
- 1555555555555
- 2【Java探索之旅】用面向对象的思维构建程序世界
- 3这个AI算法,可以帮“元宇宙”虚拟人进行虚拟更换衣服_ai虚拟换衣
- 4Getting Started Guide for Linux(3)编译DPDK_linux下编译dpdk api
- 5合合信息Embedding模型获得MTEB中文榜单第一_c-mteb
- 6Redis 学习笔记(七)-- Redis 持久化_java将redis键值对存储到磁盘
- 7[iOS]Xcode15.1编译报错Command PhaseScriptExecution failed with a nonzero exit code_xcode 15 command phasescriptexecution failed with
- 8在vue和小程序中使用腾讯实时音视频RTC(小程序端)_腾讯实时音视频 vue和小程序不在同一个环境
- 9【Android9】cm311-5 zg/yst 2+8 国科6323 已root乐家桌面卡刷包免拆禁休眠适合跑助手_cm311-5zg刷机包
- 10idea git窗口中没有Local Changes 解决方法及其他问题_idea local changes
数仓、数据湖、湖仓一体、数据网格的探索与研究_湖仓架构 数据网格架构 无服务器数据架构 图数据架构 边缘数据架构
赞
踩
整理不易,转发请注明出处,请勿直接剽窃!
点赞、关注、不迷路!
摘要:了解每一代数据存储的定义、数据类型、功能、总结。
第一代:数据仓库
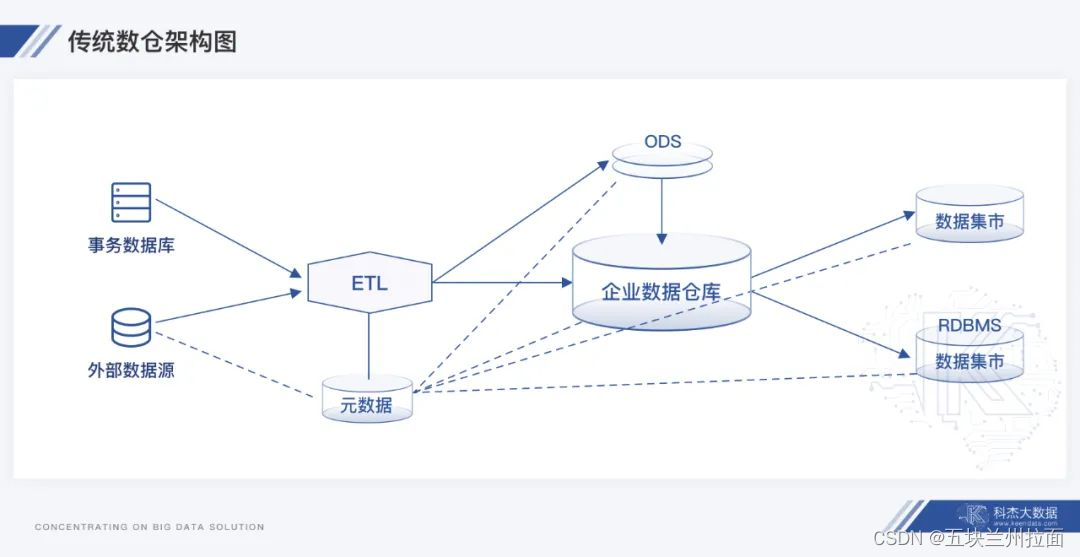
定义
为解决数据库面对数据分析的不足,孕育出新一类产品数据仓库。数据仓库(Data Warehouse)是一个面向主题的、集成的、相对稳定的、反映历史变化的数据集合,用于支持管理决策和信息的全局共享。
数据类型
功能
数据仓库对于数据的处理可分为数据集成(装载)、数据加工(ETL)、数据汇聚、数据展示及挖掘。数据经过这一过程,被抽取到数据仓库中,并严格按照预先定义的模式被装载进来,经过多层加工形成数据集市,并最终提供给终端应用或进一步供挖掘使用,主要场景包括编制报表、发布下游数据集市(Data Marts),以及支持自助式商业智能等。
数据仓库中,数据存储的结构与其定义的schema是强匹配的,也就是先建模再使用,简单点说,数据仓库就像是一个大型图书馆,里面的数据需要按照规范放好,你可以按照类别找到想要的信息,存储在仓库中都是结构化数据,可以直接消费。
第二代:数据湖
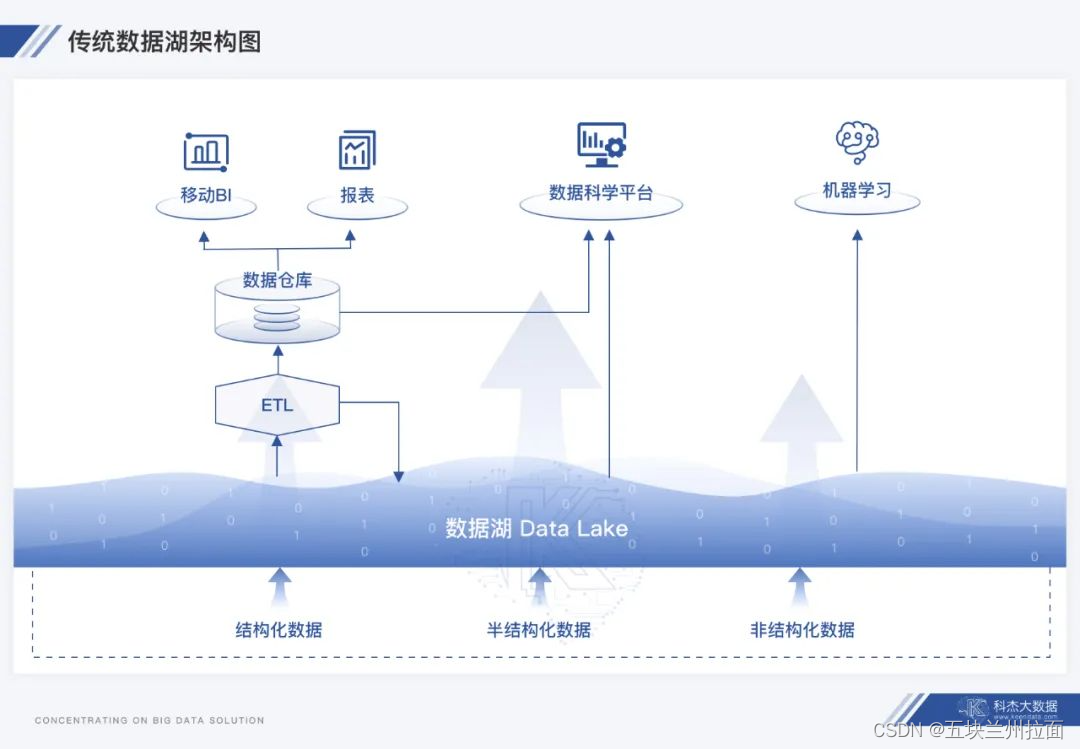
定义
随着数据规模扩大,对数据承载能力(容量、算力)的要求也不断增大,数仓架构的扩展能力面临考验,规模的扩展会面临大量资源的投入,但硬件资源缺乏弹性,会导致高峰时资源不足,低谷时资源闲置浪费问题。
数据湖通常更大,存储成本也更为廉价。结合先进的数据科学与机器学习技术,能提供预测分析、推荐模型等能力。
数据类型
结构化数据、半结构化、非结构化数据。可以存储任何形式(包括结构化和非结构化)和任何格式(包括文本、音频、视频和图像)的原始数据
功能
数据湖存储其中的数据不需要满足特定的schema,数据湖也不会尝试去将特定的schema施行其上,任何格式的数据都可以扔进数据湖。数据使用通常会在读取数据的时候解析schema(schema-on-read),当处理相应的数据时,将转换施加其上,也就是说,数据湖对于入湖的数据不做任何规范,只有在于使用时才定义存储格式以便分析使用。
第三代:湖仓一体
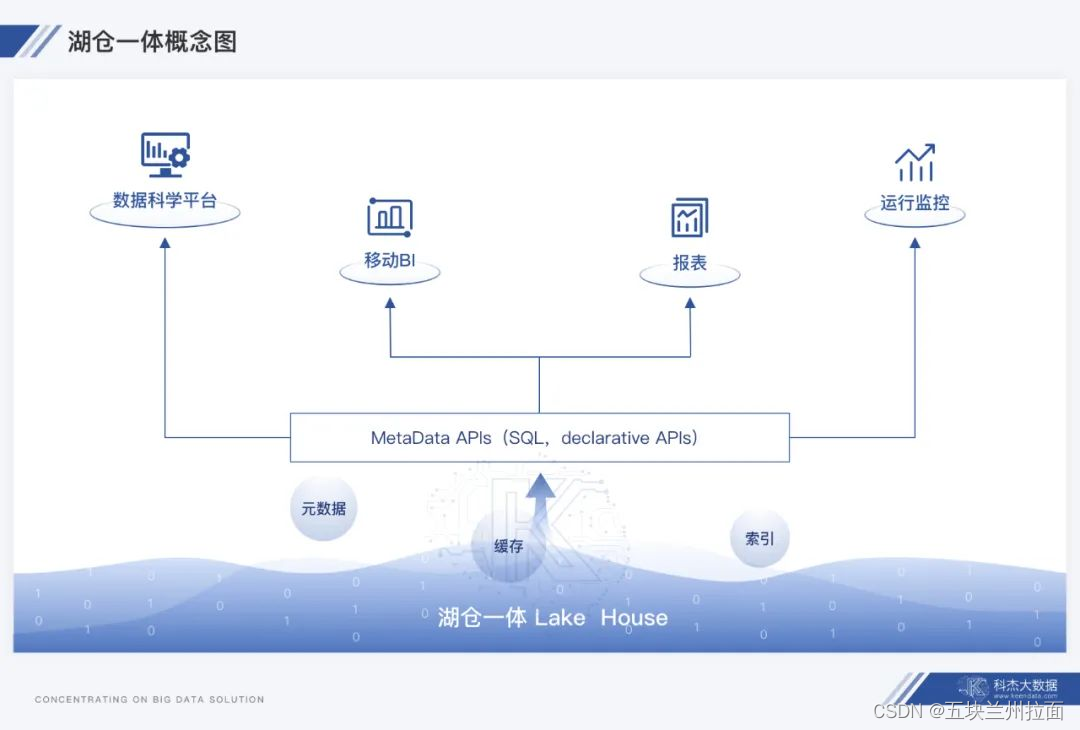
定义
将数据湖和数据仓库技术合二为一 ,在用于数据湖的低成本存储上,实现与数据仓库中类似的数据结构和数据管理功能。
数据类型
和数据湖一样
功能
类似于在湖边搭建了很多小房子,有的负责数据分析,有的运转机器学习,有的来检索音视频等,至于那些数据源流,都可以从数据湖里轻松获取。
前三代的特点和问题
特点
数据仓库,数据湖还是湖仓一体,它们都有一个共同的范式,就是以数据物理集中化为原则的、中心式,单体式的架构。
目的打破数据孤岛。
第一、统一采集企业的所有数据到一个数据平台。
第二、统一对数据进行清洗、转化、处理及分析。
第三、统一对外提供数据服务,包括数据集、API等等。

问题
1.对各类数据进行采集的响应能力变弱,企业拥有越多来源的数据,集中化管理的压力就越大
2.批处理方式很容易造成数据延迟、不一致的现象,这影响到了下游应用的准确性。
3.各类数据处理分析速度难以匹配大量应用需求,各个领域想尽办法另起炉灶。
4.集中化平台上的数据工程师对各领域的来源数据缺乏了解,也缺乏领域专业知识,越来越难以满足各领域的数据消费需求。
数据网格
定义
数据网格是一种去中心化的数据体系结构,按特定业务领域(例如营销、销售、客户服务等)来组织数据,为给定数据集的生产者提供更多所有权。但并不一定意味着您不能使用传统的存储系统,如数据湖或数据仓库。这只是意味着它们的使用已经从单一的集中式数据平台转变为多个去中心化的数据存储库。
原则:按领域对数据的所有权和架构去中心化、数据即产品、自助式数据基础设施及联邦式计算治理。
数据类型
使用数据湖或数据仓库的数据类型
功能
更好的扩展性,新的数据源或新的数据消费者只意味着添加一个新的域(数据产品),而不是重新访问整个数据湖(访问域的api即可)。
构建一个按域划分的数据架构,每个域可以公开一个或多个操作型 API,以及一个或多个数据API对外服务。
数据共享在传统集中化的数据平台做过了头,在各领域数据支撑上力不从心,数据网格希望采用分布式的架构来解决集中化和灵活性的矛盾,让数据所有权回归领域,但需要承担对外数据服务的义务。
总结
数据网格是一种架构和组织范式,它挑战了我们的传统观念 , 即必须将大量的可分析数据集中起来才能使用,将数据放在一起或让专门的数据团队来维护。数据网格认为,为了推动大数据创新,领域必须是数据的所有者并将数据作为产品以提供服务(在自助数据平台的支持下,抽象数据产品服务所涉及的技术复杂性),还必须通过自动化的方式实现一种新的联合治理形式,以支持面向领域的数据产品间的互操作性、去中心化、互操作性以及数据消费者体验,这是数据创新民主化的关键。
如果组织拥有大量的领域,包括大量产生数据的系统和团队,或者多种数据驱动的用户场景和访问模式,那么数据网格也许是一种很好的选择。


