- 1【Hadoop-HDFS】HDFS的读写流程 & SNN的数据写入流程_请简述一下hdfs的读写流程
- 2OpenWrt One/AP-24.XY 开源路由器发布,OpenWRT与Banana Pi社区合作
- 3口碑炸裂的10本书,免费包邮送20本!
- 4ENSP-----防火墙NAT策略_no-nat
- 5图像函数_图像力函数
- 6 #inc" href="/w/知新_RL/article/detail/449886" target="_blank">简单HashTable的C语言实现_"#include \"hashtable.h\" #include
#inc - 7AttributeError: module ‘numpy‘ has no attribute ‘float‘.`np.float` was a deprecated alias_attributeerror: module 'numpy' has no attribute 'f
- 8Hmac算法——秘钥的引入_hmac密钥
- 9论这两年不断突破心理底线的互联网薪水by OfferCome&&从猎头角度推测,搜狗的买卖对于互联网格局和薪水的影响&&烧钱薪水反思_offercome猎头公司
- 10爬虫实战系列(十一):Win10下手机爬虫工具appium的安装与测试_安卓爬虫实战案例
机器学习系统的设计
赞
踩
1.混淆矩阵
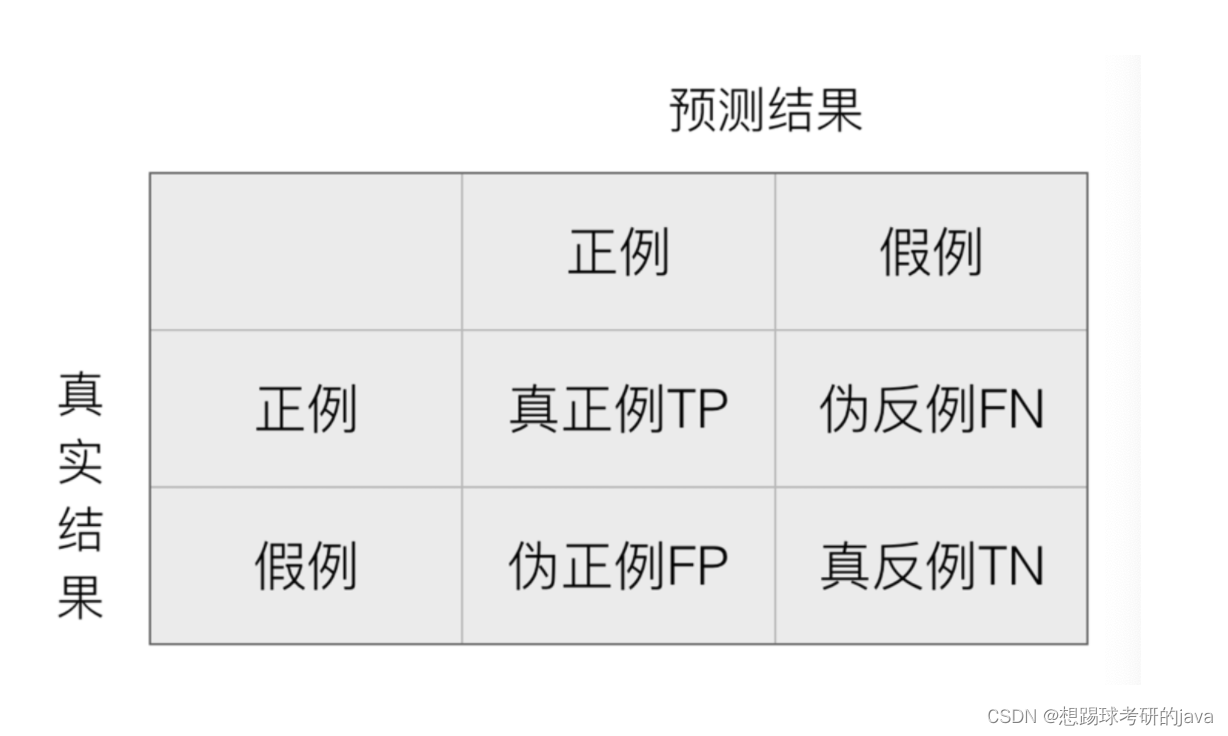
混淆矩阵作用就是看一看在测试集样本集中:
- 真实值是 正例 的样本中,被分类为 正例 的样本数量有多少,这部分样本叫做真正例(TP,True Positive),预测为真,实际为真
- 真实值是 正例 的样本中,被分类为 假例 的样本数量有多少,这部分样本叫做伪反例(FN,False Negative),预测为假,实际为真
- 真实值是 假例 的样本中,被分类为 正例 的样本数量有多少,这部分样本叫做伪正例(FP,False Positive),预测为真,实际为家
- 真实值是 假例 的样本中,被分类为 假例 的样本数量有多少,这部分样本叫做真反例(TN,True Negative),预测为假,实际为假
True Positive :表示样本真实的类别 Positive :表示样本被预测为的类别
例子:
样本集中有 6 个恶性肿瘤样本,4 个良性肿瘤样本,我们假设恶性肿瘤为正例,则:
模型 A: 预测对了 3 个恶性肿瘤样本,4 个良性肿瘤样本
- 真正例 TP 为:3
- 伪反例 FN 为:3
- 伪正例 FP 为:0
- 真反例 TN:4
模型 B: 预测对了 6 个恶性肿瘤样本,1个良性肿瘤样本
- 真正例 TP 为:6
- 伪反例 FN 为:0
- 伪正例 FP 为:3
- 真反例 TN:1
我们会发现:TP+FN+FP+TN = 总样本数量
2. Precision(精准率)
精准率也叫做查准率,指的是对正例样本的预测准确率。比如:我们把恶性肿瘤当做正例样本,则我们就需要知道模型对恶性肿瘤的预测准确率。
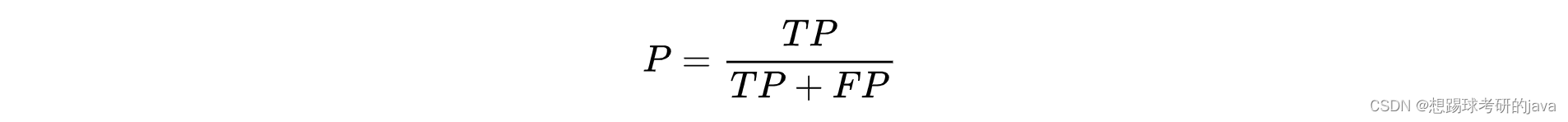
例子:
样本集中有 6 个恶性肿瘤样本,4 个良性肿瘤样本,我们假设恶性肿瘤为正例,则:
模型 A: 预测对了 3 个恶性肿瘤样本,4 个良性肿瘤样本
- 真正例 TP 为:3
- 伪反例 FN 为:3
- 假正例 FP 为:0
- 真反例 TN:4
- 精准率:3/(3+0) = 100%
模型 B: 预测对了 6 个恶性肿瘤样本,1个良性肿瘤样本
- 真正例 TP 为:6
- 伪反例 FN 为:0
- 假正例 FP 为:3
- 真反例 TN:1
- 精准率:6/(6+3) = 67%
3. Recall(召回率)¶
召回率也叫做查全率,指的是预测为真正例样本占所有真实正例样本的比重。例如:我们把恶性肿瘤当做正例样本,则我们想知道模型是否能把所有的恶性肿瘤患者都预测出来。

例子:
样本集中有 6 个恶性肿瘤样本,4 个良性肿瘤样本,我们假设恶性肿瘤为正例,则:
模型 A: 预测对了 3 个恶性肿瘤样本,4 个良性肿瘤样本
- 真正例 TP 为:3
- 伪反例 FN 为:3
- 假正例 FP 为:0
- 真反例 TN:4
- 精准率:3/(3+0) = 100%
- 召回率:3/(3+3)=50%
模型 B: 预测对了 6 个恶性肿瘤样本,1个良性肿瘤样本
- 真正例 TP 为:6
- 伪反例 FN 为:0
- 假正例 FP 为:3
- 真反例 TN:1
- 精准率:6/(6+3) = 67%
- 召回率:6/(6+0)= 100%
精准率和召回率总结:对于精准率和召回率我们发现,即使我们拥有非常偏斜的类,对于一个算法模型来说,拥有高查准率和召回率,我们可以说这是一个表现优良的算法。
4. F1-score
查准率(Precision)=TP/(TP+FP) 例,在所有我们预测有恶性肿瘤的病人中,实际上 有恶性肿瘤的病人的百分比,越高越好。
查全率(Recall)=TP/(TP+FN)例,在所有实际上有恶性肿瘤的病人中,成功预测有恶 性肿瘤的病人的百分比,越高越好。
如果我们希望只在非常确信的情况下预测为真(肿瘤为恶性),即我们希望更高的查准 率,我们可以使用比 0.5 更大的阀值,如 0.7,0.9。这样做我们会减少错误预测病人为恶性 肿瘤的情况,同时却会增加未能成功预测肿瘤为恶性的情况。
如果我们希望提高查全率,尽可能地让所有有可能是恶性肿瘤的病人都得到进一步地检查、诊断,我们可以使用比 0.5 更小的阀值,如 0.3。
我们希望有一个帮助我们选择这个阀值的方法。一种方法是计算 F1 值(F1 Score),其 计算公式为:
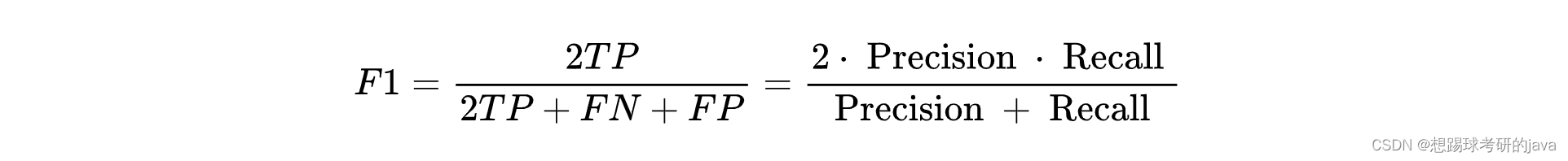
样本集中有 6 个恶性肿瘤样本,4 个良性肿瘤样本,我们假设恶性肿瘤为正例,则:
模型 A: 预测对了 3 个恶性肿瘤样本,4 个良性肿瘤样本
- 真正例 TP 为:3
- 伪反例 FN 为:3
- 假正例 FP 为:0
- 真反例 TN:4
- 精准率:3/(3+0) = 100%
- 召回率:3/(3+3)=50%
- F1-score:(2*3)/(2*3+3+0)=67%
模型 B: 预测对了 6 个恶性肿瘤样本,1个良性肿瘤样本
- 真正例 TP 为:6
- 伪反例 FN 为:0
- 假正例 FP 为:3
- 真反例 TN:1
- 精准率:6/(6+3) = 67%
- 召回率:6/(6+0)= 100%
- F1-score:(2*6)/(2*6+0+3)=80%
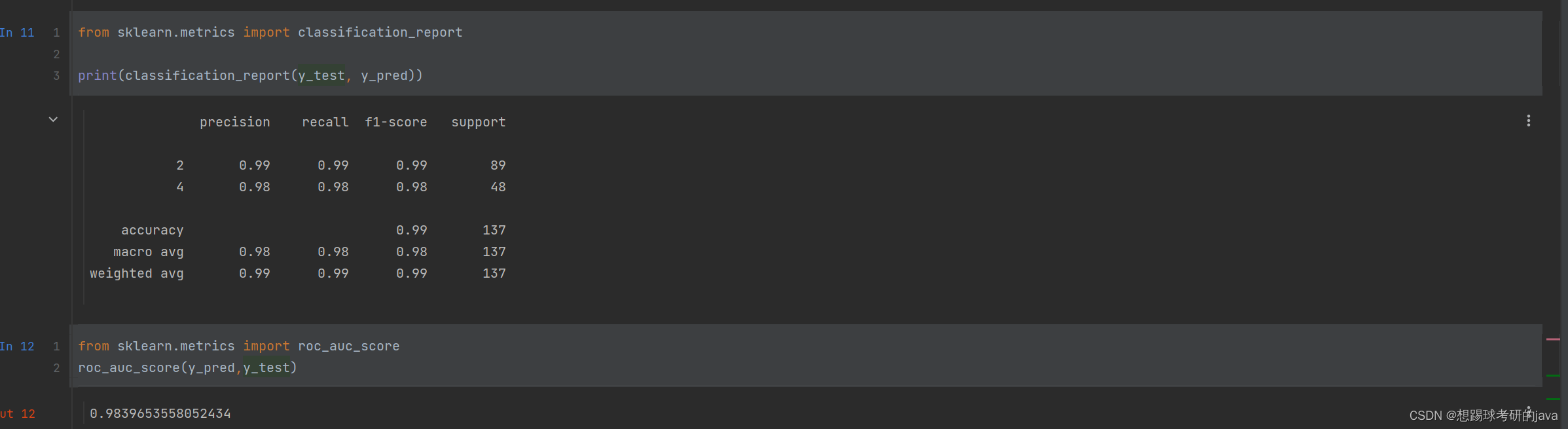
- F1-Score API
- from sklearn.metrics import classification_report
效果图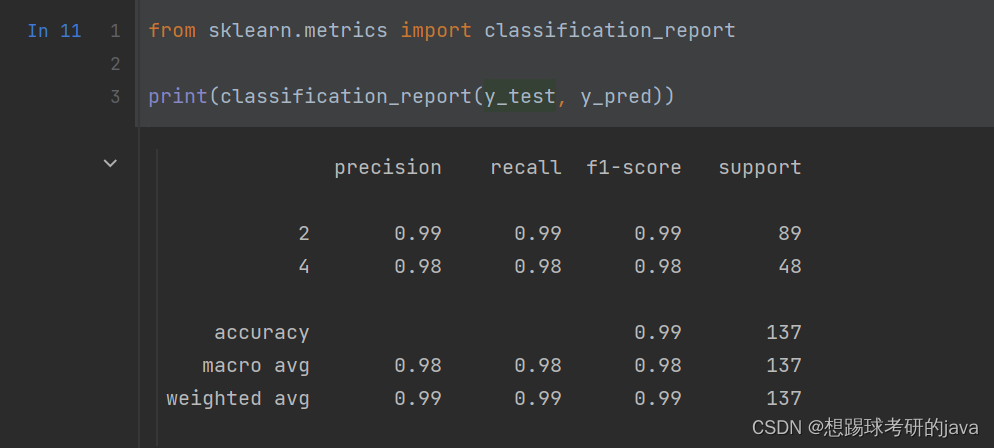
4.机器学习流程

4.1 案例(癌症分类案例截图)
4.1.1 数据描述
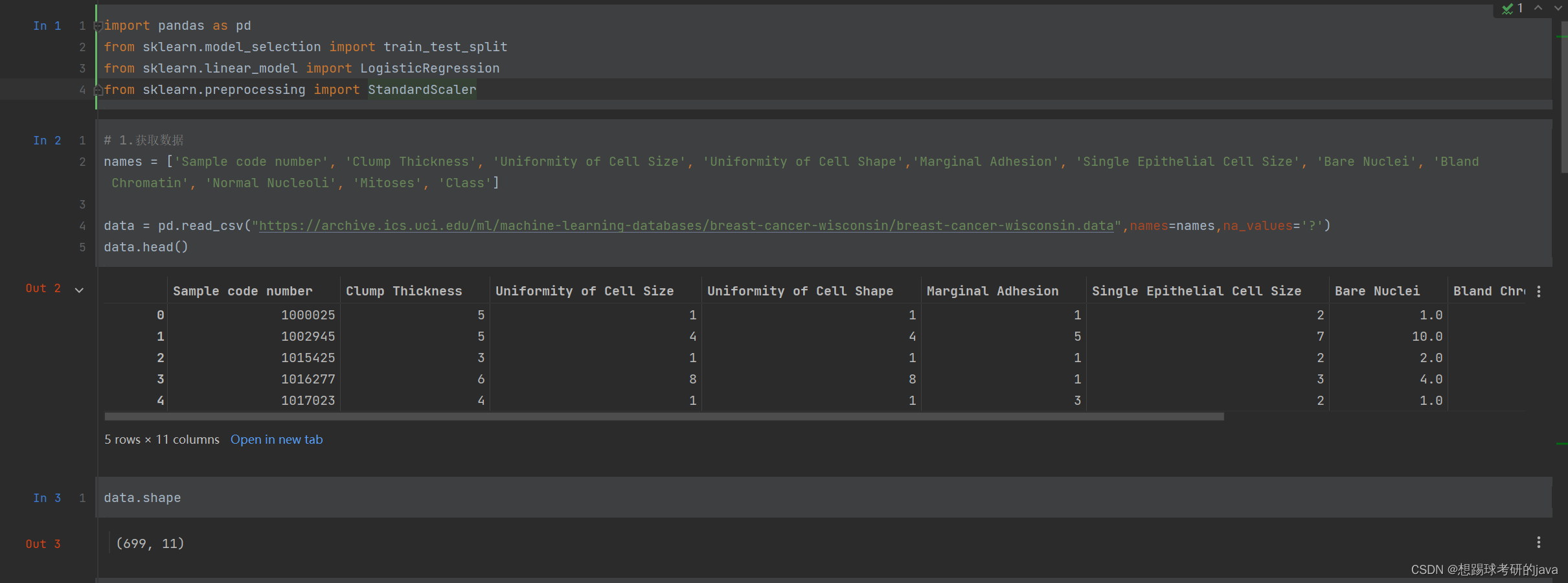
(1)699条样本,共11列数据,第一列用语检索的id,后9列分别是与肿瘤
相关的医学特征,最后一列表示肿瘤类型的数值。
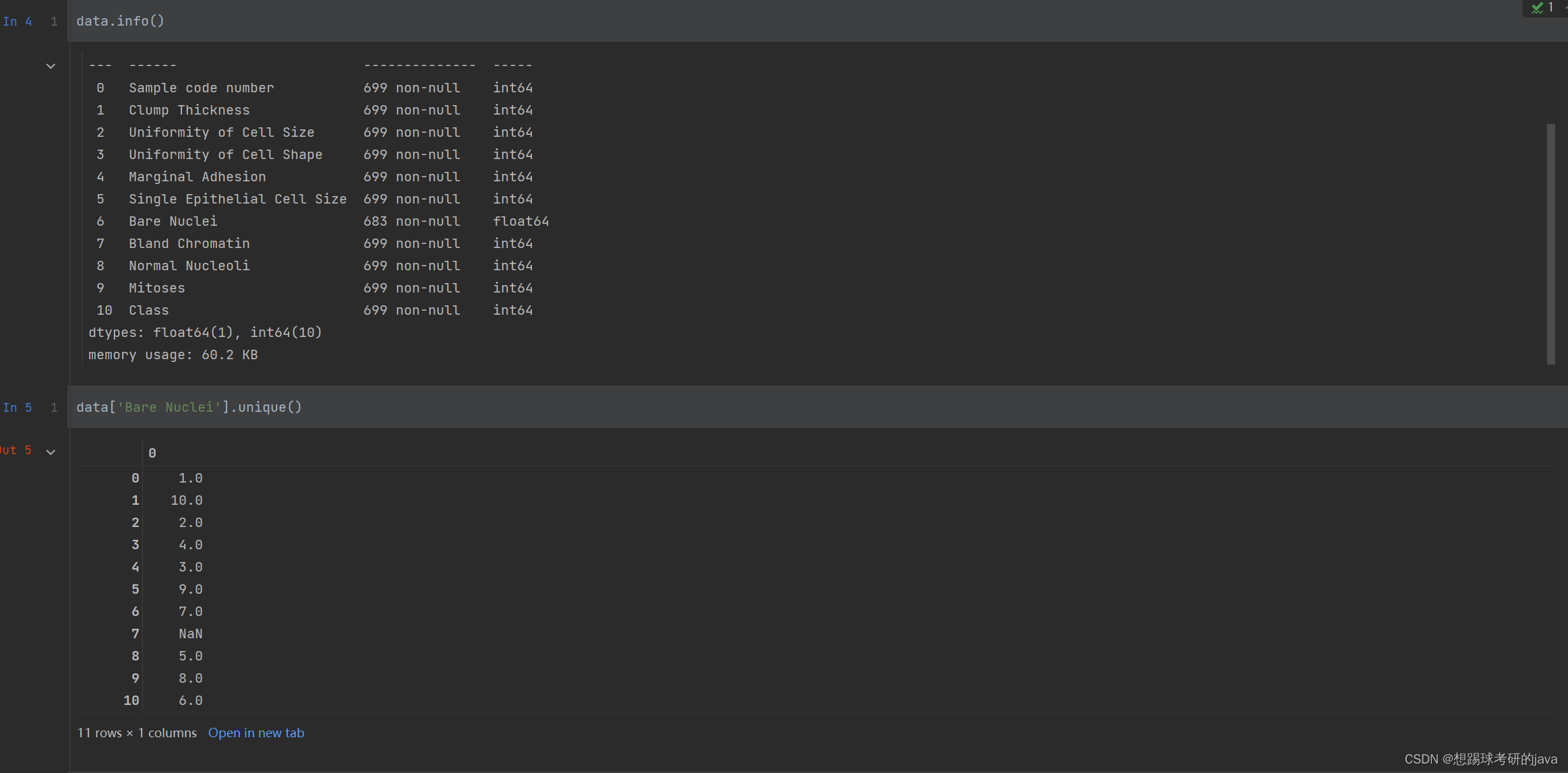
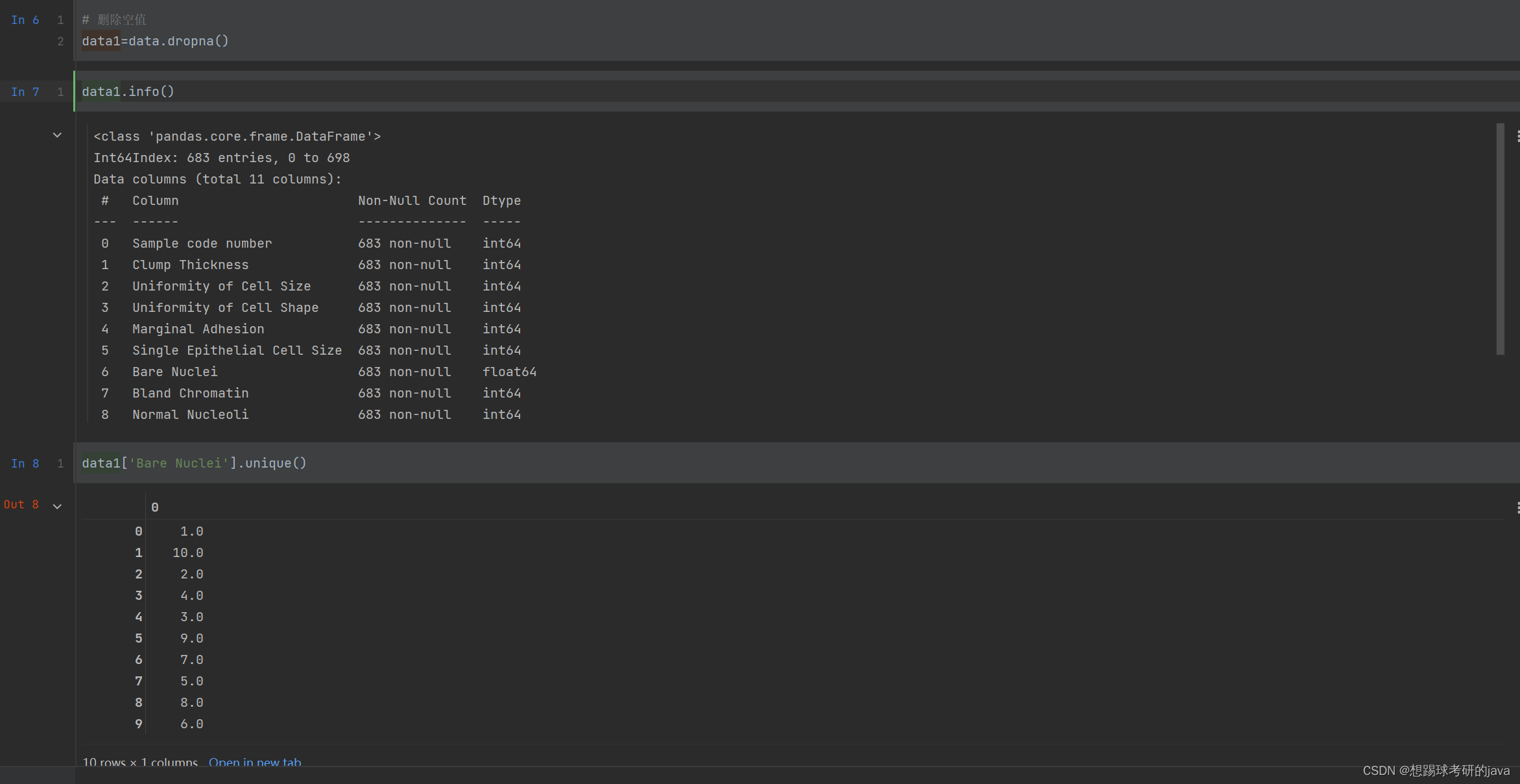
(2)包含16个缺失值,用”?”标出
4.1.2 训练流程
- 1.获取数据
- 2.基本数据处理
- 2.1 缺失值处理
- 2.2 确定特征值,目标值
- 2.3 分割数据
- 3.特征工程(标准化)
- 4.机器学习(逻辑回归)
- 5.模型评估