
- 1阿里云游戏服务器租用费用价格组成,费用详单
- 2ChatGPT训练三阶段与RLHF的威力_rlhf 是gpt3
- 32024-01-06-AI 大模型全栈工程师 - 机器学习基础
- 4python whl怎么安装_.whl文件在python库的安装
- 5在 iOS 上安装自定企业级应用
- 6迅为RK3588开发板ubuntu和window互传图形界面直接拖拽进行文件传输
- 7mybatis学习文档_unknown database 'mybatis
- 8wsl不动了,wsl2不动了。不响应_wsl 切换到 wsl2之后无法使用
- 9nodejs 解决前端跨域之后端访问第三方接口
- 10HttpRunner自动化之响应中文乱码处理
数字图像处理笔记_图像域r2
赞
踩
直方图处理
1、直方图均衡化
由像素级累积概率密度确定对应的新像素值
2、直方图规定化(直方图匹配)
寻找累计概率密度最相近的像素值作为新像素值
毕设项目演示地址: 链接
毕业项目设计代做项目方向涵盖:
目标检测、语义分割、深度估计、超分辨率、3D目标检测、CNN、GAN、目标跟踪、竞赛解决方案、人脸识别、数据增广、人脸检测、数据集、NAS、AutoML、图像分割、SLAM、实例分割、人体姿态估计、视频目标分割、Re-ID、医学图像分割、显著性目标检测、自动驾驶、人群密度估计、PyTorch、人脸、车道线检测、去雾 、全景分割、行人检测、文本检测、OCR、6D姿态估计、 边缘检测、场景文本检测、视频实例分割、3D点云、模型压缩、人脸对齐、超分辨、去噪、强化学习、行为识别、OpenCV、场景文本识别、去雨、机器学习、风格迁移、视频目标检测、去模糊、显著性检测、剪枝、活体检测、人脸关键点检测、3D目标跟踪、视频修复、人脸表情识别、时序动作检测、图像检索、异常检测等
滤波器
1、中值滤波器处理椒盐噪声优于均值滤波
2、拉普拉斯算子-二阶微分锐化:细节增强、孤立点检测
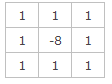
3、sobel算子-一阶微分锐化:边沿提取
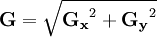
*一阶导与二阶导的异同
(1)一阶导数通常在图像中产生较粗的边缘(2)二阶导数对精细细节,如细线、孤立点和噪声有较强的响应(3)二阶导数在灰度斜坡和灰度令阶过渡处会产生双边缘响应(4)二阶导数的符号可用于确定边缘的过渡是从亮到暗还是从暗到亮。
4、自适应中值滤波-去除椒盐噪声,并且减少模糊失真【数字图像处理P210】
图像复原
1、radon变换(雷登、拉东变换)-由各个方向的投影反变换出原图【数字图像处理P235】【https://wenku.baidu.com/view/9cf5cc650812a21614791711cc7931b765ce7bbd.html】
*投影图像:图像域(x,y)->投影域(rho,theta){一次投影对应一个角度,投影域为二维,多个角度的投影域组合为三维}==一个三维->多个二维
由于rho,theta与x,y在笛卡尔坐标系中均表示直线,有对应的转换关系则->
*反投影:投影域(rho,theta)->图像域(x,y){保证角度不变,一个角度转换一个图层}==多个二维->多个三维->叠加为一个三维
多个不同角度投影图像的叠加得到最终的图像
四、哈尔(haar)小波变换----离散小波变换(DWT)
——图像分解为高频和低频信息,压缩图像并可完美重构还原
https://blog.csdn.net/baidu_27643275/article/details/84826773【小波变换入门----haar小波,1/sqrt(2)】
https://blog.csdn.net/mz5111089/article/details/78316587【Haar小波变换的推演说明,1/2】
形态学图像处理
1、孔洞填充
https://blog.csdn.net/du_shuang/article/details/82953444【形态学之孔洞填充】

X0是一幅纯黑图像只在孔洞处有一黑点
*缺点:初始点必须已知
2、凸壳——图形内任意两点的连线仍在图形内
3、细化——得到类似骨架【数字图像处理P417】
利用八个结构元对图像进行击中判定得到。类似逐步腐蚀,最后骨架是连续的。
粗化:可以先细化然后求补集得到。
4、骨架——最大圆盘法【数字图像处理P418】
由目标所有内切圆的圆心组成骨架,最终骨架多是断裂的。
5、形态学重建——测地膨胀(标记图像膨胀后再与模板图像求交集最终得到模板图像的一部分)
a、重建开操作【数字图像处理P422】
用结构元B腐蚀原图G后得到的图像作为标记图像F,再用B膨胀F,并与G交集,迭代至F不在变化为止,便可得到G中提取到的信息。
b、填充孔洞【数字图像处理P424】
上为标记图像F,原图I的补集为模板图像,测地膨胀后得到的图求补集得H,H为填充孔洞后的图。H与I的补集的交集为所有孔洞的图像。
c、边界清除——提取边界处的不完全文字
上为标记图像F,原图I为模板图像,操作与a相同,迭代完毕得到边界处文字,与原图求差,便可去掉边界文字。
灰度形态学——多使用平坦结构元(SE)【数字图像处理P428
a、膨胀——取局部最大值
突出亮细节,总体亮度变亮
b、腐蚀——取局部最小值
突出暗细节,总体亮度变暗
c、开运算——先腐蚀后膨胀
去除亮特征,不影响暗细节
d、闭运算——先膨胀后腐蚀
削弱暗特征,不影响亮细节
e、(白)顶帽变换——图像减去其开操作
用于矫正不均匀的光照。
f、(黑)底帽变换——闭操作减去图像
同e。e运用于暗背景上的亮物体,f运用于亮背景上的黑物体。
*二值图像有的全有,这里不一一列举
图像分割
1、canny边缘检测【数字图像处理P463】
https://www.cnblogs.com/techyan1990/p/7291771.html【边缘检测之Canny】
a、高斯滤波器平滑图像
b、计算梯度幅值图像和角度图像(sobel算子、Prewitt等)
c、非最大值抑制——去除粗边沿
1)将当前像素的梯度强度与沿正负梯度方向上的两个像素的梯度强度进行比较。
- 如果当前像素的梯度强度与另外两个像素的梯度强度相比最大,则该像素点保留为边缘点,否则该像素点将被抑制,即置位0。
在两个相邻像素之间使用线性插值来得到要比较的两个像素梯度强度(上述的两个梯度强度)
P 1 = E + ( N E − E ) ∗ t a n B = ( 1 − t a n B ) E + t a n B ∗ N E P1=E+(NE-E)*tanB=(1-tanB)E+tanB*NE P1=E+(NE−E)∗tanB=(1−tanB)E+tanB∗NE
d、双阈值检测——去除由噪声产生的边缘
如果边缘像素的梯度值高于高阈值,则将其标记为强边缘像素;必定为边缘
如果边缘像素的梯度值小于高阈值并且大于低阈值,则将其标记为弱边缘像素;边缘待定
如果边缘像素的梯度值小于低阈值,则会被抑制。必定不是边缘
e、抑制孤立低阈值点——连接边缘
查看弱边缘像素及其8个邻域像素,只要其中一个为强边缘像素,则该弱边缘点就保留为真实的边缘
2、边缘连接与检测——解决边缘断裂问题【数字图像处理P468】
a、局部处理的边缘连接【468】
将领域内梯度幅值相近、梯度角度相近的两点认为是同一边界连接起来。简单常用
b、用多边形近似连接边缘???【470】
也算较为常用
c、利用霍夫变换的全局处理连接断裂【475】
多用于查找图像中的直线。
找到拟合直线中的所有点后,判定所有非连续点的距离是否小于阈值,若小则连接两点,达到补全缝隙的目的。
3、利用边缘改进的全局阈值处理——利用边缘图像计算阈值:用于关注点在边沿的情况【数字图像处理P484】
首先对图F利用sobel或拉普拉斯获得边缘图;使用阈值分割保留强边缘的二值图像G;G*F=H只保留原图边缘信息;利用H的直方图计算Otsu阈值T;使用T对F进行全局分割。
4、移动平均确定阈值——本质属于局部阈值(用于文档扫描)【数字图像处理P491】
对点A,阈值T=bM,M是A前n点(包含A)灰度的平均值,b为常数可设为0.5。A则根据T进行二值化。
多用于感兴趣的物体尺寸与整个图像尺寸相比较小的情况。
5、多阈值处理——类比Otsu【数字图像处理P487】
类间方差公式变为
只是多了最后一项。两个阈值k1、k2的迭代方法:先定义k1,k2从k1+1增加到255计算类间方差;然后k1加1,循环往复。取类间方差最大对应的k1,k2,如果有多组最大值,则取k的平均。
6、分水岭算法——边界提取【数字图像处理P500】
https://blog.csdn.net/ChangWei_wenzhou/article/details/83583230【分水岭算法的个人理解】
图像的表征
1、图像的各阶矩——零阶矩、一阶矩、二阶矩、(三阶矩)【数字图像处理P542】
零阶矩求面积、一阶矩确定重心、二阶矩确定主方向、二阶矩和三阶矩(其实是归一化后的中心矩,前面的都是原点矩)可以推导出七个不变矩【https://blog.csdn.net/yang6464158/article/details/42459595空间矩算子特征矩一阶矩二阶矩中心矩重心目标方向】
二阶中心距意味着方差,归一化后可用于判定曲线弯曲程度。【https://blog.csdn.net/libing_zeng/article/details/74905378零阶矩、一阶矩、二阶矩、三阶矩】
一个图像可以用不变矩的值来代表,达到图像类别的识别。
2、主成分分析重构图像——降维【数字图像处理P547】
该页描述了协方差矩阵各个元素的意义:两个元素间的相关性和单个元素的方差。
特征描述子
- HOG(梯度方向直方图)特征检测
计算每个像素的梯度图,使用sober算子卷积即可——取88像素作为一个cell,对cell内的像素梯度信息计算其直方图,如角度划分为9个,将cell内所有像素梯度方向为该角度的梯度值累加得到该角度的值,即横坐标为9个梯度的角度,纵坐标为该梯度方向梯度的累加值——然后将这9个累加值排列为一维向量,作为该cell的特征—取去22的cell作为一个black,black为滑窗,步长为一个cell,将4个cell的特征首尾相接串联成136的向量,进行归一化*,即为每个black的特征——滑动全图后,将左右black的特征串联得到的向量即为整幅图片的hog特征——输入SVM进行分类
- 马氏距离
将各个特征进行归一化,属于标准化后的欧氏距离,方便比较
- haar(-like)特征
https://blog.csdn.net/u013403054/article/details/78461083【目标检测算法-特征提取之(一)Haar特征】
haar模板单个特征值计算:模板内白色区域像素和-黑色区域像素和
使用最小像素大小的模板(如x1模板为1,2)以步长为1扫描全图,然后单独整数放大模板某一边扫描全图,直到模板与原图一样大。最终得到了该图的x1系列特征。换一个模板则可以得到另一系列特征。
目标检测
- HOG+SVM或者Haar+AdaBoost检测
都只是分类器,要实现目标检测(如人脸检测):检测框长宽比依据人脸设置,然后按一定比例放大或缩小得到多个尺寸的检测框,将检查框不断滑动,步长固定,逐个识别检测框中的图片是否为人脸。类似RCNN
- 选择性搜索(Selective Search)——RCNN使用
运用区域生长的方法:将图像分割为多个小块,根据每个小块的特征(纹理等)进行区域的合并,合并的同时得到对应的外界矩形。最终得到一幅图的所有候选框。
- 传统滑动窗口检测(Sliding Window)
使用设定好的大小尺寸不同的窗口,以设定步长在图中滑动,每个窗口都进行类别检测,扫描全图后便得到最有可能存在目标的框。
缺点:窗口过多,逐个检测,运算量过大;得到的目标框也是固定的,无法适应任意形状的物体。
分类器
AdaBoost算法——集成学习、迭代算法
https://www.cnblogs.com/davidwang456/articles/8927029.html【手把手教你实现一个 AdaBoost】
https://www.cnblogs.com/zyly/p/9410563.html#_label4【第九节、人脸检测之Haar分类器——涉及到AdaBoost级联分类器】
-
多个弱分类器(accuracy=0.6~0.8)组合为一个强分类器
-
步骤:
-
- 选择最优弱分离器f1。将所有样本的同一个特征(只有一个值)由大到小排序,遍历所有阈值(最大特征与最小特征值之间,阈值为相邻两个特征的一半。如1,2取1.5),以最小分类误差对应的阈值作为该次最优弱分离器。输入:所有样本的某一个特征+标签。中间量:分类误差sigma。输出:最优弱分离器。
- 计算分离器权值 α 1 \alpha_1 α1,更新样本权值D。
- 同a计算下一个最优弱分离器。循环ab得到设定个数的最优分离器。
- 最终的强分离器为 α 1 ∗ f 1 + … … + α n ∗ f n \alpha_1*f_1+……+\alpha_n*f_n α1∗f1+……+αn∗fn
-
2.a是弱分类器的训练方法。2是强分类器的步骤。即强分类器步骤中包含弱分离器的构造。
-
与haar结合进行人脸识别
-
-
强分类器构造:(默认haar特征有78 460个)
-
-
构造78 460个最优分离器,选择分类误差最小的T个特征。
-
按2中所述构造T个强分类器
-
将T个强分类器进行级联得到最终的分类模型
-
- 级联:将多个强分类器连接成决策树形状。
-
-
- 概率霍夫变换
1、随机选取前景点进行霍夫变换
2、若有点达到最小投票数,则拟合该直线L,并记下此时的点A
3、由该点开始向直线两端搜索剩余前景点中在该直线上的点,对于点线距离较小,且相邻点间距离较小的点,连接为线段。(是一直搜索到图像边缘,找出L上的所有点,即一条L可以得到多个线段)(可以看做:做与L平行的两条线,去除两线间的点)
-
- 个别情况,通过霍夫提取大致直线(滤除噪点),由直线周围的点使用最小二乘拟合更加精确的线。
-
Harris角点检测
https://www.cnblogs.com/jiahenhe2/p/7930802.html【Harris角点检测原理详解】
原理:以一个划窗判定滑动前后对应各点的离散程度,即点像素值差值平方和E,各个方向的E都大才行。
具体实施:求出每个点的x和y方向的梯度Ix、Iy,由梯度计算出他们的自相关矩阵M,M的特征值lamda1、2则反映了其在x,y方向的离散程度,lamda越大则认为该方向像素方差越大,即梯度值越大,变化越剧烈,因此lamda1、2都很大,则认为是角点。使用R=det M+k(traceM)^2来评估lamda1与2是否同时大
- 点线距离计算公式
https://blog.csdn.net/love_phoebe/article/details/81112531【点到线段的距离 计算几何】
- ZCA白化处理(PCA的进一步处理)
https://www.cnblogs.com/rong86/p/3559137.html【白化(预处理步骤)【转】】https://blog.csdn.net/u014061630/article/details/80677071【机器学习中的白化处理】
-
-
去除数据中冗余的信息;如图像中的相邻像素具有很强的相关性,则其具有较多的冗余信息。
-
训练前可作为预处理,减少训练所需数据量。
-
步骤:
-
-
PCA降维得到映射矩阵U转置,U是特征向量组成,UX得到新坐标系下的坐标X1;
-
对坐标进行标准差归一化X2=X1/std(X1),使得各维度坐标范围一致;
-
再映射回原空间,映射矩阵为U,得到最终的结果。
-
注:U还是U转置不必计较,只知道他们是转置(逆)关系即可。
-
- 归一化/标准化:原数据-均值/标准差。使数据满足正态分布,均值为0,标准差为1。这里因为只需要设定范围,则没有减均值。
-
-

