、Zookeeper集群台数如何更优雅的设计指导思路
- 2.1.1.3、Zookeeper Paxos协议一致性原理剖析
- 2.1.1.4、Zookeeper 角色原理深度剖析
- 2.1.1.5、Zookeeper 元数据信息深度解读
- 2.1.1.6、Zookeeper shell client目录结构解析
- 2.1.1.7、Zookeeper 分布式配置注册与发现企业级实践
- 2.1.1.8、Zookeeper 分布式锁实现企业级实践
- 2.1.1、分布式协调框架Zookeeper
- 2.2、分布式缓存系统Redis深度剖析
- 2.2.1、分布式缓存Redis
- 2.2.1.1、Redis架构设计思路深度剖析
- 2.2.1.2、Redis数据类型结构体系分析
- 2.2.1.3、Redis NIO底层原理深度剖析
- 2.2.1.4、Redis LRU、CAP设计思路剖析
- 2.2.1.5、Redis 主从复制核心点详解
- 2.2.1.6、Redis 事务原理及企业级场景实践
- 2.2.1.7、Redis 分片设计底层原理剖析
- 2.2.1.8、互联网大厂Redis使用场景剖析
- 2.2.1.9、Redis优化核心点指导思路
- 2.2.1、分布式缓存Redis
- 2.3、分布式消息系统生态深度剖析
- 2.3.1、分布式消息系统Kafka
- 2.3.1.1、Kafka分布式消息系统架构设计思路剖析与扩展
- 2.3.1.2、Kafka底层消息存储模型原理剖析
- 2.3.1.3、Kafka角色系统深度剖析
- 2.3.1.4、Kafka副本设计思路原理深度解析
- 2.3.1.5、Kafka ISR机制核心源码深度解读
- 2.3.1.6、Kafka OSR核心源码深度解读
- 2.3.1.7、Kafka AR核心源码深度解读
- 2.3.1.8、Kafka LW核心源码深度解读
- 2.3.1.9、Kafka HW核心源码深度解读
- 2.3.1.10、Kafka LEO核心源码深度解读
- 2.3.1.11、Kafka ACK原理理论深度剖析
- 2.3.1.12、Kafka 时间戳索引源码深度解读
- 2.3.1.13、Kafka之Producer源码深度解读
- 2.3.1.14、Kafka之Consumer源码深度解读
- 2.3.1.15、企业级Kafka集群调优指导思路
- 2.3.1.16、Kafka企业级应用场景参数体系深入剖析
- 2.3.2、分布式消息系统Pulsar
- 2.3.2.1、Apache Pulsar架构设计思路剖析
- 2.3.2.2、Apache Pulsar特点与优势解读
- 2.3.2.3、Apache Pulsar企业级部署核心点解读
- 2.3.2.4、Apache Pulsar topic原理深度剖析
- 2.3.2.5、Apache Pulsar partition原理深度剖析
- 2.3.2.6、Apache Pulsar 租户与NameSpace详解
- 2.3.2.7、Apache Pulsar 生产者生产消息生产实践
- 2.3.2.8、Apache Pulsar 消费者消费消息生产实践
- 2.3.2.9、Pulsar Message管理底层原理剖析
- 2.3.2.10、Pulsar Storage存储底层原理剖析
- 2.3.2.11、Pulsar Processing 处理消息企业级生产实践
- 2.3.2.12、Pulsar 数据完整性保证原理详解
- 2.3.1、分布式消息系统Kafka
- 2.4、分布式数据分析系统ELK Stack 深度剖析
- 2.4.1、分布式搜索引擎Elastic Search
- 2.4.1.1、Elasticsearch架构设计思路深度剖析
- 2.4.1.2、Elasticsearch核心概念解读
- 2.4.1.3、Elasticsearch倒排索引底层架构深度解析
- 2.4.1.4、Elasticsearch压缩算法性能横向对比分析
- 2.4.1.5、Elasticsearch核心点深度剖析
- 2.4.1.6、Elasticsearch集群健康监控优化设计
- 2.4.1.7、Elasticsearch分词器底层原理深度剖析
- 2.4.1.8、Elasticsearch企业级场景生产实践
- 2.4.1.9、Elasticsearch性能优化方法论指导
- 2.4.2、分布式日志采集系统Logstash
- 2.4.2.1、Logstash企业级集群部署
- 2.4.2.2、Logstash配置文件系统讲解
- 2.4.2.3、Logstash工作原理深入剖析
- 2.4.2.4、Logstash input-file插件原理及实战应用
- 2.4.2.5、Logstash output-elasticsearch插件原理及实战应用
- 2.4.2.6、Logstash filter-grok插件原理及实战应用
- 2.4.3、可视化分析引擎Kibana
- 2.4.3.1、Kibana之架构体系深入分析
- 2.4.3.2、Kibana之企业级安装部署
- 2.4.3.3、Kibana之配置文件详细讲解
- 2.4.3.4、Kibana之数据导入可视化展示实战应用
- 2.4.3.5、Kibana企业级案例实战分析
- 2.4.1、分布式搜索引擎Elastic Search
3、大数据EB级架构设计之数据存储技术体系篇
- 3.1、分布式文件系统HDFS底层深度剖析
- 3.1.1、分布式文件系统HDFS
- 3.1.1.1、HDFS之架构设计思路深度剖析
- 3.1.1.2、HDFS高性能原理深度解析
- 3.1.1.3、HDFS角色体系深度解析
- 3.1.1.4、HDFS企业级集群部署核心点解析
- 3.1.1.5、HDFS启动流程源码级别解读
- 3.1.1.6、HDFS各角色通信底层原理解读
- 3.1.1.7、HDFS数据上传流程源码级别深度剖析
- 3.1.1.8、HDFS数据下载流程源码及别深度剖析
- 3.1.1.9、HDFS高可用底层实现原理剖析
- 3.1.1.10、HDFS元数据管理机制原理剖析
- 3.1.1.11、HDFS NameNode、DataNode决策原理详解
- 3.1.1.12、HDFS一线大厂使用场景核心问题实践
- 3.1.1.13、HDFS集群调优参数详解
- 3.1.1.14、HDFS集群架构思考及设计模式扩展
- 3.1.1、分布式文件系统HDFS
- 3.2、分布式数据库HBase底层深度剖析
- 3.2.1、分布式数据库HBase
- 3.2.1.1、HBase架构设计思路深度剖析
- 3.2.1.2、HBase数据模型及存储结构详解及扩展
- 3.2.1.3、HBase角色体系深度剖析
- 3.2.1.4、HBase 底层LSM树原理解析
- 3.2.1.5、HBase命令系统讲解及企业级场景实践
- 3.2.1.6、HBase Api 核心讲解及思路扩展
- 3.2.1.7、HBase 过滤器设计底层原理剖析
- 3.2.1.8、HBase 预分区及Rowkey设计优化
- 3.2.1.9、HBase Compact合并优化原理及思路扩展
- 3.2.1.10、HBase 多Htable并发写带来的性能优化思考
- 3.2.1.11、HBase多线程操作优化方案设计
- 3.2.1.12、HBase批量操作带来的性能调优实践
- 3.2.1.13、HBase索引优化原理深度剖析
- 3.2.1.14、HBase企业级数据处理场景实践分析
- 3.2.1、分布式数据库HBase
- 3.3、分布式数据仓库Hive底层深度剖析
- 3.3.1、分布式数据仓库Hive
- 3.3.1.1、Hive企业级应用核心点剖析
- 3.3.1.2、Hive元数据管理底层深度剖析
- 3.3.1.3、Hive 数据类型系统详解
- 3.3.1.4、Hive DDL SQL 规范详解
- 3.3.1.5、Hive 分桶底层原理剖析
- 3.3.1.6、Hive 索引设计及思路扩展
- 3.3.1.7、Hive DML 事务原理及思路扩展
- 3.3.1.8、Hive 表类型体系详解
- 3.3.1.9、Hive 全表、条件、分组企业级案例演示
- 3.3.1.10、Hive 运算符系统讲解
- 3.3.1.11、Hive 内置函数、自定义函数系统讲解
- 3.3.1.12、Hive 表连接、排序方式详细讲解
- 3.3.1.13、Hive 企业面试高频SQL试题实战演练
- 3.3.1.14、Hive Hive server2及Hive beeline原理剖析
- 3.3.1.15、Hive JDBC 企业级应用实践
- 3.3.1.16、Hive 角色授权模型原理深度剖析
- 3.3.1.17、Hive 数据格式体系详解
- 3.3.1.18、Hive 查询优化实践及扩展
- 3.3.1.19、Hive企业级数据表关联优化设计方案
- 3.3.1.20、Hive数据倾斜场景处理设计方案
- 3.3.1、分布式数据仓库Hive
- 3.4、分布式数据存储-数据湖生态体系深度剖析
- 3.4.1、数据湖技术Hudi
- 3.4.1.1、Hudi数据湖使用场景剖析
- 3.4.1.2、Hudi架构设计思路深度剖析
- 3.4.1.3、Hudi Timeline原理详解
- 3.4.1.4、Hudi COW及MOR表类型原理剖析
- 3.4.1.5、Hudi 增删改查实现流程剖析
- 3.4.1.6、企业级Hudi应用场景实践
- 3.4.2、数据湖技术Deltalack
- 3.4.2.1、Delta Lake 架构原理深度剖析
- 3.4.2.2、Delta Lake Schema原理详解
- 3.4.2.3、Delta Lake 元数据处理
- 3.4.2.4、Delta Lake 数据更新和删除
- 3.4.2.5、Delta Lake 数据异常处理
- 3.4.2.6、Delta Lake 与Spark框架整合
- 3.4.2.7、Delta Lake 与Flink框架整合
- 3.4.3、数据湖技术Iceberg
- 3.4.3.1、数Iceberg 架构设计原理深度剖析
- 3.4.3.2、Iceberg Table Evolution详解
- 3.4.3.3、Iceberg Schema Evolution详解
- 3.4.3.4、Iceberg 增加列企业级实践
- 3.4.3.5、Iceberg 删除数据企业级实践
- 3.4.3.6、Iceberg 嵌套数据处理
- 3.4.3.7、Iceberg 隐式分区原理剖析
- 3.4.3.8、Iceberg 与Spark、Hive框架深度整合
- 3.4.1、数据湖技术Hudi
4、大数据EB级架构设计之数据处理技术体系篇
- 4.1、分布式计算引擎MapReduce源码级深度剖析
- 4.1.1、分布式计算引擎MapReduce
- 4.1.1.1、MapReduce架构总线设计深度剖析
- 4.1.1.2、MapReduce作业提交、执行流程深度剖析
- 4.1.1.3、MapReduce企业级案例详解
- 4.1.1.4、MapReduce作业提交流程源码深度剖析
- 4.1.1.58、作业切片计算的源码深度剖析
- 4.1.1.1、MapTask输入方式的源码深度剖析
- 4.1.1.1、MapTask执行流程源码深度剖析
- 4.1.1.1、MapTask输出方式的源码深度剖析
- 4.1.1.1、MapTask环形缓冲区源码深度剖析
- 4.1.1.1、RedueTask的shuffle源码深度剖析
- 4.1.1.1、ReduceTask分组的源码深度剖析
- 4.1.1.1、ReduceTask输出的源码深度剖析
- 4.1.1.1、MapReduce参数优化深度剖析
- 4.1.1、分布式计算引擎MapReduce
- 4.2、分布式计算引擎Spark源码级深度剖析
- 4.2.1、Spark Core
- 4.2.1.1、Spark架构总线设计深度剖析
- 4.2.1.2、Spark计算框架原理深度剖析
- 4.2.1.3、Spark运行模式系统讲解
- 4.2.1.4、Spark核心RDD底层原理及扩展分析
- 4.2.1.5、Spark Transformation类算子企业级实践
- 4.2.1.6、Spark Action类算子企业级实践
- 4.2.1.7、Spark 持久化算子企业级实践
- 4.2.1.8、Spark Standalone模式及Yarn模式深度对比分析
- 4.2.1.9、Spark client及Cluster模式特点核心解读
- 4.2.1.10、Spark HadoopRDD 源码深入剖析
- 4.2.1.11、Spark WordCount 执行流程源码深入剖析
- 4.2.1.12、Spark RDD 源码剖析
- 4.2.1.13、Spark CombineByKey 源码剖析
- 4.2.1.14、Spark 分区设置内部执行流程源码剖析
- 4.2.1.15、Spark 二次排序源码剖析
- 4.2.1.16、Spark Core参数优化源码剖析
- 4.2.1.17、Submit提交任务源码剖析
- 4.2.1.18、Driver 启动源码剖析
- 4.2.1.19、SparkCore Application注册源码剖析
- 4.2.1.20、Spark Executor资源申请源码剖析
- 4.2.1.21、SparkContext源码剖析
- 4.2.1.22、DAGScheduler源码剖析
- 4.2.1.23、SparkStage划分源码剖析
- 4.2.1.24、SparkTaskScheduler源码剖析
- 4.2.1.25、Executor运行task源码剖析
- 4.2.1.26、SparkEnv源码剖析
- 4.2.1.27、Spark MemoryManager源码剖析
- 4.2.1.28、Spark BlockManagr源码剖析
- 4.2.1.29、Spark Dependency 源码剖析
- 4.2.1.30、Spark SortShuffleManager源码剖析
- 4.2.1.31、Spark SortShuffleWriter源码剖析
- 4.2.1.32、Spark内存缓冲区源码剖析
- 4.2.1.33、Spark UnsafeShuffleWriter源码剖析
- 4.2.1.34、Spark Tungsten源码剖析
- 4.2.1.35、Spark 堆外内存源码剖析
- 4.2.1.36、Shuffle Reader 、Tracker源码剖析
- 4.2.1.37、Spark Shuffle task调度源码剖析
- 4.2.1.38、Spark Task执行源码剖析
- 4.2.1.39、Spark广播变量及累加器原理深度剖析
- 4.2.1.40、互联网大厂Spark应用场景方案设计
- 4.2.1.41、Spark核心优化点详解
- 4.2.2、SparkSQL
- 4.2.2.1、SparkSQL架构设计思路解析
- 4.2.2.2、SparkSQL DataFrame及Dataset对象详解
- 4.2.2.3、SparkSQL数据源种类及特点剖析
- 4.2.2.4、SpakrSQL对象互转需要注意的核心问题剖析
- 4.2.2.5、SparkSQL自定义函数深度解析
- 4.2.2.6、SparkSQL企业级应用场景案例实践
- 4.2.2.7、SparkSQL SQL解析源码深度剖析
- 4.2.2.8、SparkSQL Dataset源码深度剖析
- 4.2.2.9、SparkSQL DataFrame源码深度剖析
- 4.2.2.10、SparkSQL antlr4、AST语法树源码深度剖析
- 4.2.2.11、SparkSQL逻辑计划源码深度剖析
- 4.2.2.12、SparkSQL优化器源码深度剖析
- 4.2.2.13、SparkSQL优化器源码深度剖析
- 4.2.2.14、SparkSQL物理计划源码深度剖析
- 4.2.2.15、SparkSQL 优化点、优化思路扩展
- 4.2.3、SparkStreaming
- 4.2.3.1、SparkStreaming架构设计思路深度剖析
- 4.2.3.2、SparkStreaming各类算子企业级实践
- 4.2.3.3、SparkStreaming与Kafka深度整合原理剖析
- 4.2.3.4、SparkStreaming与Kafka整合offset一致性保证处理
- 4.2.3.5、SparkStreaming整合Kafka参数体系详解
- 4.2.3.6、SparkStreaming整合Kafka企业级优化核心点深度剖析
- 4.2.3.7、SparkStreaming DataStream源码解析
- 4.2.3.8、SparkStreaming 微批源码解析
- 4.2.3.9、SparkStreaming updataStateByKey源码解析
- 4.2.3.10、SparkStreaming State源码解析
- 4.2.3.11、SparkStreaming window源码解析
- 4.2.4、StructuredStreaming
- 4.2.4.1、SparkStreaming处理实时数据痛点剖析
- 4.2.4.2、StructuredStreaming编程模型及特点详解
- 4.2.4.3、StructuredStreaming输出模式详解
- 4.2.4.4、StructuredStreaming Table API实践解析
- 4.2.4.5、StructuredStreaming Triggers 触发执行机制
- 4.2.4.6、StructuredStreaming Continuous 连续处理
- 4.2.4.7、StructuredStreaming InputSource&OutputSink实战解析
- 4.2.4.8、StructuredStreaming DataFrame & Dataset API 实践解析
- 4.2.4.9、StructuredStreaming 事件时间原理与窗口划分、触发机制原理剖析
- 4.2.4.10、StructuredStreaming 延迟数据处理和Watermarking 原理剖析
- 4.2.4.11、StructuredStreaming 窗口类型与Join 实践解析
- 4.2.4.12、StructuredStreaming 流去重与注意点解析
- 4.2.4.13、StructuredStreaming与Kafka整合及实战案例解析
- 4.2.1、Spark Core
- 4.3、分布式计算引擎Flink源码级深度剖析
- 4.3.1、Flink 基础
- 4.3.1.1、Flink架构设计思路深度剖析
- 4.3.1.2、Flink状态计算原理剖析
- 4.3.1.3、Flink针对批数据与流数据处理异同剖析
- 4.3.1.4、Flink 各类角色体系深度剖析
- 4.3.1.5、Flink On Yarn原理及企业级实践
- 4.3.1.6、Flink 高可用保障机制实现原理
- 4.3.1.7、Flink Source源企业级实践及深度解析
- 4.3.1.8、Flink Transformation源企业级实践及深度解析
- 4.3.1.9、Flink Sink源企业级实践及深度解析
- 4.3.2、Flink高级
- 4.3.2.1、Flink函数类企业场景应用设计
- 4.3.2.2、Flink底层ProcessFunction Api原理及企业级实践
- 4.3.2.3、Flink侧输出流Side Output 原理及企业级实践
- 4.3.2.4、Flink事件定义及模式匹配原理深度剖析
- 4.3.2.5、Flink CEP核心原理及扩展应用
- 4.3.2.6、Flink状态管理原理深度剖析
- 4.3.2.7、Flink状态后端企业级实践
- 4.3.2.8、Flink Checkpoint及SavePoint核心原理及优化实践
- 4.3.3、Flink时间窗口
- 4.3.3.1、Flink Window 架构设计原理深度剖析
- 4.3.3.2、Flink Window企业级场景应用实践设计
- 4.3.3.3、Flink Window优化核心点深度剖析
- 4.3.3.4、Flink Time时间语义原理详解
- 4.3.3.5、Flink Time WaterMark水位线底层原理剖析
- 4.3.3.6、Flink WaterMark企业常见使用方式实践
- 4.3.3.7、Flink Time AllowedLateness原理深度剖析
- 4.3.4、Flink SQL及优化
- 4.3.4.1、Flink Table架构设计思路剖析
- 4.3.4.2、Flink Table Environment原理深度剖析
- 4.3.4.3、Flink Table Api操作核心点详解
- 4.3.4.4、Flink SQL 操作核心点详解
- 4.3.4.5、一线互联网公司Flink SQL使用场景实践分析
- 4.3.4.6、FlinkCheckpoint优化及参数深度剖析
- 4.3.4.7、Flink 内存优化设计及参数深度剖析
- 4.3.4.8、Flink网络缓存优化方案设计
- 4.3.5、Flink源码
- 4.3.5.1、Flink Actor源码深度剖析
- 4.3.5.2、Flink Akka底层原理深度剖析
- 4.3.5.3、Flink Rpc通信源码级详解
- 4.3.5.4、Flink 提交任务源码深度剖析
- 4.3.5.5、Flink 配置深度剖析
- 4.3.5.6、Flink ApplicationMaster启动流程源码深度剖析
- 4.3.5.7、Flink ResourceManager启动流程源码深度剖析
- 4.3.5.8、Flink Dispatcher启动流程源码深度剖析
- 4.3.5.9、Flink JobManager启动流程源码深度剖析
- 4.3.5.10、Flink SlotManager启动流程源码深度剖析
- 4.3.5.11、Flink 资源申请流程源码级别跟踪
- 4.3.5.12、Flink 启动TaskManager流程设计
- 4.3.5.13、Flink 注册Slot源码深度剖析
- 4.3.5.14、Flink SlotPool 申请资源源码跟踪
- 4.3.5.15、Flink SlotManager分配Slot源码深度剖析
- 4.3.5.16、Flink Flink 任务调度Graph源码深度剖析
- 4.3.5.17、Flink Task调度任务深度剖析
- 4.3.5.18、Flink Task执行源码深度剖析
- 4.3.5.19、Flink 内存模型解释
- 4.3.5.20、Flink 内存分配源码深度剖析
- 4.3.5.21、Flink 内存管理源码深度剖析
- 4.3.1、Flink 基础
5、大数据EB级架构设计之OLAP生态体系篇
- 5.1、分布式OLAP分析引擎生态体系深度剖析
- 5.1.1、OLAP分析引擎之Kylin
- 5.1.1.1、Kylin架构设计思路深度剖析
- 5.1.1.2、Kylin 核心Cube构架原理剖析
- 5.1.1.3、Kylin 表类型及查询核心点剖析
- 5.1.1.4、Kylin 数据分析模型方案设计
- 5.1.1.5、Kylin 企业级应用场景实践
- 5.1.1.6、Kylin 优化核心点深度剖析
- 5.1.2、OLAP分析引擎之Presto
- 5.1.2.1、Presto架构设计原理深度剖析
- 5.1.2.2、Presto Server底层原理分析
- 5.1.2.3、Presto企业级搭建综合应用
- 5.1.2.4、Presto命令体系详解
- 5.1.2.5、Presto查询核心点深度剖析
- 5.1.2.6、Presto SQL类型及优化点深度剖析
- 5.1.2.7、Presto与其他框架深度整合原理剖析
- 5.1.3、OLAP分析引擎之Druid
- 5.1.3.1、Druid架构设计思路原理剖析
- 5.1.3.2、Druid Segment底层原理剖析
- 5.1.3.3、Druid架构角色详解
- 5.1.3.4、Druid DeepStorage类型选择实践
- 5.1.3.5、Druid 企业级应用场景实践及优化设计
- 5.1.4、OLAP分析引擎之Impala
- 5.1.4.1、Impala基于内存计算核心原理剖析
- 5.1.4.2、IImpala框架角色系统详解
- 5.1.4.3、IImpala命令参数详解及场景实践
- 5.1.4.4、IImpala支持文件格式与压缩核心剖析
- 5.1.4.5、IImpala 企业级应用场景分析及优化
- 5.1.5、OLAP分析引擎之Phoenix
- 5.1.5.1、Phoenix与HBase整合原理深度剖析
- 5.1.5.2、Phoenix企业级部署实践
- 5.1.5.3、Phoenix数据类型及使用命令详解
- 5.1.5.4、Phoenix表映射与视图构建实践
- 5.1.5.5、Phoenix二级索引、全局索引、本地索引构建方案设计
- 5.1.5.6、Phoenix加盐表原理深度剖析
- 5.1.5.7、Phoenix JDBC企业级场景操作实践与优化
- 5.1.6、OLAP分析引擎之Kudu
- 5.1.6.1、Kudu架构设计原理深度剖析
- 5.1.6.2、Kudu存储模型及概念术语详解
- 5.1.6.3、Kudu Table底层原理深度剖析
- 5.1.6.4、Kudu 增删改查企业级实践及优化
- 5.1.6.5、Kudu 与Impala 、Spark、Flink框架深度整合原理剖析
- 5.1.7、OLAP分析引擎之Clickhouse
- 5.1.7.1、OClickHouse架构设计及特点深度剖析
- 5.1.7.2、ClickHouse数据压缩底层原理剖析
- 5.1.7.3、ClickHouse向量化执行核心点深度剖析
- 5.1.7.4、ClickHouse数据类型体系详解
- 5.1.7.5、ClickHouse数据库引擎类别及各自特点剖析
- 5.1.7.6、ClickHouse表引擎类别及各自特点深度剖析
- 5.1.7.7、ClickHouse DDL、DML实践及优化核心点
- 5.1.7.8、ClickHouse数据导入导出企业级场景实践
- 5.1.7.9、ClickHouse与Flink、Spark框架深度整合
- 5.1.8、OLAP分析引擎之Doris
- 5.1.8.1、Doris架构设计原理深度剖析
- 5.1.8.2、Doris企业级集群部署实践
- 5.1.8.3、Doris数据模型系统详解
- 5.1.8.4、Doris聚合计算底层原理剖析
- 5.1.8.5、Doris 企业级应用核心点详解
- 5.1.8.6、Doris与Kafka整合原理深度剖析
- 5.1.1、OLAP分析引擎之Kylin
6、大数据EB级架构设计之稳健架构设计体系篇
- 6.1、分布式离线数据仓库体系构建方法论
- 6.1.1、离线数仓构建方法指导论
- 6.1.1.1、关系型数据库三范式详解
- 6.1.1.2、E-R实体关系与范式建模理论基础详解
- 6.1.1.3、E-R实体关系建模案例实践
- 6.1.1.4、数据仓库发展历程详解
- 6.1.1.5、自上而下建模与自下而上建模理论深度剖析
- 6.1.1.6、维度建模方法论详解
- 6.1.1.7、星型模型&雪花模型&星座模型及选型方案设计
- 6.1.1.8、维度建模案例实践
- 6.1.1.9、数据仓库分层思想详解
- 6.1.1.10、数据仓库 ODS层设计与实现
- 6.1.1.11、数据仓库 DWS层设计与实现
- 6.1.1.12、数据仓库 DWD层设计与实现
- 6.1.1.13、数据仓库 DWS层设计与实现
- 6.1.1.14、数据仓库 DM层设计与实现
- 6.1.1.15、数据仓库分层案例分析
- 6.1.1.16、大数据企业离线数仓架构分析
- 6.1.1.17、数仓数据来源及采集
- 6.1.1.18、数据仓库每层命令设计规范
- 6.1.1.19、数据仓库架构技术选型实战
- 6.1.1.20、数据仓库架构设计优缺点解析
- 6.1.1、离线数仓构建方法指导论
- 6.2、分布式实时数据仓库体系构建方法论
- 6.2.1、实时数仓构建方法指导论
- 6.2.1.1、实时数仓架构演变深度剖析
- 6.2.1.2、传统离线大数据架构特点分析
- 6.2.1.3、Lambda架构技术选型设计与优缺点
- 6.2.1.4、Kappa架构技术选型设计与优缺点
- 6.2.1.5、混合架构技术选型设计与优缺点
- 6.2.1.6、离线数仓与实时数仓特点对比
- 6.2.1.7、实时数仓建设思路总结及方案设计
- 6.2.1.8、实时数仓发展趋势与企业级实时数仓设计思路
- 6.2.1.9、批流一体架构模式到底如何设计
- 6.2.1.10、互联网大厂湖仓一体架构设计方式及实战
- 6.2.1.11、互联网大厂网易实时数仓构建实践与优缺点深度剖析
- 6.2.1.12、互联网大厂汽车之家实时数仓构建实践与优缺点深度剖析
- 6.2.1.13、互联网大厂顺丰实时数仓构建实践与优缺点深度剖析
- 6.2.1.14、互联网大厂腾讯实时数仓构建实践与优缺点深度剖析
- 6.2.1.15、互联网大厂滴滴实时数仓构建实践与优缺点深度剖析
- 6.2.1.16、实时数仓前沿思路扩展及实时数仓发展方向总结
- 6.2.1、实时数仓构建方法指导论
- 6.3、分布式数据治理技术体系深度剖析
- 6.3.1、数据质量管理
- 6.3.1.1、为什么各大公司需要数据治理
- 6.3.1.2、主数据管理构建思路与方案设计
- 6.3.1.3、元数据管理构建思路与方案设计
- 6.3.1.4、数据标准管理构建思路与方案设计
- 6.3.1.5、数据质量管理构建思路与方案设计
- 6.3.1.6、数据集成管理构建思路与方案设计
- 6.3.1.7、数据资产管理构建思路与方案设计
- 6.3.1.8、数据安全管理构建思路与方案设计
- 6.3.1.9、数据生命周期管理构建思路与方案设计
- 6.3.1.10、数据交换管理构建思路与方案设计
- 6.3.1.11、数据质量系统详解
- 6.3.1.12、数据质量问题根源问题解决
- 6.3.1.13、数据质量保证原则剖析
- 6.3.1.14、数据仓库数据质量管理设计剖析
- 6.3.1.15、数据仓库质量管理企业级案例分析
- 6.3.1.16、ODS层质量监控方式及实践
- 6.3.1.17、EDS层质量监控方式及实践
- 6.3.1.18、DM层质量监控方式及实践
- 6.3.2、元数据管理Atlas
- 6.3.2.1、互联网大厂做的元数据管理是什么
- 6.3.2.2、元数据管理工具Atlas原理详解
- 6.3.2.3、Atlas架构原理深度剖析
- 6.3.2.4、Atlas特性详解
- 6.3.2.5、企业级Atlas搭建部署
- 6.3.2.6、Atlas集成Hive原理深度剖析
- 6.3.2.7、Atlas页面实操详解
- 6.3.2.8、Atlas企业级案例详解
- 6.3.2.9、Atlas元数据管理及优化设计
- 6.3.3、数据安全管理Ranger
- 6.3.3.1、数据安全管理方案设计
- 6.3.3.2、Ranger底层架构原理剖析
- 6.3.3.3、Ranger源码编译及企业级安装部署
- 6.3.3.4、Ranger同步Linux用户实践
- 6.3.3.5、Ranger管理Hive安全实践
- 6.3.3.6、Ranger-hive-plugin原理深度剖析
- 6.3.3.7、Ranger管理HDFS安全实践
- 6.3.3.8、HDFS-plugin底层原理及优化
- 6.3.4、数据安全管理Kerberos
- 6.3.4.1、Kerberos 认证机制原理剖析
- 6.3.4.2、Hadoop Kerberos 工作原理深度剖析
- 6.3.4.3、Kerberos 企业级安装部署
- 6.3.4.4、Kerberos 创建用户、认证用户原理剖析
- 6.3.4.5、在ClouderaManager中使用Kerberos实践
- 6.3.4.6、Kerberos keytab配置原理及实践
- 6.3.4.7、Zookeeper添加Kerberos安全认证生产实践
- 6.3.4.8、Hadoop HDFS 添加Kerberos安全认证生产实践
- 6.3.4.9、Yarn 添加Kerberos安全认证生产实践
- 6.3.4.10、Hive 添加Kerberos安全认证生产实践
- 6.3.4.11、HBase 添加Kerberos安全认证生产实践
- 6.3.4.12、Kafka 添加Kerberos安全认证生产实践
- 6.3.1、数据质量管理
- 6.4、信息化数据中台技术体系深度剖析
- 6.4.1、数据中台构建方法指导论
- 6.4.1.1、数据中台构建之数据中台产生背景剖析
- 6.4.1.2、数据中台构建之数据中台概念与类比案例
- 6.4.1.3、数据中台构建之前、中、后台剖析
- 6.4.1.4、数据中台构建之数据中台与业务中台区别与联系
- 6.4.1.5、数据中台构建之数据中台与大数据平台关系剖析
- 6.4.1.6、数据中台构建之数据中台构建方法论剖析
- 6.4.1.7、数据中台构建之数据中台功能架构设计
- 6.4.1.8、数据中台构建之数据中台技术架构设计
- 6.4.1.9、数据中台构建之数据应用成熟度阶段分类
- 6.4.1.10、数据中台构建之数据应用各阶段剖析
- 6.4.1.11、数据中台构建之不同行业中台构建需求剖析
- 6.4.1.12、数据中台构建之打破企业数据鼓捣
- 6.4.1.13、数据中台构建之提取数据价值
- 6.4.1.14、数据中台构建之数据体系建设与标签构建
- 6.4.1.15、数据中台构建之数据资产管理剖析
- 6.4.1.16、数据中台构建之数据中台资产运营机制
- 6.4.1.17、数据中台构建之数据安全管理剖析
- 6.4.1.18、数据中台构建之各行业数据中台解决方案剖析
- 6.4.1.19、数据中台构建之数据中台未来发展方向剖析
- 6.4.1、数据中台构建方法指导论
- 6.5、BI大数据可视化技术体系深度剖析
- 6.5.1、BI可视化Hue
- 6.5.1.1、Hue架构原理底层剖析
- 6.5.1.2、Hue企业级分布式安装与部署
- 6.5.1.3、Hue与HDFS深度整合原理及实践
- 6.5.1.4、Hue与YARN深度整合原理及实践
- 6.5.1.5、Hue与HIVE深度整合原理及实践
- 6.5.1.6、Hue metadata原理深度剖析
- 6.5.1.7、Hue 用户管理及企业级生产实践
- 6.5.2、BI可视化Superset
- 6.5.2.1、Superset BI工具原理剖析
- 6.5.2.2、Superset BI 基于Linux的企业级部署
- 6.5.2.3、Supserset 对接外部数据库实践
- 6.5.2.4、Supserset自动绘制BI各种报表企业级应用实践
- 6.5.3、BI大屏可视化TCV
- 6.5.3.1、TCV大屏可视化工具布局
- 6.5.3.2、TCV大屏可视化工具大屏展示效果
- 6.5.3.3、企业级数据接口实战开发
- 6.5.3.4、内网穿透工具安装与配置实践
- 6.5.3.5、TCV大屏、轮播表、装饰、地图数据可视化
- 6.5.3.6、TCV数据表格定制
- 6.5.3.7、TCV数据定时刷新
- 6.5.3.8、大屏可视化工具选型对比
- 6.5.1、BI可视化Hue
7、大数据EB级架构设计之集群调度管理体系篇
- 7.1、分布式资源调度引擎Yarn底层深度剖析
- 7.1.1、分布式资源调度框架Yarn
- 7.1.1.1、Yarn架构设计思路深度剖析
- 7.1.1.2、Yarn ResourceManager原理深度解析
- 7.1.1.3、Yarn NodeManager原理深度解析
- 7.1.1.4、企业级Yarn分布式集群部署实践
- 7.1.1.5、Yarn 配置文件系统详解及优化设置
- 7.1.1.6、Yarn提交任务执行流程源码跟踪
- 7.1.1.7、Yarn ResourceManager启动源码深度剖析
- 7.1.1.8、Yarn NodeManager启动源码深度剖析
- 7.1.1、分布式资源调度框架Yarn
- 7.2、分布式任务调度引擎技术体系深度剖析
- 7.2.1、任务流调度oozie
- 7.2.1.1、Oozie架构底层原理剖析
- 7.2.1.2、Oozie框架角色深度剖析
- 7.2.1.3、Oozie Xml、Job配置文件详解
- 7.2.1.4、Oozie命令系统讲解
- 7.2.1.5、Oozie配置与监控实操演练
- 7.2.1.6、Oozie企业级案例开发实战
- 7.2.2、任务流调度Azkaban
- 7.2.2.1、Azkaban架构原理深度剖析
- 7.2.2.2、Azkaban WebServer原理深度剖析
- 7.2.2.3、Azkaban ExecutorServer原理深度剖析
- 7.2.2.4、Azkaban 企业级环境部署及实践
- 7.2.2.5、Azkaban 安全配置原理及实践
- 7.2.2.6、Azkaban Job编写及企业级配置实践
- 7.2.2.7、Azkaban 工作流监控原理及实践
- 7.2.3、任务流调度Airflow
- 7.2.3.1、Airflow任务流调度原理深度剖析
- 7.2.3.2、Airflow企业级部署实践
- 7.2.3.3、Airflow DAG任务原理深度剖析
- 7.2.3.4、Airflow WebServer、Scheduler、Worker、Executor深度剖析
- 7.2.3.5、Airflow 系统配置及优化设置
- 7.2.3.6、Airflow企业级案例实践
- 7.2.3.7、Airflow可视化操作及页面功能详解
- 7.2.1、任务流调度oozie
- 7.3、大数据集群管理平台体系深度剖析
- 7.3.1、集群管理平台ClouderaManager
- 7.3.1.1、Cloudera Manager架构设计原理剖析
- 7.3.1.2、Cloudera Manager Server、Agent原理深度剖析
- 7.3.1.3、Cloudera Manager 架构流程图解
- 7.3.1.4、Cloudera Manager 企业级部署实践
- 7.3.1.5、Cloudera Manager 部署CDH实践
- 7.3.1.6、Cloudera Manager 页面模块详解
- 7.3.1.7、Cloudera Manager 日志查看、图表查看详解
- 7.3.1.8、Cloudera Manager 配置优化详解
- 7.3.2、集群管理平台Ambari
- 7.3.2.1、Ambari集群架构原理详解
- 7.3.2.2、Ambari企业级部署实践
- 7.3.2.3、Ambari体系架构原理剖析
- 7.3.2.4、Ambari 仪表盘、状态、Metrics实践
- 7.3.2.5、Ambari WebUI功能模块详解
- 7.3.2.6、Ambari与HDP整合实践
- 7.3.2.7、Ambari 日志查看与优化详解
- 7.3.1、集群管理平台ClouderaManager
8、大数据EB级架构设计之数据挖掘体系篇
- 8.1、机器学习与数据挖掘算法体系深度剖析
- 8.1.1、多元线性回归算法
- 8.1.1.1、机器学习与人工智能关系
- 8.1.1.2、机器学习数学详解
- 8.1.1.3、线性回归原理剖析
- 8.1.1.4、线性回归损失函数公式推导
- 8.1.1.5、梯度下降迭代确定模型
- 8.1.1.6、多元线性回归原理剖析
- 8.1.1.7、步长参数分析及优化设计
- 8.1.1.8、模型过拟合、欠拟合问题及优化设计
- 8.1.1.9、线性回归企业级案例生产实践
- 8.1.2、贝叶斯分类算法
- 8.1.2.1、贝叶斯分类算法原理剖析
- 8.1.2.2、贝叶斯算法术语详解
- 8.1.2.3、贝叶斯概率分类原理详解
- 8.1.2.4、贝叶斯公式推广及推导
- 8.1.2.5、拉普拉斯估计原理
- 8.1.2.6、企业级案例生产实践
- 8.1.3、KNN分类算法
- 8.1.3.1、KNN算法原理核心剖析
- 8.1.3.2、K值的选择问题
- 8.1.3.3、KNN存在的问题
- 8.1.3.4、机器学习中的归一化
- 8.1.3.5、欧式距离详解
- 8.1.3.6、平方欧式距离详解
- 8.1.3.7、闵式距离详解
- 8.1.3.8、曼哈顿距离详解
- 8.1.3.9、谷本距离详解
- 8.1.3.10、切比雪夫距离详解
- 8.1.3.11、加权距离详解
- 8.1.3.12、KNN三要素详解
- 8.1.3.1、企业级案例生产实践
- 8.1.4、Kmeans算法、Kmeans++算法
- 8.1.4.1、Kmeans聚类算法原理剖析
- 8.1.4.2、K值的选择策略
- 8.1.4.3、肘部法确定K值
- 8.1.4.4、Kmeans聚类问题分析
- 8.1.4.5、Kmens++算法特点与优势
- 8.1.4.6、手动实现Kmeans算法
- 8.1.4.7、企业级案例生产实践
- 8.1.5、TF-IDF算法
- 8.1.5.1、文本分词技术解析
- 8.1.5.2、词频分析详解
- 8.1.5.3、逆文本频率分析详解
- 8.1.5.4、TF-IDF原理剖析
- 8.1.5.5、TF-IDF企业级案例生产实践
- 8.1.6、逻辑回归分类算法
- 8.1.6.1、逻辑回归分类算法原理深度剖析
- 8.1.6.2、逻辑回归与线性回归对比分析
- 8.1.6.3、求导法则详解
- 8.1.6.4、log对数运算法则详解
- 8.1.6.5、最大似然估计思想
- 8.1.6.6、对数似然函数推导
- 8.1.6.7、逻辑回归构造损失函数
- 8.1.6.8、逻辑回归损失函数公式推导
- 8.1.6.9、SGD梯度下降过程
- 8.1.6.10、混淆矩阵详解
- 8.1.6.11、ROC&AUC评估指标
- 8.1.6.12、企业级案例生产实践
- 8.1.7、决策树算法
- 8.1.7.1、决策树概念及术语详解
- 8.1.7.2、信息熵、条件熵原理详解
- 8.1.7.3、信息增益、信息增益率详解
- 8.1.7.4、基尼系数详解
- 8.1.7.5、ID3选择法与C4.5选择法选择
- 8.1.7.6、数据离散化处理
- 8.1.7.7、决策树回归值使用
- 8.1.7.8、预剪枝与后剪枝
- 8.1.7.9、决策树问题解决
- 8.1.7.10、企业级案例生产实践
- 8.1.8、随机森林算法
- 8.1.8.1、随机森林算法详解
- 8.1.8.2、随机森林随机选择方式
- 8.1.8.3、指定树的个数原则
- 8.1.8.4、随机森林分类规则详解
- 8.1.8.5、随机森林与决策树的关系
- 8.1.8.6、企业级案例生产实践
- 8.1.1、多元线性回归算法
这篇文章会持续更新,想看到完整版记得关注博主喔
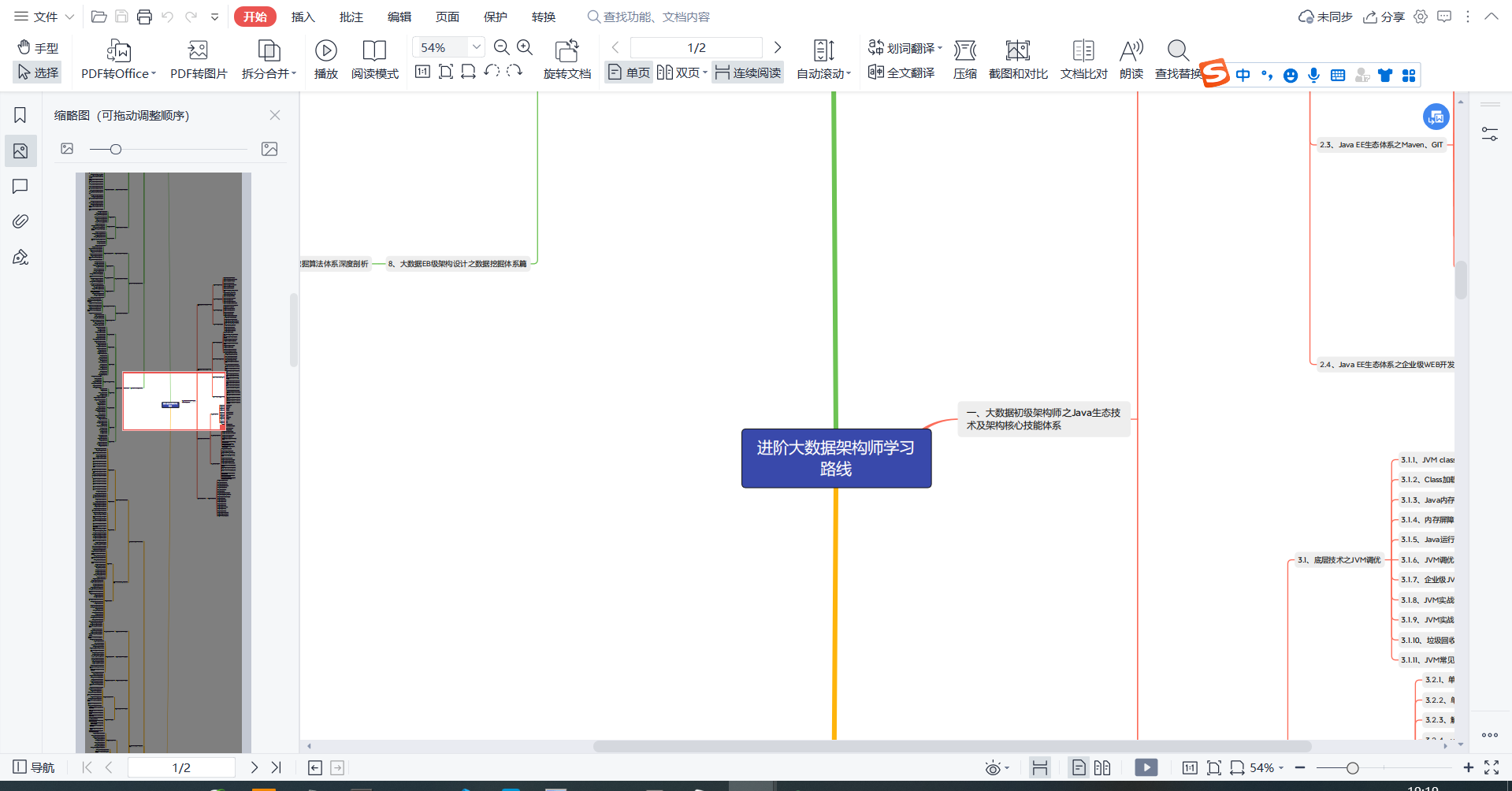
关注公众号【三帮大数据】回复“大数据”可领取高清学习路线图
不想添加公众号,也有大图,由于限制上传图片大小5M以内,这张图有点不清晰

- *文末惊喜

大数据入门核心技术是全网最划算的付费专栏,里面有集合Hadoop、Hive、HBase、Spark、Flink等大数据必学的核心技术,原价99元,现在活动价,声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/Gausst松鼠会/article/detail/439205
推荐阅读
相关标签
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

