
热门标签
热门文章
- 1Docker的原理,总结的真的全呀_docker原理
- 2Unity解决TextMeshPro中文乱码,快速生成TextMeshPro能用的中文字体_unity textmesh pro字体制作
- 3最近三年的百度产品经理面试与笔试题完整版_在你平时网络购物过程中,是否存在某种需求未被满足或者没有被满足好?
- 4pyinstaller把Python脚本打包成exe可执行文件_pyinstaller打包的py会创建外部目录的文件,可执行exe需要其他文件夹的文件,无
- 5[HTML]Web前端开发技术21(HTML5、CSS3、JavaScript )HTML5 基础与CSS3 应用,border-radius,box-shadow,transform——喵喵画网页
- 6TCP 和 UDP的区别_tcp和udp的区别
- 7逆向工程入门学习(FreeBuf)_.o 文件逆向工程
- 8工具推荐 |Devv.ai — 最懂程序员的新一代 AI 搜索引擎_devv.ai访问不了
- 9服务降级 & 熔断机制
- 10什么是devops,基于Gitlab从零开始搭建自己的持续集成流水线(Pipeline)_gitlab auto devops
当前位置: article > 正文
【python机器学习】中文情感分析_python 中文情感分析
作者:IT小白 | 2024-02-09 19:29:31
赞
踩
python 中文情感分析
3月31日,3月最后的一天接到了腾讯HR终面,看着招聘官网变成已完成还有点小自豪呢

然后百度搜了搜显示“已完成”是不是稳了,原来不是,好多最后被通知没被录取。。。。

随缘吧~代码还要继续码,博客还要继续更,论文还要继续写。。。。。
数据源
公众号文章:Python有趣|中文文本情感分析
罗罗攀在里面有发数据,大家以后可以跟着他的公众号进行学习,非常适合我这种小白哈哈哈哈哈哈
这是大众点评上的评论数据(王树义老师提供)
原始数据
import pandas as pd
import csv
import numpy as np
data = pd.read_csv(r'C:\Users\xuxiaojielucky_i\Desktop\data1.csv',encoding='utf-8')
data.head()
- 1
- 2
- 3
- 4
- 5

情感分析——分类
可以看到数据中有一列是平分(star)数据,我们看先这个数据有哪些分值。可以看到分值有1,2,4,5四中等级。
data['star'].unique()
- 1
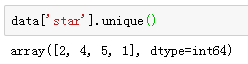
对数据进行标注,我们假定分数小于3的为消极并标注为0,大于3的分数为积极并标注为1,通过1和0 对数据进行分类,因此我们定义一个函数,用apply方法得到一个新的列(分类的列)。
def make_label(star):
if star > 3:
return 1
else:
return 0
data['setiment'] = data.star.apply(make_label)
data.head()
- 1
- 2
- 3
- 4
- 5
- 6
- 7

snownlp
python最强大的地方就是第三方库,其实有现成的库可以直接对文本进行情感分析,如snownlp,直接调用返回的是积极情绪的概率,我们来调用一下吧~
import snownlp
text1 = '我的卷发棒在哪?'
text2 = '你的卷发棒就棒在十分撑托你的美!'
s1 = Snownlp- 1
- 2
- 3
推荐阅读
相关标签

