
- 1VMware虚拟机安装MacOS系统超详细教程_vmware workstation17 安装mac
- 2Python初识元组
- 3跨平台 H264 H265/HEVC 编解码 硬件加速_hevc解码器
- 4【创作纪念日】四周年创作纪念日
- 5pytorch安装-Windows(pip install失败)_site-packages\torch\__init__.py", line 1938, in
- 6JS 获取指定日期的前几天,后几天
- 7Linux之ELF魔数解析_文件魔数详解
- 8动态规划-----最长公共子序列(及其衍生问题)
- 9数据存储之——Android文件存储系统及文件系统(Android Q)_android 文件系统
- 10机器学习 | CNN卷积神经网络_cnn的格点转化为图
一文读懂大语言模型_密度文修大语言模型
赞
踩
随着人工智能技术的飞速发展,自然语言处理(NLP)成为了热门的研究领域之一。在这一领域中,预训练大语言模型(Pre-trained Large Language Models)凭借其强大的语言理解和生成能力,逐渐成为了研究和应用的热点,越来越多的企业开始将其应用于实际场景,如智能客服、虚拟助手、内容创作、内容审核、机器翻译等。
本文将从大语言模型的基本概念为始,然后分别介绍大语言模型的开发流程、训练和推理过程中使用到的技术框架,最后对企业如何把握大模型时代的机会给出一些建议。
01 什么是大语言模型
大家在日常生活中都耳熟能详的ChatGPT、文心一言等这些其实是对预训练大语言模型微调后构建的面向广大用户的应用,支撑这些应用的其实是后台的预训练大语言模型,比如ChatGPT的后台是GPT、文心一言的后台是文心ERNIE。随着预训练大语言模型的不断升级迭代,预训练大语言模型还能够支持音频、图像、视频等多模态应用场景,而不仅仅是局限在语言这一块,因此现在大家经常讲的大模型,其实说的是预训练的多模态大模型,主要代表是GPT-4、PaLM2、Gemini、文心ERNIE,但大家接触到最多的还是大语言模型LLM(Large Language Model)。
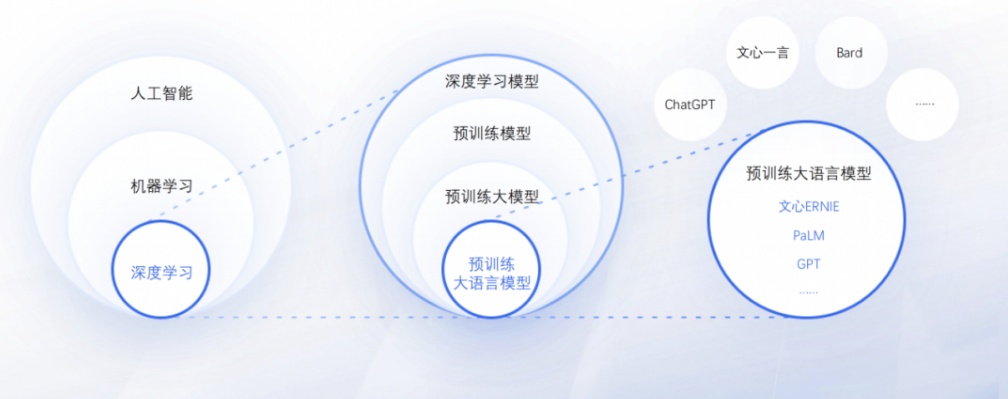
图1. 什么是预训练大语言模型
02 大语言模型的开发流程
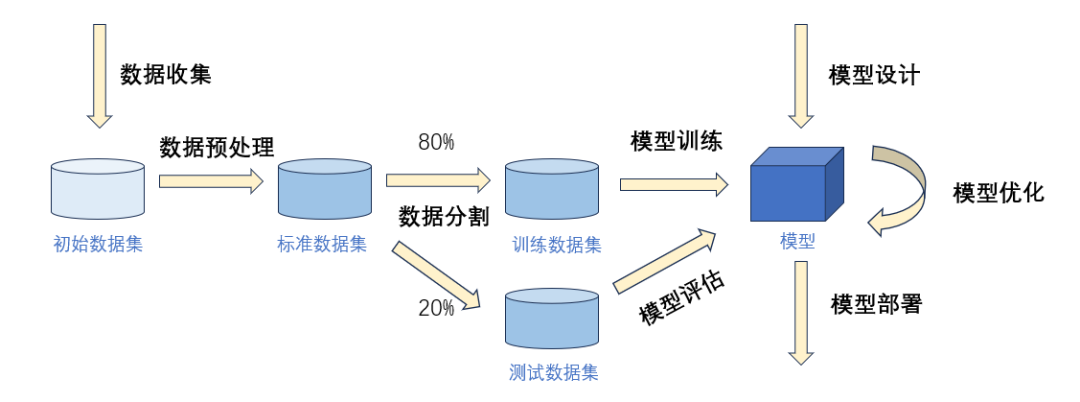
图2. 如何开发大语言模型
数据收集:收集大量的文本数据,包括书籍、新闻、社交媒体、网页等,以便训练模型;
数据预处理:对收集到的数据进行清洗、分词、去除停用词、词干提取等处理,以便提高模型的训练效果;
数据分割:将处理后的数据分割成训练数据集和测试数据集,训练数据集用于模型的训练,测试数据集用于模型评估;
模型设计:选择适合的模型架构,如Transformer,以便实现对文本的自然语言处理;
模型训练:使用收集到的数据对模型进行训练,以便模型能够学习到文本数据中的规律和模式;
模型优化:对模型进行优化,如调整超参数、使用正则化技术、使用预训练模型等,以便提高模型的性能和泛化能力;
模型评估:使用测试数据对模型进行评估,以便了解模型的性能和效果;
模型部署:将训练好的模型部署到生产环境中,以便实现对文本的自然语言处理。
03 大语言模型的训练
3.1 训练
LLM首先需要在大量的无标签数据上进行预训练,在这个过程中模型能够学习到词语的语义、句子的语法结构、以及文本的一般知识和上下文信息。预训练本质上是一个无监督学习过程,最后的预训练模型(Pretrained Model)也被称为基座模型(Base Model),模型具备通用的预测能力。但是要让预训练模型能够真正投入实际应用,还需要对预训练模型进行微调,微调包括全量微调和PEFT。
全量微调(Fine-tuning)通过在预训练的大模型基础上调整所有的层和参数,使其适应特定任务,这一过程使用较小的学习率和特定任务的数据进行,可以充分利用预训练模型的通用特征,但可能需要更多的计算资源。
PEFT(Parameter-Efficient Fine-Tuning )技术旨在通过最小化微调参数的数量和计算复杂度,来提高预训练模型在新任务上的性能,从而缓解预训练模型的训练成本,这样一来,即使计算资源受限,也可以利用预训练模型的知识来迅速适应新任务,实现高效的迁移学习。
因此,PEFT技术可以在提高模型效果的同时,大大缩短模型训练时间和计算成本,让更多人能够参与到深度学习研究中来。PEFT技术包括LORA、QLoRA、Adapter Tuning、Prefix Tuning、Prompt Tuning、P-Tuning及P-Tuning v2等。
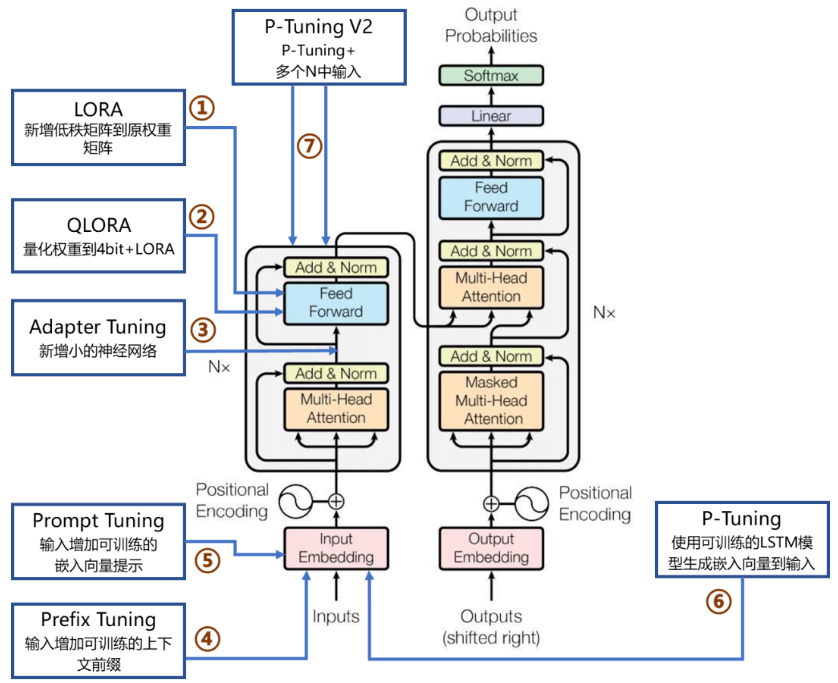
图3. 主流微调方法在Transformer网络架构的作用位置
3.2 训练框架
· PyTorch
PyTorch是由Facebook的人工智能研究团队开发的开源深度学习框架。在2016年发布后,PyTorch很快就因其易用性、灵活性和强大的功能而在科研社区中广受欢迎。PyTorch最突出的优点之一就是它使用了动态计算图(Dynamic Computation Graphs,DCGs),允许你在运行时更改图的行为,这使得PyTorch非常灵活,在处理不确定性或复杂性时具有优势,因此非常适合研究和原型设计。PyTorch提供了大量的预训练模型,包括但不限于ResNet,VGG,Inception,SqueezeNet,EfficientNet等等,PyTorch可以非常高效地利用NVIDIA的CUDA库来进行GPU计算。同时,它还支持分布式计算,让你可以在多个GPU或服务器上训练模型。
· TensorFlow
TensorFlow是谷歌于2015年11月9日正式开源的计算框架,它采用静态图模式,先构建计算图,然后再进行执行。静态图在执行前需要经过编译优化,性能相对较高,但灵活性相对较低,TensorFlow在分布式训练方面有更丰富的选项和工具,如tf.distribute.Strategy等,可以进行灵活的分布式训练,TensorFlow 官方社区提供了良好的文档支持,这些文档中包括大量的机器学习库,方便大家学习,它还集成了不同的 API ,可以用来创建一个大规模的深度学习架构,比如 CNN(卷积神经网络)或 RNN(递归神经网络)。
· PaddlePaddle
PaddlePaddle(飞桨)是以百度多年的深度学习技术研究和业务应用为基础,集深度学习核心训练和推理框架、基础模型库、端到端开发套件、丰富的工具组件于一体,是中国首个自主研发、功能完备、开源开放的产业级深度学习平台,注重易用性和高性能,并提供了灵活的动态图和高效的静态图两种模式,用户可以根据需求选择适合的模式,同时PaddlePaddle对分布式训练也有很好的支持,提供了paddle.distributed模块,能够满足多机多卡的训练需求。
3.3 分布式训练框架
(1)深度学习框架自带分布式训练功能
· TensorFlow
TensorFlow的分布式训练方式主要有MirroredStrategy、MultiWorkerMirroredStrategy、Horovod三种,其中前两者是TensorFlow原生支持的方式,而Horovod是第三方支持。
· PyTorch
PyTorch 的分布式训练方式主要有 DP (DataParallel)、DDP (Distributed DataParallel)、Horovod 三种,其中 DP 和 DDP 是 PyTorch 原生支持的方式, 而 Horovod 是第三方支持。
· PaddlePaddle
“PaddlePaddle” 是 “Parallel Distributed Deep Learning” 并行分布式深度学习的字母缩写组合。飞桨不仅在业内最早支持了万亿级稀疏参数模型的训练能力,而且近期又创新性地提出了 4D 混合并行策略,以训练千亿级稠密参数模型,可以说分布式训练是飞桨最具特色的技术之一。
(2)基于现有的深度学习框架优化和扩展分布式训练功能
· Megatron-LM(Nvidia)
Megatron-LM是NVIDIA应用深度学习研究团队研发的大规模Transformer语言模型训练框架,支持模型并行(张量并行、序列并行与流水并行)与多节点预训练(multi-node pre-training),目前已支持BERT、GPT和T5模型。
· DeepSpeed
DeepSpeed是一个由微软开发的开源深度学习优化库,基于PyTorch构建,旨在提高大规模模型训练的效率和可扩展性。它通过多种技术手段来加速训练,包括模型并行化、梯度累积、动态精度缩放、本地模式混合精度等。DeepSpeed还提供了一些辅助工具,如分布式训练管理、内存优化和模型压缩等,以帮助开发者更好地管理和优化大规模深度学习训练任务。
· FairScale
FairScale(由 Facebook 研究)是一个用于高性能和大规模训练的 PyTorch 扩展库。FairScale 支持Fully Sharded Data Parallel (FSDP),在可用性方面FairScale能够让用户以最小的认知代价理解和使用 FairScale API,在模块化方面让用户能够将多个 FairScale API 无缝组合为训练循环的一部分,同时FairScale API 在扩展和效率方面提供了最佳性能。
04 大语言模型的推理
4.1 推理
LLM推理服务重点关注两个指标:吞吐量和时延。
吞吐量主要从系统的角度来看,即系统在单位时间内能处理的 tokens 数量。计算方法为系统处理完成的 tokens 个数除以对应耗时,其中 tokens 个数一般指输入序列和输出序列长度之和。吞吐量越高,代表 LLM 服务系统的资源利用率越高,对应的系统成本越低。
时延主要从用户的视角来看,即用户平均收到每个 token 所需的时间。计算方法为用户从发出请求到收到完整响应所需的时间除以生成序列长度。一般来讲,当时延不大于 50 ms/token 时,用户使用体验会比较流畅。
为了在部署阶段提高模型的效率和性能,可以对模型进行优化,主要通过以下优化技术:
· 计算:算子融合和高性能算子
· 显存:KV Cache和Paged Attention
· 低比特量化:INT4/INT8 Weight only,Weight+Activation同时量化,KV Cache量化,Hopper架构下的FP8
· 分布式:张量并行、流水线并行、NCCL通信优化
· 服务:Continuous Batching, Dynamic Batching , Async Serving
4.2 推理框架
· TensorFlow Serving
TensorFlow Serving是一个用于将经过训练的TensorFlow模型进行推理部署的开源框架。它提供了高性能、可扩展和可靠的服务,使得可以在生产环境中轻松地部署和管理机器学习模型。它的特点包括支持多种模型格式、高性能的模型加载和推断、灵活的模型版本管理、分布式系统支持、多种接口选择以及监控和日志记录功能。这些特性使得TensorFlow Serving成为机器学习模型推理部署的首选框架之一。
· Torch Serve
TorchServe是AWS和Facebook联合推出的Pytorch模型部署推理框架,具有部署简单、高性能、轻量化等优点。提供Management API和 Inference API,用户通过API进行模型管理和模型推理,支持多模型,多GPU部署,Inference API支持批量推理,支持模型版本控制,提供日志服务。
· ONNX Runtime
ONNX Runtime是一个用于深度学习模型推理部署的高性能开源框架,具有跨多个深度学习框架的互操作性、跨平台兼容性、高性能推理引擎、模型优化和转换、动态图支持、轻量级和可嵌入性等特点。
· TensorRT
TensorRT(Tensor Runtime)是英伟达(NVIDIA)开发的一个针对深度学习模型推理进行高性能优化和部署的框架。具有模型优化和网络层融合、张量核心加速、自动混合精度、动态形状支持、跨平台兼容性、图优化和层融合等特点。
4.3 分布式推理框架
· DeepSpeed Inference
早期的 DeepSpeed 框架虽然支持训练大规模模型,但是训练好的模型在已有的推理解决方案上面临以下问题:缺乏对多 GPU 推理的支持以适应大模型推理的显存要求并满足 Latency 要求;在小批量推理(batch_size)时 GPU 内核性能有限,很难支持量化。
为此,微软开发了 DeepSpeed Inference 系统,它是一种分布式推理解决方案,能够很好地支持 transformer 类型的LLM,通过张量并行技术同时利用多个 GPU,提高推理性能。
· FasterTransformer
NVIDIA FasterTransformer (FT) 是一个用于实现基于Transformer的神经网络推理的加速引擎。FT框架是用C++/CUDA编写的,依赖于高度优化的 cuBLAS、cuBLASLt 和 cuSPARSELt 库,因此可以在 GPU 上进行快速的 Transformer 推理。与NVIDIA TensorRT等其他编译器相比,FT 的最大特点是它支持以分布式方式进行 Transformer 大模型推理,具备tensor parallel和pipeline parallel的能力,可以解决单机单卡无法装载大模型的问题。不过英伟达新推出了TensorRT-LLM,相对来说更加易用,后续FasterTransformer将不再维护了。
05 大语言模型时代的AI算力基础设施
当前企业的数字化转型正进入深水区,面对大模型的兴起,是跟风去采购大量的AI算力训练自己的大模型,还是充分的考虑企业现状以及发展规划后,逐步的推进智能化转型,相信大部分的企业都会选择后者,对于企业AI业务的开展,包括开发、训练、部署推理过程,AI算力是基础也是核心。因此企业可以先从AI算力的采购部署、管理运维、使用支持以及安全合规等维度去思考如何构建大语言模型时代的AI算力基础设施。
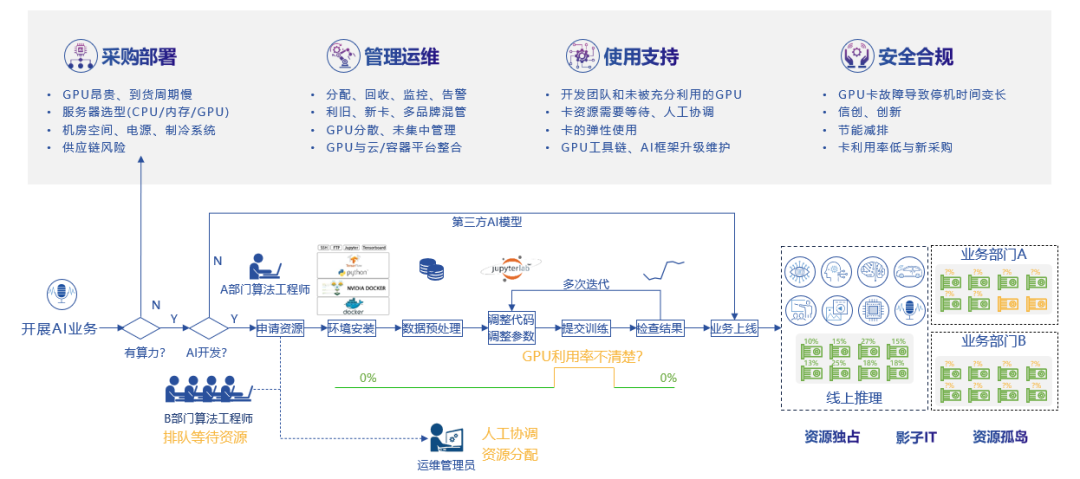
图4. AI算力在使用过程中面临的挑战
06 算力池化技术与大模型的意义
大模型技术一定会进入千家万户赋能百业,人类社会对算力的需求一定会持续增长,用户永远都希望算力成本越低越好,AI算力资源池化技术为数据中心提供了从软件角度实现智能分配算力资源、高效调度和管理算力资源的思路,支撑企业AI业务的开展。
趋动科技的OrionX AI算力资源池化解决方案,支持主流的训练和推理框架,通过软件定义算力技术满足大模型在预训练、监督微调、人类反馈强化学习过程中对于GPU算力的需求,同时基于共享的理念构建的开发、训练和推理一体化GPU算力资源池,帮助企业提升资源利用率5-8倍。
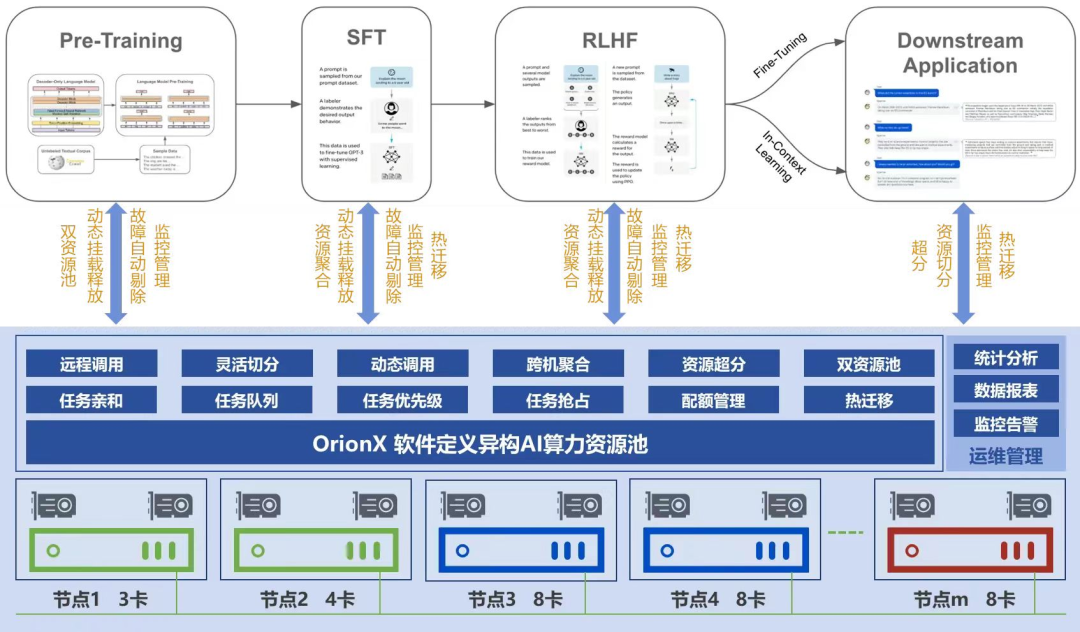
图5. OrionX AI算力资源池化解决方案
面对国内AI芯片的迅速崛起,OrionX已兼容多款国产芯片,实现异构资源池化管理,资源池内各类硬件加速卡可通过OrionX进行算力抽象,软件化后形成统一的AI算力资源提供给上层应用使用。
总之,AI算力池化解决方案可在实现多厂商AI算力硬件统一管理、统一调度、统一使用的同时,结合软件定义AI算力技术实现AI算力的统筹分配、资源池化、高效保障和运维管理,提高企业的人效和物效,加速企业的业务创新,帮助企业逐步实现智能化转型。
参考文献:
1.《深度 | 啥是大模型?一篇文章看懂火遍全网的“AI大模型”》
https://mp.weixin.qq.com/s/33gOVH963ql3FDgRjFA7Zg
2. 《9个主流的分布式深度学习框架》
https://zhuanlan.zhihu.com/p/582498905
3. 《深度学习模型推理部署常用的框架总结记录》
https://blog.csdn.net/Together_CZ/article/details/131856146
4.《大语言模型推理性能优化综述》
https://zhuanlan.zhihu.com/p/656485997?utm_id=0
5.《如何开发大型语言模型?》
https://cloud.tencent.com/developer/article/2288533?areaSource=102001.16&traceId=ynGZjOjwADgy6EZHoVcF_
6.《使用FasterTransformer实现LLM分布式推理》
https://zhuanlan.zhihu.com/p/644322962
7.《LLM 的推理优化技术纵览》
https://blog.csdn.net/hellozhxy/article/details/131897500
8.《【推理引擎】Transformer&LLM模型部署框架/推理引擎总结》
https://zhuanlan.zhihu.com/p/663967083
9.《一文辨析清楚LORA、Prompt Tuning、P-Tuning、Adapter 、Prefix等大模型微调方法》
https://blog.csdn.net/weixin_44292902/article/details/134529591

