
- 1ADB获取手机分辨率的多种方法,解决部分手机获取不到的问题_adb调手机分辨率
- 2GIt常用指令、概念及原理分析,图解rebase、merge指令区别,stash、reset贮藏重置等指令详解,每一条指令都有详细说明,值得收藏!_git rm stash
- 3Python自然语言处理笔记(五)------获取文本语料库_什么函数用于获取语料库中的文件
- 4ESP8266 01sWiFi模块保姆级教程 烧录和联网,连接华为云_esp8266wifi模块如何连接网络
- 5PostgreSQL11 | 数据类型和运算符_pgsql boolean相关函数
- 6开篇,对想学Java的小伙伴说点掏心窝子的大实话_程序员青戈怎么样
- 7[开题报告]Springboot会议室预约管理系统0bcs4计算机毕业设计
- 82024年运维最全升级Linux下的sudo_sudo v1(1),2024年最新原理+实战+视频+源码_sudo最新补丁包下载
- 9hive建表_hive创建外部表并指定存储位置
- 10LangChain快速加proxy代理_langchain openai proxy
python编程自我介绍方法,python程序员自我介绍_如何用python介绍自己
赞
踩
大家好,给大家分享一下python编程自我介绍方法,很多人还不知道这一点。下面详细解释一下。现在让我们来看看!

仅供自己参考
Python数据类型和变量
(1)python是动态语言,在定义变量时不需要指定变量类型
(2)通常大写为常量,但是python中没有任何机制保证常量不会被改变
(3)对于很大的整数,允许在数字中间以_分隔
(4)用 r 表示 **' '**内部的字符串默认不转义
字符编码和字符串
(1)ASCII码:8bit 为一个字节,以一个字节存储
取值0~127,表示大小写英文字母、数字和一些符号。大写字母A的编码是65,小写是122
(2)Unicode编码:通常是两个字节存储
(3)UTF-8:英文时→以一个字节存储
中文时→以3个字符存储,生僻字4-6个字节
在计算机内部统一使用Unicode编码,当保存到硬盘或者需要传输的时候就转换为UTF-8
(4)ord()获取字符的整数表示
chr()编码转换为对应的字符
(5)b'字母' 表示每个字符占用一个字节
(6)str.encode('ascii') 或是 str.encode('utf-8')将str编码为指定的bytes
(7)bytes 变为 str ,用 decode() 方法
list列表和tuple元组
list列表
用法:[ ] 表示列表,初始化数据即可
向list中添加元素
listname.append('元素') 添加到list末尾
listname.insert(i,'元素') 添加到指定位置
删除list中元素
listname.pop() 删除list末尾元素
listname.pop(i) 删除指定位置元素
tuple元组
用法: ( )表示元组
注意:tuple一旦被初始化就不能修改,在定义的时候,元组元素必须被确定下来python turtle库函数。
有关input()
用input() 读取用户输入时,是获取的str,所以我们需要注意类型转换。
有关输出print()
用print()输出时常用几种输出方法:
变量 i,j,k
(1)没有变量:
print('Hello','Wrold!')
结果:Hello Wrold!
print('Hello'+'Wrold!')
结果:HelloWrold!
(2)有变量时:
print(i,j,k)
或
print('I is:%d'%i,'J is:%d'%d,'K is:%d'%k)
或
print('i is:%d, j is %d, k is %d'%(i,j,k) )
或
print(f'I is:{i} J is:{j} K is:{k}')
(3)几个print语句连接起来(保存为.py文件再在解释器中解释)
- print(i,end=' ')
- print(j,end=' ')
- print(k,end=' ')
结果: ijk
dict字典和set
dict字典
用法:d = { key 1: value1, key2 : value2 ,.......}
添加一对键值对: d['key'] = value
删除一个key:d.pop('key')
查找key,如果不存在可以返回None或是自定义的值:d.get('key',-1)
注意:dict的key必须是不可变对象。像list是可变对象,就不能作为key
list和dict的比较:
dict的特点:
1、查找和插入的速度极快,不会随着key的增加而变慢
2、需要占用大量的内存,内存浪费多,可以说dict是用空间来换取时间
list的特点:
1、查找和插入的时间随着元素的增加而增加
2、占用空间小,浪费内存很少
set
用法:s = set( [ key] ) 需要提供一个list作为输入集合
注意:set和dict类似,也是一组key的集合,但不存储value
添加元素:s.add(key)
删除元素:remove(key)
Python函数
基本用法
(1)python中存在空函数,只需要在函数体中写pass即可
(2)python中允许返回多个值,同样的,接受函数返回参数时也会按顺序接受参数
(3)使用isinstance()函数对参数进行检查
使用isinstance():
isinstance('A',(int,float))
函数参数
默认参数
def func1(x,n=2)
可变参数
def func1(*numbers)
关键字参数
- >>>def func1(name,**kw):
- ... print('name:','other:',kw)
- ...
- >>>func1('bob',age=18,city='hubei')
- >>>name:bob other:{'age':18,'city':'hubei'}
注意:当传入一个dict给kw时,函数kw获得的dict是一份拷贝,对于kw的改动不会影响外部的dict
命名关键字参数
- >>>def func1(name,*,age,city):
- ... print(name,age,city)
- ...
- >>>func1('bob',age=18,city='hubei')
- >>>bob 18 hubei
注意:定义一个可变参数后,后面跟着的命名关键字参数就不需要分隔符了。
参数组合使用
定义顺序必须是:必选参数、默认参数、可变参数、命名关键字参数、关键字参数
递归函数
注意点:递归函数优点是逻辑简单清晰,缺点是过深调用会导致栈溢出。
Python变量作用域
Python变量的作用域一共是4中,分别是:
- L(local) 局部作用域
- E (enclosing) 闭包函数的环境变量
- G (global)全局作用域
- B (built-in) 内建作用域
Python中查找作用域的规则:L—>E---->G----->B
局部作用域:定义在函数内部
类中的变量被所有对象共享!
- x=5 #全局变量Global
- def func_a():
- print(x)
- def func_b():
- print(x)
- def func_c():
- x+=1
- print(x)
- #以上调用:
- func_a()
- 5
- func_b()
- 5
- func_c()
- UnboundLocalError: local variable 'x' referenced before assignment
func_c() 报错的原因是:在函数内部有和全局变量同名的x,并且对这个变量有修改。
此时,python会认为函数中的x是一个局部变量,但是函数中并没有x的定义和赋值,所以会报错。
在函数内部使用global会声明 x是一个全局变量,此时,会从全局变量中找到x的赋值
random模块
可以产生指定范围内的随机数、字符串等
- >>>import random #导入random模块
- >>>random.choice('abcdefghi') #从参数中选择一个元素,参数也可以是一个列表
- >>>s = "abcdefghigk"
- >>>random.sample(s,3) #从数据源s中随机取出3个值
-
- >>>random.randint(1,100) #打印一个随机数
string模块
- >>>import string #导入string模块
- >>>string.ascii_letters
- 'abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ'
-
- >>>string.ascii_uppercase
- 'ABCDEFGHIJKLMNOPQRSTUVWXYZ' #大写字母
-
- >>>string.ascii_lowercase #小写字母
- 'abcdefghijklmnopqrstuvwxyz'
-
- >>>string.punctuation #打印特殊字符
- '!"#$%&\'()*+,-./:;<=>?@[\\]^_`{|}~'
-
- >>>string.digits #打印数字
- '0123456789'
IO编程
文件读写
读文件:
- >>>f = open(r'C:\Users\ZJ188\Desktop\pythontest.txt','r',encoding='utf-8')
- >>>f.read()
- 'Hello,Wrold!'
第一个标识符r表示显示声明字符串不用转义
若没有r报错:
Python_报错:SyntaxError: (unicode error) ‘unicodeescape’ codec can’t decode bytes in position 2-3: truncated \UXXXXXXXX escape
原因:windows读取文件可以用\,但是在字符串中\是被当作转义字符来使用,经过转义之后可能久找不到路径的资源了,例如\t会被转义为tab键。
第二个标识符’ r ’ 表示读文件。
在python中默认的编码方式是“gbk”,而windows中的文件默认的编码方式是“utf-8",所以导致python编译器无法成功读取或是写入文件内容。
故,我们需要在open内加入:encoding=‘utf-8’
若没使用encoding报错:
UnicodeDecodeError: ‘gbk’ codec can’t decode byte 0x81 in position 15: incomplete multibyte sequence
调用close()方法关闭文件。
文件使用完毕后必须关闭,因为文件对象会占用操作系统的资源,并且操作系统同一时间能打开的文件数量也是有限的:
>>>f.close()
使用try…finally保证正确的关闭文件:
- try:
- f = open(r'C:\Users\ZJ188\Desktop\pythontest.txt','r',encoding='utf-8')
- finally:
- if f:
- f.close()
也可以使用with语句自动帮我们调用close()方法:
- with open(r'C:\Users\ZJ188\Desktop\pythontest.txt','r',encoding='utf-8') as f:
- print(f.read())
使用with语句和try…finally是一样的,但是代码更加简介,并且不必手动调用f.close()方法。
read()函数:
每次最多读取size个字节的内容:read(size)
每次读取一行内容:readline()
一次读取所有内容并按行返回list:readlines()
二进制文件读取:
要读取二进制文件按,如图片、视频等等,用’ rb '模式打开文件即可:
- >>> f = open(r'C:\Users\ZJ188\Desktop\pythontest.txt','rb')
- >>> f.read()
- b'Hello\xef\xbc\x8cWrold\xef\xbc\x81'
seek()函数
功能:用于移动文件读取指针到参数中设定的位置。
语法:fileObject.seek(offset[,whence])
参数说明:
offset:偏移量whence:可选,默认值为0
指定偏移的起始位置0,从文件开头开始算起1,从当前位置开始算起2,从文件末尾算起
返回值:返回文件的当前位置。
用法:
- file = open('../test.txt','r',encoding='utf-8')
- file.seek(3)
- print(file.read().encode())
- file.close()
-
- #结果
- b'\xe5\xa5\xbd\xef\xbc\x81\nHelloWorl\xef\xbc\x81'
说明:
中文和!在utf-8编码中一般占3个字符。
所以当我们设置seek的偏移量时,最好设置3或是3的倍数(文件中有中文时)。
不然会报错:
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xa0 in position 0: invalid start byte
写文件
同读文件,区别是open()函数内的标识符为'w'
- >>> f = open(r'C:\Users\ZJ188\Desktop\pythontest.txt','w')
- >>> f.write('我是新来的!')
- 6
- >>>f.close()
当我们写文件时,操作系统往往不会立刻把数据写入磁盘,而是放到内存缓存起来,空闲的时候再慢慢写入。
只有调用close()方法时,操作系统才保证把没有写入的数据全部写入磁盘。
忘记调用close()的后果是数据可能只写了一部分到磁盘,剩下的丢失了。
所以也可以用with语句来自动调用close()
- with open(r'C:\Users\ZJ188\Desktop\pythontest.txt','w') as f:
- f.write('我是新来的!')
这种写法会直接覆盖之前文件中的内容,可以传入一个' a ' (append)表示追加到文件中内容后面
StringIO and BytesIO
StingIO
有时候,需要对获取到的数据进行操作,但是并不想把数据写到本地硬盘上,这时候可以使用stringIO,写入内存中。
用法:
- #先创建一个StrignIO
- >>>from io import StringIO
- >>>f = StringIO()
- >>>f.write('hello')
- 5
- >>>f.write(' ')
- 1
- >>>f.write('world!')
- 6
- #使用getvalue()方法用于获得写入后的str
- >>>print(f.getvalue())
- hello world!
BytesIO
对二进制数据进行操作,使用BytesIO
BytesIO实现在内存中读写bytes。
写入的不是str,而是经过UTF-8编码的bytes。
- >>> from io import BytesIO
- >>> fi = BytesIO()
- >>> fi.write('中文'.encode('utf-8'))
- 6
- >>> print(fi.getvalue())
操作文件和目录
- #导入os模块
- >>>import os
- >#查看当前目录的绝对路径
- >>> os.path.abspath('.')
- 'C:\\Users\\ZJ188'
- #在某个目录下创建一个新目录,首先把新目录的完整路径表示出来:
- >>> os.path.join('C:\\Users\\ZJ188','testdir')
- 'C:\\Users\\ZJ188\\testdir'
- #然后创建一个目录:
- >>> os.mkdir('C:\\Users\\ZJ188\\testdir')
- #删掉一个目录
- >>> os.rmdir('C:\\Users\\ZJ188\\testdir')
序列化
序列化(pickling):把变量从内存中变成可存储或是传输的过程。
使用pickle.dumps()方法,把对象序列化成一个bytes,然后就可以把这个bytes写入文件。
反序列化(unpickling):把变量内容从序列化对象重新读到内存。
使用pickle.loads()方法反序列化出对象。
但是pickle只能用于Python。
JSON
在不同语言之间传递对象,把对象序列化为标准格式。
JSON表示出来就是一个字符串,可以被所有语言读取,也可以方便地存储到磁盘或者通过网络传输。
Python对象变成一个JSON:json.dumps()
JSON反序列化为Python对象:json.loads(json_str)
类和实例
repr()方法
调用对象的__repr__()方法,获得该方法的返回值,如下:
- >>>class Student():
- ... def __init__(self,id,name):
- ... self.id = id
- ... self.name = name
- ... def __repr__(self):
- ... return 'id = '+self.id+', name = '+self.name
- ...
- >>>xiaoming = Student('001','xiaoming')
- >>>xiaoming
- id = 001, name = xiaoming
若是没有__repr__()方法:
- >>> class Func2(object):
- ... def __init__(self,id,name):
- ... self.id = id
- ... self.name = name
- ...
- >>> two = Func2('001','xiaojuan')
- >>> two
- <__main__.Func2 object at 0x0000019256EDFD68>
call()方法
重写Student类的__call__()方法:
- >>> class Student(object):
- ... def __init__(self,id,name):
- ... self.id = id
- ... self.name = name
- ... def __repr__(self):
- ... return 'id = '+self.id+', name = '+self.name
- ... def __call__(self):
- ... print('I can be called')
- ... print(f'my name is {self.name}')
- ...
- >>> t = Student('001','xiaoming')
- >>> callable(t) #说明t是一个callable对象
- True
- >>> t()
- I can be called
- my name is xiaoming

注:__call__()方法中还可以定义形参
@classmethod类方法
类方法: 第一个参数必须是当前类对象,该参数名一般约定为cls ,通过它来传递类的属性和方法(不能传实例的属性和方法)
调用: 实例对象和类对象都可以调用
使用@classmethod装饰器定义的类方法,这个类方法让类模板具有记忆力。
类模板就是我们所定义的类。
普通情况下,不使用类方法对类进行实例化,类本身是不具有记忆性的,只是当一个静态模板被套用多次而已。
使用类方法,可以让类在每次实例化之后,都能记载一些记忆,如下:
-
- >>>class Person(object):
- ... id = 0 #类变量
- ... def __init__(self,name):
- ... self.name = name
- ... self.id = self.id_number()
- ... @classmethod
- ... def id_number(cls):
- ... cls.id+=1
- ... return cls.id
- ...
- >>>a = Person('A')
- >>>print(a.id)
- 1
- >>>b = Person('B')
- >>>print(b.id)
- 2
注:类方法处理的变量一定要是类变量
关于@classmethod的具体解释点击连接跳转
@staticmethod静态方法
**静态方法:**用@staticmethod装饰的不带self参数的方法叫做静态方法,类的静态方法可以没有参数,可以直接使用类名调用。
- >>> import time
- >>> class TimeTest(object):
- ... def __init__(self,hour,minute,second):
- ... self.hour = hour
- ... self.minute = minute
- ... self.second = second
- ... @staticmethod
- ... def showTime():
- ... return time.strftime("%H:%M:%S",time.localtime())
- ...
- >>> print(TimeTest.showTime())
- 15:11:57
- >>> t = TimeTest(2,10,10)
- >>> nowTime = t.showTime()
- >>> print(nowTime)
- 15:12:20
python运算符优先级
以下优先级:从低到高
- 1 Lambda #运算优先级最低
- 2 逻辑运算符: or
- 3 逻辑运算符: and
- 4 逻辑运算符:not
- 5 成员测试: in, not in
- 6 同一性测试: is, is not
- 7 比较: <,<=,>,>=,!=,==
- 8 按位或: |
- 9 按位异或: ^
- 10 按位与: &
- 11 移位: << ,>>
- 12 加法与减法: + ,-
- 13 乘法、除法与取余: *, / ,%
- 14 正负号: +x,-x
- 15 按位翻转:~x
- 16 指数: **
- 17 属性参考: x.attribute
- 18 下标: x[index]
- 19 寻址段: x[index:index]
- 20 函数调用: f(arguments...)
- 21 绑定或元组显示: (experession,...)
- 22 列表显示: [expression,...]
- 23 字典显示: {key:datum,...}
- 24 字符串转换: 'expression,...'
一些python内置函数等
| 函数 | 作用 |
|---|---|
| callable() | 判断对象是否可被调用,如函数str,int等都是可被调用的。 |
| ord() | 查看某个ASCII字符对应的十进制数 |
| chr() | 查看十进制整数对应的ASCII字符 |
| complex() | 创建一个负数,如complex(1,2) ===(1+2j) |
| delattr() | 删除对象属性,如delattr(xiaoming,‘id’) |
| hasattr() | 查看对象是否有某个属性,如hasattr(xiaoming,‘id’) |
| dir() | 一键查看对象所有方法,如dir(xiaoming) |
| divmod(除数,被除数) | 分别取商和余数,如divmod(10,3) ===(3,1) |
| enumerate(sequence,[start=0]) | 将一个可遍历的数据对象(list,tuple,string)组合为一个索引序列,同时列出数据和数据下标,一般用在for循环中。 |
| eval(str) | 将字符串str当成有效的表达式来求知并返回计算结果取出字符串中内容。如 s=‘1+2+3’ eval(s) 9 |
| getsizeof() | 查看变量所占字节数,要import sys并sys.getsizeof(a) |
| frozenset() | 创建一个不可修改的集合,冻结集合 |
| hash() | 返回对象的哈希值 自定义的实例都是可哈希的 list,dict,set等可变对象都是不可哈希的 |
| help(对象) | 返回对象的帮助文档,如help(xiaoming) |
| id(对象) | 返回对象的内存地址,如id(xiaoming) |
| issubclass(类A,类B) | 当类A是类B的子类时,返回True |
| round(float,ndigits) | ndigits表示小数点后保留几位 |
| type() | 查看对象类型 |
字符串格式化
| 3.1415926 | {:.2f} | 3.14 | 保留小数点后两位 |
| 3.1415926 | {:+.2f} | +3.14 | 带符号保留小数点后两位 |
| -1 | {:+.2f} | -1.00 | 带符号保留小数点后两位 |
| 2.71828 | {:.0f} | 3 | 不带小数 |
| 5 | {:0>2d} | 05 | 数字补零 (填充左边, 宽度为2) |
| 5 | {:x<4d} | 5xxx | 数字补x (填充右边, 宽度为4) |
| 10 | {:x<4d} | 10xx | 数字补x (填充右边, 宽度为4) |
| 1000000 | {:,} | 1,000,000 | 以逗号分隔的数字格式 |
| 0.25 | {:.2%} | 25.00% | 百分比格式 |
| 1000000000 | {:.2e} | 1.00e+09 | 指数记法 |
| 18 | {:>10d} | ’ 18’ | 右对齐 (默认, 宽度为10) |
| 18 | {:<10d} | '18 ’ | 左对齐 (宽度为10) |
| 18 | {:^10d} | ’ 18 ’ | 中间对齐 (宽度为10) |
关键字
nonlocal关键字:在函数内部创建一个函数,该函数使用变量x作为非局部变量。
python3 枚举
枚举类型
当一个变量有几种固定的取值时,通常我们可以将它定义为枚举类型。枚举类型用于声明一组命名的常数,使用枚举类型可以增强代码的可读性。
python2中枚举类
在python2中没有枚举这种数据类型。但是从python3开始,python正式提供了枚举类型。
python2用定义一个类来定义枚举类,但是类属性可以被随便修改。使用如下:
- >>>class ColorCode:
- >>> RED = 1
- >>> BLUE = 2
- >>> BLACK = 3
- >>>
- >>>def print_color(color_code):
- >>> if color_code == ColorCode.RED:
- >>> print('红色')
- >>> elif color_code == ColorCode.BLUE:
- >>> print('蓝色')
- >>> elif color_code == ColorCode.Black:
- >>> print('黑色')
- >>>print_color(1)
- >>>红色
python3中枚举类型
python3中提供enum模块,定义类时继承enum.Enum,有如下特性:
(1)继承了enum.Enum,则ColorCode中类属性将无法修改。
(2)enum模块提供unique装饰器,使得枚举类中没有重复的值。
(3)获得枚举类的名字:color.name ,color为ColorCode对象。
(4)获得枚举类的值:color.value。
(5)枚举值之间不支持>和<操作,但支持等值比较和is身份比较。
使用如下:
- >>>import enum
- >>>from enum import unique
- >>>
- >>>@unique
- ... class ColorCode(enum.Enum):
- ... RED = 1
- ... BLUE = 2
- ... BLACK = 3
- ...
- >>>#调用
- >>>for color in ColorCode:
- ... print(color.name,color.value)
- RED 1
- BLUE 2
- BLACK 3
bytes字节串
应用场景
(1)计算md5,在计算md5值的过程中,有一步要使用update方法,该方法只接受bytes类型数据
- import hashlib
- string = ’12345’
- m = hashlib.md5() #创建md5对象
- str_bytes = string.encode(encoding = 'utf-8')
- print(type(str_bytes))
- m.update(str_bytes)
- str_md5 = m.hexdigest()
-
- print('MD5散列前为:'+ string)
- print('MD5散列后为:'+ str_md5)
关于md5
MD5是最常见的一种摘要算法,在hashlib模块中。
它计算出来的结果称为md5值,固定的128bit字节,是一个32位长度的16进制字符串。
摘要算法能指出数据是否被纂改过,因为摘要函数是一个单向函数。对原始数据做一个bit的修改,都会导致计算出的摘要完全不同。
(2)二进制读写文件。
二进制写文件时,write方法只接受bytes类型数据,需要先将字符串(encode)转成bytes类型数据。
读取二进制文件时,read方法返回的时bytes类型数据,使用decode方法将bytes类型转成字符串。
(3)socket编程
使用socket时,无论时发送还是接受数据,都需要使用bytes类型数据。
字符串与bytes转换:
字符串 ----->bytes :encode方法
bytes------->字符串 :decode方法
类型标注
由于python是动态型语言,所以不需要指定变量的类型。
在python3.5中引入了一个类型系统,它允许开发人员指定变量类型,主要作用是便于开发维护代码,供IDE和开发工具使用,对代码运行不产生任何影响,运行时会过滤类型信息。
示例:
- def add(x:int,y:int)->int:
- return x+y
-
- print(add(3,4.3)
运行结果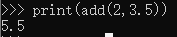
从上面可以看出,类型标注就只是标注,方便开发人员维护,传入其他类型仍然可以进行计算。
使用mypy对python程序进行静态检查
mypy是一个利用类型注解对python代码进行静态类型检查的工具,使用pip安装pip install mypy
使用:
写一个demo.py模块:
- class Stu:
- def __init__(self,name:str,age:int) -> None:
- self.name = name
- self.age = age
-
- def __str__(self) -> str:
- return '{name}{age}'.format(name = self.name,age = self.age)
-
- stu1 = Stu('小明',16.5)
- stu2 = Stu('小刚','17')
-
- print(stu1,stu2)
使用mypy检查:
- PS C:\Study\vscode\PythonWorkplace\theFirstTest\learning> mypy use_mypy检查.py
- use_mypy检查.py:9: error: Argument 2 to "Stu" has incompatible type "float"; expected "int"
- use_mypy检查.py:10: error: Argument 2 to "Stu" has incompatible type "str"; expected "int"
- Found 2 errors in 1 file (checked 1 source file)
python运行时类型检查
正则表达式
特殊字符
| 代码/语法 | 说明 |
|---|---|
. | 匹配除换行符以外的任意字符 |
\w | 匹配字母或数字 |
\s | 匹配任意的空白符 |
\d | 匹配数字 |
\b | 匹配单词的开始或结束 |
^ | 匹配字符串的开始 |
$ | 匹配字符串的结束 |
正则表达式之重复
| 代码/语法 | 说明 |
|---|---|
* | 重复0次或更多次 |
+ | 重复1次或更多次 |
? | 重复0次或1次 |
{n} | 重复n次 |
{n,} | 重复n次或更多次 |
{n,m} | 重复n到m次 |
正则表达式之替换、反义
替换
使用'|'表示或者,如 \bthis\b | \bbool\b表示匹配上this或者匹配book,两个单词,都可以匹配。
[ ]指定一个字符范围[0-5] :表示从0到5的字符[a-z] :表示从a到z的字符[a-zA-Z0-5] :多个范围[+?] :表示+或是?在中括号里,特殊字符可以不适用字符转义
反义
反义就是匹配字符之外的内容
| 代码/语法 | 说明 |
|---|---|
\W | 匹配任意不是字母和数字的字符 |
\S | 匹配任意不是空白符的字符 |
\D | 匹配任意非数字的字符 |
\B | 匹配不是单词开头或结束的位置 |
[^x] | 匹配出来x以外的任意字符 |
[a-z] | 匹配出来小写字母以外的任意字符 |
match用法
1、一般用法:
match方法:从字符串起始位置匹配一个模式,如果模式不配备,则返回None.
compile 方法对正则表达式进行编译,生成一个正则表达式对象,正则表达式对象才有match方法。
2、从起始位置匹配模式,并提取子表达式内容
例子:将学生的姓名和学号提取出来:
- import re
- lst = [
- '小明的学号是123456,小班',
- '小红的学号是456789,中班',
- '小刚的生日是7月15日,大班']
- pattern = re.compile('(.+)的学号是(\d+)')
- for item in lst:
- res = pattern.match(item)
- if res:
- print(res.groups())
- print(res.gruop(1),res.group(2))
注意:groups()匹配的子表达式里的全部内容。
而group(1)匹配子表达式的第一组内容,但group(0)==groups()
search与findall用法
1、search一般用法
search方法扫描整个字符串,返回第一个成功的匹配。
结论:
1、即使有多个匹配,search方法也只会返回第一个。
2、匹配的位置可以是任何位置,这一点与match不同。
如:
- import re
- text = '我喜欢数字123,456,789’
- pattern = re.compile('(\d{3})')
- res = pattern.search(text)
- print(res.span())
- print(res.groups())
- #输出结果:
- (5, 8)
- ('123',)
2、搜索范围
search方法允许设置搜索范围,提供一个开始的位置和一个结束的位置。
默认是从索引0开始搜索,要获取全部匹配,则需要使用循环,上一次匹配的结束位置作为下一次匹配的开始位置。
如:
- >>>import re
- >>> text ='我喜欢数字123,456,789'
- >>> pattern = re.compile('(\d{3})')
- >>> res = pattern.search(text)
- >>> print(res.span())
- (5, 8)
- >>> print(res.groups())
- ('123',)
- >>> liss = []
- >>> while res:
- ... start,end = res.span()
- ... liss.append(res.group(1))
- ... res = pattern.search(text,start+1)
- ...
- >>> print(liss)
- ['123', '456', '789']
3、findall()
findall()在字符串中找到所有正则表达式匹配的子串,并返回一个列表,如果没有则返回空列表。
findall()方法同search()方法设置搜索范围一样。
如:
- >>> text ='我喜欢数字123,456,789'
- >>> pattern = re.compile('(\d{3})')
- >>> ress = pattern.findall(text)
- >>> print(ress)
- ['123', '456', '789']
4、finditer()
与findall的功能类似,不同之处在于,finditer返回的是一个迭代器。
- >>> text ='我喜欢数字123,456,789'
- >>> pattern = re.compile('(\d{3})')
- >>> ress = pattern.finditer(text)
- >>> for item in ress:
- ... print(item.group())
- ...
- 123
- 456
- 789
split方法与sub方法
1、split方法,以正则表达式分割字符串
字符串提供split方法可以根据分割符对字符串进行分割,但是该方法只能使用一个分隔符。
- >>> lst = ['1小时3分15秒','4分39秒','54秒']
- >>> pattern = re.compile('小时|分|秒')
- >>> for time_str in lst:
- ... res = pattern.split(time_str)
- ... print(res)
- ...
- ['1', '3', '15', '']
- ['4', '39', '']
- ['54', '']
2、sub方法,替换字符串中的匹配项
- import re
-
- text = '我有3个电话号,分别是13343454523, 13341154523,13341152223'
-
- pattern = re.compile('\d{11}')
- text = pattern.sub("***", text)
- print(text)
- #结果:
- 我有3个电话号,分别是***, ***,***
python内存管理
1、变量引用
(1)复制语句执行过程中,在内存中创建了新的数据。
(2)可以多个变量指向同一个数据
(3)当一个数据没有变量指向它时,这个数据的引用数量就编程了0,python会销毁掉这个对象,这就是GC(垃圾回收)。
(4)通过sys.getrefcount()方法查看一个数据的引用量。
2、可变对象与不可变对象
不可变对象:int、float、str、tuple
可变对象(内存中值可变):dict、set、列表
但对于:
- lst = [1,2]
- print(id(lst))
- lst = [1,2,3]
- print(id(lst))
- #以上两个输出内存地址不同
浅拷贝与深拷贝
浅拷贝
拷贝规则:
1.如果被拷贝对象是不可变对象,则不会生成新的对象。
2.如果被拷贝对象是可变对象,则会生成新的对象,但是只会对可变对象最外层进行拷贝。
可变对象最外层拷贝:
- import
- a = [1,[1]]
- b = copy.copy(a)
- print(id(a),id(b))
- print(id(a[1]),id(b[1]))
-
- #结果:可以看出a和b内存地址不同,但a[1],b[1]内存地址相同
- >>> id(a)
- 2628498872264
- >>> id(b)
- 2628498872008
- >>> id(a[1])
- 2628498871944
- >>> id(b[1])
- 2628498871944
所以这种浅拷贝,改变一个变量的值,也会对另一个对象的值产生影响。
深拷贝
拷贝规则:
1.如果被拷贝对象是不可变对象,深拷贝不会生成新对象,因为被拷贝对象是不可变的,继续用原来的那个,不会产生什么坏的影响。
2.如果被拷贝对象是可变对象,那么会彻底的创建出一个被拷贝对象一模一样的新对象。
如:
- import copy
-
- a = [1,[1]]
- b = copy.deepcopy(a)
-
- print(id(a),id(b))
- print(id(a[0]),id(b[0]))
- print(id(a[1]),id(b[1]))
-
- 结果输出:
- 1497238640200 1497239292424 #地址不同
-
- 140705289720864 140705289720864 #地址相同
-
- 1497239139720 1497239292360 #地址不同
- >>> type(a[0])
- <class 'int'>
- >>> type(a[1])
- <class 'list'>
对于a[0]和b[0]地址相同,原因是a[0]是一个int类型,不可变对象,拷贝时不会产生新的对象。
而a和a[1]都是list类型,为可变对象,则会产生新的对象。
深拷贝之后,对b的任何操作,都不会影响到a,虽然多耗费了一些内存,但是更加安全。
内存池技术
一切皆对象,“对象”二字暗示着在内存中存在一片区域。
如果对象频繁的创建和销毁,就会产生很多内存碎片,最终会影响系统性能。
(1)小整数对象:存储[ -5,257)
python提供了对象池技术,在python启动之后,会在内存中申请一片内存,将频繁使用的小整数存储在这里,在整个程序运行期间,这些小整数都一直存在,不会被销毁,对于他们的使用,仅仅增加了他们的引用计数而已。
(2)字符串驻留
对于字符串的使用,同样有着内存困扰。
python提供了intern机制,python内部维护了一个字典(interned),当一个字符串需要驻留时,就去interned中查看这个字符是否已经存在,存在则增加字符串的引用计数,否则增加到字典中。
使用驻留技术好处:
1、节省内存。
2、字符串比较时,驻留字符串的比较速度远远高于非驻留字符串。
什么时候发生驻留
- 编译时发生驻留,运行时不驻留
- 只含大小写字母、数字、下划线时发生驻留
- 字符串长度为0或是1
- 被sys.intern指定驻留
- from sys import intern
-
- s1 = intern('python!')
- s2 = inter('python!')
-
- print(s1 is s2)
- True
- 用乘法(*)得到的字符串
乘数为1: - 1.字符串只包含下划线,数字,字母,默认驻留
- 2.字符串长度小于等于1,默认驻留
- s1 = '你好呀'
- s2 = s1*1 # 若 s2 = '你好呀'*1 则不驻留
- s1 is s2
- True
乘数为2:
- 1.字符串只包含下划线、数字、字母且长度小于等一20,默认驻留
- 2.含有其他字符时,不论长度是多少,都不驻留
python列表,元组内存分配优化
1、空元组与空列表
当创建两个空元组时:内存地址相同
当创建两个空列表时:内存地址不同
2、小元组的分配优化
减少内存碎片,加快分配速度,python会重用旧的元组。
重用前提:
1、a元组不再被使用,且长度小于20
2、b元组与a元组长度相同,则b元组可以重用a元组的这片内存。
注:元组a被del后,内存并不是真的被回收。
3、列表大小调整
python中的列表和C++中的vector很像,总是预先分配一些容量,当存储的数据超过容量时,采取一定的算法增加容量,可以避免过于频繁的申请内存,又保证插入效率。
python容量增长方式为:0、4、8、16、25、35、46、58、72、88......
例子:
- >>> b = []
- >>> for i in range(10):
- ... b.append(i)
- ... sys.getsizeof(b)
- ...
- 96
- 96
- 96
- 96
- 128
- 128
- 128
- 128
- 192
- 192
空列表占64字节。
加入一个元素后,增加4个插槽的容量,每个插槽占8个字节大小。
当4个插槽都有内容后,再加入一个元素,则增加8个插槽,依次类推。
垃圾回收机制
python的垃圾回收以引用计数为主,标记清除和分代回收为辅。
引用计数的优点
- 简单
- 实时性高,只要引用计数为0,对象就会被销毁,内存被释放,回收内存的时间平摊到了平时。
引用计数的缺点
- 为了维护引用计数消耗了很多资源
- 循环引用,导致内存泄漏
当循环引用时,引用计数一直大于0,除非动手操作,不然不会被GC回收。
针对这种情况,python引入了标记清楚和分代回收机制作为补充。
标记清除
标记清楚可以处理循环引用的情况,它分为两个阶段。
第1阶段,标记阶段
GC会把所有活动对象打上标记,这些活动对象就如同一个点,他们之间的引用关系构成边,最后点和边构成了一个有向图:

第2阶段,搜索清楚阶段
从根对象(root)出发,沿着有向边遍历整个图,不可达的对象就是需要清理的垃圾对象。这个根对象就是全局对象,调用栈,寄存器。
从上图中,可以到大1 2 3 4,而5,6,7均不能到达,其中6和7相互引用,这3个对象都会被回收。
分代回收
分代回收建立在标记清除的基础之上,是一种以空间换时间的操作方式。
分代回收:将内存中对象的存活时间分为3代,新生对象放入0代,如果一个对象在0代的垃圾回收过程中存活下来,GC就会将其放入到1代,如果1代里的对象在第1代的垃圾回收过程中存活下来,则会进入到2代。
分代回收的触发机制
- >>> import gc
- >>> print(gc.get_threshold())
- (700, 10, 10)
解读:
- 当分配对象的个数 减去 释放对象的个数的差值大于700时,就会产生依次0代回收
- 10次0代回收会导致1次1代回收
- 10次1代回收会导致1次2代 回收
对于0代的对象来说,需要经常被回收。
而2代回收的就不那么频繁。
通过设置这桑阈值,来改变分代回收的触发条件
- import gc
-
- gc.set_threshold(600,10,5)
- print(gc.get_threshold())
这个设置使0代和2代回收更加频繁。
Collections模块
collections实现了许多特定容器,这些容器在某些情况下可以代替内置容器dict,list,tuple,set。
counter – 统计对象个数
counter类可以统计对象的个数,它是字典的子类。
1、创建
counter有3中创建对象的方法
- from collections import Counter
-
- c1 = Counter() #创建一个空的Counter对象
- c2 = Counter('hello world') #从一个可迭代对象(列表、元组、字典,字符串)
- c3 = Counter(a=3,b=4) #从一组键值对创建
-
- print(c1)
- print(c2)
- print(c3)
-
- #运行结果:
- Counter()
- Counter({'l': 3, 'o': 2, 'h': 1, 'e': 1, ' ': 1, 'w': 1, 'r': 1, 'd': 1})
- Counter({'b': 4, 'a': 3})
2、访问缺失的键
counter虽然是字典的子类,但访问缺失的键时,不会引发KeyError,而是返回0.
- from collections import Counter
-
- c1 = Counter() #创建一个空的Counter对象
- print(c1['apple']) #0
3、计数器更新
更新方法:
(1)update,用来新增计数。
(2)substract,用来减少计数。
使用update
使用方法:
c1.update(string)
就是往c1这个counter中添加string并计数
- c1 = Counter('hello world')
- c1.update('hello') #使用另一个iterable对象更新
- print(c1['o'])
-
- c2 = Counter('world')
- c1.update(c2) #使用另一个Counter对象更新
- print(c1['o'])
使用subtract
使用方法:
c1.subtract(string)
就是往c1里删除string
- from collections import Counter
- c1 = Counter('hello world')
- c1.subtract('hello') #使用另一个iterable对象更新
- print(c1['o']) #1
-
- c2 = Counter('world')
- c1.subtract(c2) #使用另一个Counter对象更新
- print(c1['o']) #0
-
- print(c1)
- Counter({'l': 1, 'o': 1, ' ': 1, 'w': 1, 'r': 1, 'd': 1, 'h': 0, 'e': 0})
4、键的删除
使用方法:
同字典一样,使用del即可删除键值对
- from collections import Counter
-
- c1 = Counter('hello world')
- del c1['o']
- print(c1['o']) #0
5、elements()
elements()返回一个迭代器,一个元素的计数是多少,在迭代器中就会有多少。
使用方法:
Counter对象调用elements()方法即可
- c1 = Counter('hello world')
- lst = list(c1.elements())
- print(lst)
- #结果
- ['h', 'e', 'l', 'l', 'l', 'o', 'o', ' ', 'w', 'r', 'd']
6、most_common([n])
most_common返回top N的列表,即计数排名前N的元素。
如果计数相同,排列无指定顺序,如果不指定n,则返回所有元素。
- c1 = Counter('hello world')
- print(c1.most_common(2))
- #结果:
- [('l', 3), ('o', 2)]
7、算数和集合操作
Count类支持+、-、&、|操作:
&操作返回两个Counter对象的最小值|操作返回两个Counter对象的最大值-操作得到的Counter对象将删除计数小于1的元素
- >>> from collections import Counter
- >>> c = Counter(a=1,b=3)
- >>> d = Counter(a=2,b=2)
- >>> print(c+d)
- Counter({'b': 5, 'a': 3})
- >>> print(c-d)
- Counter({'b': 1})
- >>> print(c&d)
- Counter({'b': 2, 'a': 1})
- >>> print(c|d)
- Counter({'b': 3, 'a': 2})
ChainMap – 合并多个字典
ChainMap可以将多个字典组合成一个可更新的视图。
在使用时,允许将多个字典视为一个字典。
1、遍历多个字典
使用for循环一个字典一个字典遍历
- dict1 = {'python':100}
- for key,value in dict1.items():
- print(key,value)
2、合并遍历
ChainMap返回的对象类型并不是字典
使用ChainMap可以只用一个for循环即可遍历出所有对象
- from collections import ChainMap
- dict1 = {'python':100}
- dict2 = {'C++':99}
- dic = ChainMap(dict1,dict2)
- print(type(dic))
- for key,value in dic.items():
- print(key,value)
- #程序输出结果
- <class 'collections.ChainMap'>
- C++ 99
- python 100
3、动手实现类似功能
- dict1 = {'python':100}
- dict2 = {'C++':99}
-
- def pair_chain(*args):
- for dic in args:
- for key in dic:
- yield key,dic[key]
-
- for key,value in pair_chain(dict1,dict2):
- print(key,value)
OrderedDict – 有序字典
python3.6之前,字典都是无序的,这里的有序,是指插入dict的顺序。
python3.6之后就不需要依靠OrderedDict来实现有序字典了。
但是还可以使用popitem方法按照先进后出的原则删除最后加入的key-value对。
使用move_to_end方法,可以将一个key-value移动到末尾
- from collections import OrderedDict
- order_dict = OrderedDict()
-
- order_dict[1] = 1
- order_dict['a'] = 2
- order_dict['0'] = 3
-
- for key,value in order_dict.items():
- print(key,value)
- print("*"*20)
- #将第一个键值对加到字典末尾
- order_dict.move_to_end(1)
- for key,value in order_dict.items():
- print(key,value)
-
- #删除最后加入的键值对
- order_dict.popitem()
- (1, 1)
- for key,value in order_dict.items():
- print(key,value)
- #结果:
- 1 1
- a 2
- b 3
- ********************
- a 2
- b 3
- 1 1
- #删除最后加入的键值对后dict中的内容
- a 2
- b 3
defaultdict — 不会引发KeyError的字典
1、KeyError异常
在python标准模块提供的字典中,如果key不存在,则会引发KeyError异常。
collection模块中的defaultdict可以避免这种错误
- >>> dic = { }
- >>> print(dic['python'])
- Traceback (most recent call last):
- File "<stdin>", line 1, in <module>
- KeyError: 'python'
2、defaultdict一般用法
defaultdict是字典的子类,用于不会引发KeyError异常
使用:
(1)必须传入一个工厂函数:int,float,list,set。
(2)在defaultdict中有__mising__(key)方法,当没有key时,根据你所传入工厂函数会返回一个默认值。如int则返回 0,list则返回空列表。
使用:
- >>> from collections import defaultdict
- >>> dic = defaultdict(int)
- >>> print(dic['python'])
- 0
3、defaultdict应用
使用defaultdict统计列表中各个值出现的次数。
- from collections import defaultdict
-
- lst = [1,3,4,2,1,3,5]
- count_dict = defaultdict(int)
-
- for item in lst:
- count_dict[item] +=1
- print(count_dict)
deque — 一个类似列表的容器
deque:类似列表的容器,支持在两端快速的追加和删除元素。
提供如下方法:
(1)append()在末尾追加数据
(2)appendleft()在头部追加数据
(3)pop()删除并返回指定索引的数据,默认时末尾的数据
(4)popleft()删除并返回头部数据
(5)insert(index,obj)在指定位置插入数据
(6)remove(obj)删除指定数据
(7)extend()从右端逐个添加可迭代对象
(8)entendleft()从左端逐个添加可迭代对象
(9)count()统计队列中的元素个数
(10)rotate(n)从右侧反转n步,如果n为负数,则从左侧反转
(11)clear()将deque中的元素全部删除,最后长度为0
(12)maxlen只读属性,deque限定的最大长度,当限制长度的deque增加超过限制数的项时,另一边的项会自动删除。
此外,deque还支持迭代、序列化、
len(d)、reversed(d)、copy.copy(d)、copy.deepcopy(d),通过in操作符进行成员测试和下标索引
1、实现双端队列
- from collections import deque
-
-
- class DoubleQueue():
- def __init__(self):
- self.queue = deque()
-
- def is_empty(self):
- """判断是否为空队列"""
- return len(self.queue) == 0
-
- def insert_front(self,data):
- """从队首插入数据"""
- self.queue.appendleft(data)
-
- def delete_front(self):
- """从队首删除数据"""
- return self.queue.popleft()
-
- def insert_rear(self,data):
- """从队尾插入数据"""
- self.queue.append(data)
-
- def delete_rear(self):
- """从队尾删除数据"""
- return self.queue.pop()
-
- def size(self):
- """返回队列长度"""
- return len(self.queue)
-
- def show(self):
- """打印出列表中的数据"""
- for item in self.queue:
- print(item)
-
- dq = DoubleQueue()
-
- print(dq.is_empty())
- dq.insert_front(4)
- dq.insert_rear(5)
- dq.insert_rear(6)
-
- dq.show()
- print("*"*20)
- print(dq.delete_front())
- print(dq.delete_rear())
- print(dq.size())
注意:初始化时,
self.queue = deque()不要忘了deque后面的()不然在使用len()函数时报错:TypeError: object of type 'type' has no len()
原因是:deque是一个类型,没有实例化。
如: int就是一个类型,是没有len()函数的。
2、实现栈
- #使用deque实现栈的先进后出
-
- from collections import deque
-
- class Stack:
- def __init__(self) -> None:
- self.stack = deque()
-
- def push_stack(self,date):
- """"入栈"""
- self.stack.append(date)
-
- def pop_stack(self):
- """出栈"""
- return self.stack.pop()
-
- def size(self):
- """栈大小"""
- return len(self.stack)
-
- def is_empty(self):
- return self.size() == 0
-
- def show(self):
- for item in self.stack:
- print(item)
-
-
- stack =Stack()
-
- print('入栈的数据:')
- stack.push_stack(4)
- stack.push_stack(3)
- stack.push_stack(1)
-
- stack.show()
- print('出栈的数据:')
- print(stack.pop_stack())
- print('栈内剩下的数据:')
- stack.show()
- print('栈的大小:')
- print(stack.size())
namedtuple — 有属性名称的元组
1、有属性的元组
namedtuple允许我们创建有属性名称的元组,这样就可以通过属性名称来获取数据。
创建如下:
- >>> from collections import namedtuple
- >>> Point = namedtuple('Point',['x_coord','y_coord'])
- #说明Point是tuple的子类
- >>> print(issubclass(Point,tuple))
- True
- >>> point = Point(3,5)
- >>> print(point.x_coord,point.y_coord)
- 3 5
2、为什么不用类
以上完全可以创建一个类来解决:
- class Point():
- def __init__(self,x,y):
- self.x_coord = x
- self.y_coord = y
-
- point = Point(3,5)
- #输出x,y坐标
- print(point.x_coord,point.y_coord)
为什么不用类,而用namedtuple,最常见的解释是定义一个类大材小用。
但是创建一个namedtuple对象,不比创建一个类简单。
而且namedtuple返回的对象本身就是一个类。
原因:
元组是不可变对象,因此元组可以做字典的key,可以存储到集合中。
如果我们用定义的普通类来替代namedtuple,一旦需要做字典的key,那么普通的类创建出的对象就无能为力了。
而namedtuple创建的是tuple的子类,因此具有tuple的一切属性。
functools模块
OS操作
1.返回当前工作目录
os.getcwd() 方法用于返回当前工作目录
使用os模块前记得: import os
2.遍历文件、目录
os.walk(top[, topdown=True[, onerror=None[, followlinks=False]]])
参数:
- top:所要遍历的目录的地址,返回的是一个三元组(root,dirs,files)
- root :当前正在遍历的这个文件夹本身的地址
- dirs : 一个list,内容是该文件夹中所有的目录的名字(不包括子目录)
- files : 一个list,内容是该文件夹中所有的文件(不包括子目录)
- topdown --可选,为True则优先遍历top目录,否则先遍历top的子目录(默认为开启)。如果topdown参数为True,walk会遍历top文件夹,与top文件夹中每一个子目录。
- onerror – 可选,需要一个callable对象,当walk需要异常时,会调用。
- followlinks – 可选,如果为True,则会遍历目录下的快捷方式,如果为false,则优先遍历top子目录。
返回值:返回生成器
实例:
- import os
- for root,dirs,files in os.walk(".",topdown=False):
- for name in files:
- print(os.path.join(root,name))
- for name in dirs:
- print(os.path.join(root,name))
python glob()用法
glob是python自带的一个文件操作的相关模块。
用于:查找符号自己目的的文件
支持通配符:* 代表0个或多个字符? 代表一个字符[] 匹配指定范围内的字符,如[0-9] 匹配数字
用法:
- file_f = glob.glob(path1 + "\\*.xlsx")
- print(file_f)
输出结果:输出path1路径下以.xlsx结尾的文件名
iglob方法
用于:获取一个迭代器(interator)对象,使用它可以逐个获取匹配的文件路径名。
glob与iglob区别:
glob.glob()同时获取所有匹配路径
glob.iglob()一次只获取一个匹配路径

