
- 1qtp9.2测试java_QTP的使用举例说明
- 2文字转语音工具:GPT-SoVITS_gpt-sovist
- 3隔代获取dom,多个commit合并成一个,计算属性完整写法_commit('dom')
- 42021-09-01_createproxymiddleware
- 5SQL server 数据库log日志过大,占用内存大解决办法_sqlserver日志文件太大解决方法
- 6一、github_github官网
- 7[前端知识点]元素水平垂直居中_子元素垂直居中 子元素定位都设置为0什么意思
- 86DoF位姿估计的度量标准
- 9解决报错 unable to access jarfile apachejmeter.jar 的一些技巧!_error: unable to access jarfile apachejmeter.jar
- 10数据结构初阶--二叉树的链式结构_二叉树的递归遍历算法的时间复杂度是多少
大数据框架之Hadoop:HDFS(一)HDFS概述_hdfs外表
赞
踩
1.1HDFS产出背景及定义
-
HDFS产生背景随着数据量越来越大,在一个操作系统存不下所有的数据,那么就分配到更多的操作系统管理的磁盘中,但是不方便管理和维护,迫切需要一种系统来管理多台机器上的文件,这就是分布式文件管理系统。
HDFS只是分布式文件管理系统中的一种。 -
HDFS定义HDFS(Hadoop Distributed File System),它是一个文件系统,用于存储文件,通过目录树来定位文件,其次,它是分布式的,由很多服务器联合起来实现其功能,集群中的服务器有各自的角色。HDFS的使用场景: 适合一次写入,多次读出的场景,且不支持文件的修改。适合用来做数据分析,并不适合用来做网盘应用。
1.2HDFS优缺点
1.2.1优点
1)高容错性
- 数据自动保存多个副本。它通过增加副本的形式,提高容错性;

- 某一个副本丢失以后,它可以自动恢复。

2)适合处理大数据
-
数据规模:能够处理数据规模达到GB、TB、甚至PB级别的数据;
-
文件规模:能够处理百万规模以上的文件数量,数量相当之大。
3)可构建在廉价机器上,通过多副本机制,提高可靠性
1.2.2缺点
1)不适合低延时数据访问,比如毫秒级的存储数据,是做不到的。
2)无法高效的对大量小文件进行存储
-
存储大量小文件的话,它会占用NameNode大量的内存来存储文件目录和块信息。这样是不可取的,因为NameNode的内存总是有限的;
-
小文件存储的寻址时间会超过读取时间,它违反了HDFS的设计目标。
3)不支持并发写入、文件随机修改
-
一个文件只能有一个写,不允许多个线程同时写;
-
仅支持数据append (追加) ,不支持文件的随机修改。
1.3HDFS组成架构
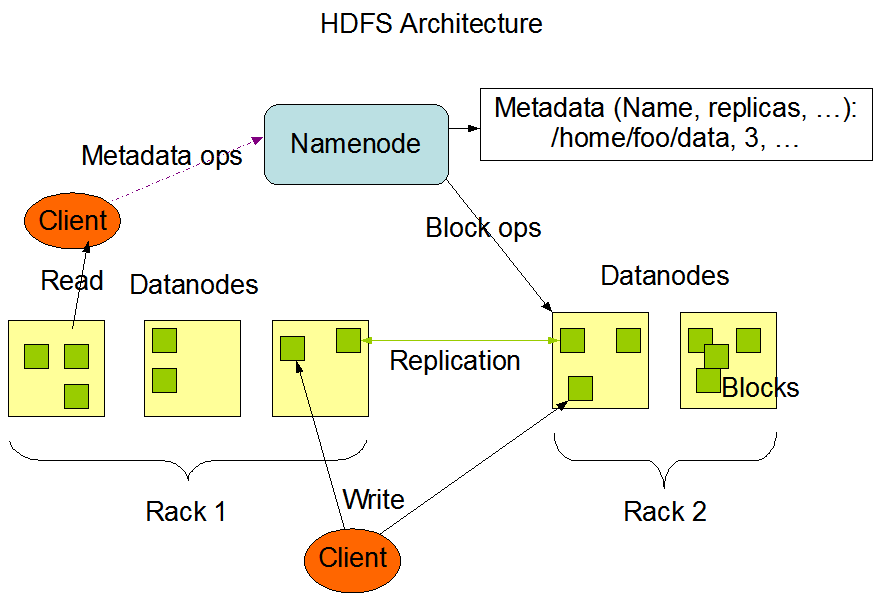
1)NameNode (nn) :就是Master,它是一个主管、管理者。
-
管理HDFS的名称空间;
-
配置副本策略;
-
管理数据块(Block)映射信息;
-
处理客户端读写请求。
2)DataNode: 就是Slave。NameNode下达命令,DataNode执行实际的操作。
-
存储实际的据块
-
执行数据块的读/写操作
3)Client: 就是客户端
- 文件切分。文件上传HDFS的时候,client将文件切分成一个一个的Block,然后进行上传;
- 与NameNode交互,获取文件的位置信息;
- 与DataNode交互,读取或者写入数据
- Client提供一些命今来管理HDFS,比如NameNode格式化;
- Client可以通过一些命今来访问HDFS,比如对HDFS增删查改操作
4)SecondaryNameNode: 并非NameNode的热备。当NameNode挂掉的时候,它并不能马上替换NameNode并提供服务.
-
辅助NameNode,分担其工作量,比如定期合并Fsimage和Edits,并推送给NameNode;
-
在紧急情况下,可辅助恢复NameNode。
1.4HDFS文件块大小(面试重点)
1.4.1HDFS文件块大小
HDFS中的文件在物理上是分块存储(Block),块的大小可以通过配置参数(dfs.blocksize)来规定,默认大小在Hadoop2.x和Hadoop3.x版本中是128M,老版本Hadoop1.x中是64M。
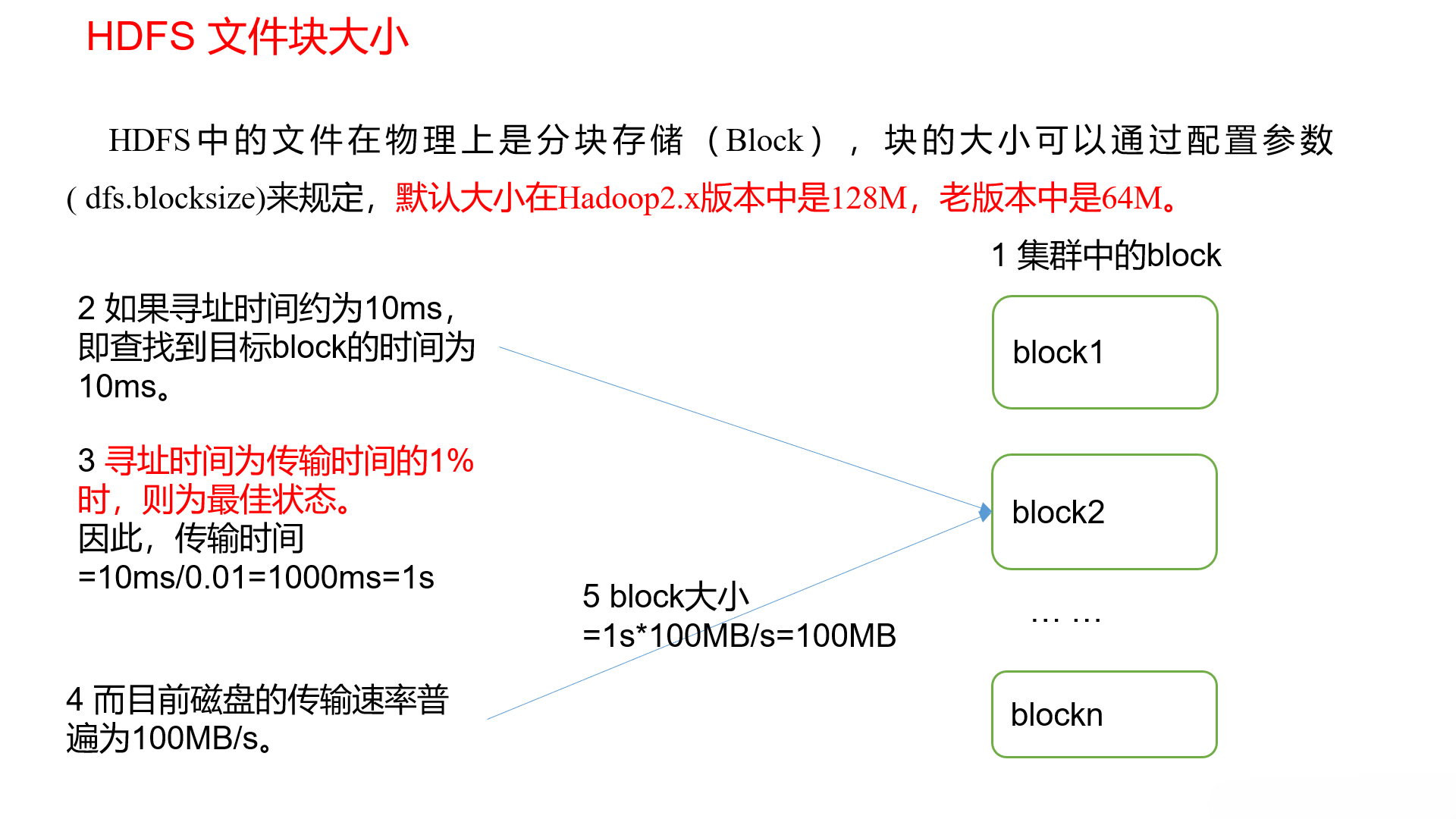
1.4.2HDFS文件块大小设置原理
HDFS文件块大小设置主要取决于磁盘传输速率,目前通过Namenode对HDFS元数据进行寻址的时间约为10ms,即查找到目标block的时间为10ms。
寻址时间为传输时间的1%时,则为最佳状态
因此,传输时间为10ms/0.01=1000ms=1s
目前磁盘的传输速率普遍为100MB/s
因此,block大小为1s*100MB/s=100MB
因为电脑底层数据采用二进制存储,所以目前的block块官方大小设置为128MB。
总结:HDFS文件块大小设置主要取决于磁盘传输速率,生产中采用高速磁盘作为存储介质的可以考虑在HDFS的配置文件中设置dfs.blocksize参数调整block块大小。
1.4.3块大小要设置合理
HDFS的块设置太小,会增加寻址时间,程序一直在找块的开始位置;
如果块设置的太大,从磁盘传输数据的时间会明显大于定位这个块开始位置所需的时间。导致程序在处理这块数据时,会非常慢。

