
- 1脉冲神经网络大致流程_脉冲神经网络python数据集
- 2阿里腾讯极其看重的数据中台,我用大白话给你解释清楚了_腾讯阿里 数据中台
- 3第二章 Linux的目录和文件管理
- 4vue3结合element-plus封装table列表组件_vue3 element-plus el-table树形列表 自定义图标
- 5python对电影进行预测评分_GitHub - tomzhang/recsys_core: [电影推荐系统] Based on the movie scoring data set, the mov...
- 6kafka查看消费数据
- 7计算机桌面动态壁纸,动态桌面壁纸,详细教您电脑动态桌面壁纸怎么设置
- 8快递分拣机器人系统运用了哪些计算机技术,自动分拣十几秒完成 快递机器人何日满城“跑”...
- 9大模型 Transformer介绍-Part1
- 10(1)TCL 基础入门_数字后端命令tclsh什么意思
3D车道线检测论文阅读:3DLaneNet
赞
踩
此论文是基于深度学习的image-based 3D车道线检测的开创之作,由通用汽车以色列研究中心在2019年的ICCV上提出的,作为开篇之作肯定存在不足之处所以才有后来的由百度Apollo在2020年ECCV上提出的Gen-LaneNet以及原团队改进后的3D-LaneNet+等,这些将在后面的文章中一一介绍。
论文地址:
synthetic-3D-lanes数据集地址:(https://link.zhihu.com/?target=https%3A//sites.google.com/view/danlevi/3dlanes
0 摘要
我们介绍一种网络,可以直接从单张图像中预测道路场景中车道的3D布局。这项工作标志着在不假设已知恒定车道宽度或依赖预映射环境的情况下,首次尝试用车载视觉传感解决这一任务。我们的网络架构3D-LaneNet应用了两个新概念: 网络内部的逆透视映射(IPM)和基于锚点anchor的车道表示。网络内的IPM投影促进了常规图像视图和顶视图的双重表示信息流。每列anchor输出表示使我们的端到端方法取代了常见的启发式方法,如聚类和异常值排除,将车道估计作为对象检测问题。此外,我们的方法明确地处理复杂的情况,如车道合并和分割。在两个新的三维车道数据集上展示了结果,一个合成的和一个真实的。为了与现有方法进行比较,我们在仅图像的简单车道检测基准上测试了我们的方法,实现了与最先进的性能相竞争的性能。
1 创新点
- 引入了一个新问题:没有几何假设的单帧3D车道检测,以及新的评估指标。
- 一种新型的双路径架构,在网络内部实现特征的IPM投影。
- 一种新的基于锚点的车道输出表示,可以为3D和2D车道检测提供直接端到端的网络训练。
- 一种用于生成具有车道拓扑结构(即车道数量、合并、分割)和3D形状变化的随机合成样本的方法
2 方法
2.1 总体框架介绍
3D LaneNet的整体网络结构如下图所示,可以看到上下两个通道,上面的通道提取原始输入的前视图特征,最终预测相机的俯仰角θ给到SIPM进行后续的前视图特征到俯视图特征的转换。下面的通道接收各个尺度下的由前视图特征转换来的俯视图特征,并不断提取俯视图特征,最终输出3D车道线相关数据的预测。
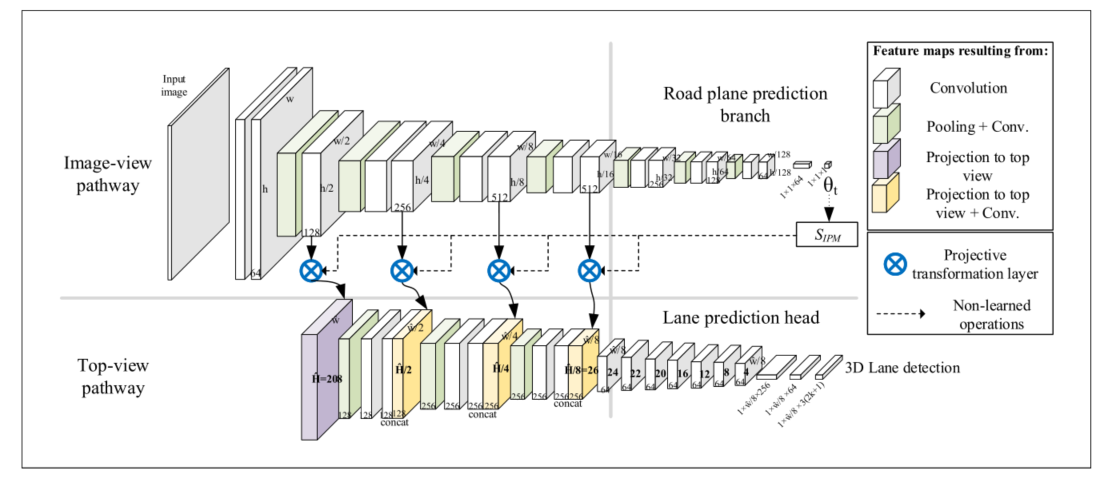
在安装在车辆上的前置摄像头拍摄的单个图像作为输入,如图2所示。论文假设已知相机的固有参数κ(如焦距、投影中心)、摄像机安装在相对于本地地平面的零度滚动位置(这个假设也不合适)。不假设已知摄像头高度和俯仰角,因为这些可能会改变由于车辆的动态。论文中用车道中心线和车道分隔符(即我们常说的车道线)表示车道,如图3所示。每个这样的车道实体(中心线或分隔符)都是用相机坐标(Ccamera)表示的3D曲线。任务是检测给定图像的车道中心线和车道分隔符集。
每个锚点的网络输出包括三个类型:前两种类型 ( c 1 , c 2 ) (c_1,c_2) (c1,c2)表示车道中心线,第三种类型表示车道分隔符。为每个锚点分配两个可能的中心线会产生网络对合并和分割的支持,即两个车道的中心线在 Y r e f Y_{ref} Yref处重合,并在不同的道路位置分开。因此,最终预测层向量大小为 3 ⋅ ( 2 ⋅ K + 1 ) × 1 × N 3\cdot(2\cdot K+1)\times 1 \times N 3⋅(2⋅K+1)×1×N,每列 i i i 对应一个锚点, i ∈ { 1... N } i\in\{1...N\} i∈{1...N}。锚点中每个点的网络输出形式为 ( x t i , z t i , p t i ) (x^i_t,z^i_t,p^i_t) (xti,zti,pti)。最后的预测执行一维非最大抑制,这在物体检测中很常见——只保留局部置信度最大的车道(与左邻和右邻锚相比)。经过非极大值抑制后的每个车道由少量(K)个3D点表示,使用样条插值转换为光滑曲线。
2.2 模块介绍
2.2.1 Top-view projection(顶视图投影)
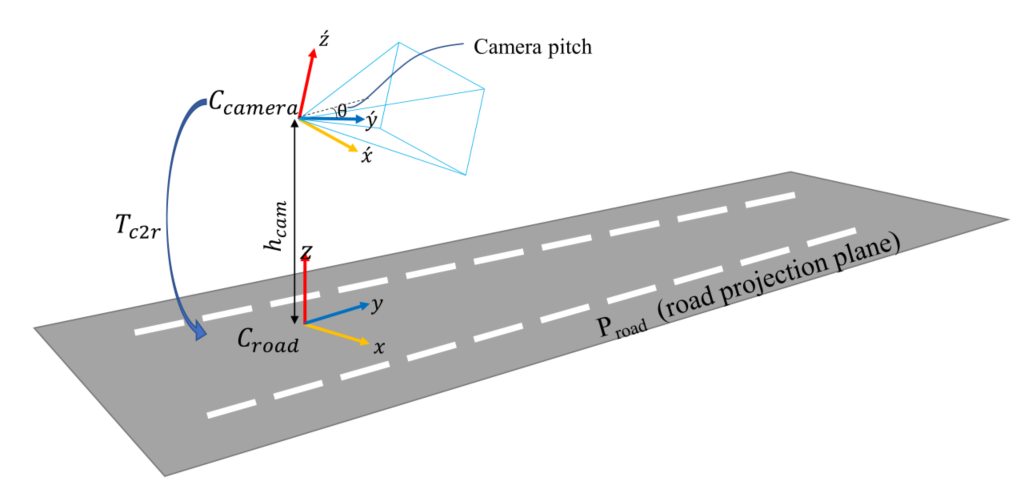
IPM是一种单应性,它将前视图图像扭曲为虚拟俯视图图像,相当于应用一个相机旋转单应性(视图向下旋转),然后是一个各向异性缩放。论文希望确保俯视图图像中的每个像素都对应于道路上的预定义位置,独立于摄像机的内参及其相对于道路的姿态。图2中,相机坐标为Ccamera =(´x´, ´y´,´z´)、道路坐标Croad = (x, y, z)、Proad为与局部路面相切的平面: z方向为Proad的法线,y为y´在Proad上的投影(即原点为摄像机中心在Proad上的投影)。Tc2r是6-D.O.F。相机和相机之间的转换Croad (3D平移和3D旋转)。由于假设滚转角度为0,Tc2r由摄像机俯仰角θ和它高于地面的高度hcam唯一定义。
将Proad上的每个点映射到图像平面坐标的单应性Hr2i: Proad→Pimg由Tc2r和κ决定(参考:Multiple View Geometry in Computer Vision)。最后,从Hr2i获得IPM,使用一组固定的参数IPM-Params定义俯视图区域边界和从米到像素的各向异性缩放。俯视图图像是使用采样网格SIPM定义的双线性插值生成的。
投影后的像素点值一般是浮点数,通过双线性插值对其周围像素进行采样。
2.2.2 The projective transformation layer(投影变换层)
这部分主要是图1中蓝色标记的投影转换层。这一层是projective transformation layer模块[Spatial transformer networks]的特定实现,略有变化。它对图像平面空间上对应的输入特征映射进行可微分采样,在保留通道数量的情况下,输出与场景虚拟俯视图空间上对应的特征映射。
Road projection prediction branch
Image-view路径网络的第一个中间输出是对道路投影平面Proad的估计。本质上,这个分支预测了Tc2r,即摄像机向道路坐标的转变。它是在监督的方式下训练的。Tc2r决定了顶视图单应性Hr2i和采样网格SIPM,因此在top-view路径的前馈步骤中需要Tc2r。在推理时,它还用于将用Croad表示的网络输出转换回摄像机。Tc2r在本例中由摄像机高度hcam和间距θ定义,因此这是该分支的两个输出实际上前视图分支预测两个参数:相机高度hcam 相机俯仰角θ(但是从整体图上没有看到高度的预测输出)。
Lane prediction head
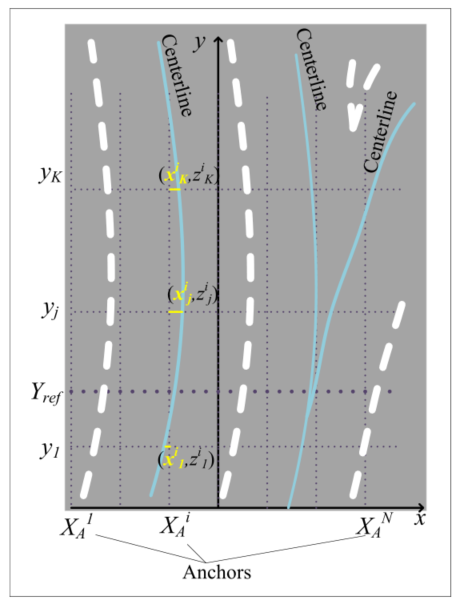
受目标检测的影响,我们使用anchor来表示3D车道线,如图3所示,在道路坐标系中,沿x轴等间距设置anchor,每个anchor在y轴上固定的K个坐标上预测:x坐标偏移和高度z,从而组成表示车道线一组三维坐标,另外每个anchor还预测一个置信度(表示anchor内是否有车道),所以预测数据维度为(2K+1)。对于每个anchor,网络输出最多三种类型的车道描述符(置信度和几何形状),前两种 (c1, c2)表示车道中心线,第三种类型(d)表示车道分隔符–表示实际的车道线。车道分隔符的拓扑通常比中心线更复杂,我们的表示不能捕获所有情况。
最终预测头的大小为:3 · (2 · K + 1) × 1 × N (N为anchor数量,K为y轴上设置预测点的数量)。最后的预测执行一个在目标检测中常见的一维非最大抑制:只保留局部置信度最大的车道(与左右邻居锚点相比)。每个剩余的车道,由少量(K)个3D点表示,使用样条插值转换为平滑曲线。
问:为什么需要c1,c2两个中心线?
答:为每个锚点分配两条可能的中心线可以为合并和分割提供网络支持,这通常会导致两条车道的中心线在某个点重合,并在不同的道路位置分离,如图3中最右边的示例所示。(个人认为一个anchor预测两个车道中心线一般会需要较大的横向偏移量预测值,会增加预测难度)
2.2.3 训练
在训练时间和评估中,如果整个车道没有在有效的俯视图图像边界内穿过 Y r e f Y_{ref} Yref,则忽略整个车道(个人认为没有穿过 Y r e f Y_{ref} Yref(图3中所示)就被忽略的做法不好);如果车道点被地形遮挡(即超出山顶),则忽略车道点。总体损失函数如下,置信度用交叉熵损失,其他用L1-Loss
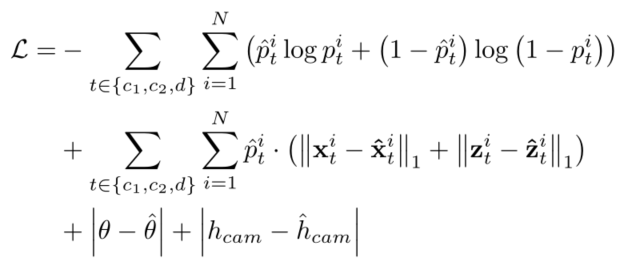
3 实验
3.1 评估指标
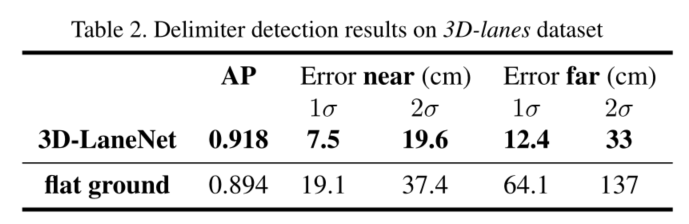
提出了一种三维车道检测的评估方法,该方法将检测精度与几何估计精度分开。检测精度通过精度-召回曲线的标准平均精度(AP)测量来计算。首先计算GT和检测车道之间的曲线距离,作为点向欧几里得距离的加权和。沿着曲线用一组预定义的y值测量距离,在0-80米范围内每80厘米测量一次,权重随距离衰减。然后,通过选择减少相似度的对来执行一对一(曲线)匹配。如果加权距离低于某个相当允许的阈值(1.5米),则认为匹配是正确的。通过对车道置信度阈值的迭代,生成精度-召回率曲线。
对于匹配上的预测结果,通过测量误差分布来评估几何估计精度 (点欧几里得距离)在相同的点上用于测量曲线到曲线的距离。由于误差大小的不同,将整个数据集进一步划分为近范围(0-30m)和远范围(30-80m)的车道点。然后计算每个范围的1σ误差,作为68%的误差和2σ误差作为95%误差。
3.2 部署细节
训练阶段真值如何匹配锚点:
- 将所有车道线以及车道中心线通过IPM投影到俯视图下;
- 在 Y r e f Y_{ref} Yref位置上将每条线匹配给 x x x方向距离最近的锚点线段;
- 对于每个锚点上匹配到的线,将最左边的车道线与中心线赋为 d , c 1 d,c_1 d,c1,如果还有其他中心线,则赋为 c 2 c_2 c2。
5.3 精度结果
仿真数据集:
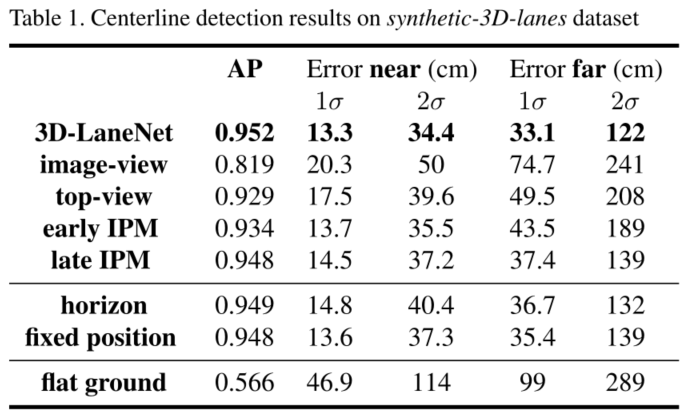
真实数据集:
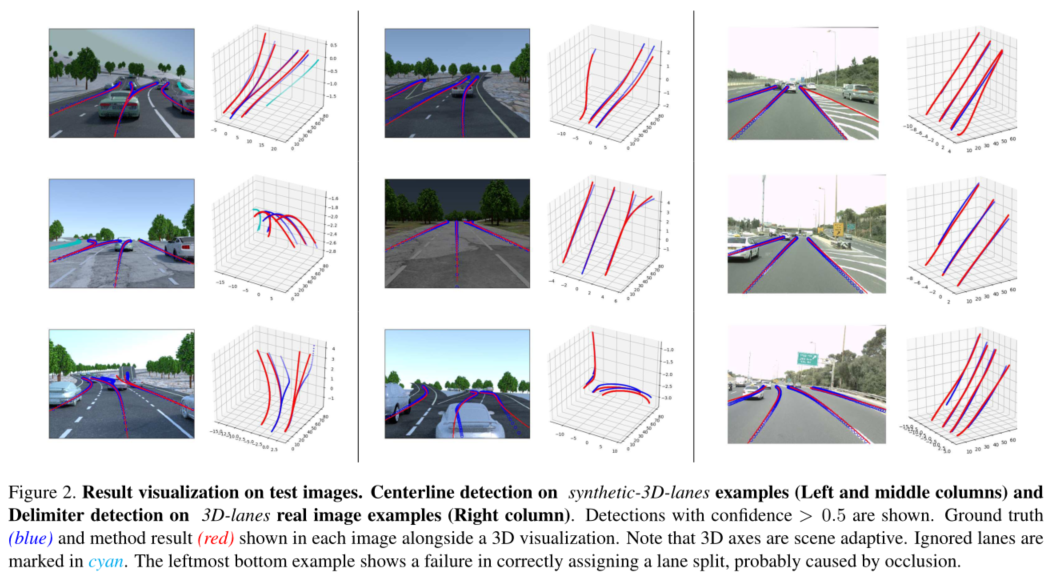
可视化结果:
4 分析
优点: 开创性工作
缺点:
2D和3D的几何先验过于简单,会引入明显的误差。
双通道并不是并行计算,要等最终的image-view预测结果出来后才能进行top-view通道预测。
Anchor的车道线表示不完善,如:
车道分隔符的拓扑通常比中心线更复杂,我们的表示不能捕获所有情况。
个人认为一个anchor预测两个车道中心线一般会需要较大的横向偏移量预测值,会增加预测难度。
不能预测垂直于车辆形式方向的横向车道。
可能的改进:
3D车道表示和效率,可参考后面的Gen-3DLaneNet\3DLaneNet+等。
参考文献
知乎:自动驾驶–车道线检测–3D-LaneNet: End-to-End 3D Multiple Lane Detection
CSDN: 3D-LaneNet: End-to-End 3D Multiple Lane Detection

