
热门标签
热门文章
- 1面试了几十家,整理出这份车载测试面试题
- 2【Solidity】智能合约案例——②供应链金融合约_智能合约经典案例
- 3【微服务安全】OpenID Connect 简介:现代应用程序的身份验证
- 4guid oracle 生成不重复_详解oracle数据库唯一主键SYS_GUID()
- 5【MySQL】对表中数据的操作_mysql的insert into
- 6数据挖掘与机器学习
- 7海外版华为手机安装谷歌框架(也适用于国内任意机型)_海外版华为能使用谷歌吗
- 8Arduino与Proteus仿真实例-电子相册仿真_9341仿真
- 9adb install 指定设备安装
- 10手把手教你用Python爬取某网小说数据,并进行可视化分析_爬虫可视化怎么实现
当前位置: article > 正文
大语言模型总结整理(不定期更新)
作者:Monodyee | 2024-04-14 18:30:21
赞
踩
大语言模型总结整理(不定期更新)
《【快捷部署】016_Ollama(CPU only版)》 介绍了如何一键快捷部署Ollama,今天就来看一下受欢迎的模型。
| 模型 | 简介 |
|---|---|
| gemma | Gemma是由谷歌及其DeepMind团队开发的一个新的开放模型。参数:2B(1.6GB)、7B(4.8GB) |
| llava | LLaVA是一种多模式模型,它结合了视觉编码器和Vicuna,用于通用视觉和语言理解,实现了模仿多模式GPT-4精神的令人印象深刻的聊天功能。参数:7B(4.7GB)、13B(8.0GB)、34B(20GB) |
| qwen | Qwen是阿里云基于transformer的一系列大型语言模型,在大量数据上进行预训练,包括网络文本、书籍、代码等。参数:0.5B、1.8B、4B (default)、7B、14B、 32B (new) 、 72B |
| llama2 | Llama 2由Meta Platforms发布。该模型默认情况下支持4096的上下文长度。Llama 2聊天模型根据超过100万条人工注释进行了微调,专为聊天而设计。参数:7B(3.8GB)、13B(7.4GB)、70B(39GB) |
| deepseek-coder | DeepSeek编码程序是从零开始训练的87%的代码和13%的英语和中文自然语言。每个模型都在2万亿个tokens上进行了预训练。参数:1.3B(0.8GB)、6.7B(3.8GB)、33B(19GB) |
| yi | 零一万物出品参数:6B(3.5GB)、34B(19GB) |
| phi | 由微软研究公司开发的2.7B语言模型,展示了卓越的推理和语言理解能力。参数:2.7B(1.6GB) |
| THUDM/GLM系列 | 智谱清言,https://chatglm.cn,知名的ChatGLM-6B、GLM-130B,以及最新的ChatGLM3-6B |
| nomic-embed-text | 大上下文嵌入模型 |
| grok-1 | Grok-1,马斯克xAI,314B,这个的使用门槛就比较高了。 |
点击模型文字,进入ollama library。选择对应的模型,就可以看到下载的命令。
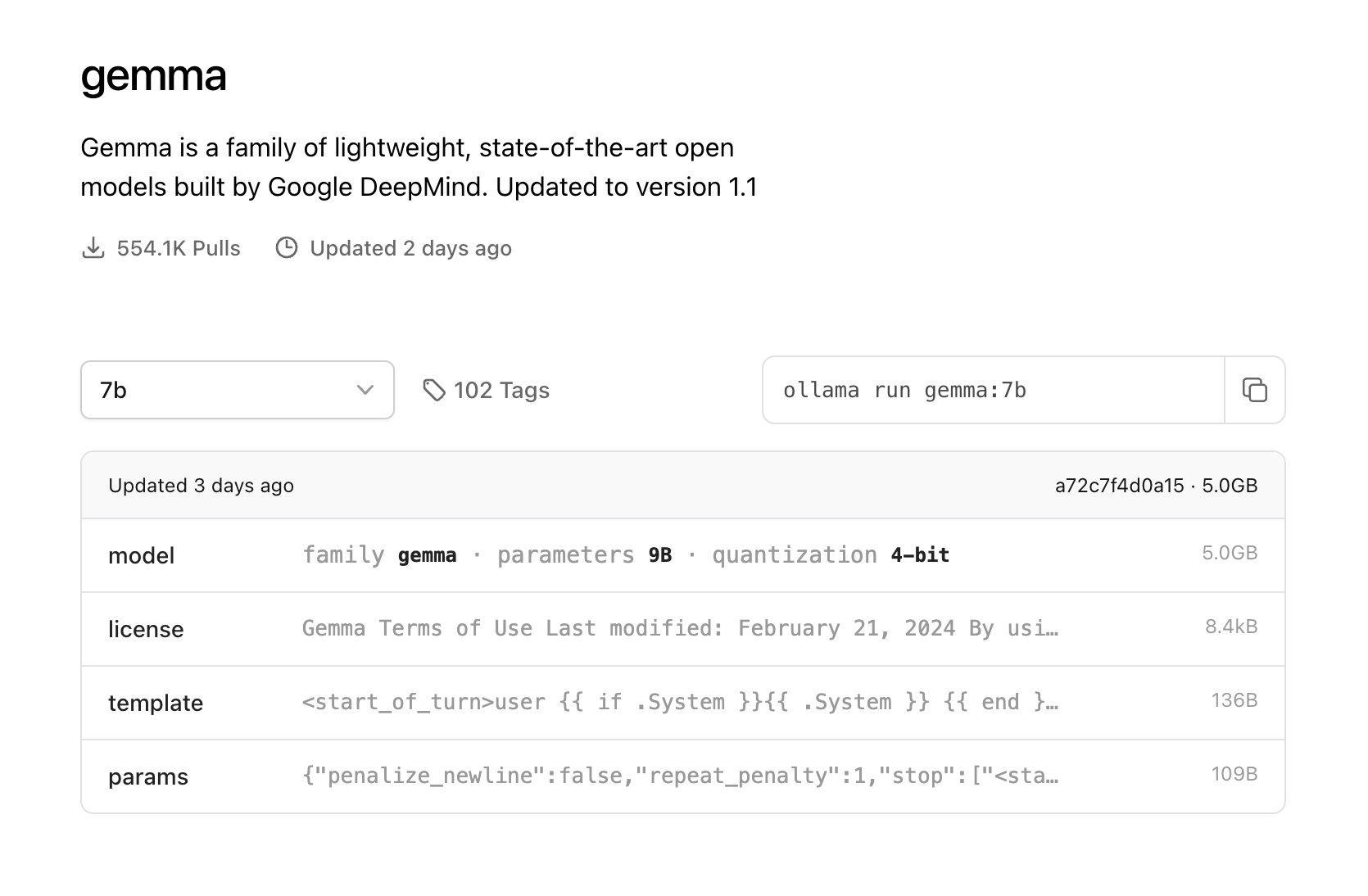
注意:运行7B模型至少需要8 GB RAM, 13B 模型至少需要16 GB RAM, 33B 需要 32 GB。
更多模型请参见:
https://ollama.com/library
https://huggingface.co/models
大模型榜单:https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard
往期精彩内容推荐
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/Monodyee/article/detail/423543
推荐阅读
相关标签
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

