
- 1基于Anaconda配置Python开发环境详解(1)安装Anaconda并做基本配置_anaconda配置python环境
- 2docker环境下安装Hbase+Phoenix_docker安装phoenix
- 3WinFR界面版(微软官方数据恢复软件)使用教程
- 4用app inventor编写童年经典游戏-传感版《黄金矿工》记录_appinventor游戏
- 5一文辨析清楚LORA、Prompt Tuning、P-Tuning、Adapter 、Prefix等大模型微调方法_ptuning和lora对比
- 6开源C# WPF控件库:MahApps.Metro介绍
- 7Mac系统下使用远程桌面连接Windows系统_mac远程连接windows桌面
- 8MongoDB安装和配置_mongodb下载安装配置教程
- 9MySQL——Linux安装包
- 10git rm 与 git rm --cached 的区别
基于 pytorch 的手写 transformer + tokenizer_手写transformer
赞
踩
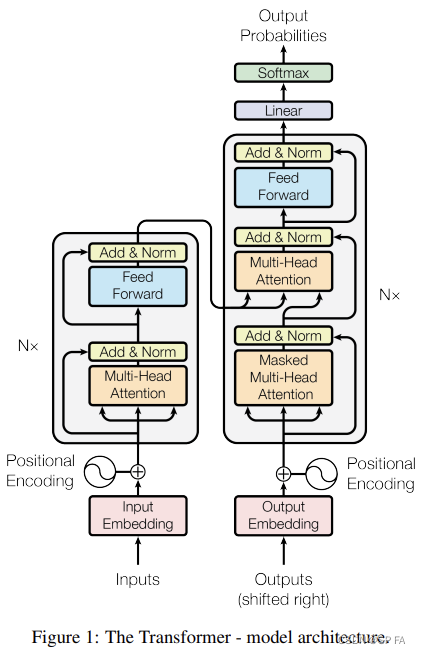
先放出 transformer 的整体结构图,以便复习,接下来就一个模块一个模块的实现它。
1. Embedding
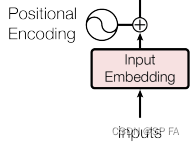
Embedding 部分主要由两部分组成,即 Input Embedding 和 Positional Encoding,位置编码记录了每一个词出现的位置。通过加入位置编码可以提高模型的准确率,因为同一个词出现在不同位置可能代表了不同意思,这直接影响了最终的结果,所以要考虑位置因素。
位置编码公式:
P
E
(
p
o
s
,
2
i
)
=
sin
(
p
o
s
1000
0
2
i
d
)
P
E
(
p
o
s
,
2
i
+
1
)
=
cos
(
p
o
s
1000
0
2
i
d
)
PE(pos, 2i)=\sin(\frac{pos}{10000^\frac{2i}{d}})\\PE(pos,2i+1)=\cos(\frac{pos}{10000^\frac{2i}{d}})
PE(pos,2i)=sin(10000d2ipos)PE(pos,2i+1)=cos(10000d2ipos)
def get_angles(pos, i, d):
return pos / np.power(10000, (2 * (i//2)) / np.float32(d))
def positional_encoding(position, d):
theta = get_angles(np.arange(position)[:, np.newaxis], np.arange(d)[np.newaxis, :], d)
theta[:, 0::2] = np.sin(theta[:, 0::2])
theta[:, 1::2] = np.cos(theta[:, 1::2])
return theta[np.newaxis, ...] # shape: [1, position, d]
class Embedding(nn.Module):
def __init__(self, cfg):
super(Embedding, self).__init__()
self.dim = cfg.hidden_dim
self.device = cfg.device
self.word_em = nn.Embedding(num_embeddings=cfg.vocab_size, embedding_dim=self.dim).to(self.device)
self.position_em = positional_encoding(cfg.max_len, self.dim)
def forward(self, input_ids):
seq_length = input_ids.size(1)
we = self.word_em(input_ids)
we *= torch.sqrt(self.dim).to(self.device)
pe = self.position_em[:, :seq_length, :]
return we + pe
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
其中 cfg 文件用来存一些超参数,device 是选择使用 CPU / GPU 的设备编号。
2. Masking
为一些标记添加遮罩,这里主要用于一下两种情况:
- 对填充标记
[PAD]进行遮罩,确保模型不会将填充作为输入。 - 前瞻遮挡(look-ahead mask)用于遮挡一个序列中的后续部分,比如说要预测第三个词,那么前面的
[CLS]标记以及第一第二个词被保留用于预测,而其它位置的词则应该被遮住,不能输入模型。
def create_padding_mask(seq):
seq.eq_(0)
# 添加额外的维度来将填充加到注意力对数(logits)。
return seq[:, np.newaxis, np.newaxis, :] # shape: [batch_size, 1, 1, seq_len]
def create_look_ahead_mask(seq_len):
return torch.triu(torch.ones(seq_len, seq_len), 1) # shape: [seq_len, seq_len]
def create_masks(src_ids, trg_ids):
en_padding_mask = create_padding_mask(src_ids)
de_padding_mask = create_padding_mask(src_ids)
look_ahead_mask = create_look_ahead_mask(trg_ids.shape[1])
de_trg_padding_mask = create_padding_mask(trg_ids)
combined_mask = torch.maximum(de_trg_padding_mask, look_ahead_mask)
return en_padding_mask, combined_mask, de_padding_mask
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
3. Attention
3.1 Scaled Dot-Product Attention (按比缩放的点积注意力)
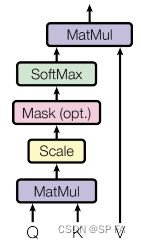
点积注意力机制的公式为:
A
t
t
e
n
t
i
o
n
(
Q
,
K
,
V
)
=
s
o
f
t
m
a
x
(
Q
K
T
d
)
V
Attention(Q,K,V)=softmax(\frac{QK^T}{\sqrt{d}})V
Attention(Q,K,V)=softmax(d
QKT)V
点积注意力被缩小了深度的平方根倍。这样做是为了防止 Softmax 函数值集中在 0 和 1 的附近,这样可能会导致梯度消失。
假设 Q 和 K 的每个元素是独立同分布的,均值为0,方差为1的正态分布。它们的矩阵乘积将有均值为0,方差为 d。此时把所有元素除以 d \sqrt d d 就可以把方差缩放回 1。用公式表示即为:
Q
i
K
j
T
=
∑
d
=
0
D
q
d
k
d
q
d
,
k
d
∼
N
(
0
,
1
)
Q_iK_j^T=\sum^D_{d=0}q_dk_d~~~~q_d,k_d\sim\mathcal{N}(0,1)
QiKjT=d=0∑Dqdkd qd,kd∼N(0,1)
V
a
r
(
Q
i
K
i
T
)
=
∑
d
=
0
D
V
a
r
(
q
d
k
d
)
=
∑
d
=
0
D
E
(
q
d
2
k
d
2
)
−
E
(
q
d
k
d
)
2
=
∑
d
=
0
D
E
(
q
d
2
)
E
(
k
d
2
)
−
E
(
q
d
)
2
E
(
k
d
)
2
=
∑
d
=
0
D
(
V
a
r
(
q
d
)
+
E
(
q
d
)
2
)
(
V
a
r
(
k
d
)
+
E
(
k
d
)
2
)
−
E
(
q
d
)
2
E
(
k
d
)
2
=
∑
d
=
0
D
(
1
+
0
)
(
1
+
0
)
−
0
=
D
Var(QiKTi)=D∑d=0Var(qdkd)=D∑d=0E(q2dk2d)−E(qdkd)2=D∑d=0E(q2d)E(k2d)−E(qd)2E(kd)2=D∑d=0(Var(qd)+E(qd)2)(Var(kd)+E(kd)2)−E(qd)2E(kd)2=D∑d=0(1+0)(1+0)−0=D
在 Softmax 之前要记得加入遮罩,遮罩乘以 -1e9 来添加一个无穷小的数,使得 Softmax 之后的输出在被遮住的部分接近于 0,这样就可以忽略该位置的信息。
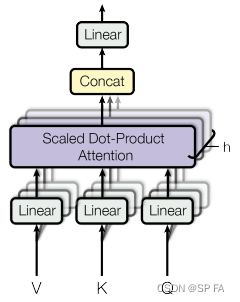
3.2 Multi-Head Attention
class MultiHeadAttention(nn.Module):
def __init__(self, cfg):
super(MultiHeadAttention, self).__init__()
self.n_head = cfg.n_head
self.dim = cfg.hidden_dim
self.device = cfg.device
self.wq = nn.Linear(self.dim, self.dim).to(self.device)
self.wk = nn.Linear(self.dim, self.dim).to(self.device)
self.wv = nn.Linear(self.dim, self.dim).to(self.device)
self.softmax = nn.Softmax(dim=3)
self.f = nn.Linear(self.dim, self.dim).to(cfg.device)
def split(self, tensor):
a, b, c = tensor.size()
d = c // self.n_head
return tensor.view(a, b, self.n_head, d).permute(0, 2, 1, 3)
def concat(self, tensor):
a, b, c, d = tensor.size()
return tensor.view(a, c, b * d)
def attention(self, q, k, v, mask):
_, _, _, d = k.size()
kt = torch.transpose(k, 2, 3)
s = (q @ kt) / math.sqrt(d) # Scale 操作,防止之后 Softmax 时梯度消失
if mask is not None:
s += (mask * -1e9);
s = self.softmax(s)
v = s @ v
return v
def forward(self, v, k, q, mask):
k, q, v = self.wk(v), self.wq(k), self.wv(q)
k, q, v = self.split(k), self.split(q), self.split(v)
output = self.attention(k, q, v, mask)
output = self.concat(output)
return self.f(output)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
4. Add & Norm
残差连接层有助于避免深度网络中的梯度消失问题。
class AddNorm(nn.Module):
def __init__(self, cfg):
super(AddNorm, self).__init__()
self.dim = cfg.hidden_dim
self.norm = nn.LayerNorm(self.dim).to(cfg.device)
self.dropout = nn.Dropout(cfg.drop_out) # 正则化,参数为正则化概率
def forward(self, input, x):
input = self.dropout(input)
return self.norm(input + x)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
5. Point wise feed forward network (点式前馈网络)
点式前馈网络由两层全联接层组成,两层之间有一个 ReLU 激活函数。
class FeedForward(nn.Module):
def __init__(self, cfg):
super(FeedForward, self).__init__()
self.dim = cfg.hidden_dim
self.f1 = nn.Linear(self.dim, self.dim).to(cfg.device)
self.relu = nn.ReLU().to(cfg.device)
self.f2 = nn.Linear(self.dim, self.dim).to(cfg.device)
def forward(self, x):
x = self.f1(x)
x = self.relu(x)
return self.f2(x)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
6. Encoder and Decoder
6.1 Encoder Layer
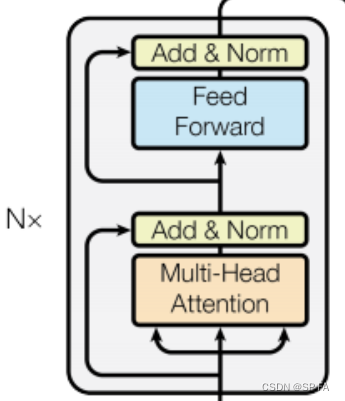
class EncoderLayer(nn.Module):
def __init__(self, cfg):
super(Encoder, self).__init__()
self.attention = MultiHeadAttention(cfg)
self.fforward = FeedForward(cfg)
self.addnorm1 = AddNorm(cfg)
self.addnorm2 = AddNorm(cfg)
def forward(self, x, mask):
attn = self.attention(x, x, x, mask)
attn = self.addnorm1(attn, x)
ffw = self.fforward(attn)
ffw = self.addnorm2(ffw, attn)
return ffw
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
6.2 Encoder
编码器包括
- Embedding
- N 个编码器层
class Encoder(nn.Module):
def __init__(self, cfg):
super(Encoder, self).__init__()
self.num_layers = cfg.encoder_layer_count
self.embedding = Embedding(cfg)
self.layers = [EncoderLayer(cfg) for _ in range(self.num_layers)]
self.dropout = nn.Dropout(cfg.drop_out)
def forward(self, x, mask):
x = self.embedding(x)
x = self.dropout(x)
for i in range(self.num_layers):
x = self.layers[i](x, mask)
return x
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
6.3 Decoder Layer
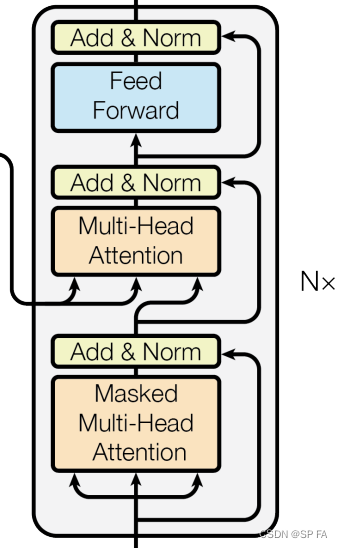
class DecoderLayer(nn.Module):
def __init__(self, cfg):
super(Decoder, self).__init__()
self.attention1 = MultiHeadAttention(cfg)
self.attention2 = MultiHeadAttention(cfg)
self.fforward = FeedForward(cfg)
self.addnorm1 = AddNorm(cfg)
self.addnorm2 = AddNorm(cfg)
self.addnorm3 = AddNorm(cfg)
def forward(self, x, encoder_out, look_ahead_mask, padding_mask):
attn1 = self.attention1(x, x, x, look_ahead_mask)
ffw1 = self.addnorm1(attn1, x)
attn2 = self.attention2(encoder_out, encoder_out, ffw1, padding_mask)
ffw2 = self.addnorm2(attn2, ffw1)
output = self.fforward(ffw2)
output = self.addnorm3(output, ffw2)
return output
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
6.4 Decoder
解码器包括
- Embedding
- N 个解码器层
class Decoder(nn.Module):
def __init__(self, cfg):
super(Decoder, self).__init__()
self.dim = cfg.dim
self.num_layers = cfg.decoder_layer_count
self.embedding = Embedding(cfg)
self.layers = [Decoder(cfg) for _ in range(self.num_layers)]
self.dropout = nn.Dropout(cfg.drop_out)
def forward(self, x, encode_output, look_ahead_mask, padding_mask):
x = self.embedding(x)
x = self.dropout(x)
for i in range(self.num_layers):
x = self.layers[i](x, encode_output, look_ahead_mask, padding_mask)
return x
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
7. Transformer
class Transformer(nn.Module):
def __init__(self, cfg):
super(Transformer, self).__init__()
self.encoder = Encoder(cfg)
self.decoder = Decoder(cfg)
self.linear = nn.Linear(cfg.hidden_dim, cfg.vocab_size).to(cfg.device)
def forward(self, src_ids, trg_ids, en_padding_mask, look_ahead_mask, de_padding_mask):
en_output = self.encoder(src_ids, en_padding_mask)
de_output = self.decoder(trg_ids, en_output, look_ahead_mask, de_padding_mask)
return self.linear(de_output)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
8. 优化器 与 损失函数
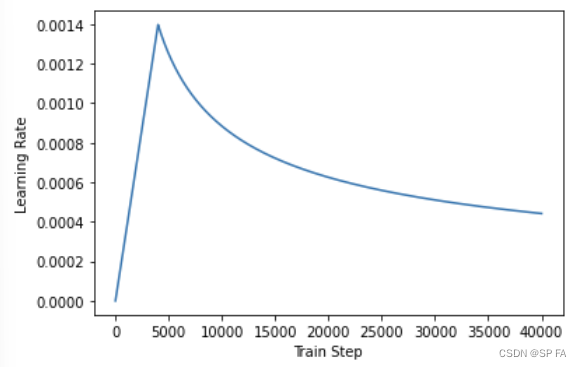
根据论文中的公式,将 Adam 优化器与自定义的学习速率调度程序(scheduler)配合使用。
l r a t e = d − 1 2 ∗ min ( n u m − 1 2 , n u m ∗ w a r m u p _ s t e p s − 3 2 ) lrate=d^{-\frac12}*\min(num^{-\frac12},num*warmup\_steps^{-\frac32}) lrate=d−21∗min(num−21,num∗warmup_steps−23)
warmup_steps 为 4000 时的学习率变化如图:
由于目标序列是 padding 过的,因此在计算损失函数时,应该使用 mask 遮去 [PAD] 的部分。
def loss_function(y, pred):
mask = torch.logical_not(torch.eq(y, 0))
loss = criterion(real, pred) # 损失函数
mask = mask.float()
loss *= mask
return torch.mean(loss)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
9. Tokenizer
顺便学一下训练一个自己的 tokenizer
tokenizer = Tokenizer(models.WordPiece(unk_token="[UNK]")) # 用 [UNK] 替换未知字符
tokenizer.normalizer = normalizers.Sequence( # 按一定规则标准化:NFD:统一 Unicode 编码
[normalizers.NFD(), normalizers.Lowercase()]
)
tokenizer.pre_tokenizer = pre_tokenizers.WhitespaceSplit() # 使用 空格 来分割
special_tokens = ["[UNK]", "[PAD]", "[CLS]", "[SEP]", "[MASK]"]
trainer = trainers.WordPieceTrainer(vocab_size=10000, special_tokens=special_tokens) # 分成 10000 类
tokenizer.train(['text.txt'], trainer=trainer) # 用于训练的文本
tokenizer.save('my_tokenizer.json')
# 使用
tokenizer = Tokenizer.from_file("my_tokenizer.json") # 调用自己的 tokenizer
s = "给他们来点小小的蜀国震撼"
tokens = tokenizer.encode(s)
print(tokens.ids, tokens.tokens)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
同步更新于:SP-FA 的博客

