
热门标签
热门文章
- 1Unity之UGUI-特效遮挡问题2.0_unity scrollview 超出区域没有遮罩
- 2ucf 转xdc_已解决: UCF转XDC问题 - Community Forums
- 3使用 React 和 Tailwind CSS 创建漂亮 Hero Section
- 4vue前后端rsa+aes混合加密_微服务:前后端分离后API交互如何保证数据安全性?...
- 5自动安装第三方库python,python第三方库自动安装脚本
- 6Go最全情感分析——深入snownlp原理和实践(3),2024-2024历年网易跳动Golang面试真题解析
- 7愉快的学习就从翻译开始吧_6-Time Series Forecasting with the Long Short-Term Memory Network in Python_《long-short-term-memory-networks-with-python》
- 8zynq-7015启动分析及裸机BootLoader编写(未完待续)
- 9OpenCV C++基本操作入门学习
- 10springBoot + myBatis+PageHelper分页查询_spring boot 的mybatis pagehelper分页查询显示当前数据
当前位置: article > 正文
【Spark分布式内存计算框架——Spark SQL】15. Catalyst 优化器_catalyst框架
作者:weixin_40725706 | 2024-06-06 05:36:18
赞
踩
catalyst框架
第九章 Catalyst 优化器
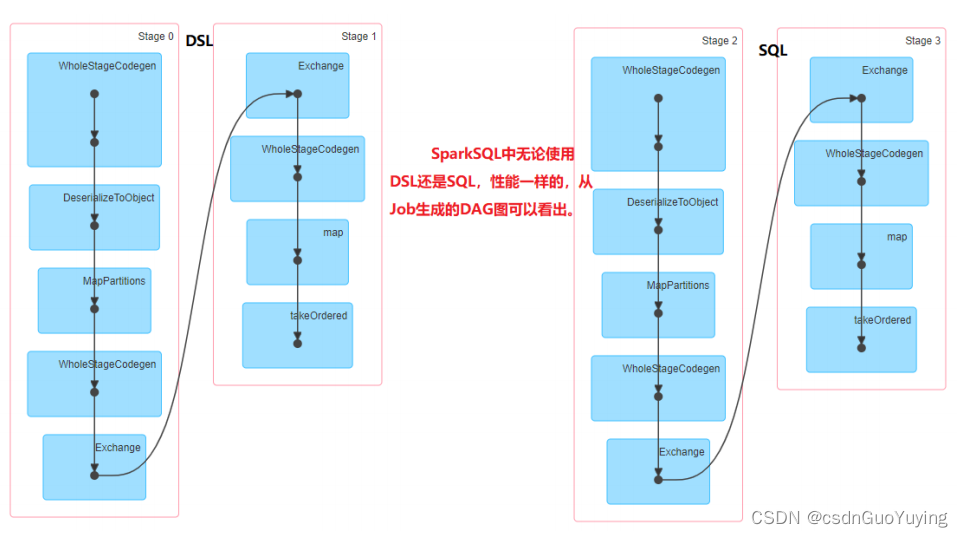
在第四章【案例:电影评分数据分析】中,运行应用程序代码,通过WEB UI界面监控可以看出,无论使用DSL还是SQL,构建Job的DAG图一样的,性能是一样的,原因在于SparkSQL中引擎:Catalyst:将SQL和DSL转换为相同逻辑计划。
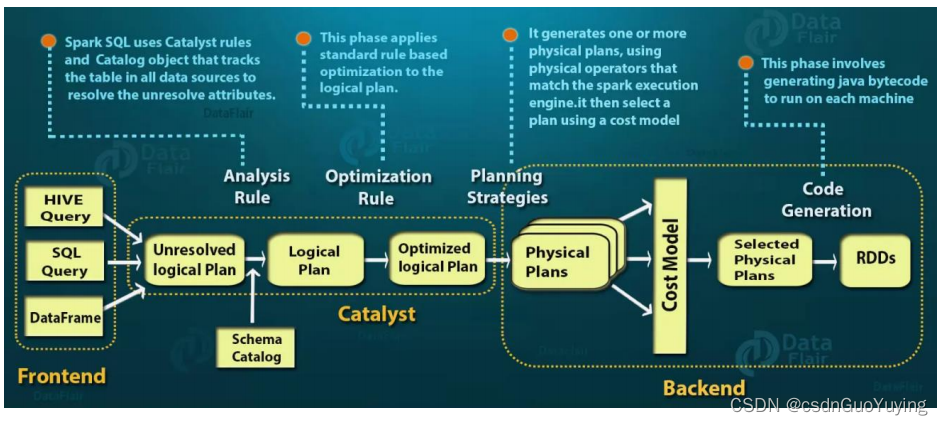
Spark SQL是Spark最新,技术最复杂的组件之一。它为SQL查询和新的DataFrame API提供支持。Spark SQL的核心是Catalyst优化器,它以一种新颖的方式利用高级编程语言功能(例如Scala的模式匹配和quasiquotes)来构建可扩展的查询优化器。
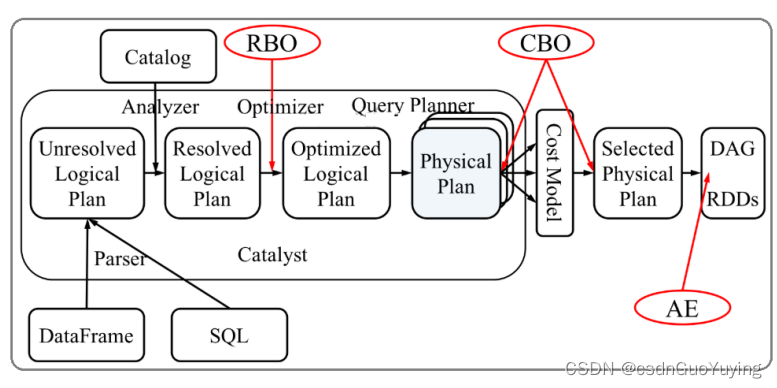
SparkSQL的Catalyst优化器是整个SparkSQL pipeline的中间核心部分,其执行策略主要两方向:
- 基于规则优化/Rule Based Optimizer/RBO;
- 基于代价优化/Cost Based Optimizer/CBO;
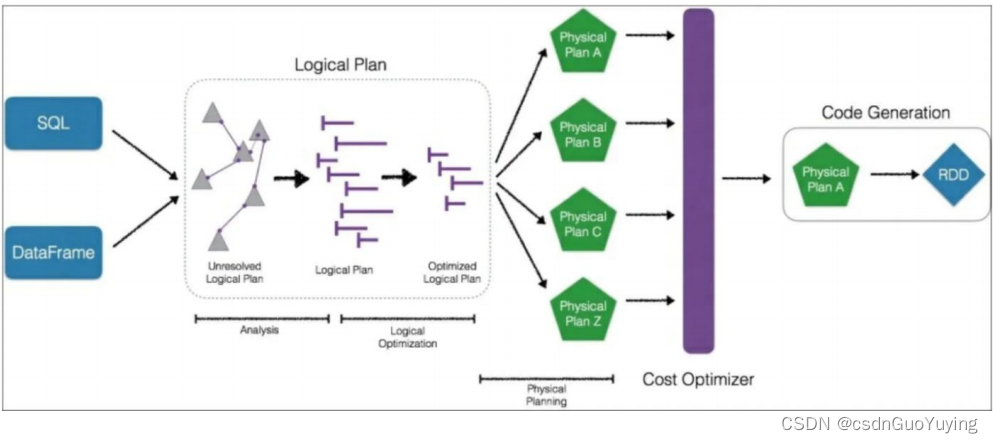
从上图可见,无论是直接使用SQL语句还是使用 ataFrame,都会经过一些列步骤转换成DAG对RDD的操作。
Catalyst工作流程:SQL语句首先通过Parser模块被解析为语法树,此棵树称为Unresolved Logical Plan;Unresolved Logical Plan通过Analyzer模块借助于数据元数据解析为Logical Plan;此时再通过各种基于规则的Optimizer进行深入优化,得到Optimized Logical Plan;优化后的逻辑执行计划依然是逻辑的,需要将逻辑计划转化为Physical Plan

核心三个点:
- 第一点、Parser,第三方类库ANTLR实现。将sql字符串切分成Token,根据语义规则解析成一颗AST语法树;
- 第二点、Analyzer,Unresolved Logical Plan,进行数据类型绑定和函数绑定;
- 第三点、Optimizer,规则优化就是模式匹配满足特定规则的节点等价转换为另一颗语法树;
附录:Maven 依赖
在Maven Project中创建Maven Model,依赖pom.xml添加如下依赖:
<repositories> <repository> <id>aliyun</id> <url>http://maven.aliyun.com/nexus/content/groups/public/</url> </repository> <repository> <id>cloudera</id> <url>https://repository.cloudera.com/artifactory/cloudera-repos/</url> </repository> <repository> <id>jboss</id> <url>http://repository.jboss.com/nexus/content/groups/public</url> </repository> </repositories> <properties> <scala.version>2.12.10</scala.version> <scala.binary.version>2.12</scala.binary.version> <spark.version>2.4.5</spark.version> <hadoop.version>2.6.0-cdh5.16.2</hadoop.version> <mysql.version>8.0.19</mysql.version> </properties> <dependencies> <dependency> <groupId>org.scala-lang</groupId> <artifactId>scala-library</artifactId> <version>${scala.version}</version> </dependency> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-core_${scala.binary.version}</artifactId> <version>${spark.version}</version> </dependency> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-sql_${scala.binary.version}</artifactId> <version>${spark.version}</version> </dependency> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-hive_${scala.binary.version}</artifactId> <version>${spark.version}</version> </dependency> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-hive-thriftserver_${scala.binary.version}</artifactId> <version>${spark.version}</version> </dependency> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-sql-kafka-0-10_${scala.binary.version}</artifactId> <version>${spark.version}</version> </dependency> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-avro_${scala.binary.version}</artifactId> <version>${spark.version}</version> </dependency> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-mllib_${scala.binary.version}</artifactId> <version>${spark.version}</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-client</artifactId> <version>${hadoop.version}</version> </dependency> <dependency> <groupId>mysql</groupId> <artifactId>mysql-connector-java</artifactId> <version>${mysql.version}</version> </dependency> </dependencies> <build> <outputDirectory>target/classes</outputDirectory> <testOutputDirectory>target/test-classes</testOutputDirectory> <resources> <resource> <directory>${project.basedir}/src/main/resources</directory> </resource> </resources> <plugins> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-compiler-plugin</artifactId> <version>3.0</version> <configuration> <source>1.8</source> <target>1.8</target> <encoding>UTF-8</encoding> </configuration> </plugin> <plugin> <groupId>net.alchim31.maven</groupId> <artifactId>scala-maven-plugin</artifactId> <version>3.2.0</version> <executions> <execution> <goals> <goal>compile</goal> <goal>testCompile</goal> </goals> </execution> </executions> </plugin> </plugins> </build>

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/weixin_40725706/article/detail/679734
推荐阅读
相关标签

