
热门标签
热门文章
- 1关于郑州大学校园网锐捷客户端禁止热点分享,禁止多网卡的解决办法_禁止热点共享
- 2playwright基础教程_playwright教程
- 3opencv训练自己的xml分类器以及如何获取opencv_createsamples.exe和opencv_traincascade.exe
- 4修改Windows中 pip 的缓存位置与删除 pip 缓存_pip config set global.cache-dir
- 5深度学习在图像检索的应用_互联网带来的大数据很大程度上缓解了模型训练过拟合的问题
- 6Java常见跳出循环的4种方式总结、switch中的break与return、lamada表达式中foreach如何正确选择退出方式_java switch return
- 7论文笔记 P-Tuning v2 与微调性能相等的提示性优化_ai pq tuning
- 8华为鸿蒙技术——应用程序包_鸿蒙 hap 安装包结构
- 9OpenHarmonyOs / LiteOs-a 应用开发_liteos 应用程序
- 10手把手教你安装苹果官方转译工具Game Porting Toolkit ,用Mac轻松玩转windows以及3A大作_mac游戏转译
当前位置: article > 正文
51-17 视频理解串讲— MViT,Multiscale Vision Transformer 论文精读_mvit视频模型
作者:Monodyee | 2024-03-13 01:12:36
赞
踩
mvit视频模型
继TimeSformer模型之后,咱们再介绍两篇来自Facebook AI的论文,即Multiscale Vision Transformers以及改进版MViTv2: Improved Multiscale Vision Transformers for Classification and Detection。
本文由深圳季连科技有限公司AIgraphX自动驾驶大模型团队编辑。如有错误,欢迎在评论区指正。由于本司大模型组最近组织阅读的论文较多,为理清相互之间的脉络,画草图如下 <->
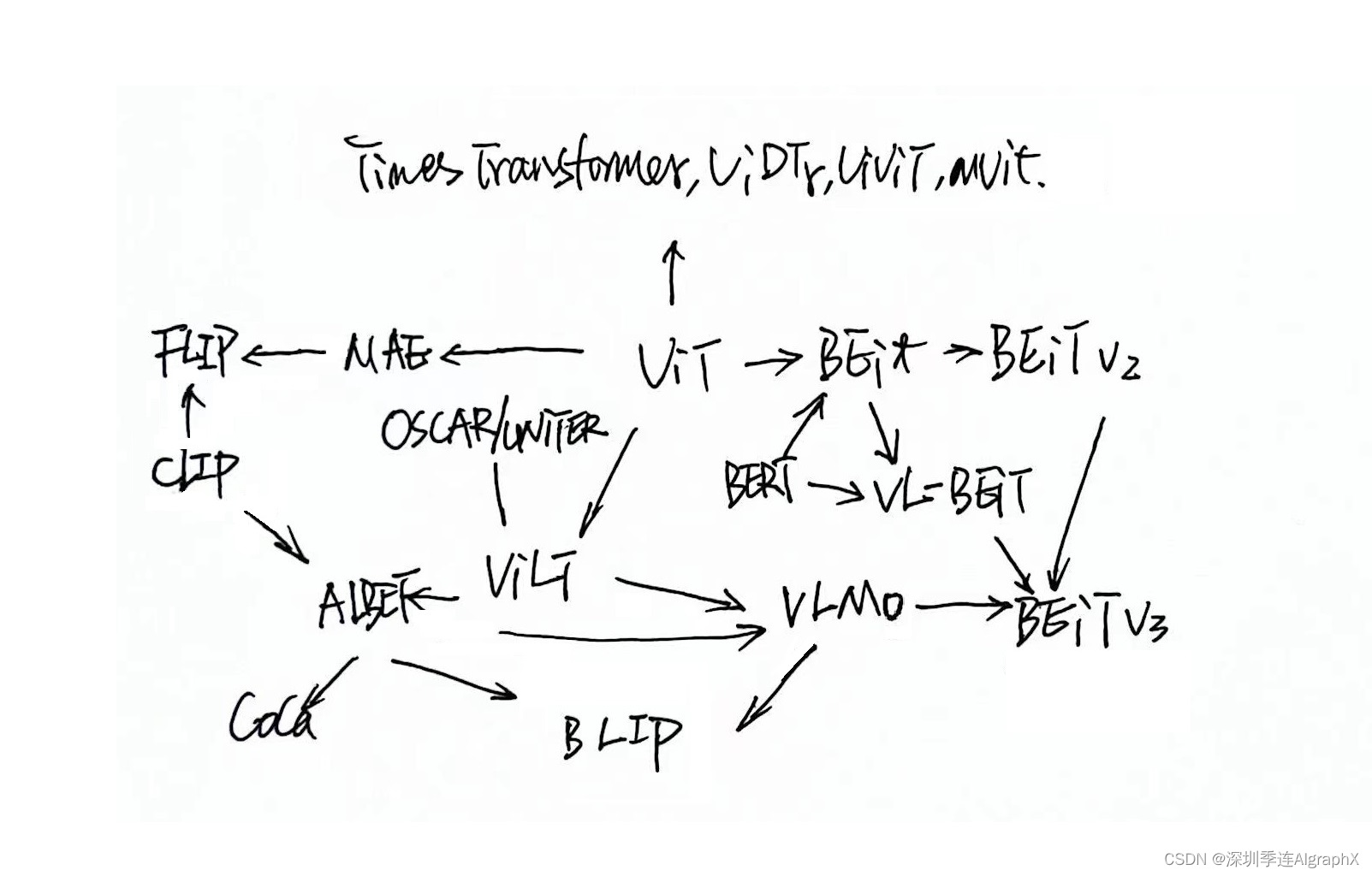
MViT,Multiscale Vision Transformers
MViT就是Transformer和多尺度分层建模相融合的产物。
Abstract
通过将多尺度、层次性特征的开创性思想与transformer模型联系起来,我们提出了用于视频和图像识别的多尺度视觉transformer,MViT。多尺度transformer有几个channel-resolution扩展过程。从输入分辨率和一个小的通道维度开始,每个stage分层地扩展通道容量,同时降低空间分辨率。这创建了一个多尺度的特征金字塔,其中早期的层以高空间分辨率运行,以模拟简单的低层次视觉信息,而更深的层则有空间粗糙但复杂的高维特征。我们评估了先前基础架构,它们为密集性质的视觉信号建模,用于各种视频识别任务。在这些任务中,并发vision-transformer依赖大规模外部预训练,并且在计算和参数方面成本高出MViT 5-10倍。我们进一步消除了时间维度,并将我们的模型应用于图
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/Monodyee/article/detail/227027
推荐阅读
相关标签

