搭好了hadoop集群之后,就该使用它了
第一步:下载hadoop eclipse的插件,将它放到eclipse\plugins的目录下,然后重启eclipse,点击windows->show view->Other->MapReduceTool如下图:

双击Map/Reduce Locations,右键新建一个Map/Reduce Locations,编辑如下图:

设置好以后,新建一个map/reduce项目,要求hadoop的安装位置,直接定位到安装位置即可,然后再使用运行一个简单的统计字符串的脚本,
代码如下:
package mr.java; import java.io.*; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; //import org.apache.hadoop.yarn.conf.YarnConfiguration; public class WordCount1 { public static class WordCountMapper extends Mapper<Object,Text,Text,IntWritable> { private final static IntWritable one = new IntWritable(1); private Text word = new Text(); public void map(Object key,Text value,Context context) throws IOException, InterruptedException { String[] words = value.toString().split(" "); for (String str: words) { word.set(str); context.write(word,one); } } } public static class WordCountReducer extends Reducer<Text,IntWritable,Text,IntWritable> { public void reduce(Text key,Iterable<IntWritable> values,Context context) throws IOException, InterruptedException { int total=0; for (IntWritable val : values){ total++; } context.write(key, new IntWritable(total)); } } public static void main (String[] args) throws Exception{ Configuration conf = new Configuration(); //conf.set("fs.defaultFS", "hdfs://192.168.18.110:9000"); //conf.set("mapreduce.framework.name", "yarn"); //conf.set("yarn.resourcemanager.address", "192.168.18.110:8032"); //conf.set("yarn.resourcemanager.hostname", "192.168.18.110"); //conf.set("mapred.jar","C:/Users/Administrator/Desktop/mapred.jar"); //conf.set("mapred.remote.os", "Linux"); //conf.set("mapreduce.app-submission.cross-platform", "true"); System.setProperty("hadoop.home.dir", "E:/软件1/大数据/hadoop-2.6.4生态圈软件包/hadoop-2.6.4/hadoop-2.6.4"); //conf.set("mapred.jar","wc1.jar"); //Job job = new Job(conf, "word count"); Job job = Job.getInstance(conf); job.setJobName("word count"); job.setJarByClass(WordCount1.class); job.setMapperClass(WordCountMapper.class); job.setReducerClass(WordCountReducer.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); FileInputFormat.addInputPath(job, new Path(args[0])); FileOutputFormat.setOutputPath(job, new Path(args[1])); System.exit(job.waitForCompletion(true) ? 0 : 1); } }
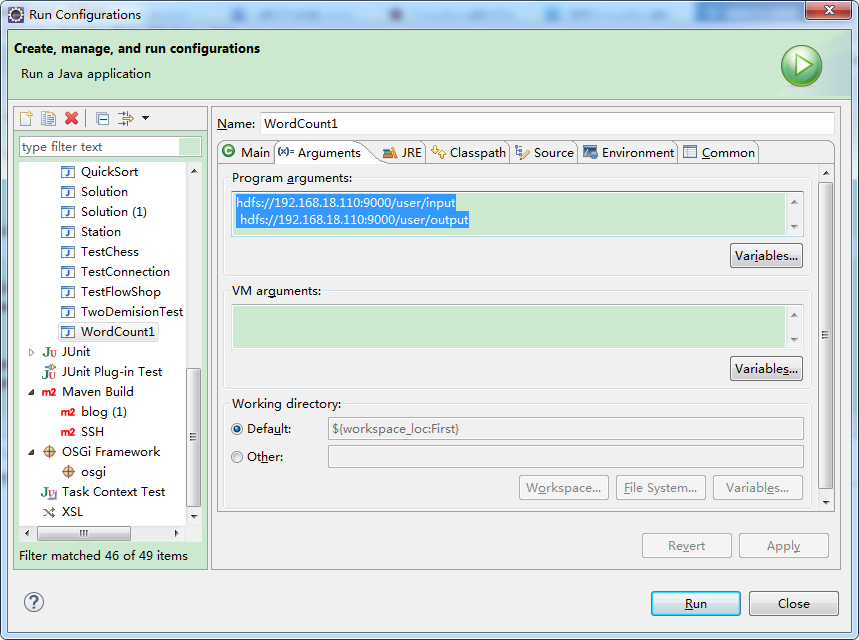
不过还需要上传文件,在root文件夹下新建一个user,在user文件夹下新建一个input文件夹,将写好的文件上传,在右键run as ->configurration添加如下操作:
你以为这样就完了,还要设置,在工程中新建两个包名:org.apache.hadoop.io.nativeio和org.apache.hadoop.mapred在第一个包里加上这个类:、
/** * Licensed to the Apache Software Foundation (ASF) under one * or more contributor license agreements. See the NOTICE file * distributed with this work for additional information * regarding copyright ownership. The ASF licenses this file * to you under the Apache License, Version 2.0 (the * "License"); you may not use this file except in compliance * with the License. You may obtain a copy of the License at * * http://www.apache.org/licenses/LICENSE-2.0 * * Unless required by applicable law or agreed to in writing, software * distributed under the License is distributed on an "AS IS" BASIS, * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. * See the License for the specific language governing permissions and * limitations under the License. */ package org.apache.hadoop.io.nativeio; import java.io.File; import java.io.FileDescriptor; import java.io.FileInputStream; import java.io.FileOutputStream; import java.io.IOException; import java.io.RandomAccessFile; import java.lang.reflect.Field; import java.nio.ByteBuffer; import java.nio.MappedByteBuffer; import java.nio.channels.FileChannel; import java.util.Map; import java.util.concurrent.ConcurrentHashMap; import org.apache.hadoop.classification.InterfaceAudience; import org.apache.hadoop.classification.InterfaceStability; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.CommonConfigurationKeys; import org.apache.hadoop.fs.HardLink; import org.apache.hadoop.io.IOUtils; import org.apache.hadoop.io.SecureIOUtils.AlreadyExistsException; import org.apache.hadoop.util.NativeCodeLoader; import org.apache.hadoop.util.Shell; import org.apache.hadoop.util.PerformanceAdvisory; import org.apache.commons.logging.Log; import org.apache.commons.logging.LogFactory; import sun.misc.Unsafe; import com.google.common.annotations.VisibleForTesting; /** * JNI wrappers for various native IO-related calls not available in Java. * These functions should generally be used alongside a fallback to another * more portable mechanism. */ @InterfaceAudience.Private @InterfaceStability.Unstable public class NativeIO { public static class POSIX { // Flags for open() call from bits/fcntl.h public static final int O_RDONLY = 00; public static final int O_WRONLY = 01; public static final int O_RDWR = 02; public static final int O_CREAT = 0100; public static final int O_EXCL = 0200; public static final int O_NOCTTY = 0400; public static final int O_TRUNC = 01000; public static final int O_APPEND = 02000; public static final int O_NONBLOCK = 04000; public static final int O_SYNC = 010000; public static final int O_ASYNC = 020000; public static final int O_FSYNC = O_SYNC; public static final int O_NDELAY = O_NONBLOCK; // Flags for posix_fadvise() from bits/fcntl.h /* No further special treatment. */ public static final int POSIX_FADV_NORMAL = 0; /* Expect random page references. */ public static final int POSIX_FADV_RANDOM = 1; /* Expect sequential page references. */ public static final int POSIX_FADV_SEQUENTIAL = 2; /* Will need these pages. */ public static final int POSIX_FADV_WILLNEED = 3; /* Don't need these pages. */ public static final int POSIX_FADV_DONTNEED = 4; /* Data will be accessed once. */ public static final int POSIX_FADV_NOREUSE = 5; /* Wait upon writeout of all pages in the range before performing the write. */ public static final int SYNC_FILE_RANGE_WAIT_BEFORE = 1; /* Initiate writeout of all those dirty pages in the range which are not presently under writeback. */ public static final int SYNC_FILE_RANGE_WRITE = 2; /* Wait upon writeout of all pages in the range after performing the write. */ public static final int SYNC_FILE_RANGE_WAIT_AFTER = 4; private static final Log LOG = LogFactory.getLog(NativeIO.class); private static boolean nativeLoaded = false; private static boolean fadvisePossible = true; private static boolean syncFileRangePossible = true; static final String WORKAROUND_NON_THREADSAFE_CALLS_KEY = "hadoop.workaround.non.threadsafe.getpwuid"; static final boolean WORKAROUND_NON_THREADSAFE_CALLS_DEFAULT = true; private static long cacheTimeout = -1; private static CacheManipulator cacheManipulator = new CacheManipulator(); public static CacheManipulator getCacheManipulator() { return cacheManipulator; } public static void setCacheManipulator(CacheManipulator cacheManipulator) { POSIX.cacheManipulator = cacheManipulator; } /** * Used to manipulate the operating system cache. */ @VisibleForTesting public static class CacheManipulator { public void mlock(String identifier, ByteBuffer buffer, long len) throws IOException { POSIX.mlock(buffer, len); } public long getMemlockLimit() { return NativeIO.getMemlockLimit(); } public long getOperatingSystemPageSize() { return NativeIO.getOperatingSystemPageSize(); } public void posixFadviseIfPossible(String identifier, FileDescriptor fd, long offset, long len, int flags) throws NativeIOException { NativeIO.POSIX.posixFadviseIfPossible(identifier, fd, offset, len, flags); } public boolean verifyCanMlock() { return NativeIO.isAvailable(); } } /** * A CacheManipulator used for testing which does not actually call mlock. * This allows many tests to be run even when the operating system does not * allow mlock, or only allows limited mlocking. */ @VisibleForTesting public static class NoMlockCacheManipulator extends CacheManipulator { public void mlock(String identifier, ByteBuffer buffer, long len) throws IOException { LOG.info("mlocking " + identifier); } public long getMemlockLimit() { return 1125899906842624L; } public long getOperatingSystemPageSize() { return 4096; } public boolean verifyCanMlock() { return true; } } static { if (NativeCodeLoader.isNativeCodeLoaded()) { try { Configuration conf = new Configuration(); workaroundNonThreadSafePasswdCalls = conf.getBoolean( WORKAROUND_NON_THREADSAFE_CALLS_KEY, WORKAROUND_NON_THREADSAFE_CALLS_DEFAULT); initNative(); nativeLoaded = true; cacheTimeout = conf.getLong( CommonConfigurationKeys.HADOOP_SECURITY_UID_NAME_CACHE_TIMEOUT_KEY, CommonConfigurationKeys.HADOOP_SECURITY_UID_NAME_CACHE_TIMEOUT_DEFAULT) * 1000; LOG.debug("Initialized cache for IDs to User/Group mapping with a " + " cache timeout of " + cacheTimeout/1000 + " seconds."); } catch (Throwable t) { // This can happen if the user has an older version of libhadoop.so // installed - in this case we can continue without native IO // after warning PerformanceAdvisory.LOG.debug("Unable to initialize NativeIO libraries", t); } } } /** * Return true if the JNI-based native IO extensions are available. */ public static boolean isAvailable() { return NativeCodeLoader.isNativeCodeLoaded() && nativeLoaded; } private static void assertCodeLoaded() throws IOException { if (!isAvailable()) { throw new IOException("NativeIO was not loaded"); } } /** Wrapper around open(2) */ public static native FileDescriptor open(String path, int flags, int mode) throws IOException; /** Wrapper around fstat(2) */ private static native Stat fstat(FileDescriptor fd) throws IOException; /** Native chmod implementation. On UNIX, it is a wrapper around chmod(2) */ private static native void chmodImpl(String path, int mode) throws IOException; public static void chmod(String path, int mode) throws IOException { if (!Shell.WINDOWS) { chmodImpl(path, mode); } else { try { chmodImpl(path, mode); } catch (NativeIOException nioe) { if (nioe.getErrorCode() == 3) { throw new NativeIOException("No such file or directory", Errno.ENOENT); } else { LOG.warn(String.format("NativeIO.chmod error (%d): %s", nioe.getErrorCode(), nioe.getMessage())); throw new NativeIOException("Unknown error", Errno.UNKNOWN); } } } } /** Wrapper around posix_fadvise(2) */ static native void posix_fadvise( FileDescriptor fd, long offset, long len, int flags) throws NativeIOException; /** Wrapper around sync_file_range(2) */ static native void sync_file_range( FileDescriptor fd, long offset, long nbytes, int flags) throws NativeIOException; /** * Call posix_fadvise on the given file descriptor. See the manpage * for this syscall for more information. On systems where this * call is not available, does nothing. * * @throws NativeIOException if there is an error with the syscall */ static void posixFadviseIfPossible(String identifier, FileDescriptor fd, long offset, long len, int flags) throws NativeIOException { if (nativeLoaded && fadvisePossible) { try { posix_fadvise(fd, offset, len, flags); } catch (UnsupportedOperationException uoe) { fadvisePossible = false; } catch (UnsatisfiedLinkError ule) { fadvisePossible = false; } } } /** * Call sync_file_range on the given file descriptor. See the manpage * for this syscall for more information. On systems where this * call is not available, does nothing. * * @throws NativeIOException if there is an error with the syscall */ public static void syncFileRangeIfPossible( FileDescriptor fd, long offset, long nbytes, int flags) throws NativeIOException { if (nativeLoaded && syncFileRangePossible) { try { sync_file_range(fd, offset, nbytes, flags); } catch (UnsupportedOperationException uoe) { syncFileRangePossible = false; } catch (UnsatisfiedLinkError ule) { syncFileRangePossible = false; } } } static native void mlock_native( ByteBuffer buffer, long len) throws NativeIOException; /** * Locks the provided direct ByteBuffer into memory, preventing it from * swapping out. After a buffer is locked, future accesses will not incur * a page fault. * * See the mlock(2) man page for more information. * * @throws NativeIOException */ static void mlock(ByteBuffer buffer, long len) throws IOException { assertCodeLoaded(); if (!buffer.isDirect()) { throw new IOException("Cannot mlock a non-direct ByteBuffer"); } mlock_native(buffer, len); } /** * Unmaps the block from memory. See munmap(2). * * There isn't any portable way to unmap a memory region in Java. * So we use the sun.nio method here. * Note that unmapping a memory region could cause crashes if code * continues to reference the unmapped code. However, if we don't * manually unmap the memory, we are dependent on the finalizer to * do it, and we have no idea when the finalizer will run. * * @param buffer The buffer to unmap. */ public static void munmap(MappedByteBuffer buffer) { if (buffer instanceof sun.nio.ch.DirectBuffer) { sun.misc.Cleaner cleaner = ((sun.nio.ch.DirectBuffer)buffer).cleaner(); cleaner.clean(); } } /** Linux only methods used for getOwner() implementation */ private static native long getUIDforFDOwnerforOwner(FileDescriptor fd) throws IOException; private static native String getUserName(long uid) throws IOException; /** * Result type of the fstat call */ public static class Stat { private int ownerId, groupId; private String owner, group; private int mode; // Mode constants public static final int S_IFMT = 0170000; /* type of file */ public static final int S_IFIFO = 0010000; /* named pipe (fifo) */ public static final int S_IFCHR = 0020000; /* character special */ public static final int S_IFDIR = 0040000; /* directory */ public static final int S_IFBLK = 0060000; /* block special */ public static final int S_IFREG = 0100000; /* regular */ public static final int S_IFLNK = 0120000; /* symbolic link */ public static final int S_IFSOCK = 0140000; /* socket */ public static final int S_IFWHT = 0160000; /* whiteout */ public static final int S_ISUID = 0004000; /* set user id on execution */ public static final int S_ISGID = 0002000; /* set group id on execution */ public static final int S_ISVTX = 0001000; /* save swapped text even after use */ public static final int S_IRUSR = 0000400; /* read permission, owner */ public static final int S_IWUSR = 0000200; /* write permission, owner */ public static final int S_IXUSR = 0000100; /* execute/search permission, owner */ Stat(int ownerId, int groupId, int mode) { this.ownerId = ownerId; this.groupId = groupId; this.mode = mode; } Stat(String owner, String group, int mode) { if (!Shell.WINDOWS) { this.owner = owner; } else { this.owner = stripDomain(owner); } if (!Shell.WINDOWS) { this.group = group; } else { this.group = stripDomain(group); } this.mode = mode; } @Override public String toString() { return "Stat(owner='" + owner + "', group='" + group + "'" + ", mode=" + mode + ")"; } public String getOwner() { return owner; } public String getGroup() { return group; } public int getMode() { return mode; } } /** * Returns the file stat for a file descriptor. * * @param fd file descriptor. * @return the file descriptor file stat. * @throws IOException thrown if there was an IO error while obtaining the file stat. */ public static Stat getFstat(FileDescriptor fd) throws IOException { Stat stat = null; if (!Shell.WINDOWS) { stat = fstat(fd); stat.owner = getName(IdCache.USER, stat.ownerId); stat.group = getName(IdCache.GROUP, stat.groupId); } else { try { stat = fstat(fd); } catch (NativeIOException nioe) { if (nioe.getErrorCode() == 6) { throw new NativeIOException("The handle is invalid.", Errno.EBADF); } else { LOG.warn(String.format("NativeIO.getFstat error (%d): %s", nioe.getErrorCode(), nioe.getMessage())); throw new NativeIOException("Unknown error", Errno.UNKNOWN); } } } return stat; } private static String getName(IdCache domain, int id) throws IOException { Map<Integer, CachedName> idNameCache = (domain == IdCache.USER) ? USER_ID_NAME_CACHE : GROUP_ID_NAME_CACHE; String name; CachedName cachedName = idNameCache.get(id); long now = System.currentTimeMillis(); if (cachedName != null && (cachedName.timestamp + cacheTimeout) > now) { name = cachedName.name; } else { name = (domain == IdCache.USER) ? getUserName(id) : getGroupName(id); if (LOG.isDebugEnabled()) { String type = (domain == IdCache.USER) ? "UserName" : "GroupName"; LOG.debug("Got " + type + " " + name + " for ID " + id + " from the native implementation"); } cachedName = new CachedName(name, now); idNameCache.put(id, cachedName); } return name; } static native String getUserName(int uid) throws IOException; static native String getGroupName(int uid) throws IOException; private static class CachedName { final long timestamp; final String name; public CachedName(String name, long timestamp) { this.name = name; this.timestamp = timestamp; } } private static final Map<Integer, CachedName> USER_ID_NAME_CACHE = new ConcurrentHashMap<Integer, CachedName>(); private static final Map<Integer, CachedName> GROUP_ID_NAME_CACHE = new ConcurrentHashMap<Integer, CachedName>(); private enum IdCache { USER, GROUP } public final static int MMAP_PROT_READ = 0x1; public final static int MMAP_PROT_WRITE = 0x2; public final static int MMAP_PROT_EXEC = 0x4; public static native long mmap(FileDescriptor fd, int prot, boolean shared, long length) throws IOException; public static native void munmap(long addr, long length) throws IOException; } private static boolean workaroundNonThreadSafePasswdCalls = false; public static class Windows { // Flags for CreateFile() call on Windows public static final long GENERIC_READ = 0x80000000L; public static final long GENERIC_WRITE = 0x40000000L; public static final long FILE_SHARE_READ = 0x00000001L; public static final long FILE_SHARE_WRITE = 0x00000002L; public static final long FILE_SHARE_DELETE = 0x00000004L; public static final long CREATE_NEW = 1; public static final long CREATE_ALWAYS = 2; public static final long OPEN_EXISTING = 3; public static final long OPEN_ALWAYS = 4; public static final long TRUNCATE_EXISTING = 5; public static final long FILE_BEGIN = 0; public static final long FILE_CURRENT = 1; public static final long FILE_END = 2; public static final long FILE_ATTRIBUTE_NORMAL = 0x00000080L; /** Wrapper around CreateFile() on Windows */ public static native FileDescriptor createFile(String path, long desiredAccess, long shareMode, long creationDisposition) throws IOException; /** Wrapper around SetFilePointer() on Windows */ public static native long setFilePointer(FileDescriptor fd, long distanceToMove, long moveMethod) throws IOException; /** Windows only methods used for getOwner() implementation */ private static native String getOwner(FileDescriptor fd) throws IOException; /** Supported list of Windows access right flags */ public static enum AccessRight { ACCESS_READ (0x0001), // FILE_READ_DATA ACCESS_WRITE (0x0002), // FILE_WRITE_DATA ACCESS_EXECUTE (0x0020); // FILE_EXECUTE private final int accessRight; AccessRight(int access) { accessRight = access; } public int accessRight() { return accessRight; } }; /** Windows only method used to check if the current process has requested * access rights on the given path. */ private static native boolean access0(String path, int requestedAccess); /** * Checks whether the current process has desired access rights on * the given path. * * Longer term this native function can be substituted with JDK7 * function Files#isReadable, isWritable, isExecutable. * * @param path input path * @param desiredAccess ACCESS_READ, ACCESS_WRITE or ACCESS_EXECUTE * @return true if access is allowed * @throws IOException I/O exception on error */ public static boolean access(String path, AccessRight desiredAccess) throws IOException { return true; //return access0(path, desiredAccess.accessRight()); } /** * Extends both the minimum and maximum working set size of the current * process. This method gets the current minimum and maximum working set * size, adds the requested amount to each and then sets the minimum and * maximum working set size to the new values. Controlling the working set * size of the process also controls the amount of memory it can lock. * * @param delta amount to increment minimum and maximum working set size * @throws IOException for any error * @see POSIX#mlock(ByteBuffer, long) */ public static native void extendWorkingSetSize(long delta) throws IOException; static { if (NativeCodeLoader.isNativeCodeLoaded()) { try { initNative(); nativeLoaded = true; } catch (Throwable t) { // This can happen if the user has an older version of libhadoop.so // installed - in this case we can continue without native IO // after warning PerformanceAdvisory.LOG.debug("Unable to initialize NativeIO libraries", t); } } } } private static final Log LOG = LogFactory.getLog(NativeIO.class); private static boolean nativeLoaded = false; static { if (NativeCodeLoader.isNativeCodeLoaded()) { try { initNative(); nativeLoaded = true; } catch (Throwable t) { // This can happen if the user has an older version of libhadoop.so // installed - in this case we can continue without native IO // after warning PerformanceAdvisory.LOG.debug("Unable to initialize NativeIO libraries", t); } } } /** * Return true if the JNI-based native IO extensions are available. */ public static boolean isAvailable() { return NativeCodeLoader.isNativeCodeLoaded() && nativeLoaded; } /** Initialize the JNI method ID and class ID cache */ private static native void initNative(); /** * Get the maximum number of bytes that can be locked into memory at any * given point. * * @return 0 if no bytes can be locked into memory; * Long.MAX_VALUE if there is no limit; * The number of bytes that can be locked into memory otherwise. */ static long getMemlockLimit() { return isAvailable() ? getMemlockLimit0() : 0; } private static native long getMemlockLimit0(); /** * @return the operating system's page size. */ static long getOperatingSystemPageSize() { try { Field f = Unsafe.class.getDeclaredField("theUnsafe"); f.setAccessible(true); Unsafe unsafe = (Unsafe)f.get(null); return unsafe.pageSize(); } catch (Throwable e) { LOG.warn("Unable to get operating system page size. Guessing 4096.", e); return 4096; } } private static class CachedUid { final long timestamp; final String username; public CachedUid(String username, long timestamp) { this.timestamp = timestamp; this.username = username; } } private static final Map<Long, CachedUid> uidCache = new ConcurrentHashMap<Long, CachedUid>(); private static long cacheTimeout; private static boolean initialized = false; /** * The Windows logon name has two part, NetBIOS domain name and * user account name, of the format DOMAIN\UserName. This method * will remove the domain part of the full logon name. * * @param Fthe full principal name containing the domain * @return name with domain removed */ private static String stripDomain(String name) { int i = name.indexOf('\\'); if (i != -1) name = name.substring(i + 1); return name; } public static String getOwner(FileDescriptor fd) throws IOException { ensureInitialized(); if (Shell.WINDOWS) { String owner = Windows.getOwner(fd); owner = stripDomain(owner); return owner; } else { long uid = POSIX.getUIDforFDOwnerforOwner(fd); CachedUid cUid = uidCache.get(uid); long now = System.currentTimeMillis(); if (cUid != null && (cUid.timestamp + cacheTimeout) > now) { return cUid.username; } String user = POSIX.getUserName(uid); LOG.info("Got UserName " + user + " for UID " + uid + " from the native implementation"); cUid = new CachedUid(user, now); uidCache.put(uid, cUid); return user; } } /** * Create a FileInputStream that shares delete permission on the * file opened, i.e. other process can delete the file the * FileInputStream is reading. Only Windows implementation uses * the native interface. */ public static FileInputStream getShareDeleteFileInputStream(File f) throws IOException { if (!Shell.WINDOWS) { // On Linux the default FileInputStream shares delete permission // on the file opened. // return new FileInputStream(f); } else { // Use Windows native interface to create a FileInputStream that // shares delete permission on the file opened. // FileDescriptor fd = Windows.createFile( f.getAbsolutePath(), Windows.GENERIC_READ, Windows.FILE_SHARE_READ | Windows.FILE_SHARE_WRITE | Windows.FILE_SHARE_DELETE, Windows.OPEN_EXISTING); return new FileInputStream(fd); } } /** * Create a FileInputStream that shares delete permission on the * file opened at a given offset, i.e. other process can delete * the file the FileInputStream is reading. Only Windows implementation * uses the native interface. */ public static FileInputStream getShareDeleteFileInputStream(File f, long seekOffset) throws IOException { if (!Shell.WINDOWS) { RandomAccessFile rf = new RandomAccessFile(f, "r"); if (seekOffset > 0) { rf.seek(seekOffset); } return new FileInputStream(rf.getFD()); } else { // Use Windows native interface to create a FileInputStream that // shares delete permission on the file opened, and set it to the // given offset. // FileDescriptor fd = NativeIO.Windows.createFile( f.getAbsolutePath(), NativeIO.Windows.GENERIC_READ, NativeIO.Windows.FILE_SHARE_READ | NativeIO.Windows.FILE_SHARE_WRITE | NativeIO.Windows.FILE_SHARE_DELETE, NativeIO.Windows.OPEN_EXISTING); if (seekOffset > 0) NativeIO.Windows.setFilePointer(fd, seekOffset, NativeIO.Windows.FILE_BEGIN); return new FileInputStream(fd); } } /** * Create the specified File for write access, ensuring that it does not exist. * @param f the file that we want to create * @param permissions we want to have on the file (if security is enabled) * * @throws AlreadyExistsException if the file already exists * @throws IOException if any other error occurred */ public static FileOutputStream getCreateForWriteFileOutputStream(File f, int permissions) throws IOException { if (!Shell.WINDOWS) { // Use the native wrapper around open(2) try { FileDescriptor fd = NativeIO.POSIX.open(f.getAbsolutePath(), NativeIO.POSIX.O_WRONLY | NativeIO.POSIX.O_CREAT | NativeIO.POSIX.O_EXCL, permissions); return new FileOutputStream(fd); } catch (NativeIOException nioe) { if (nioe.getErrno() == Errno.EEXIST) { throw new AlreadyExistsException(nioe); } throw nioe; } } else { // Use the Windows native APIs to create equivalent FileOutputStream try { FileDescriptor fd = NativeIO.Windows.createFile(f.getCanonicalPath(), NativeIO.Windows.GENERIC_WRITE, NativeIO.Windows.FILE_SHARE_DELETE | NativeIO.Windows.FILE_SHARE_READ | NativeIO.Windows.FILE_SHARE_WRITE, NativeIO.Windows.CREATE_NEW); NativeIO.POSIX.chmod(f.getCanonicalPath(), permissions); return new FileOutputStream(fd); } catch (NativeIOException nioe) { if (nioe.getErrorCode() == 80) { // ERROR_FILE_EXISTS // 80 (0x50) // The file exists throw new AlreadyExistsException(nioe); } throw nioe; } } } private synchronized static void ensureInitialized() { if (!initialized) { cacheTimeout = new Configuration().getLong("hadoop.security.uid.cache.secs", 4*60*60) * 1000; LOG.info("Initialized cache for UID to User mapping with a cache" + " timeout of " + cacheTimeout/1000 + " seconds."); initialized = true; } } /** * A version of renameTo that throws a descriptive exception when it fails. * * @param src The source path * @param dst The destination path * * @throws NativeIOException On failure. */ public static void renameTo(File src, File dst) throws IOException { if (!nativeLoaded) { if (!src.renameTo(dst)) { throw new IOException("renameTo(src=" + src + ", dst=" + dst + ") failed."); } } else { renameTo0(src.getAbsolutePath(), dst.getAbsolutePath()); } } public static void link(File src, File dst) throws IOException { if (!nativeLoaded) { HardLink.createHardLink(src, dst); } else { link0(src.getAbsolutePath(), dst.getAbsolutePath()); } } /** * A version of renameTo that throws a descriptive exception when it fails. * * @param src The source path * @param dst The destination path * * @throws NativeIOException On failure. */ private static native void renameTo0(String src, String dst) throws NativeIOException; private static native void link0(String src, String dst) throws NativeIOException; /** * Unbuffered file copy from src to dst without tainting OS buffer cache * * In POSIX platform: * It uses FileChannel#transferTo() which internally attempts * unbuffered IO on OS with native sendfile64() support and falls back to * buffered IO otherwise. * * It minimizes the number of FileChannel#transferTo call by passing the the * src file size directly instead of a smaller size as the 3rd parameter. * This saves the number of sendfile64() system call when native sendfile64() * is supported. In the two fall back cases where sendfile is not supported, * FileChannle#transferTo already has its own batching of size 8 MB and 8 KB, * respectively. * * In Windows Platform: * It uses its own native wrapper of CopyFileEx with COPY_FILE_NO_BUFFERING * flag, which is supported on Windows Server 2008 and above. * * Ideally, we should use FileChannel#transferTo() across both POSIX and Windows * platform. Unfortunately, the wrapper(Java_sun_nio_ch_FileChannelImpl_transferTo0) * used by FileChannel#transferTo for unbuffered IO is not implemented on Windows. * Based on OpenJDK 6/7/8 source code, Java_sun_nio_ch_FileChannelImpl_transferTo0 * on Windows simply returns IOS_UNSUPPORTED. * * Note: This simple native wrapper does minimal parameter checking before copy and * consistency check (e.g., size) after copy. * It is recommended to use wrapper function like * the Storage#nativeCopyFileUnbuffered() function in hadoop-hdfs with pre/post copy * checks. * * @param src The source path * @param dst The destination path * @throws IOException */ public static void copyFileUnbuffered(File src, File dst) throws IOException { if (nativeLoaded && Shell.WINDOWS) { copyFileUnbuffered0(src.getAbsolutePath(), dst.getAbsolutePath()); } else { FileInputStream fis = null; FileOutputStream fos = null; FileChannel input = null; FileChannel output = null; try { fis = new FileInputStream(src); fos = new FileOutputStream(dst); input = fis.getChannel(); output = fos.getChannel(); long remaining = input.size(); long position = 0; long transferred = 0; while (remaining > 0) { transferred = input.transferTo(position, remaining, output); remaining -= transferred; position += transferred; } } finally { IOUtils.cleanup(LOG, output); IOUtils.cleanup(LOG, fos); IOUtils.cleanup(LOG, input); IOUtils.cleanup(LOG, fis); } } } private static native void copyFileUnbuffered0(String src, String dst) throws NativeIOException; }
还有log4j.properties
log4j.rootLogger=DEBUG,CONSOLE,DATABASE,FILE
log4j.addivity.org.apache=true
log4j.appender.CONSOLE=org.apache.log4j.ConsoleAppender
log4j.appender.CONSOLE.Threshold=INFO
log4j.appender.CONSOLE.Target=System.out
log4j.appender.CONSOLE.Encoding=GBK
log4j.appender.CONSOLE.layout=org.apache.log4j.PatternLayout
log4j.appender.CONSOLE.layout.ConversionPattern=[framework] %d - %c -%-4r [%t] %-5p %c %x - %m%n
log4j.appender.DATABASE=org.apache.log4j.jdbc.JDBCAppender
log4j.appender.DATABASE.URL=jdbc:oracle:thin:@90.0.12.20:1521:ORCL
log4j.appender.DATABASE.driver=oracle.jdbc.driver.OracleDriver
log4j.appender.DATABASE.user=Nation
log4j.appender.DATABASE.password=1
log4j.appender.CONSOLE.Threshold=WARN
log4j.appender.DATABASE.sql=INSERT INTO LOG4J(stamp,thread, infolevel,class,messages) VALUES ('%d{yyyy-MM-dd HH:mm:ss}', '%t', '%p', '%l', '%m')
# INSERT INTO LOG4J (Message) VALUES ('[framework] %d - %c -%-4r [%t] %-5p %c %x - %m%n')
log4j.appender.DATABASE.layout=org.apache.log4j.PatternLayout
log4j.appender.DATABASE.layout.ConversionPattern=[framework] %d - %c -%-4r [%t] %-5p %c %x - %m%n
log4j.appender.A1=org.apache.log4j.DailyRollingFileAppender
log4j.appender.A1.File=C:/log4j/log
log4j.appender.A1.Encoding=GBK
log4j.appender.A1.Threshold=DEBUG
log4j.appender.A1.DatePattern='.'yyyy-MM-dd
log4j.appender.A1.layout=org.apache.log4j.PatternLayout
log4j.appender.A1.layout.ConversionPattern=%d{ABSOLUTE} %5p %c{1}:%L : %m%n
log4j.appender.FILE=org.apache.log4j.FileAppender
log4j.appender.FILE.File=C:/log4j/file.log
log4j.appender.FILE.Append=false
log4j.appender.FILE.Encoding=GBK
log4j.appender.FILE.layout=org.apache.log4j.PatternLayout
log4j.appender.FILE.layout.ConversionPattern=[framework] %d - %c -%-4r [%t] %-5p %c %x - %m%n
log4j.appender.ROLLING_FILE=org.apache.log4j.RollingFileAppender
log4j.appender.ROLLING_FILE.Threshold=ERROR
log4j.appender.ROLLING_FILE.File=rolling.log
log4j.appender.ROLLING_FILE.Append=true
log4j.appender.CONSOLE_FILE.Encoding=GBK
log4j.appender.ROLLING_FILE.MaxFileSize=10KB
log4j.appender.ROLLING_FILE.MaxBackupIndex=1
log4j.appender.ROLLING_FILE.layout=org.apache.log4j.PatternLayout
log4j.appender.ROLLING_FILE.layout.ConversionPattern=[framework] %d - %c -%-4r [%t] %-5p %c %x - %m%n
log4j.appender.im = net.cybercorlin.util.logger.appender.IMAppender
log4j.appender.im.host = mail.cybercorlin.net
log4j.appender.im.username = username
log4j.appender.im.password = password
log4j.appender.im.recipient = corlin@cybercorlin.net
log4j.appender.im.layout=org.apache.log4j.PatternLayout
log4j.appender.im.layout.ConversionPattern =[framework] %d - %c -%-4r [%t] %-5p %c %x - %m%n
log4j.appender.SOCKET=org.apache.log4j.RollingFileAppender
log4j.appender.SOCKET.RemoteHost=localhost
log4j.appender.SOCKET.Port=5001
log4j.appender.SOCKET.LocationInfo=true
# Set up for Log Facter 5
log4j.appender.SOCKET.layout=org.apache.log4j.PatternLayout
log4j.appender.SOCET.layout.ConversionPattern=[start]%d{DATE}[DATE]%n%p[PRIORITY]%n%x[NDC]%n%t[THREAD]%n%c[CATEGORY]%n%m[MESSAGE]%n%n
# Log Factor 5 Appender
log4j.appender.LF5_APPENDER=org.apache.log4j.lf5.LF5Appender
log4j.appender.LF5_APPENDER.MaxNumberOfRecords=2000
log4j.appender.MAIL=org.apache.log4j.net.SMTPAppender
log4j.appender.MAIL.Threshold=FATAL
log4j.appender.MAIL.BufferSize=10
log4j.appender.MAIL.From=web@www.wuset.com
log4j.appender.MAIL.SMTPHost=www.wusetu.com
log4j.appender.MAIL.Subject=Log4J Message
log4j.appender.MAIL.To=web@www.wusetu.com
log4j.appender.MAIL.layout=org.apache.log4j.PatternLayout
log4j.appender.MAIL.layout.ConversionPattern=[framework] %d - %c -%-4r [%t] %-5p %c %x - %m%n
在地二个包里加上YARNRunner.java文件:
/** * Licensed to the Apache Software Foundation (ASF) under one * or more contributor license agreements. See the NOTICE file * distributed with this work for additional information * regarding copyright ownership. The ASF licenses this file * to you under the Apache License, Version 2.0 (the * "License"); you may not use this file except in compliance * with the License. You may obtain a copy of the License at * * http://www.apache.org/licenses/LICENSE-2.0 * * Unless required by applicable law or agreed to in writing, software * distributed under the License is distributed on an "AS IS" BASIS, * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. * See the License for the specific language governing permissions and * limitations under the License. */ package org.apache.hadoop.mapred; import java.io.IOException; import java.nio.ByteBuffer; import java.util.ArrayList; import java.util.Collection; import java.util.HashMap; import java.util.HashSet; import java.util.List; import java.util.Map; import java.util.Vector; import org.apache.commons.logging.Log; import org.apache.commons.logging.LogFactory; import org.apache.hadoop.classification.InterfaceAudience.Private; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FileContext; import org.apache.hadoop.fs.FileStatus; import org.apache.hadoop.fs.Path; import org.apache.hadoop.fs.UnsupportedFileSystemException; import org.apache.hadoop.io.DataOutputBuffer; import org.apache.hadoop.io.Text; import org.apache.hadoop.ipc.ProtocolSignature; import org.apache.hadoop.mapreduce.Cluster.JobTrackerStatus; import org.apache.hadoop.mapreduce.ClusterMetrics; import org.apache.hadoop.mapreduce.Counters; import org.apache.hadoop.mapreduce.JobContext; import org.apache.hadoop.mapreduce.JobID; import org.apache.hadoop.mapreduce.JobStatus; import org.apache.hadoop.mapreduce.MRJobConfig; import org.apache.hadoop.mapreduce.QueueAclsInfo; import org.apache.hadoop.mapreduce.QueueInfo; import org.apache.hadoop.mapreduce.TaskAttemptID; import org.apache.hadoop.mapreduce.TaskCompletionEvent; import org.apache.hadoop.mapreduce.TaskReport; import org.apache.hadoop.mapreduce.TaskTrackerInfo; import org.apache.hadoop.mapreduce.TaskType; import org.apache.hadoop.mapreduce.TypeConverter; import org.apache.hadoop.mapreduce.protocol.ClientProtocol; import org.apache.hadoop.mapreduce.security.token.delegation.DelegationTokenIdentifier; import org.apache.hadoop.mapreduce.v2.LogParams; import org.apache.hadoop.mapreduce.v2.api.MRClientProtocol; import org.apache.hadoop.mapreduce.v2.api.protocolrecords.GetDelegationTokenRequest; import org.apache.hadoop.mapreduce.v2.jobhistory.JobHistoryUtils; import org.apache.hadoop.mapreduce.v2.util.MRApps; import org.apache.hadoop.security.Credentials; import org.apache.hadoop.security.SecurityUtil; import org.apache.hadoop.security.UserGroupInformation; import org.apache.hadoop.security.authorize.AccessControlList; import org.apache.hadoop.security.token.Token; import org.apache.hadoop.yarn.api.ApplicationConstants; import org.apache.hadoop.yarn.api.ApplicationConstants.Environment; import org.apache.hadoop.yarn.api.records.ApplicationAccessType; import org.apache.hadoop.yarn.api.records.ApplicationId; import org.apache.hadoop.yarn.api.records.ApplicationReport; import org.apache.hadoop.yarn.api.records.ApplicationSubmissionContext; import org.apache.hadoop.yarn.api.records.ContainerLaunchContext; import org.apache.hadoop.yarn.api.records.LocalResource; import org.apache.hadoop.yarn.api.records.LocalResourceType; import org.apache.hadoop.yarn.api.records.LocalResourceVisibility; import org.apache.hadoop.yarn.api.records.ReservationId; import org.apache.hadoop.yarn.api.records.Resource; import org.apache.hadoop.yarn.api.records.URL; import org.apache.hadoop.yarn.api.records.YarnApplicationState; import org.apache.hadoop.yarn.conf.YarnConfiguration; import org.apache.hadoop.yarn.exceptions.YarnException; import org.apache.hadoop.yarn.factories.RecordFactory; import org.apache.hadoop.yarn.factory.providers.RecordFactoryProvider; import org.apache.hadoop.yarn.security.client.RMDelegationTokenSelector; import org.apache.hadoop.yarn.util.ConverterUtils; import com.google.common.annotations.VisibleForTesting; /** * This class enables the current JobClient (0.22 hadoop) to run on YARN. */ @SuppressWarnings("unchecked") public class YARNRunner implements ClientProtocol { private static final Log LOG = LogFactory.getLog(YARNRunner.class); private final RecordFactory recordFactory = RecordFactoryProvider.getRecordFactory(null); private ResourceMgrDelegate resMgrDelegate; private ClientCache clientCache; private Configuration conf; private final FileContext defaultFileContext; /** * Yarn runner incapsulates the client interface of * yarn * @param conf the configuration object for the client */ public YARNRunner(Configuration conf) { this(conf, new ResourceMgrDelegate(new YarnConfiguration(conf))); } /** * Similar to {@link #YARNRunner(Configuration)} but allowing injecting * {@link ResourceMgrDelegate}. Enables mocking and testing. * @param conf the configuration object for the client * @param resMgrDelegate the resourcemanager client handle. */ public YARNRunner(Configuration conf, ResourceMgrDelegate resMgrDelegate) { this(conf, resMgrDelegate, new ClientCache(conf, resMgrDelegate)); } /** * Similar to {@link YARNRunner#YARNRunner(Configuration, ResourceMgrDelegate)} * but allowing injecting {@link ClientCache}. Enable mocking and testing. * @param conf the configuration object * @param resMgrDelegate the resource manager delegate * @param clientCache the client cache object. */ public YARNRunner(Configuration conf, ResourceMgrDelegate resMgrDelegate, ClientCache clientCache) { this.conf = conf; try { this.resMgrDelegate = resMgrDelegate; this.clientCache = clientCache; this.defaultFileContext = FileContext.getFileContext(this.conf); } catch (UnsupportedFileSystemException ufe) { throw new RuntimeException("Error in instantiating YarnClient", ufe); } } @Private /** * Used for testing mostly. * @param resMgrDelegate the resource manager delegate to set to. */ public void setResourceMgrDelegate(ResourceMgrDelegate resMgrDelegate) { this.resMgrDelegate = resMgrDelegate; } @Override public void cancelDelegationToken(Token<DelegationTokenIdentifier> arg0) throws IOException, InterruptedException { throw new UnsupportedOperationException("Use Token.renew instead"); } @Override public TaskTrackerInfo[] getActiveTrackers() throws IOException, InterruptedException { return resMgrDelegate.getActiveTrackers(); } @Override public JobStatus[] getAllJobs() throws IOException, InterruptedException { return resMgrDelegate.getAllJobs(); } @Override public TaskTrackerInfo[] getBlacklistedTrackers() throws IOException, InterruptedException { return resMgrDelegate.getBlacklistedTrackers(); } @Override public ClusterMetrics getClusterMetrics() throws IOException, InterruptedException { return resMgrDelegate.getClusterMetrics(); } @VisibleForTesting void addHistoryToken(Credentials ts) throws IOException, InterruptedException { /* check if we have a hsproxy, if not, no need */ MRClientProtocol hsProxy = clientCache.getInitializedHSProxy(); if (UserGroupInformation.isSecurityEnabled() && (hsProxy != null)) { /* * note that get delegation token was called. Again this is hack for oozie * to make sure we add history server delegation tokens to the credentials */ RMDelegationTokenSelector tokenSelector = new RMDelegationTokenSelector(); Text service = resMgrDelegate.getRMDelegationTokenService(); if (tokenSelector.selectToken(service, ts.getAllTokens()) != null) { Text hsService = SecurityUtil.buildTokenService(hsProxy .getConnectAddress()); if (ts.getToken(hsService) == null) { ts.addToken(hsService, getDelegationTokenFromHS(hsProxy)); } } } } @VisibleForTesting Token<?> getDelegationTokenFromHS(MRClientProtocol hsProxy) throws IOException, InterruptedException { GetDelegationTokenRequest request = recordFactory .newRecordInstance(GetDelegationTokenRequest.class); request.setRenewer(Master.getMasterPrincipal(conf)); org.apache.hadoop.yarn.api.records.Token mrDelegationToken; mrDelegationToken = hsProxy.getDelegationToken(request) .getDelegationToken(); return ConverterUtils.convertFromYarn(mrDelegationToken, hsProxy.getConnectAddress()); } @Override public Token<DelegationTokenIdentifier> getDelegationToken(Text renewer) throws IOException, InterruptedException { // The token is only used for serialization. So the type information // mismatch should be fine. return resMgrDelegate.getDelegationToken(renewer); } @Override public String getFilesystemName() throws IOException, InterruptedException { return resMgrDelegate.getFilesystemName(); } @Override public JobID getNewJobID() throws IOException, InterruptedException { return resMgrDelegate.getNewJobID(); } @Override public QueueInfo getQueue(String queueName) throws IOException, InterruptedException { return resMgrDelegate.getQueue(queueName); } @Override public QueueAclsInfo[] getQueueAclsForCurrentUser() throws IOException, InterruptedException { return resMgrDelegate.getQueueAclsForCurrentUser(); } @Override public QueueInfo[] getQueues() throws IOException, InterruptedException { return resMgrDelegate.getQueues(); } @Override public QueueInfo[] getRootQueues() throws IOException, InterruptedException { return resMgrDelegate.getRootQueues(); } @Override public QueueInfo[] getChildQueues(String parent) throws IOException, InterruptedException { return resMgrDelegate.getChildQueues(parent); } @Override public String getStagingAreaDir() throws IOException, InterruptedException { return resMgrDelegate.getStagingAreaDir(); } @Override public String getSystemDir() throws IOException, InterruptedException { return resMgrDelegate.getSystemDir(); } @Override public long getTaskTrackerExpiryInterval() throws IOException, InterruptedException { return resMgrDelegate.getTaskTrackerExpiryInterval(); } @Override public JobStatus submitJob(JobID jobId, String jobSubmitDir, Credentials ts) throws IOException, InterruptedException { addHistoryToken(ts); // Construct necessary information to start the MR AM ApplicationSubmissionContext appContext = createApplicationSubmissionContext(conf, jobSubmitDir, ts); // Submit to ResourceManager try { ApplicationId applicationId = resMgrDelegate.submitApplication(appContext); ApplicationReport appMaster = resMgrDelegate .getApplicationReport(applicationId); String diagnostics = (appMaster == null ? "application report is null" : appMaster.getDiagnostics()); if (appMaster == null || appMaster.getYarnApplicationState() == YarnApplicationState.FAILED || appMaster.getYarnApplicationState() == YarnApplicationState.KILLED) { throw new IOException("Failed to run job : " + diagnostics); } return clientCache.getClient(jobId).getJobStatus(jobId); } catch (YarnException e) { throw new IOException(e); } } private LocalResource createApplicationResource(FileContext fs, Path p, LocalResourceType type) throws IOException { LocalResource rsrc = recordFactory.newRecordInstance(LocalResource.class); FileStatus rsrcStat = fs.getFileStatus(p); rsrc.setResource(ConverterUtils.getYarnUrlFromPath(fs .getDefaultFileSystem().resolvePath(rsrcStat.getPath()))); rsrc.setSize(rsrcStat.getLen()); rsrc.setTimestamp(rsrcStat.getModificationTime()); rsrc.setType(type); rsrc.setVisibility(LocalResourceVisibility.APPLICATION); return rsrc; } public ApplicationSubmissionContext createApplicationSubmissionContext( Configuration jobConf, String jobSubmitDir, Credentials ts) throws IOException { ApplicationId applicationId = resMgrDelegate.getApplicationId(); // Setup resource requirements Resource capability = recordFactory.newRecordInstance(Resource.class); capability.setMemory( conf.getInt( MRJobConfig.MR_AM_VMEM_MB, MRJobConfig.DEFAULT_MR_AM_VMEM_MB ) ); capability.setVirtualCores( conf.getInt( MRJobConfig.MR_AM_CPU_VCORES, MRJobConfig.DEFAULT_MR_AM_CPU_VCORES ) ); LOG.debug("AppMaster capability = " + capability); // Setup LocalResources Map<String, LocalResource> localResources = new HashMap<String, LocalResource>(); Path jobConfPath = new Path(jobSubmitDir, MRJobConfig.JOB_CONF_FILE); URL yarnUrlForJobSubmitDir = ConverterUtils .getYarnUrlFromPath(defaultFileContext.getDefaultFileSystem() .resolvePath( defaultFileContext.makeQualified(new Path(jobSubmitDir)))); LOG.debug("Creating setup context, jobSubmitDir url is " + yarnUrlForJobSubmitDir); localResources.put(MRJobConfig.JOB_CONF_FILE, createApplicationResource(defaultFileContext, jobConfPath, LocalResourceType.FILE)); if (jobConf.get(MRJobConfig.JAR) != null) { Path jobJarPath = new Path(jobConf.get(MRJobConfig.JAR)); LocalResource rc = createApplicationResource( FileContext.getFileContext(jobJarPath.toUri(), jobConf), jobJarPath, LocalResourceType.PATTERN); String pattern = conf.getPattern(JobContext.JAR_UNPACK_PATTERN, JobConf.UNPACK_JAR_PATTERN_DEFAULT).pattern(); rc.setPattern(pattern); localResources.put(MRJobConfig.JOB_JAR, rc); } else { // Job jar may be null. For e.g, for pipes, the job jar is the hadoop // mapreduce jar itself which is already on the classpath. LOG.info("Job jar is not present. " + "Not adding any jar to the list of resources."); } // TODO gross hack for (String s : new String[] { MRJobConfig.JOB_SPLIT, MRJobConfig.JOB_SPLIT_METAINFO }) { localResources.put( MRJobConfig.JOB_SUBMIT_DIR + "/" + s, createApplicationResource(defaultFileContext, new Path(jobSubmitDir, s), LocalResourceType.FILE)); } // Setup security tokens DataOutputBuffer dob = new DataOutputBuffer(); ts.writeTokenStorageToStream(dob); ByteBuffer securityTokens = ByteBuffer.wrap(dob.getData(), 0, dob.getLength()); // Setup the command to run the AM List<String> vargs = new ArrayList<String>(8); vargs.add("$JAVA_HOME/bin/java"); // TODO: why do we use 'conf' some places and 'jobConf' others? long logSize = jobConf.getLong(MRJobConfig.MR_AM_LOG_KB, MRJobConfig.DEFAULT_MR_AM_LOG_KB) << 10; String logLevel = jobConf.get( MRJobConfig.MR_AM_LOG_LEVEL, MRJobConfig.DEFAULT_MR_AM_LOG_LEVEL); int numBackups = jobConf.getInt(MRJobConfig.MR_AM_LOG_BACKUPS, MRJobConfig.DEFAULT_MR_AM_LOG_BACKUPS); MRApps.addLog4jSystemProperties(logLevel, logSize, numBackups, vargs, conf); // Check for Java Lib Path usage in MAP and REDUCE configs warnForJavaLibPath(conf.get(MRJobConfig.MAP_JAVA_OPTS,""), "map", MRJobConfig.MAP_JAVA_OPTS, MRJobConfig.MAP_ENV); warnForJavaLibPath(conf.get(MRJobConfig.MAPRED_MAP_ADMIN_JAVA_OPTS,""), "map", MRJobConfig.MAPRED_MAP_ADMIN_JAVA_OPTS, MRJobConfig.MAPRED_ADMIN_USER_ENV); warnForJavaLibPath(conf.get(MRJobConfig.REDUCE_JAVA_OPTS,""), "reduce", MRJobConfig.REDUCE_JAVA_OPTS, MRJobConfig.REDUCE_ENV); warnForJavaLibPath(conf.get(MRJobConfig.MAPRED_REDUCE_ADMIN_JAVA_OPTS,""), "reduce", MRJobConfig.MAPRED_REDUCE_ADMIN_JAVA_OPTS, MRJobConfig.MAPRED_ADMIN_USER_ENV); // Add AM admin command opts before user command opts // so that it can be overridden by user String mrAppMasterAdminOptions = conf.get(MRJobConfig.MR_AM_ADMIN_COMMAND_OPTS, MRJobConfig.DEFAULT_MR_AM_ADMIN_COMMAND_OPTS); warnForJavaLibPath(mrAppMasterAdminOptions, "app master", MRJobConfig.MR_AM_ADMIN_COMMAND_OPTS, MRJobConfig.MR_AM_ADMIN_USER_ENV); vargs.add(mrAppMasterAdminOptions); // Add AM user command opts String mrAppMasterUserOptions = conf.get(MRJobConfig.MR_AM_COMMAND_OPTS, MRJobConfig.DEFAULT_MR_AM_COMMAND_OPTS); warnForJavaLibPath(mrAppMasterUserOptions, "app master", MRJobConfig.MR_AM_COMMAND_OPTS, MRJobConfig.MR_AM_ENV); vargs.add(mrAppMasterUserOptions); if (jobConf.getBoolean(MRJobConfig.MR_AM_PROFILE, MRJobConfig.DEFAULT_MR_AM_PROFILE)) { final String profileParams = jobConf.get(MRJobConfig.MR_AM_PROFILE_PARAMS, MRJobConfig.DEFAULT_TASK_PROFILE_PARAMS); if (profileParams != null) { vargs.add(String.format(profileParams, ApplicationConstants.LOG_DIR_EXPANSION_VAR + Path.SEPARATOR + TaskLog.LogName.PROFILE)); } } vargs.add(MRJobConfig.APPLICATION_MASTER_CLASS); vargs.add("1>" + ApplicationConstants.LOG_DIR_EXPANSION_VAR + Path.SEPARATOR + ApplicationConstants.STDOUT); vargs.add("2>" + ApplicationConstants.LOG_DIR_EXPANSION_VAR + Path.SEPARATOR + ApplicationConstants.STDERR); Vector<String> vargsFinal = new Vector<String>(8); // Final command StringBuilder mergedCommand = new StringBuilder(); for (CharSequence str : vargs) { mergedCommand.append(str).append(" "); } vargsFinal.add(mergedCommand.toString()); LOG.debug("Command to launch container for ApplicationMaster is : " + mergedCommand); // Setup the CLASSPATH in environment // i.e. add { Hadoop jars, job jar, CWD } to classpath. Map<String, String> environment = new HashMap<String, String>(); MRApps.setClasspath(environment, conf); // Shell environment.put(Environment.SHELL.name(), conf.get(MRJobConfig.MAPRED_ADMIN_USER_SHELL, MRJobConfig.DEFAULT_SHELL)); replaceEnvironment(environment); // Add the container working directory in front of LD_LIBRARY_PATH MRApps.addToEnvironment(environment, Environment.LD_LIBRARY_PATH.name(), MRApps.crossPlatformifyMREnv(conf, Environment.PWD), conf); // Setup the environment variables for Admin first MRApps.setEnvFromInputString(environment, conf.get(MRJobConfig.MR_AM_ADMIN_USER_ENV, MRJobConfig.DEFAULT_MR_AM_ADMIN_USER_ENV), conf); // Setup the environment variables (LD_LIBRARY_PATH, etc) MRApps.setEnvFromInputString(environment, conf.get(MRJobConfig.MR_AM_ENV), conf); // Parse distributed cache MRApps.setupDistributedCache(jobConf, localResources); Map<ApplicationAccessType, String> acls = new HashMap<ApplicationAccessType, String>(2); acls.put(ApplicationAccessType.VIEW_APP, jobConf.get( MRJobConfig.JOB_ACL_VIEW_JOB, MRJobConfig.DEFAULT_JOB_ACL_VIEW_JOB)); acls.put(ApplicationAccessType.MODIFY_APP, jobConf.get( MRJobConfig.JOB_ACL_MODIFY_JOB, MRJobConfig.DEFAULT_JOB_ACL_MODIFY_JOB)); // Setup ContainerLaunchContext for AM container ContainerLaunchContext amContainer = ContainerLaunchContext.newInstance(localResources, environment, vargsFinal, null, securityTokens, acls); Collection<String> tagsFromConf = jobConf.getTrimmedStringCollection(MRJobConfig.JOB_TAGS); // Set up the ApplicationSubmissionContext ApplicationSubmissionContext appContext = recordFactory.newRecordInstance(ApplicationSubmissionContext.class); appContext.setApplicationId(applicationId); // ApplicationId appContext.setQueue( // Queue name jobConf.get(JobContext.QUEUE_NAME, YarnConfiguration.DEFAULT_QUEUE_NAME)); // add reservationID if present ReservationId reservationID = null; try { reservationID = ReservationId.parseReservationId(jobConf .get(JobContext.RESERVATION_ID)); } catch (NumberFormatException e) { // throw exception as reservationid as is invalid String errMsg = "Invalid reservationId: " + jobConf.get(JobContext.RESERVATION_ID) + " specified for the app: " + applicationId; LOG.warn(errMsg); throw new IOException(errMsg); } if (reservationID != null) { appContext.setReservationID(reservationID); LOG.info("SUBMITTING ApplicationSubmissionContext app:" + applicationId + " to queue:" + appContext.getQueue() + " with reservationId:" + appContext.getReservationID()); } appContext.setApplicationName( // Job name jobConf.get(JobContext.JOB_NAME, YarnConfiguration.DEFAULT_APPLICATION_NAME)); appContext.setCancelTokensWhenComplete( conf.getBoolean(MRJobConfig.JOB_CANCEL_DELEGATION_TOKEN, true)); appContext.setAMContainerSpec(amContainer); // AM Container appContext.setMaxAppAttempts( conf.getInt(MRJobConfig.MR_AM_MAX_ATTEMPTS, MRJobConfig.DEFAULT_MR_AM_MAX_ATTEMPTS)); appContext.setResource(capability); appContext.setApplicationType(MRJobConfig.MR_APPLICATION_TYPE); if (tagsFromConf != null && !tagsFromConf.isEmpty()) { appContext.setApplicationTags(new HashSet<String>(tagsFromConf)); } return appContext; } @Override public void setJobPriority(JobID arg0, String arg1) throws IOException, InterruptedException { resMgrDelegate.setJobPriority(arg0, arg1); } @Override public long getProtocolVersion(String arg0, long arg1) throws IOException { return resMgrDelegate.getProtocolVersion(arg0, arg1); } @Override public long renewDelegationToken(Token<DelegationTokenIdentifier> arg0) throws IOException, InterruptedException { throw new UnsupportedOperationException("Use Token.renew instead"); } @Override public Counters getJobCounters(JobID arg0) throws IOException, InterruptedException { return clientCache.getClient(arg0).getJobCounters(arg0); } @Override public String getJobHistoryDir() throws IOException, InterruptedException { return JobHistoryUtils.getConfiguredHistoryServerDoneDirPrefix(conf); } @Override public JobStatus getJobStatus(JobID jobID) throws IOException, InterruptedException { JobStatus status = clientCache.getClient(jobID).getJobStatus(jobID); return status; } @Override public TaskCompletionEvent[] getTaskCompletionEvents(JobID arg0, int arg1, int arg2) throws IOException, InterruptedException { return clientCache.getClient(arg0).getTaskCompletionEvents(arg0, arg1, arg2); } @Override public String[] getTaskDiagnostics(TaskAttemptID arg0) throws IOException, InterruptedException { return clientCache.getClient(arg0.getJobID()).getTaskDiagnostics(arg0); } @Override public TaskReport[] getTaskReports(JobID jobID, TaskType taskType) throws IOException, InterruptedException { return clientCache.getClient(jobID) .getTaskReports(jobID, taskType); } private void killUnFinishedApplication(ApplicationId appId) throws IOException { ApplicationReport application = null; try { application = resMgrDelegate.getApplicationReport(appId); } catch (YarnException e) { throw new IOException(e); } if (application.getYarnApplicationState() == YarnApplicationState.FINISHED || application.getYarnApplicationState() == YarnApplicationState.FAILED || application.getYarnApplicationState() == YarnApplicationState.KILLED) { return; } killApplication(appId); } private void killApplication(ApplicationId appId) throws IOException { try { resMgrDelegate.killApplication(appId); } catch (YarnException e) { throw new IOException(e); } } private boolean isJobInTerminalState(JobStatus status) { return status.getState() == JobStatus.State.KILLED || status.getState() == JobStatus.State.FAILED || status.getState() == JobStatus.State.SUCCEEDED; } @Override public void killJob(JobID arg0) throws IOException, InterruptedException { /* check if the status is not running, if not send kill to RM */ JobStatus status = clientCache.getClient(arg0).getJobStatus(arg0); ApplicationId appId = TypeConverter.toYarn(arg0).getAppId(); // get status from RM and return if (status == null) { killUnFinishedApplication(appId); return; } if (status.getState() != JobStatus.State.RUNNING) { killApplication(appId); return; } try { /* send a kill to the AM */ clientCache.getClient(arg0).killJob(arg0); long currentTimeMillis = System.currentTimeMillis(); long timeKillIssued = currentTimeMillis; while ((currentTimeMillis < timeKillIssued + 10000L) && !isJobInTerminalState(status)) { try { Thread.sleep(1000L); } catch (InterruptedException ie) { /** interrupted, just break */ break; } currentTimeMillis = System.currentTimeMillis(); status = clientCache.getClient(arg0).getJobStatus(arg0); if (status == null) { killUnFinishedApplication(appId); return; } } } catch(IOException io) { LOG.debug("Error when checking for application status", io); } if (status != null && !isJobInTerminalState(status)) { killApplication(appId); } } @Override public boolean killTask(TaskAttemptID arg0, boolean arg1) throws IOException, InterruptedException { return clientCache.getClient(arg0.getJobID()).killTask(arg0, arg1); } @Override public AccessControlList getQueueAdmins(String arg0) throws IOException { return new AccessControlList("*"); } @Override public JobTrackerStatus getJobTrackerStatus() throws IOException, InterruptedException { return JobTrackerStatus.RUNNING; } @Override public ProtocolSignature getProtocolSignature(String protocol, long clientVersion, int clientMethodsHash) throws IOException { return ProtocolSignature.getProtocolSignature(this, protocol, clientVersion, clientMethodsHash); } @Override public LogParams getLogFileParams(JobID jobID, TaskAttemptID taskAttemptID) throws IOException { return clientCache.getClient(jobID).getLogFilePath(jobID, taskAttemptID); } private static void warnForJavaLibPath(String opts, String component, String javaConf, String envConf) { if (opts != null && opts.contains("-Djava.library.path")) { LOG.warn("Usage of -Djava.library.path in " + javaConf + " can cause " + "programs to no longer function if hadoop native libraries " + "are used. These values should be set as part of the " + "LD_LIBRARY_PATH in the " + component + " JVM env using " + envConf + " config settings."); } } public void close() throws IOException { if (resMgrDelegate != null) { resMgrDelegate.close(); resMgrDelegate = null; } if (clientCache != null) { clientCache.close(); clientCache = null; } } private void replaceEnvironment(Map<String, String> environment) { String tmpClassPath = environment.get("CLASSPATH"); tmpClassPath=tmpClassPath.replaceAll(";", ":"); tmpClassPath=tmpClassPath.replaceAll("%PWD%", "\\$PWD"); tmpClassPath=tmpClassPath.replaceAll("%HADOOP_MAPRED_HOME%", "\\$HADOOP_MAPRED_HOME"); tmpClassPath= tmpClassPath.replaceAll("\\\\", "/" ); environment.put("CLASSPATH",tmpClassPath); } }
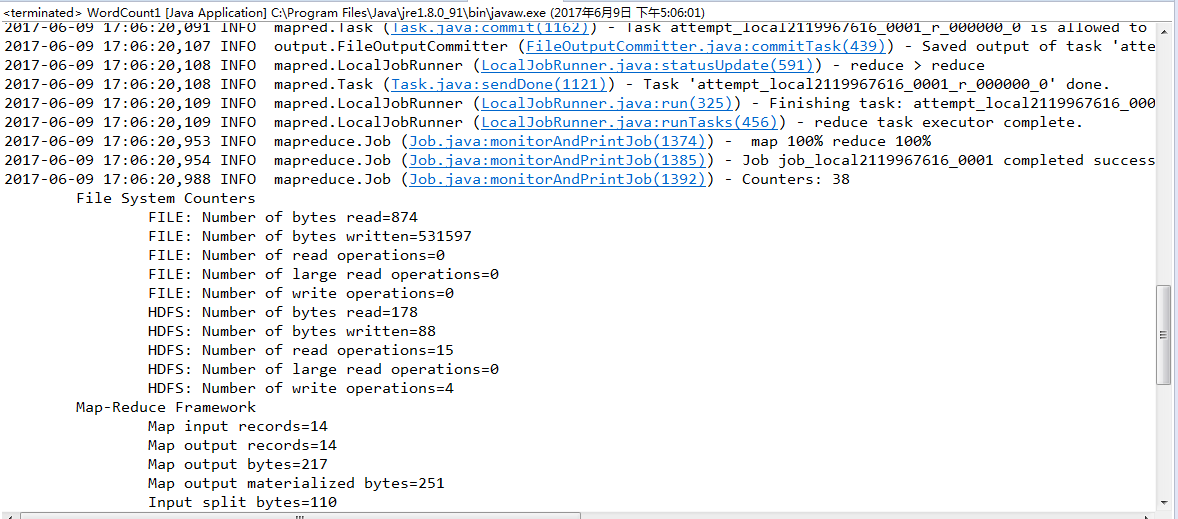
最后再放一张成功结果图: