
- 1python:word_(-2147024891, '拒绝访问。', none, none)
- 2微信小程序相册图片转base64_微信小程序 图片转base64
- 3【SVN】设置不提交的文件_svn设置不提交的文件
- 4数据结构与算法-拓扑排序_拓扑排序计算事故率是每个链路相加么
- 5什么是微信分付?微信分付怎么开通?如何3步开通微信分付
- 6利用Python提取函数图像数据并拟合曲线_根据函数图像生成数据
- 7unet图像分割_UNet++解读 + 它是如何对UNet改进 + 作者的研究态度和方式
- 8考虑储能电池参与一次调频技术经济模型的容量配置方法(matlab代码)
- 9从零搭建flyway+maven+Spring Boot,快速上手java_maven flyway
- 10PTA 甲级真题 1151 LCA in a Binary Tree_pta甲级真题
终极GPU互联技术探索:消失的内存墙_内存墙 在 gpu的作用
赞
踩

《AI算力的阿喀琉斯之踵:内存墙》一文曾指出,过去20年,硬件算力峰值增长了90000倍,但是DRAM/硬件互连带宽只增长了30倍。在这个趋势下,特别是芯片内或者芯片间的数据传输会迅速成为训练大规模AI模型的瓶颈。
上个月,在英伟达GTC 2024大会上发布了“更大的GPU”:新一代Blackwell 架构的B200和GB200 GPU ,其中B200采用台积电4nm工艺,晶体管数量高达2080亿,而GB200集成了1个Grace CPU和2个B200 GPU。
目前,头部AI芯片厂商都在推进现有芯片设计和制造技术的极限,但问题是,当这些“花招”用完后怎么办?
在面向AI负载的新锐芯片创业企业里,我们在此前的文章中提到了SambaNova、Tenstorrent和Ascenium,他们要解决的最核心的问题是placement和routing。
成立于2021年Eliyan公司则专注于芯片组互联技术,他们在物理层(physical layer,PHY)方面进行了架构创新,并推出了NuLink技术,号称能够在标准封装技术上上实现超大型系统级封装,从而通过消除算力内存墙(memory wall),将人工智能负载的性能提升10倍。今年3月,Eliyan获得了6000万美元的B轮融资。
(本文经授权后由OneFlow编译发布,转载请联系授权。原文:https://www.nextplatform.com/2024/03/28/how-to-build-a-better-blackwell-gpu-than-nvidia-did/)
作者 | Timothy Prickett Morgan
OneFlow编译
翻译|杨婷、宛子琳
当人们将目光投向各种计算引擎的浮点运算和整数处理架构时,我们却开始关注内存层次结构和互连层次结构。这是因为计算本身很简单,而数据搬运和内存管理却变得越来越难。
简单来说,可以通过一些数字进行说明:在过去的二十年里,CPU和GPU的计算能力增加了90000倍,但DRAM内存带宽和互连带宽却仅增加了30倍。近年来,虽然我们在某些方面取得了进步,但计算与内存之间的平衡仍严重失调。这意味着,针对许多AI和HPC工作负载,我们过度投资于内存不足的计算引擎。
考虑到这一点,我们开始关注Eliyan公司在物理层(physical layer,PHY)方面进行的架构创新。在MemCon 2024大会上,他们以新颖而实用的方式展示了这些创新。Eliyan的联合创始人兼首席执行官Ramin Farjadrad花了些时间向我们展示了NuLink PHY及其用例如何随着时间的推移而演变,以及如何用它们来构建比当前基于硅中介层(silicon interposer)的封装技术更好、更便宜、更强大的计算引擎。
PHY是一种物理网络传输设备,它将交换机芯片、网络接口或计算引擎内部的任何其他类型的接口连接到物理媒介(铜线、光纤、无线电信号),从而使它们能够相互连接或连接到网络。
硅中介层是一种特殊的电路桥(circuitry bridge),用于将HBM堆栈式DRAM内存与计算引擎(如GPU和常用于HPC和AI领域的定制ASIC)连接起来。有时,HBM也会用于需要高带宽内存的普通CPU。
Eliyan成立于2021年,总部位于圣何塞,目前公司规模已发展到60人,刚刚完成了第二轮6000万美元的融资,其中内存制造商三星和Tiger Global Capital领投了B轮融资。2022年11月,Eliyan完成了4000万美元的A轮融资,由Tracker Capital Management领投,Celesta Capital、英特尔、Marvell和存储器制造商美光科技也参与了投资。
Farjadrad在互联网繁荣时期曾担任Sun Microsystems和LSI Logic的设计工程师,后来成为了Velio Communications(现为LSI Logic的一部分)的 Switch ASIC首席工程师和联合创始人,并在Aquantia担任联合创始人兼首席技术官,该公司为汽车市场制造以太网PHY芯片。2019年9月,Marvell收购了Aquantia,并任命Farjadrad负责网络和汽车领域的PHY芯片。Marvell已成为最大的PHY芯片制造商之一,与Broadcom、Alphawave Semi、Nvidia、Intel、Synopsys、Cadence以及现在的Eliyan竞争,设计这些系统的关键组件。
Eliyan的其他联合创始人包括工程与运营主管Syrus Ziai,他曾在Ikanos、高通、PsiQuantum和Nuvia担任工程副总裁;Patrick Soheili担任商业与公司发展主管,之前负责eSilicon的产品管理和人工智能战略。eSilicon的出名得益于创建了苹果iPod音乐播放器内部的ASIC芯片以及开发2.5D ASIC封装和HBM内存控制器,2019年底,该公司以2.13亿美元的价格被Inphi收购,从而拓展了其PHY能力;而在2021年4月,Marvell以100亿美元的价格收购了Inphi,完成了其2020年10月收购闭环。
PHY、I/O SerDes以及retimer(重定时器)都蕴含着商机。SerDes是一种特殊类型的PHY,用于switch ASIC,以将设备输出的并行数据转换为串行数据,并通过电线、光纤或无线信号进行传输。从某种角度来看,retimer也是一种特殊的PHY,随着带宽的提高和铜线的距离缩短,retimer的使用频率会逐渐上升。
了解了PHY,接下来我们来聊聊2.5D封装技术。
随着摩尔定律下晶体管密度的增长放缓,以及随着每一代工艺技术的进步,晶体管的成本并没有降低,反而成本在提高,我们都意识到,现代芯片制程的光刻工艺存在的掩模限制(reticle limit)。使用普通的极紫外(EUV)水浸光刻技术,我们能在硅片上刻蚀的晶体管的最大尺寸为26mm×33mm。
然而,或许许多人并未意识到硅中介层的尺寸存在的限制,它限制了芯片组(chiplet)在有机基板(类似于每个计算引擎插槽及其附属的HBM内存下方的主板)上相互链接的能力。
硅中介层的尺寸取决于制造中间板所采用的技术。尽管中介层采用了与芯片相同的光刻工艺制造,但不同于芯片的858平方毫米掩模限制,今天的某些技术可以将中介层的面积扩大到2500平方毫米,使用其他技术则接近1900平方毫米,据Farjadrad称,他们计划将其扩大到3300平方毫米。有机基板插槽则不受这样的面积限制,这对于芯片组的2.5D封装非常重要。
Farjadrad介绍了Eliyan的NuLink PHY的竞品2.5D封装方法的参数、速度与局限性。
以下是台积电采用其Chip on Wafer on Silicon (CoWoS)工艺进行2.5D封装的方式,该工艺被用于创建Nvidia和AMD的GPU及其HBM堆栈等产品:
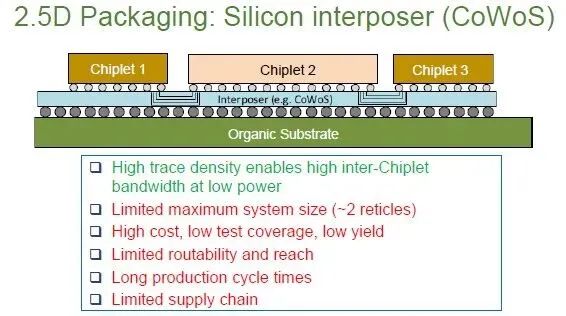
技术层面上,上图展示了台积电的CoWoS-S中介层技术,该技术用于将GPU、CPU和其他加速器连接到HBM内存。前身CoWoS-R的硅中介层尺寸大约限制在两个掩模单元,这恰好与Nvidia刚刚推出的“Blackwell” B100和B200 GPU的尺寸相同,但这款GPU采用了更先进、不那么引人注目的CoWoS-L技术,其制造更加复杂,类似于其他方法中使用的嵌入式桥。CoWoS-L在尺寸上有三个掩模单元的限制。
还有一种桥接技术被称为具有嵌入式桥的晶圆级扇出技术(wafer level fan out with embedded bridge),这种技术由芯片封装公司安靠科技(Amkor Technology)推广,ASE控股公司还提供了一种变体FOCoS-B。以下为该封装方法的参数和速度:
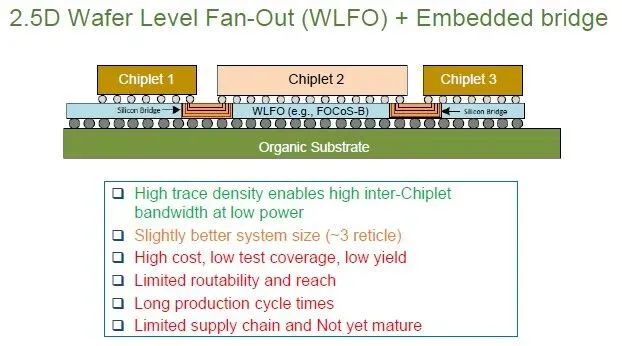
使用这种2.5D封装技术,可以制造一个尺寸约为三个掩模单元的封装包。高密度的走线意味着我们可以在低功耗下获得更高的芯片间带宽,但其连接范围受限,走线布线的路由能力也受到限制。实际上,这一技术还没有得到真正的大规模推广。
英特尔将硅桥直接嵌入到承载芯片的有机基板中——不使用中介层——这与Eliyan使用NuLink的方法相似:
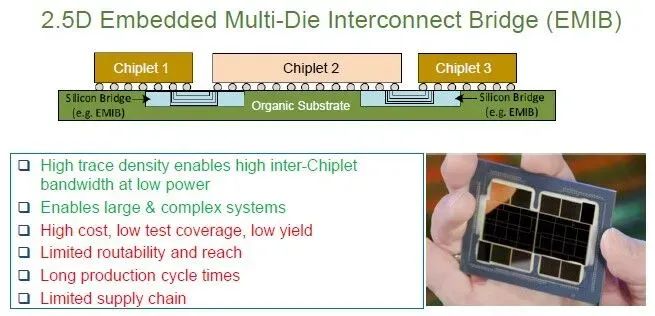
然而,EMIB(嵌入式多芯片互连桥接)技术存在一系列问题,包括生产周期长、良率低、有限的覆盖范围和布线能力,其供应链仅有英特尔这一家公司,它在当今先进半导体领域的声誉欠佳。公平地说,虽然英特尔正在逐步恢复正轨,但尚未达到预期水平。
这使得Eliyan提出的NuLink技术成为了一种改进的2D多芯片模块(MCM)工艺:
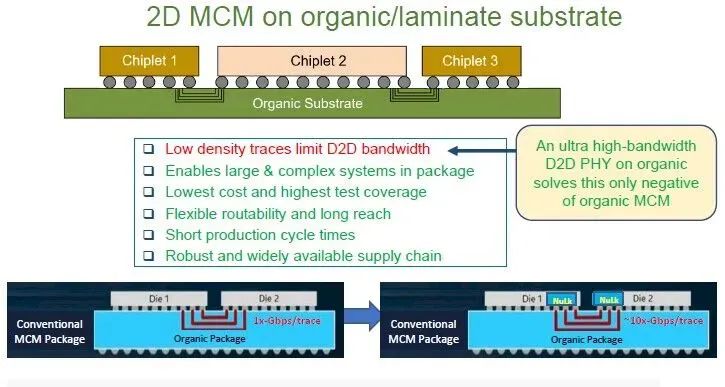
一年前,Farjadrad称,NuLink PHY的数据传输速率约为传统MCM封装中使用的PHY的10倍。此外,NuLink PHY之间的走线长度可以达到2cm至3cm,这比CoWoS和其他2.5D封装技术支持的0.1mm走线长度高了20至30倍。走线长度的增加以及NuLink PHY在这些走线上具有双向信号传输的特性,这对于计算引擎设计来说意义重大。目前市场上有更快的PHY可供竞对使用,使得NuLink PHY的优势降低到了4倍的差距。
Farjadrad告诉The Next Platform,根据当前的架构,在内存和ASIC之间传输数据包时,数据包是单向的,不具备同时双向传输的能力,要么从内存读取数据,要么向内存写入数据。但如果有一个端口可以同时传输或接收数据,就可以从同一I/O资源中中获得两倍的带宽,而这正是NuLink所实现的。这样,我们就不会浪费ASIC的一半I/O资源。
Farjadrad进一步提出,为了保持内存的一致性,需要使用特殊的自定义协议,确保读取和写入之间没有冲突。在设计PHY时,需要为特定的应用程序制定相关的协议,这是NuLink的重要优势之一。拥有最好的PHY技术只是一方面,另一方面,重要的是将其与正确的专业知识结合起来应用于人工智能应用,而Eliyan知道如何做到这一点。
2022年11月,当NuLink首次引入时还没有这个名称,当时Eliyan也尚未提出利用PHY来创建通用内存接口(UMI)的方法。NuLink最初只是一种实现能够使用UCI-Express芯片片间互连协议的方案,且支持Farjadrad及其团队多年前创建并捐赠给开放计算项目(Open Compute Project)作为提议标准的原始Bunch of Wires(BoW)芯片片间互连所支持的任何协议。下表中,Eliyan比较了NuLink与各种内存和芯片片间的互连协议:
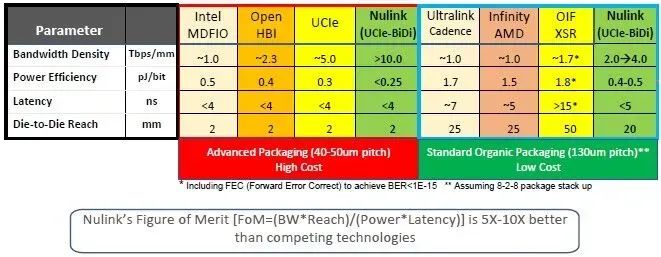
这张表很清晰。
Intel的“MDFIO”是“Multi-Die Fabric I/O(多芯片互连输入输出)”的缩写,用于连接“Sapphire Rapids”Xeon SP处理器中的四个计算芯片组。EMIB用于将这些芯片组连接到HBM内存栈,主要用于具有HBM的Sapphire Rapids的Max系列CPU变体。
OpenHBI基于JEDEC HBM3的电互连标准,也是一个OCP(开放计算项目)标准。UCI-Express是一种带有CXL一致性覆盖(coherency overlay)的新型PCI-Express,旨在成为芯片组之间的芯片间互连。
Nvidia的NVLink目前用于将Blackwell GPU复杂结构上的芯片组“粘”在一起,但以上表格并未列出;同样地,Intel的XeLink用于将“Ponte Vecchio”Max系列GPU上的GPU芯片组“粘”在一起,也未列入表格。与UCI-Express不同,NuLink PHY是双向的,这意味着,可以使用与UCI-Express相同数量或更多的导线,但能够实现UCI-Express的两倍或更多的带宽。
如图所示,这里有一种高成本的封装选项,它使用了40微米至50微米的凸点间距(bump pitch),且片间距离仅约为2mm。PHY的带宽密度可以非常高,每个芯片上的每毫米边缘区域的带宽可以达到Tb/sec级别,功耗效率则因方法而异,在所有情况下时延都低于4纳秒。
图表右侧的PHY可以与标准的有机基板封装配合使用,并使用了130微米的凸点,因此是成本更低的选择。这些选择包括Cadence的Ultralink PHY、AMD的Infinity Fabric PHY、Alphawave Semi的OIF Extra Short Reach(XSR)PHY,以及在不使用低凸点间距也能实现高信号传输的NuLink版本。
图表右侧是芯片间距,通过2cm的连接距离,我们可以做很多事,这是2mm间距以及ASIC与HBM堆栈或相邻芯片之间的0.1mm间距所无法实现的。这些更长的连接链路扩展了计算和内存复杂结构的几何布局,并且消除了ASIC和HBM之间的热串扰效应(thermal crosstalk effect)。堆栈内存对热度非常敏感,随着GPU变得越来越热,需要冷却HBM以确保其正常工作。如果能够使HBM远离ASIC,就可以更快地运行ASIC(Farjadrad估计速度能提高约20%),并且能够运行在更热的温度下,因为内存的距离比较远,不会受到ASIC热量增加的直接影响。
此外,通过在类似GPU的设备中去除硅中介层或其等效材料,转而使用有机基板,并使用更大的凸点和增加组件间距,可以将具有十二个HBM堆栈的双ASIC设备的制造成本从约12000美元(芯片加封装的产出率约为50%)降低到约6800美元,且实现87%的良率。
让我们通过两张图对比一下UCI-Express、BoW和UMI,然后我们可以稍微进行系统架构设计。
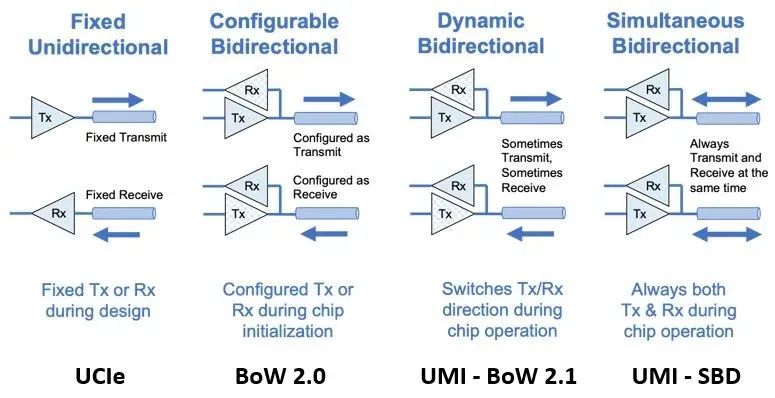
如图所示,Eliyan一直在不断推动其PHY的双向传输能力,且现在已经具备了同时进行双向数据传输的能力,称为UMI-SBD。
下图显示这四种选项的带宽和ASIC的芯片边缘区域(beachfront)情况:
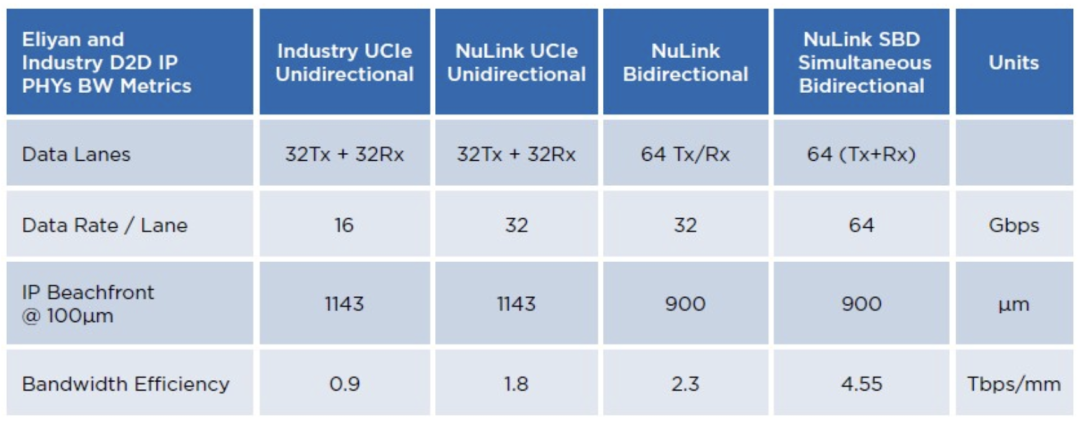
所以,现在被称为UMI的NuLink PHY比UCI-Express更小、更快,而且可以同时进行数据传输和接收。可以用它做什么呢?
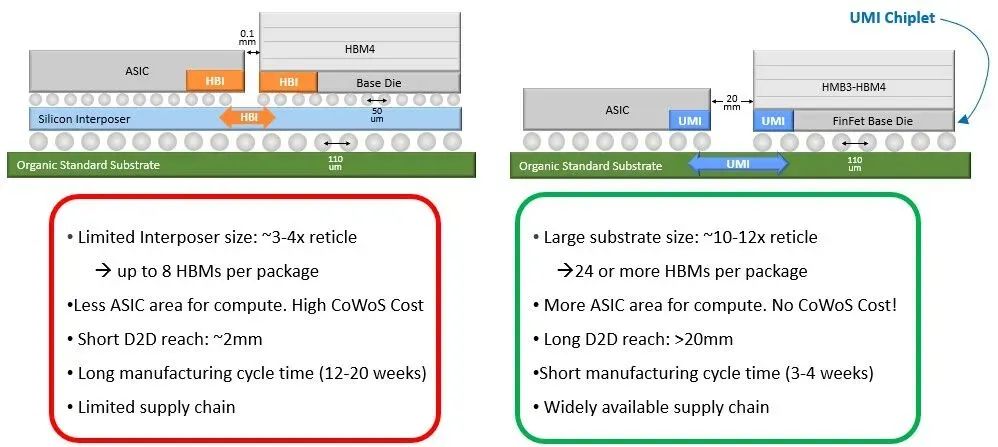
首先,可以构建更大的计算引擎。例如拥有24个或更多的HBM堆栈以及10到12个芯片组的计算引擎封装。由于采用了标准有机基板,该设备的制造时间只需1/4到1/5。
1989年是IBM的巅峰时期,1990年代初,它开始走下坡路,当时人们常说:同样的价格,你可以找到比IBM更好的产品。
当然,Nvidia并不是IBM或英特尔,至少现在还不是。无论如何,赚钱太轻松会对公司及其Roadmap产生可怕的影响。
以下是Eliyan认为HBM4在未来可能的发展方式:
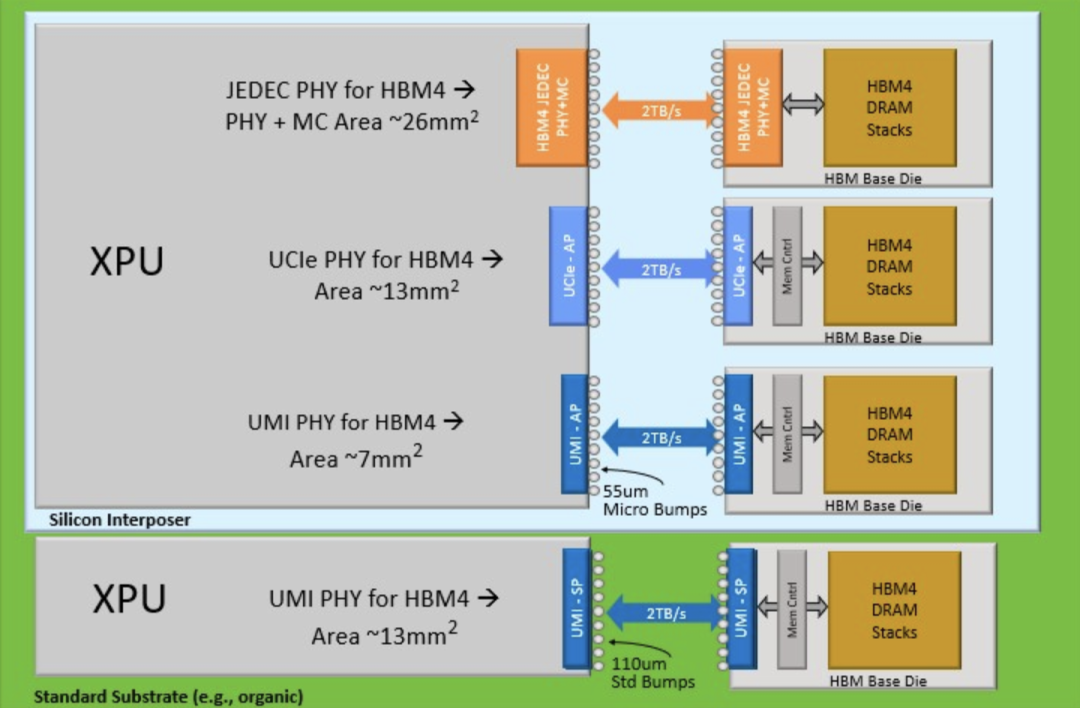
HBM4内存的JEDEC PHY尺寸较大,如果使用UCI-Express可以将其面积缩减一半,而采用NuLink UMI PHY可以在此基础上,将其面积再缩减一半,为你选择的XPU上的逻辑电路留出更多空间。或者,如果你想放弃中介层,制造一个尺寸更大的设备,并接受一个13平方毫米的UMI PHY,也可以制造一个成本更低的设备,并且每个HBM4堆栈仍然可以实现2TB/s的数据传输速率。
现在有趣的地方来了。
2022年11月,Eliyan提出其想法时,比较了一款带有中介层连接到其HBM内存的GPU,与一款去除中介层并将ASIC加倍(类似于Blackwell的做法)以及将24个HBM堆栈放置在这些ASIC芯片上的设备。如下图所示:
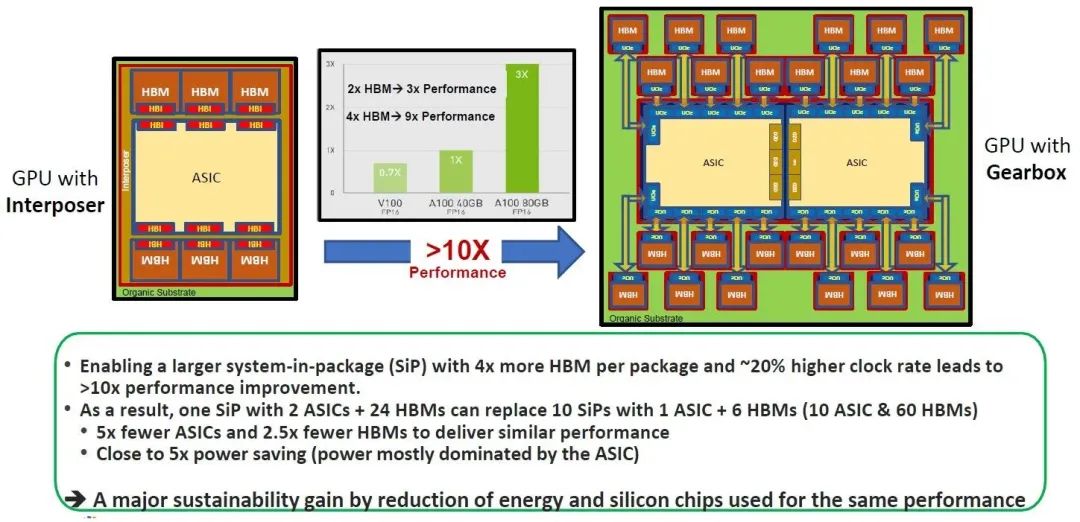
上图左边是Nvidia A100和H100 GPU及其HBM内存的架构图。中间是Nvidia的一张图表,显示随着更多的HBM内存容量和更大的HBM内存带宽提供给AI应用程序,性能是如何提升的。正如我们所知,相比具有相同GH100 GPU但只有80GB HBM3内存和3.35TB/sec带宽的H100,具有141GB HBM3E内存和4.8TB/sec带宽的H200的工作效率提高了1.6倍至1.9倍。
假设有一台如上图所示的设备,拥有576GB的HBM3E内存和19TB/sec的带宽。记住:主要的功耗并非来自内存,而是来自GPU,而我们迄今所见到的一些证据确实表明,Nvidia、AMD和Intel推出的GPU都受限于HBM内存容量和带宽,这一问题已经存在很长一段时间了,因为制造这种堆栈内存十分困难。这些公司制造的是GPU,而不是内存,它们通过尽可能少地提供HBM内存,同时保持强大的计算能力,从而最大化收入和利润。虽然他们总能展示出相比上一代的优势,但GPU计算的增长速度总是超过内存容量和带宽。Eliyan提出的这种设计可以重新平衡计算和内存,使这些设备更便宜。
也许对于GPU制造商来说,这种设计过于激进了,因此随着UMI的推出,Eliyan后退一步,并展示如何使用中介层和有机基板以及NuLink PHY来制造一个更大、更均衡的Blackwell GPU复杂系统。
下图左侧是关于如何创建一个具有单个NVLink端口的Blackwell-Blackwell超级芯片,该端口以1.8TB/sec的速度连接两个双芯片Blackwell GPU。
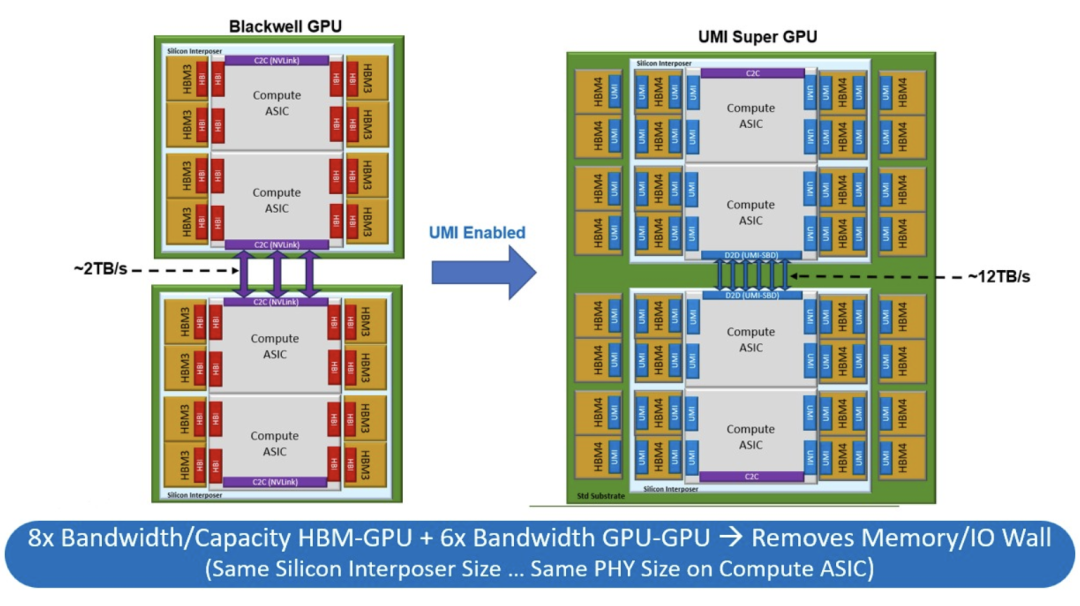
通过上图右侧所示的NuLink UMI方法,在两个Blackwell GPU之间提供了六个端口,传输带宽约为12 TB/sec,稍高于Nvidia用NVLink端口连接两个Blackwell GPU的B100和B200提供的10TB/sec。这意味着,Eliyan超级芯片设计中的带宽是Nvidia B200超级芯片设计的6倍。如果Nvidia继续使用其CoWoS制造工艺,Eliyan可以在中介层放置与Nvidia相同的八个HBM3E内存芯片组,然后可以在每个Blackwell设备上再放置另外八个HBM3E内存芯片组,总共可达32个HBM3E内存库,容量达到768GB,带宽达到25 TB/sec。
你再仔细想想。
但这还不是全部。这种UMI方法适用于任何XPU以及任何类型的内存,你可以在一个庞大的有机基板上进行类似的尝试,而无需中介层。
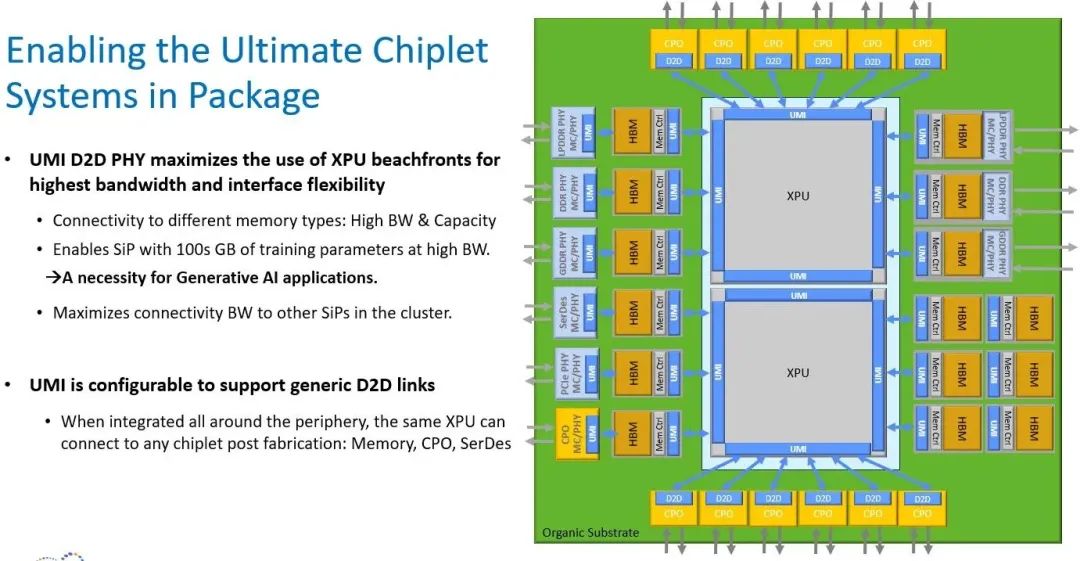
任何类型的内存、任何共封装的光电子器件、任何PCI-Express或其他控制器,都可以使用NuLink与任何XPU进行连接。在这一点上,插槽确实已经变成了主板。
而对于更大型的复杂系统,Eliyan可以构建NuLink交换机。
【语言大模型推理最高加速11倍】SiliconLLM是由硅基流动开发的高效、易用、可扩展的LLM推理加速引擎,旨在为用户提供开箱即用的推理加速能力,显著降低大模型部署成本,加速生成式AI产品落地。(技术合作、交流请添加微信:SiliconFlow01)
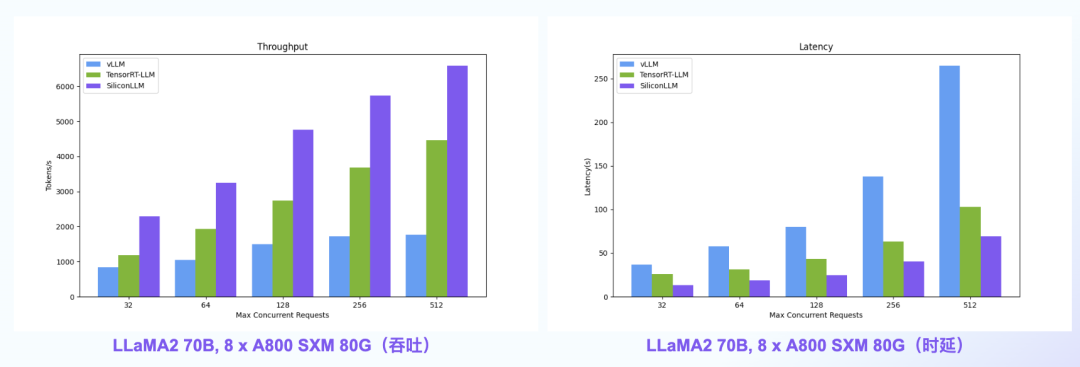
SiliconLLM的吞吐最高提升近4倍,时延最高降低近4倍
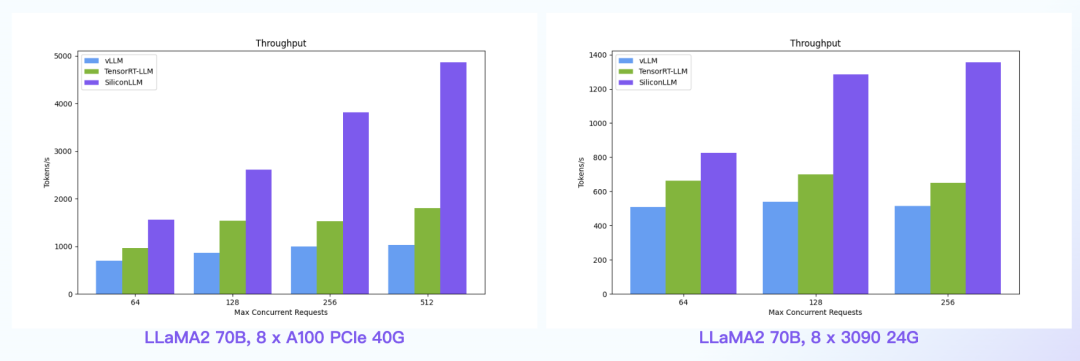
数据中心+PCIe:SiliconLLM的吞吐最高提升近5倍;消费卡场景:SiliconLLM的吞吐最高提升近3倍
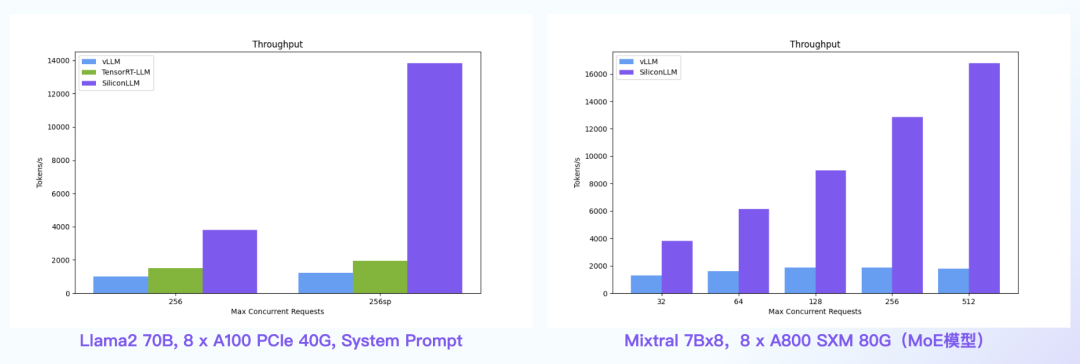
System Prompt场景:SiliconLLM的吞吐最高提升11倍;MoE模型:推理 SiliconLLM的吞吐最高提升近10倍
其他人都在看


