
- 1windows启动Redis报错: Could not create server TCP listening socket *:6379: listen: 提供了一个无效的参数
- 2鸿蒙剥离 AOSP 不兼容 Android 热门问题汇总,不吹不黑不吵_鸿蒙4 官网 android兼容
- 35分钟搭建开源运维监控工具Uptime Kuma并实现无公网IP远程访问_uptime安装
- 4如何在Linux设置JumpServer实现无公网ip远程访问管理界面
- 5单元测试系列 | 如何更好地测试依赖外部接口的方法_单元测试依赖
- 6Day30 78子集 90子集II 491非递减子序列
- 7算法通关村第九关|白银|二分查找与搜索树高频问题【持续更新】
- 8计算机网络 应用层
- 9【算法优选】 动态规划之路径问题——贰
- 10【A情感文本分类实战】2023 Pytorch+Bert、Roberta+TextCNN、BiLstm、Lstm等实现IMDB情感文本分类完整项目(项目已开源)_roberta文本分类
selenium实现原理_selenium原理图
赞
踩
Selenium 1.0 的工作原理
Selenium 1.0,又称Selenium RC ,RC是Remote Control的缩写。Selenium RC利用的原理:JavaScript代码可以方便的获取页面上的任意元素并执行各种操作。
但是因为“同源政策(Same-origin policy)”(只有来自相同域名、端口和协议的javaScript代码才能被浏览器执行),所以,要想在测试用例运行中的浏览器中,注入javascript代码,从而实现自动化web操作,Selenium RC必须“欺骗”被测站点,让它误以为被注入的代码是同源的。
那如何实现“欺骗”呢?这就是需要引入 Selenium RC Server 的原因了。其中的 Http Proxy 模块就是来「欺骗」浏览器的。除了 Selenium RC Server,Selenium RC 方案的另一部分就是 Client Libraries。他们的具体关系如下图1所示:
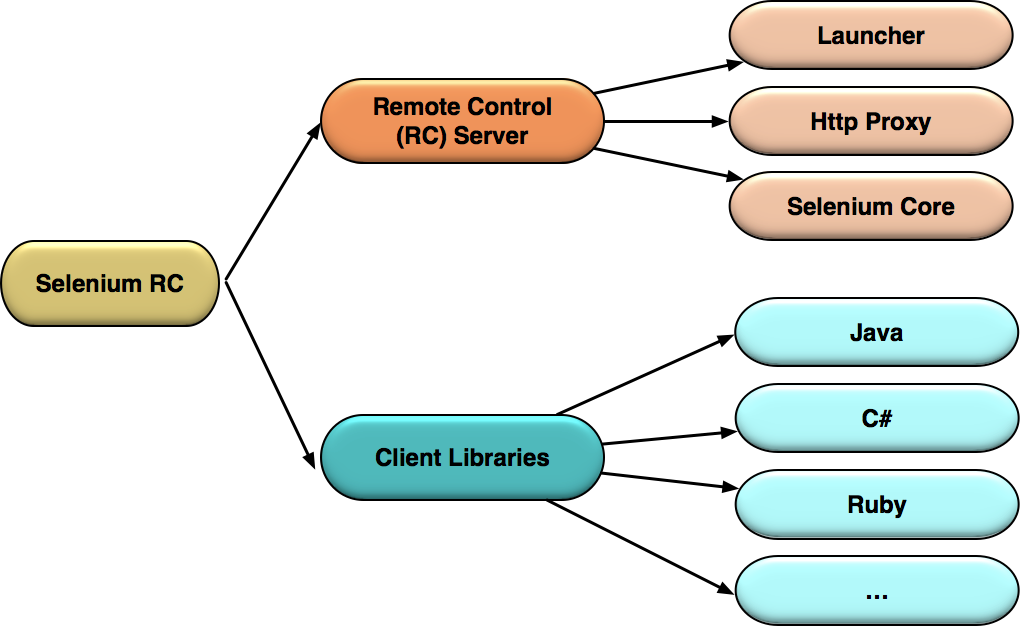
图1 Selenium RC 的基本模块
Selenium RC Server,主要包括Selenium Core,Http Proxy 和Launcher 三部分:
-
Selenium Core,是被注入到浏览器页面中的JavaScript 函数集合,用来实现界面元素的识别和操作;
-
Http Proxy,作为代理服务器修改JavaScrip的源,以达到“欺骗”被测站点的目的;
- Launcher,用来在启动测试浏览器时完成,Selenium Core 的注入和浏览器代理的设置。
Client Libraries,是测试用例代码向Selenium RC Server发送 Http 请求的接口,支持多种语言,包括 Java、C# 和 Ruby 等。
Selenium执行流程图,如图2:
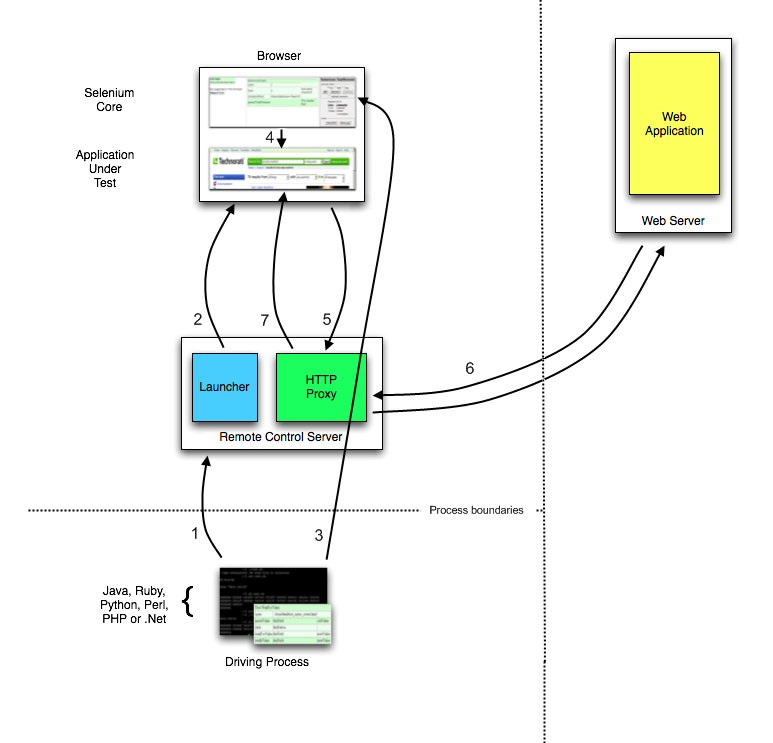
图2 Selenium RC 的执行流程
-
测试用例通过基于不同语言的 Client Libraries向 Selenium RC Server 发送Http请求,要求与其建立连接。
-
连接建立后,Selenium RC Server 的Launcher 就会启动浏览器或者重用之前已经打开的浏览器,把 Selenium Core(JavaScript 函数的集合)加载到浏览器页面当中,并同时把浏览器的代理设置为Http Proxy。
-
测试用例通过 Client Libraries,向 Selenium RC Server 发送 Http请求,Selenium RC Server 解析请求,然后通过 Http Proxy 发送 JavaScript命令通知 Selenium Core 执行浏览器上控件的具体操作。
- Selenium Core 接收到指令后,执行操作。
-
如果浏览器收到新的页面请求信息,则会发送 Http 请求来请求新的 Web 页面。由于 Launcher 在启动浏览器时把 Http Proxy 设置成为了浏览器的代理,所以 Selenium RC Server 会接收到所有由它启动的浏览器发送的请求。
-
Selenium RC Server 接收到浏览器发送的 Http 请求后,重组 Http 请求以规避“同源策略”,然后获取对应的 Web 页面。
-
Http Proxy 把接收的 Web 页面返回给浏览器,浏览器对接收的页面进行渲染。
Selenium 2.0 的工作原理
Selenium 2.0,又称 Selenium WebDriver,其原理是:使用浏览器原生的 WebDriver 实现页面操作。实现方式完全不同于 Selenium 1.0。Selenium WebDriver 是典型的 Server-Client 模式,Server 端就是 Remote Server。以下是 Selenium 2.0 工作原理:
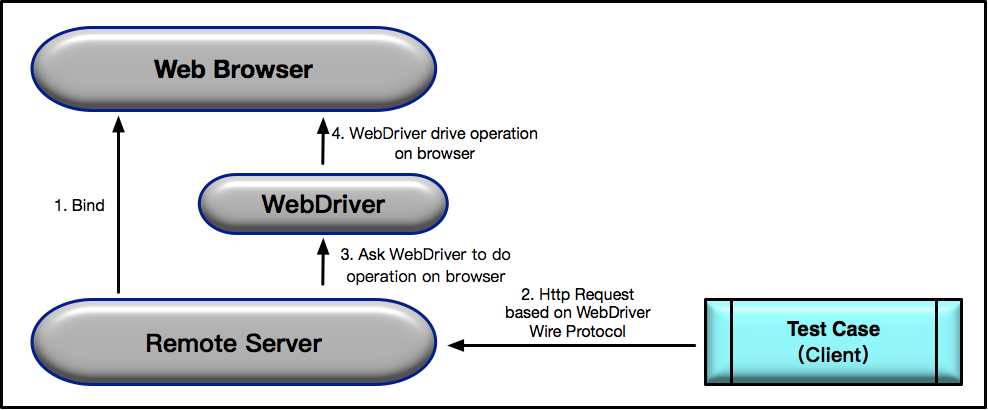
图3 Selenium WebDriver 的执行流程
- 当使用 Selenium 2.0 启动浏览器时,后台会同时启动基于 WebDriver Wire 协议的 Web Service 作为 Selenium 的 Remote Server,并与浏览器绑定。之后,Remote Server 就开始监听 Client 端的操作请求;
- 执行测试时,测试用例会作为 Client 端,将需要执行的页面操作请求以 Http Request 的方式发送给 Remote Server 。该 Http Request 的 body,是以 WebDriver Wire 协议规定的 JSON 格式来描述需要浏览器执行的具体操作;
- Remote Server 接收到请求后,会对请求进行解析,并将解析结果发给 WebDriver,由WebDriver 实际执行浏览器的操作;
- WebDriver 可以看做是直接操作浏览器的原生组件(Native Component),所以搭建测试环境时,通常都需要先下载浏览器对应的 WebDriver。


