
【自然语言处理之文本分类】——GloVe和FastText_词频 glove
赞
踩
【自然语言处理之文本分类】——GloVe和FastText
GloVe
GloVe(Global Vectors for Word Representation)它是一个基于全局词频统计(count-based & overall statistics)的词表征。
GloVe 官方提供的预训练词向量:
https://nlp.stanford.edu/projects/glove/
FastText
FastText 是 word2vec 衍生物,都基于 CBOW 模型。是词向量模型也是一个快速的文本分类方法。FastText 使用了字符级别的 n-grams 来表示一个单词。
对于单词“apple”,假设 n 的取值为 3,则它的 Trigram 有:“<ap”, “app”, “ppl”, “ple”, “le>”。
ps:上图参考https://blog.csdn.net/weixin_36604953
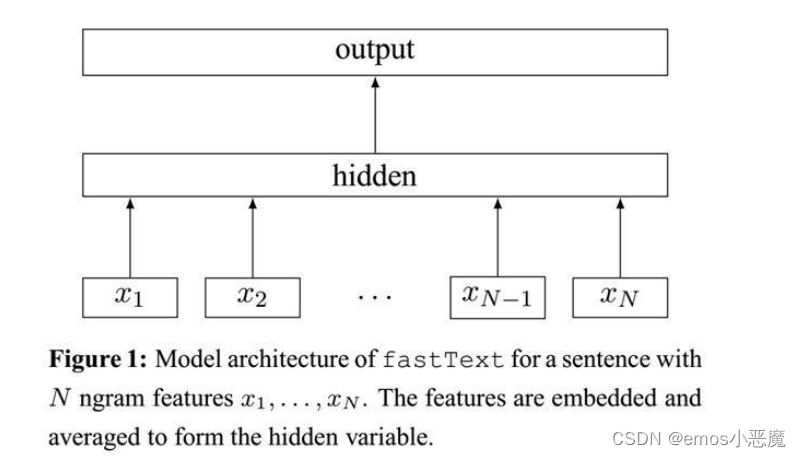
FastText 模型架构和 word2vec 的 CBOW 模型架构非常相似,与 CBOW 一样,FastText 模型也只有三层:输入层、隐含层、输出层(Hierarchical Softmax),输入1 x~ Nx为输入每个单词 Char-level 的 N-gram 向量。
训练过程与 CBOW 一样,只不过CBOW 的输入是目标单词的上下文,FastText 的输入是多个单词及其 n-gram 特征,这些特征用来表示单个文档;
CBOW 的输入单词被 one-hot 编码过,FastText 的输入特征是被 embedding 过;CBOW 的输出是目标词汇,FastText 的输出是文档对应的类别。
网上有提供了三个预训练的词向量:
-
wiki-news-300d-1M.vec.zip: 在维基百科 2017、UMBC webbase 语料库和statmt。
org 新闻数据集中(16B tokens)训练的 100 万个词向量。 -
wiki-news-300d-1M-subword.vec.zip: 在维基百科 2017、UMBC webbase 语料库和 statmt.org 新闻数据集(16B tokens)中包含子单词信息训练的100 万个词向量。
-
crawl-300d-2M.vec.zip: 在 Common Crawl 训练的 200 万个词向量(600B tokens)。

