
- 1Linux入门之使用 dmesg 查看引导日志_dmesg日志在哪里
- 2windows环境下无法默认git运行.sh文件,选择在git中直接运行_sh脚本默认变成git的图标了
- 3STM32发生HardFault_Handler错误的查找方法_hardfault_handler的上一步
- 4R语言数据可视化之图形参数修改_图形参数"pin"的值设得不对
- 5bat文件批量打开应用程序/快捷方式_批量打开软件批处理
- 6使用virt-install手动创建qcow2镜像并安装ISO_virt-manager找不到本地镜像
- 7【服务器数据恢复】DELL Eq PS系列服务器硬盘坏道的数据恢复案例_eqps
- 8R语言ggplot2中的theme函数_r语言theme函数
- 9【半月刊 4】前端高频面试题及答案汇总
- 10【浅谈MySQL数据目录】Ubuntu安装Mysql8服务器,相关数据目录介绍_ubuntu18.04安装mysql8时指定数据目录
[深度学习论文笔记]TransUNet: Transformers Make Strong Encoders for Medical Image Segmentation
赞
踩
[深度学习论文笔记] TransUNet: Transformers Make Strong Encoders for Medical Image Segmentation
TransUNet:用于医学图像分割的Transformers强大编码器
论文:https://arxiv.org/pdf/2102.04306
代码:https://github.com/Beckschen/TransUNet
发表时间:Feb 2021
一、基本介绍
1.1问题动机
医学图像分割是开发医疗保健系统(尤其是疾病诊断和治疗计划)的必要先决条件。在各种医学图像分割任务中,U形架构(U-Net)已成为事实上的标准,并取得了巨大的成功。但是,由于卷积运算的固有局部性,U-Net通常在明确建模远程依赖关系方面显示出局限性。设计用于序列到序列预测的Transformer,已经成为具有先天性全局自注意力机制的替代体系结构,但由于low-level细节不足,可能导致定位能力受到限制。
1.2 TransUnet
而TransUnet,它同时具有Transformers和U-Net的优点,是医学图像分割的强大替代方案。一方面,Transformer将来自卷积神经网络(CNN)特征图的标记化图像块,编码为提取全局上下文的输入序列。另一方面,解码器对编码的特征进行上采样,然后将其与高分辨率的CNN特征图组合以实现精确的定位。作者认为,借助U-Net的组合,通过恢复局部的空间信息,可以将Transformers用作医学图像分割任务的强大编码器。
二、网络结构
2.1 解决思路
卷积神经网络(CNN),尤其是全卷积网络(FCN),已在医学图像分割中占主导地位。 在不同的变体中,由具有跳跃连接的对称编码-解码结构组成的U-Net,以增强细节保留,成为最佳的选择。 基于这种方法,已在广泛的医学应用中取得了巨大的成功,例如磁共振(MR)的心脏分割,CT图像的器官分割和息肉结肠镜检查视频分割。
尽管基于卷积神经网络的方法具有出色的表现能力,但由于卷积运算的内部局限性(在建模显示长距离关系方面仍存在局限性)。因此,这些体系结构通常产生较弱的性能,特别是对于结构纹理,形状和大小方面表现出较大差异的患者。为了克服这一局限性,就提议基于CNN特征建立self-attention机制。另一方面,为序列到序列预测而设计的Transformer已经出现,作为一种替代体系结构,它完全采用了分配卷积运算,而仅依赖于注意力机制。与以前的基于CNN的方法不同,Transformer不仅在建模全局上下文方面功能强大,而且在大规模的预训练下对下游任务也显示出卓越的可传递性。
在本文中,作者在医学图像分割的背景下探讨了Transformer的潜力。 但是,有趣的是,作者发现单纯的使用Transformer对标记化的图像块进行编码,然后直接将隐藏的特征表示 上采样为完整分辨率的密集输出,无法产生令人满意的结果。
这是由于Transformer将输入视为一维序列,并且只专注于在所有阶段建模全局上下文,因此会产生缺乏详细定位信息的低分辨率特征。而且,该信息不能通过直接上采样到全分辨率来有效地恢复,因此导致粗略的分割结果。 另一方面,CNN架构(例如,U-Net)提供了提取低low-level visual线索的途径,可以很好地弥补此类精细的空间细节。
2.2主要方法
为此,作者提出了一个医学图像分割框架TransUNet,它从序列到序列的预测角度建立了self-attention机制。为了弥补Transformer带来的特征分辨率的损失,TransUNet采用了CNN-Transformer混合结构,以利用来自CNN特征的详细高分辨率空间信息以及Transformer编码的全局上下文。受U-Net设计的启发,然后就对Transformer编码的自注意特征进行上采样,以此与从编码路径中跳过的不同高分辨率CNN特征结合,以实现精确的定位。这种设计使框架能够保留Transformer的优势,也能有益于医学图像分割。实证结果表明,与以前的基于CNN的自注意方法相比,基于Transformer的体系结构提供了一种更好的利用自注意的方法。大量的实验证明了TransUNet在各种医学图像分割任务上相对于其他竞争方法的优越性。
2.3结构详解
①如何直接应用Transformer对来自分解后的图像块的特征表示进行编码?
图像序列化:
首先通过将输入x,整型为一系列平坦的2D补丁序列来执行标记化,其中每个patch的大小是P×P,N= HW/P^2 是图像patch的数量(即输入序列长度),其中,每个patch的尺寸是图像块的数目(即输入序列长度)
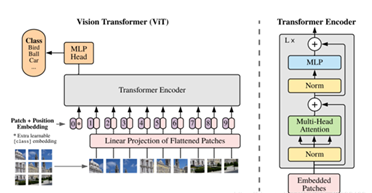
②(a)Transformer层示意图 (b)拟议的跨网结构
给定图像x∈R^(HWC),其空间分辨率为HW,通道数为C。目标是预测相应像素大小为HW的标签图。最常见的方法是直接训练CNN(例如U-Net),首先将图像编码为高级特征表示,然后将其解码回完整的空间分辨率。 与现有方法不同,作者的方法通过使用Transformer将self-attention机制引入编码器设计。
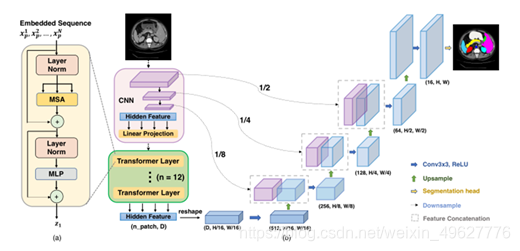
③为了分割的目的,一个直观的解决方案是简单地将编码的特征表示z_L∈R(Hw/p2 D)上采样到全分辨率,以预测密集输出。 在这里,为了恢复空间顺序,编码特征的大小应该首先从 HW/P^2
变成H/PW/P。使用11卷积 以将重新成形的特征的通道尺寸减少到类的数量,然后将特征图直接上采样到全分辨率HW,用于预测最终的分割结果。
虽然将Transformer与传统上采样相结合已经产生了合理的性能,但如上所述,这种策略并不是Transformer在分割中的最佳使用,因为H/PW/P 通常比原始图像分辨率HW小得多,因此不可避免地导致低分辨率细节的丢失(例如器官的形状和边界)。
④因此,为了补偿这种信息损失,TransUnet采用了一种混合的CNN-Transformer体系结构作为编码器以及级联上采样,以实现精确的定位。其中CNN首先用作特征提取器,为输入生成特征图。patch嵌入应用于从CNN特征图而不是从原始图像中提取的1 * 1 patch。选择这种设计是因为:首先,它允许在解码路径中利用中间高分辨率CNN特征图;其次,作者发现混合CNN-Transformer编码器比简单地使用Transformer作为编码器表现更好。
⑤级联上采样:(CUP)
它由多个上采样步骤组成,用于解码隐藏特征,以输出最终的分割Mask。在对隐藏特征z_L∈R(HW/p2 D)的序列整形为H/PW/PD之后,通过级联多个上采样块来实现CUP,达到全分辨率从H/PW/P到H*W,其中每个块依次包括2X上采样、一个3×3卷积层和一个ReLU层。可以看到,CUP与混合编码器一起形成了一个u形架构,它通过跳跃连接支持不同分辨率级别的功能聚合。
三、网络模型主要应用及结果
4.1 实验中使用的分割数据集
两个数据集:
①Synapse multi-organ segmentation dataset
腹部CT扫描 (30次腹部CT扫描 总共有3779张轴向增强腹部临床CT图像)
每个CT体由512 *512像素的85198切片组成,体素空间分辨率([0.540.54]×[0.980.98]×[2.55.0]) mm^3。报告了8个腹部器官(主动脉、胆囊、脾、左肾、右肾、肝、胰腺、脾、胃)的平均Dice和平均豪斯多夫距离(HD),随机分为18个训练病例(2212个轴向切片)和12个验证病例。
②Automated cardiac diagnosis challenge
心脏CMR(心脏核磁)
一系列短轴切片从左心室底部到顶部覆盖心脏,切片厚度为5至8毫米。短轴平面内空间分辨率从0.83到1.75 mm^2/pixel。每个患者扫描都用手工标注了左心室(LV)、右心室(RV)和心肌(MYO)。报告了平均Dice,随机分为70个训练病例(1930个轴向切片),10个用于验证,20个用于测试。
4.2主要结果
在Synapse多器官CT数据集(腹部)上的比较(平均dice分数%和平均豪斯多夫距离,单位为毫米,以及每个器官dice分数%)。
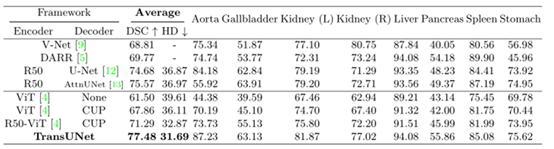
①验证CUP解码器的有效性,使用ViT作为编码器,并分别使用None和CUP作为解码器比较结果;
②为了证明混合编码器设计的有效性,使用CUP作为解码器,并分别比较使用ViT和R50-ViT作为编码器的结果。
③为了R50-ViT-CUP和TransUNet进行比较,也用ImageNet预训练的ResNet-50替换了U-Net和AttnUNet的原始编码器。
与现有技术相比,提出的TransUNet有显著的改进,例如,平均Dice性能增益从1.91%到8.67%。其中,直接使用Transformer进行多器官分割的结果比较合理(ViT-CUP有67.86%的DSC),但不能与U-Net或AttnUNet的性能相比较。这是由于Transformer可以很好地捕捉高级语义,这有利于分类任务,但缺乏低层线索分割医学图像的良好形状。另一方面,将Transformer与CNN结合,即R50-ViT CUP,其性能优于V-Net和DARR,但仍然不如纯基于CNN的R50-U-Net和R50-AttnUNet。最后,通过跨接结合U-Net结构,提出的TransUNet达到了最新的水平,比r50 - vit - cup和之前最好的R50-AttnUNet分别高出6.19%和1.91%,表明TransUNet具有较强的高层语义特征和低层细节的学习能力。这是医学图像分割的关键。在平均豪斯多夫距离上也可以看到类似的趋势,这进一步证明了TransUNet相对于这些基于cnn的方法的优势。
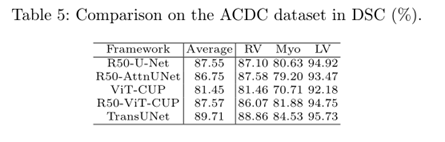
4.3视觉比较
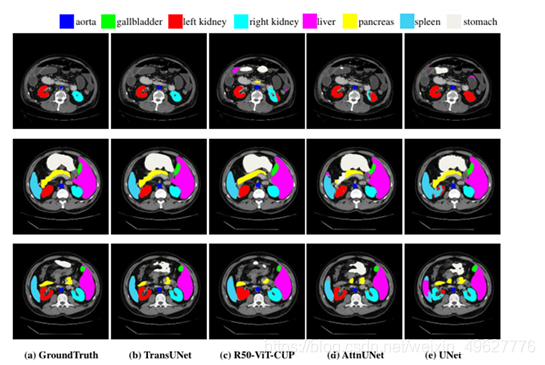
心脏数据集结果比较:
4.4消融实验
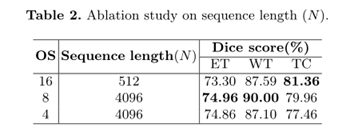
①序列长度消融实验
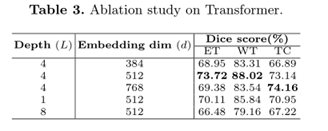
②Transformer位置的消融实验(下采样四次效果最好)
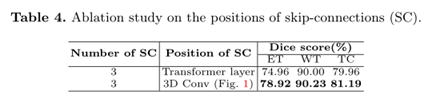
③跳跃连接位置的消融研究
六、个人思考总结
总结:
Transformer是一种天生具有强大自我注意机制的解构。在这篇论文中,作者研究Transformer在一般医学图像分割中的应用。为了充分利用Transformer的力量,提出了TransUNet,它不仅将图像特征作为序列来编码强全局上下文,还通过Unet混合网络设计来很好地利用低层CNN特征。TransUNet可作为一种替代框架用于医学图像分割,其性能优于各种竞争方法,包括基于cnn的自我注意方法。

