
- 1【从零开始】Docker Desktop:听说你小子要玩我_dockerdesktop 阿里
- 2使用Dockerfile创建docker镜像_dockerfile from images
- 3Git学习(一)_保存文件的状态_git stash保存untrack文件
- 4使用vscode编译器,&运行c++程序_vscode怎么运行c++
- 5若依框架——前后端分离版
- 6win10官方不再支持PHP,优雅的使用WSl安装PHP环境_wsl下载php
- 7Android相机支持的预览格式详解_getsupportedpreviewformats
- 8C++ 类成员函数作用域以及构造函数初始值列表_c++类中初始化,作用域
- 9phton如何将文件内容转化为二维数组_从文件中还原二维数组 python
- 10【Python 第2篇】如何用Python设计简单的“猜数字”小游戏_用python输入数字,猜测输的对不对
【数据分析与挖掘(二)】面试题汇总(附答案)_给定如下的数据集,现考虑两种不同的属性划分形式: (a)二路划分:gender=m, gender=
赞
踩
现整理python数据分析与挖掘相关面试题如下(代码已亲试),供自己与有需要的同仁共同学习提高。
活到老,学到老!(梭伦) 终身学习!
面试题
python数据分析
1 列举几个常用的python分析数据包及其作用
数据处理和分析:NumPy, SciPy, Pandas
机器学习:SciKit
可视化: Matplotlib, Seaborn
2 在python中如何创建包含不同类型数据的dataframe
利用pandas包的DataFrame函数的serias创建列然后用dtype定义类型:
df = pd.DataFrame({'x': pd.Series(['1.0', '2.0', '3.0'], dtype=float), 'y': pd.Series(['1', '2', '3'],
dtype=int)})
- 1
- 2
3 归一化
归一化方法:最小-最大规范化、零-均值规范化、小数定标规范化
作用1:消除量纲,在多指标评价体系中,由于各评价指标的性质不同,通常具有不同的量纲和数量级。当各指标间的水平相差很大时,如果直接用原始指标值进行分析,就会突出数值较高的指标在综合分析中的作用,相对削弱数值水平较低指标的作用。因此,为了保证结果的可靠性,需要对原始指标数据进行标准化处理。
作用2:提升模型的收敛速度,狭长的标量场经过标准化后变得比较圆,这样会大大提升计算的收敛速度。
4 如何处理缺失数据?(如果缺失的数据不可得,将采用何种手段收集?)
1)删除样本或删除字段
2)用中位数、平均值、众数等填充
3)插补:同类均值插补、多重插补、极大似然估计
4)用其它字段构建模型,预测该字段的值,从而填充缺失值(注意:如果该字段也是用于预测模型中作为特征,那么用其它字段建模填充缺失值的方式,并没有给最终的预测模型引入新信息)
5)onehot,将缺失值也认为一种取值
6)压缩感知及矩阵补全
5 如何避免决策树过拟合
1)限制树深
2)剪枝
3)限制叶节点数量
4)正则化项
5)增加数据
6)bagging(subsample、subfeature、低维空间投影)
7)数据增强(加入有杂质的数据)
8)早停
6 怎么做恶意刷单检测
分类问题用机器学习方法建模解决,我想到的特征有:
1)商家特征:商家历史销量、信用、产品类别、发货快递公司等
2)用户行为特征:用户信用、下单量、转化率、下单路径、浏览店铺行为、支付账号
3)环境特征(主要是避免机器刷单):地区、ip、手机型号等
4)异常检测:ip地址经常变动、经常清空cookie信息、账号近期交易成功率上升等
5)评论文本检测:刷单的评论文本可能套路较为一致,计算与已标注评论文本的相似度作为特征
6)图片相似度检测:同理,刷单可能重复利用图片进行评论
7 讲下 K-Means算法的原理及改进,遇到异常值怎么办?评估算法的指标有哪些?
1)k-means原理:选k个点开始作为聚类中心,然后剩下的点根据距离划分到类中;找到新的类中心;重新分配点;迭代直到达到收敛条件或者迭代次数。 优点是快;缺点是要先指定k,同时对异常值很敏感。
在最小化函数误差的基础上将数据划分为预定的类树K,采用距离作为相似性的评价指标,即认为两个对象的距离越近,其相似度就越大。
< size=5>2)聚类方法主要有:
a. 层次聚类
b. 划分聚类:kmeans
c. 密度聚类
d. 网格聚类
e. 模型聚类:高斯混合模型
3)改进:
a. kmeans++:初始随机点选择尽可能远,避免陷入局部解。方法是n+1个中心点选择时,对于离前n个点选择到的概率更大。
b. mini batch kmeans:每次只用一个子集做重入类并找到类心(提高训练速度)
c. ISODATA:对于难以确定k的时候,使用该方法。思路是当类下的样本小时,剔除;类下样本数量多时,拆分。
d. kernel kmeans:kmeans用欧氏距离计算相似度,也可以使用kernel映射到高维空间再聚类。
4)遇到异常值
a. 使用密度聚类或者一些软聚类的方式先聚类,剔除异常值。不过本来用kmeans就是为了快,这么做有些南辕北辙。
b. 局部异常因子LOF:如果点p的密度明显小于其邻域点的密度,那么点p可能是异常值。
c. 多元高斯分布异常点检测
d. 使用PCA或自动编码机进行异常点检测:使用降维后的维度作为新的特征空间,其降维结果可以认为剔除了异常值的影响(因为过程是保留使投影后方差最大的投影方向)
e. isolation forest:基本思路是建立树模型,一个节点所在的树深度越低,说明将其从样本空间划分出去越容易,因此越可能是异常值。是一种无监督的方法,随机选择n个sumsampe,随机选择一个特征一个值。
8 SVM的优缺点
1)优点:
a. 能应用于非线性可分的情况
b. 最后分类时由支持向量决定,复杂度取决于支持向量的数目而不是样本空间的维度,避免了维度灾难
c. 具有鲁棒性:因为只使用少量支持向量,抓住关键样本,剔除冗余样本
d. 高维低样本下性能好,如文本分类
2)缺点:
a. 模型训练复杂度高
b. 难以适应多分类问题
c. 核函数选择没有较好的方法论
9 hadoop原理和mapreduce原理
1)Hadoop原理:采用HDFS分布式存储文件,MapReduce分解计算,其它先略
2)MapReduce原理:
a. map阶段:读取HDFS中的文件,解析成<k,v>的形式,并对<k,v>进行分区(默认一个区),将相同k的value放在一个集合中。
b. reduce阶段:将map的输出copy到不同的reduce节点上,节点对map的输出进行合并、排序。
10 简述多线程、多进程
进程:
1、操作系统进行资源分配和调度的基本单位,多个进程之间相互独立
2、稳定性好,如果一个进程崩溃,不影响其他进程,但是进程消耗资源大,开启的进程数量有限制
线程:
1、CPU进行资源分配和调度的基本单位,线程是进程的一部分,是比进程更小的能独立运行的基本单位,一个进程下的多个线程可以共享该进程的所有资源
2、如果IO操作密集,则可以多线程运行效率高,缺点是如果一个线程崩溃,都会造成进程的崩溃
应用:
1、IO密集的用多线程,在用户输入,sleep 时候,可以切换到其他线程执行,减少等待的时间
2、CPU密集的用多进程,因为假如IO操作少,用多线程的话,因为线程共享一个全局解释器锁,当前运行的线程会霸占GIL,其他线程没有GIL,就不能充分利用多核CPU的优势
11 一个网站销售额变低,你从哪几个方面去考量?
1)首先要定位到现象真正发生的位置,到底是谁的销售额变低了?这里划分的维度有:
a. 用户(画像、来源地区、新老、渠道等)
b. 产品或栏目
c. 访问时段
2)定位到发生未知后,进行问题拆解,关注目标群体中哪个指标下降导致网站销售额下降:
a. 销售额=入站流量下单率客单价
b. 入站流量 = Σ各来源流量转化率
c. 下单率 = 页面访问量转化率
d. 客单价 = 商品数量*商品价格
3)确定问题源头后,对问题原因进行分析,如采用内外部框架:
a. 内部:网站改版、产品更新、广告投放
b. 外部:用户偏好变化、媒体新闻、经济坏境、竞品行为等
12 还有用户流失的分析,新用户流失和老用户流失有什么不同?
1)用户流失分析:
a. 两层模型:细分用户、产品、渠道,看到底是哪里用户流失了。注意由于是用户流失问题,所以这里细分用户时可以细分用户处在生命周期的哪个阶段。
b. 指标拆解:用户流失数量 = 该群体用户数量*流失率。拆解,看是因为到了这个阶段的用户数量多了(比如说大部分用户到了衰退期),还是这个用户群体的流失率比较高
c. 内外部分析:
I. 内部:新手上手难度大、收费不合理、产品服务出现重大问题、活动质量低、缺少留存手段、用户参与度低等
II. 外部:市场、竞争对手、社会环境、节假日等
2)新用户流失和老用户流失有什么不同:
a. 新用户流失:原因可能有非目标用户(刚性流失)、产品不满足需求(自然流失)、产品难以上手(受挫流失)和竞争产品影响(市场流失)。
新用户要考虑如何在较少的数据支撑下做流失用户识别,提前防止用户流失,并如何对有效的新用户进行挽回。
b. 老用户流失:原因可能有到达用户生命周期衰退期(自然流失)、过度拉升arpu导致低端用户驱逐(刚性流失)、社交蒸发难以满足前期用户需求(受挫流失)和竞争产品影响(市场流失)。
老用户有较多的数据,更容易进行流失用户识别,做好防止用户流失更重要。当用户流失后,要考虑用户生命周期剩余价值,是否需要进行挽回。
13 怎么向小孩子解释正态分布
(随口追问了一句小孩子的智力水平,面试官说七八岁,能数数)
1)拿出小朋友班级的成绩表,每隔2分统计一下人数(因为小学一年级大家成绩很接近),画出钟形。然后说这就是正态分布,大多数的人都集中在中间,只有少数特别好和不够好
2)拿出隔壁班的成绩表,让小朋友自己画画看,发现也是这样的现象
3)然后拿出班级的身高表,发现也是这个样子的
4)大部分人之间是没有太大差别的,只有少数人特别好和不够好,这是生活里普遍看到的现象,这就是正态分布
14 淘宝办了一次促销活动,从哪些方面来评价这次活动是否成功,结合支付宝来考虑了这个问题
1)明确目标:拉新?促活?提客单?
2)根据目的确定核心指标
3)效果评估:
a. 自身比较:活动前与活动中比较
b. 与预定目标比
c. 与同期其它活动比
d. 与往期同类活动比
4)持续监控:
a. 检查活动后情况,避免透支消费情况发生
b. 如果是拉新等活动,根据后续数据检验这批新客的质量
15 柴静的穹顶之下前段时间很火,你来分析一下为什么能这么火?
1)明确问题:“火”这里有三个方面:
a. 微博上传播大
b. 媒体曝光量大
c. 线下传播与讨论多
2)分析原因(对(1)中abc三种情况分别分析,先用a举例):
传播能力 = 初始曝光能力 * 裂变能力
初始曝光能力是由于柴静自身有巨大的曝光能力,裂变能力是因为信息满足了传播者的需求。对传播者需求进行分析:
a. 内部:信息对传播者有影响(价值、震撼、鼓动等)、信息传播对传播者有利(内在想警醒别人、外在的社会形象、参与社会讨论等)
b. 外部:PEST
16 Linux基本命令
1)目录操作:ls、cd、mkdir、find、locate、whereis等
2)文件操作:mv、cp、rm、touch、cat、more、less
3)权限操作:chmod+rwx421
4)账号操作:su、whoami、last、who、w、id、groups等
5)查看系统:history、top
6)关机重启:shutdown、reboot
7)vim操作:i、w、w!、q、q!、wq等
17 SQL的数据类型
1)字符串:char、varchar、text
2)二进制串:binary、varbinary
3)布尔类型:boolean
4)数值类型:integer、smallint、bigint、decimal、numeric、float、real、double
5)时间类型:date、time、timestamp、interval
18 如何写SQL求出中位数平均数和众数(除了用count之外的方法)
1)中位数:
方案1(没考虑到偶数个数的情况):
set @m = (select count(*)/2 from table)
select column from table order by column limit @m, 1
- 1
- 2
- 3
方案2(考虑偶数个数,中位数是中间两个数的平均):
set @index = -1
select avg(table.column) from (select @index:=@index+1 as index, column from table order by column) as t
where t.index in (floor(@index/2),ceiling(@index/2))
- 1
- 2
- 3
- 4
- 5
2)平均数:select avg(distinct column) from table
3)众数:select column, count(*) from table group by column order by column desc limit 1(好像用到count了)
19 现有一个数据库表Tourists,记录了某个景点7月份每天来访游客的数量如下: id date visits 1 2017-07-01 100 …… 非常巧,id字段刚好等于日期里面的几号。现在请筛选出连续三天都有大于100天的日期。 上面例子的输出为: date 2017-07-01 ……
select t1.date
from Tourists as t1, Tourists as t2, Tourists as t3
on t1.id = (t2.id+1) and t2.id = (t3.id+1)
where t1.visits >100 and t2.visits>100 and t3.visits>100
- 1
- 2
- 3
- 4
- 5
- 6
20 在一张工资表salary里面,发现2017-07这个月的性别字段男m和女f写反了,请用一个Updae语句修复数据 例如表格数据是: id name gender salary month 1 A m 1000 2017-06 2 B f 1010 2017-06
update salary
set gender = replace('mf', gender, '')
- 1
- 2
- 3
21 统计教授多门课老师数量并输出每位老师教授课程数统计表
设表class中字段为id,teacher,course
1)统计教授多门课老师数量
select count(*) from class
group by teacher having count(*) > 1
- 1
- 2
- 3
2)输出每位老师教授课程数统计
select teacher, count(course) as count_course
from class
group by teacher
- 1
- 2
- 3
- 4
- 5
22 表user_id,visit_date,page_name,plat 统计近7天每天到访的新用户数 统计每个访问渠道plat7天前的新用户的3日留存率和7日留存率
1)近7天每天到访的新用户数
select day(visit_date), count(distinct user_id)
from table
where user_id not in
(select user_id from table
where day(visit_date) < date_sub(visit_date, interval 7day))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
2)每个渠道7天前用户的3日留存和7日留存
三日留存
先计算每个平台7日前的新用户数量
select t1.plat, t1.c/t2.c as retention_3 (select plat, count(distinct user_id) from table group by plat, user_id having day(min(visit_date)) = date_sub(now(), interval 7 day)) as t1 left join (select plat, count(distinct user_id) as c from table group by user_id having count(user_id) > 0 having day(min(visit_date)) = date_sub(now(), interval 7 day) and day(max(visit_date)) > date_sub(now(), interval 7 day) and day(max(visit_date)) <= date_sub(now(), interval 4day)) as t2 on t1.plat = t2.plat

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
23 请找出数列4,9,23,60,157的下一项(A)
A 411
B 314
C 425
D ABC均错
603-23=157,1573-60=411
python程序解析
1 以下代码的输出?
def multipliers():
return [lambda x: i * x for i in range(4)]
print ([m(2) for m in multipliers()])
[6, 6, 6, 6]
- 1
- 2
- 3
- 4
- 5
原因是 Python 的闭包的后期绑定导致的 late binding,这意味着在闭包中的变量是在内部函数被调用的时候被查找。所以结果是,当任何 multipliers() 返回的函数被调用,在那时,i 的值是在它被调用时的周围作用域中查找,到那时,无论哪个返回的函数被调用,for 循环都已经完成了,i 最后的值是 3,因此,每个返回的函数 multiplies 的值都是 3。因此一个等于 2 的值被传递进以上代码,它们将返回一个值 6 (比如: 3 x 2)。
2 以下代码的输出
def foo(i=[]):
i.append(1)
return i
print(foo())
print(foo())
[1]
[1, 1]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
新的默认列表仅仅只在函数被定义时创建一次。当foo没有被指定的列表参数调用的时候,其使用的是同一个列表。
3 创建三角级数类,阅读下列代码回答问题
import numpy as np import matplotlib.pyplot as plt class trigonometric_function: tra_1 = 6 tra_2 = 12 def __init__(self,a,k,l): self.const1 = a self.const2 = k self.const3 = l def Additive_term(self,x): self.summand_s = np.sin(self.const2*x + self.tra_1) self.summand_c = np.cos(self.const3*x + self.tra_2) def trigon_sum(self,m,n): sum_1 = sum([sum([self.const1*(self.summand_s**i)*(self.summand_c**j) for i in range(m)]) for j in range(n)]) return sum_1 def draw_pic(self,data): fig,axes_1 = plt.subplots(1,1,dpi=140,figsize=(6,4)) axes_1.plot(x,data) f1=trigonometric_function(3,4,6)#类的实例化 x=np.linspace(-5,5,500)#生成500个-5到5之间的点 f1.Additive_term(x)#生成普通三角函数sin和cos data=f1.trigon_sum(4,5)#生成三角级数数据 f1.draw_pic(data) plt.show()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
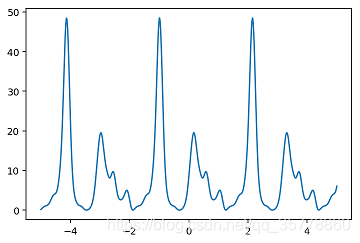
a.请在代码中找出类变量、实例变量、方法、对象
类变量:tra1,tra2,const1,const2,const3,summand_s,summand_c
实例变量:x,a,k,l,m,n,data(通常前面没有self.)
方法(属性): Additive_term、trigon_sum、draw_pic
对象:方法、类变量和实例变量
b.self 什么意思?
self 代表类的实例,self 在定义类的方法时是必须有的,虽然在调用时不必传入相应的参数。
说明:本文是从相关博文的分享总结与补充而来,如有疑问,还望各位同仁与前辈指正。
附作者相关研究:(望多多支持,感激不尽!)
超级热门工具下载!!!
DirectX修复工具V4.1增强版.zip
https://download.csdn.net/download/qq_35778860/76003621
DirectX修复工具V4.1标准版.zip
https://download.csdn.net/download/qq_35778860/76003426
DirectX修复工具V4.1在线修复版.zip
https://download.csdn.net/download/qq_35778860/76003325
周杰伦
周杰伦婚礼歌单 无损mp3歌曲 适用结婚 基础版+完整版
https://download.csdn.net/download/qq_35778860/80045641
Python:
Python实现线性回归、逻辑回归、KNN、SVM、朴素贝叶斯、决策树、K-Means7种机器学习算法的经典案例——亲测可用,链接
https://download.csdn.net/download/qq_35778860/20715889
Python实现飞机大战的完整代码——亲测可用,链接
https://download.csdn.net/download/qq_35778860/57165535
Python爬虫获取豆瓣网评分Top200的电影——亲测可用,链接
https://download.csdn.net/download/qq_35778860/56379309
Python根据下拉选项绘制雷达图和柱形图(异常预控平台)——亲测可用,链接
https://download.csdn.net/download/qq_35778860/20715210
python实现雷达图——亲测可用,链接
https://download.csdn.net/download/qq_35778860/20695215
基于python的北京房屋出租数据可视化分析与3D展示——亲测可用,链接
https://download.csdn.net/download/qq_35778860/20675051
基于Python设计的web接口聊天机器人
https://download.csdn.net/download/qq_35778860/66662593
用Python进行自然语言处理(中文).rar
https://download.csdn.net/download/qq_35778860/63652414
《机器学习实战》全书python代码——很全很完整
https://download.csdn.net/download/qq_35778860/62203534
Python3实现十大排序算法
https://download.csdn.net/download/qq_35778860/61630851
Python学生信息管理系统.zip
https://download.csdn.net/download/qq_35778860/85006851
C#
成绩管理系统(C/S结构的应用系统,含access数据库)——C#实现
https://download.csdn.net/download/qq_35778860/66967387
C#实现学生信息管理系统(包括增删改查功能)——亲测可用
https://download.csdn.net/download/qq_35778860/61620149
Matlab
极限学习机ELM+OSELM+KELM+半监督SSELM+USELM的matlab程序(附完整代码)
https://download.csdn.net/download/qq_35778860/56378533
BP+近邻KNN+LS最小二乘算法的matlab代码——亲测可用(含实例)
https://download.csdn.net/download/qq_35778860/56378309
基于matlab的卷积神经网络实现手写数字识别
https://download.csdn.net/download/qq_35778860/66667747
基于MATLAB的人工蜂群算法
https://download.csdn.net/download/qq_35778860/66665944
利用MATLABsilulink搭建有源电力滤波器仿真.zip
https://download.csdn.net/download/qq_35778860/63659150
动态规划MATLAB程序.zip
https://download.csdn.net/download/qq_35778860/63658838
基于matlab的模式识别基础实例源代码.zip
https://download.csdn.net/download/qq_35778860/63658486
Matlab_动态窗口法实现机器人在障碍环境下的模拟避碰仿真.zip
https://download.csdn.net/download/qq_35778860/63658232
bp神经网络整定pid参数matlab应用程序.rar
https://download.csdn.net/download/qq_35778860/63656174
利用深度学习的matlab程序编码仿真实现图像分割.zip
https://download.csdn.net/download/qq_35778860/63655267
matlab算法神经网络、粒子群算法、遗传算法、蚁群算法.rar
https://download.csdn.net/download/qq_35778860/74976067
Java
基于java的信息管理系统
https://download.csdn.net/download/qq_35778860/66658535
Java swing学生成绩系统(源码+数据库脚本).rar
https://download.csdn.net/download/qq_35778860/63653951
Jsp
jsp学生信息管理系统(源码+数据库脚本).zip
https://download.csdn.net/download/qq_35778860/63653655
SCN
随机配置网络SCN实现的matlab代码——亲测可用
https://download.csdn.net/download/qq_35778860/61636684
BLS
宽度学习BLS的matlab代码+Mnist数据集
https://download.csdn.net/download/qq_35778860/61635045
Mysql
Mysql增删改查代码操作,很全很完整——亲测可用
https://download.csdn.net/download/qq_35778860/61626574
C
基于单片机的交通灯控制系统设计(含代码,原理图)——C语言实现
https://download.csdn.net/download/qq_35778860/60383113
基于单片机的温度控制系统设计代码(含代码,原理图)——C语言实现
https://download.csdn.net/download/qq_35778860/60379923
郭天祥51单片机书中400例程——亲测可用
https://download.csdn.net/download/qq_35778860/58014293
Linux
一篇非常好的linux学习笔记分享(Linux入门绝佳).docx
https://download.csdn.net/download/qq_35778860/75444944
资料类
最全的事业编制考试计算机基础知识试题.doc
https://download.csdn.net/download/qq_35778860/85005561
江苏事业编制计算机类真题+解析.zip
https://download.csdn.net/download/qq_35778860/85005388
CSDN Share:大会PPT合集下载,纯干货!
https://download.csdn.net/download/qq_35778860/81175779
C语言教程基础篇【全免费】.ppt
https://download.csdn.net/download/qq_35778860/75560127
华为云Stack-8.0.pdf
https://download.csdn.net/download/qq_35778860/75445048
C++ 谭浩强(超级完整版).pptx
https://download.csdn.net/download/qq_35778860/74975782
表白类
999度玫瑰的表白程序源代码.zip
https://download.csdn.net/download/qq_35778860/74975889
网红表白程序-你要愿意爱我一辈子吗?
https://download.csdn.net/download/qq_35778860/74975870
Python设计表白神器无法拒绝的爱——亲测可用
https://download.csdn.net/download/qq_35778860/60723376
软件破解注册机
Matlab R2019b Win64 Crack.zip
https://download.csdn.net/download/qq_35778860/58000811
其他
微信转盘抽奖小程序源码.rar
https://download.csdn.net/download/qq_35778860/63652890

