
热门标签
热门文章
- 1程序员找工作难吗?我用亲身经历来告诉大家_程序员工作好找吗
- 2C#实现简单人机交互_c#人机对话拾音
- 3基于Java的宠物管理的设计与实现(附源码地址)_宠物管理系统
- 4【大模型系列 07】MiniGPT-4 for PyTorch 昇腾迁移_blip_laion_cc_sbu数据下载
- 5基于Spring Boot的网上书城系统(带文档)_基于springboot的网上书城
- 6亚马逊云科技AI应用 SageMaker 新突破,机器学习优势显著_sagemaker inference.py的作用
- 7Python报错:AttributeError: ‘int‘ object has no attribute ‘decode‘_int' object has no attribute 'decode
- 8Python 数据可视化:WordCloud 词云的构建_amueller.github.io
- 9不知道AIGC是什么?近屿智能OJAC第六期AIGC深度训练营,带您从入门到精通!
- 102021SC@SDUSC山东大学软件学院软件工程应用与实践--YOLOV5代码分析(八)plots.py-1_yolov5中if self.pil or not is_ascii(label)
当前位置: article > 正文
python学习之实现语音的简单训练及识别_python sklearn 语音
作者:不正经 | 2024-04-09 05:24:49
赞
踩
python sklearn 语音
语音识别是一门交叉学科。近二十年来,语音识别技术取得显著进步,开始从实验室走向市场。人们预计,未来10年内,语音识别技术将进入工业、家电、通信、汽车电子、医疗、家庭服务、消费电子产品等各个领域。 语音识别听写机在一些领域的应用被美国新闻界评为1997年计算机发展十件大事之一。很多专家都认为语音识别技术是2000年至2010年间信息技术领域十大重要的科技发展技术之一。 语音识别技术所涉及的领域包括:信号处理、模式识别、概率论和信息论、发声机理和听觉机理、人工智能等等。
此次用的是python3.6的版本实现的,安装一些相关模块sklearn:
pip install sklearn
- 1
会自动下载相关的包,好像一般来说,是下载最新的(不敢确认)。
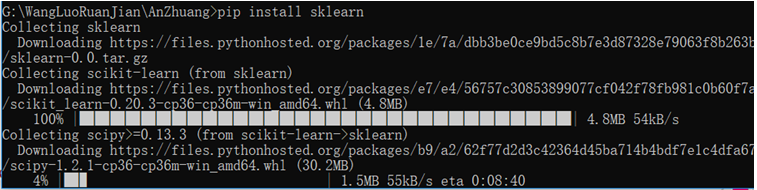
中间也可能会存在一定的错误,导致失败,但可以重新,继续下载,反正我是这样的。
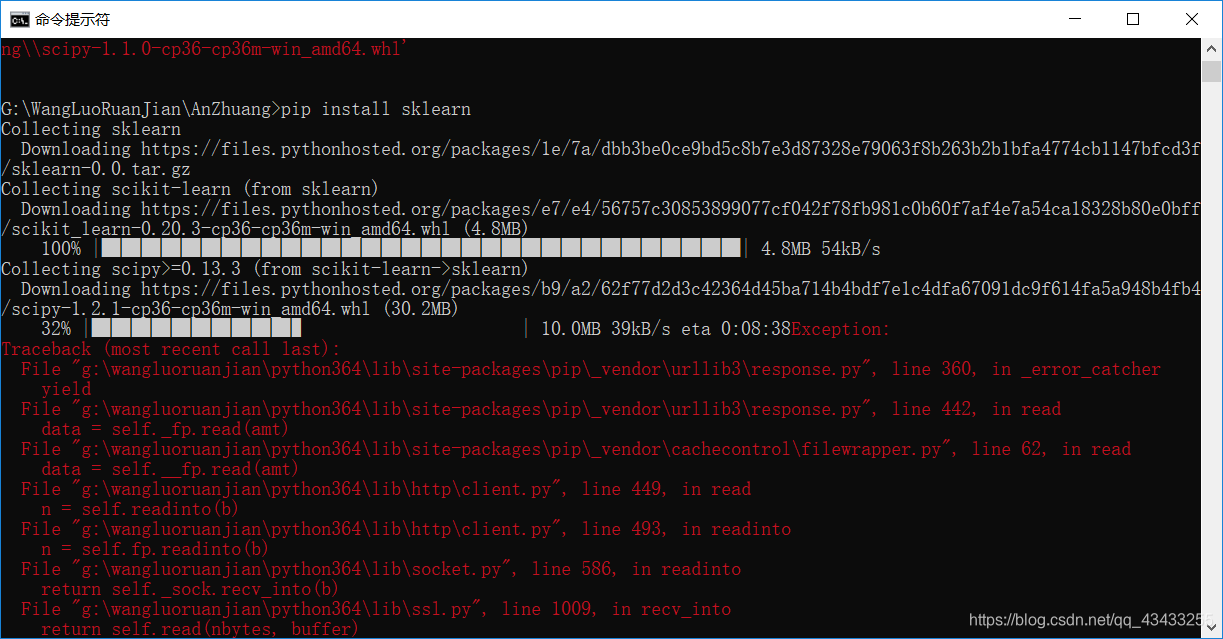
知道成功安装。
gParam的代码:
#!/usr/bin/env python3 # -*- coding:utf-8 -*- u''' Created on 2019年4月27日 @author: wuluo ''' __author__ = 'wuluo' __version__ = '1.0.0' __company__ = u'重庆交大' __updated__ = '2019-04-27' TRAIN_DATA_PATH = 'G:/2018and2019two/duomeitijishu/data/train/' TEST_DATA_PATH = 'G:/2018and2019two/duomeitijishu/data/test/' NSTATE = 4 NPDF = 3 MAX_ITER_CNT = 100 NUM = 10 if __name__ == "__main__": pass

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
对于读入的路径,我用的是绝对路径,也就是写死。
test的代码:
#!/usr/bin/env python3 # -*- coding:utf-8 -*- u''' Created on 2019年4月27日 @author: wuluo ''' __author__ = 'wuluo' __version__ = '1.0.0' __company__ = u'重庆交大' __updated__ = '2019-04-27' import numpy as np from numpy import * from duomeiti import gParam from duomeiti import my_hmm from my_hmm import gmm_hmm #可会出现报错,但实际运行起来,没有问题 my_gmm_hmm = gmm_hmm() my_gmm_hmm.loadWav(gParam.TRAIN_DATA_PATH) my_gmm_hmm.hmm_start_train() my_gmm_hmm.recog(gParam.TEST_DATA_PATH) if __name__ == "__main__": pass
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
在编译与修改代码的边缘,疯狂试探;
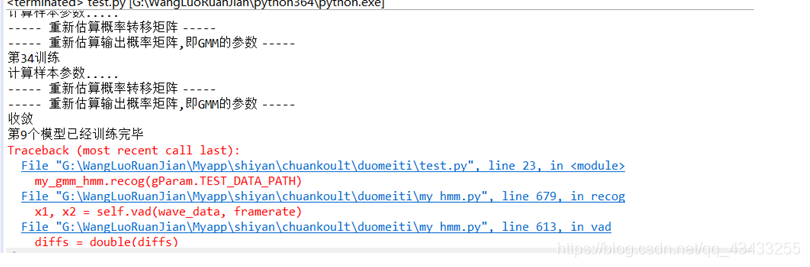
主要还是python版本的原因,版本的不同,有些函数的用法也不同。具体详细请见这个网址:https://www.runoob.com/python3/python3-att-list-extend.html
my_hmm的代码:
#!/usr/bin/env python3 # -*- coding:utf-8 -*- u''' Created on 2019年4月27日 @author: wuluo ''' __author__ = 'wuluo' __version__ = '1.0.0' __company__ = u'重庆交大' __updated__ = '2019-04-27' import numpy as np from numpy import * from sklearn.cluster import KMeans from scipy import sparse import scipy.io as sio from scipy import signal import wave import math from duomeiti import gParam import copy def pdf(m, v, x): est_v = np.prod(v, axis=0) test_x = np.dot((x - m) / v, x - m) p = (2 * math.pi * np.prod(v, axis=0))**-0.5 * \ np.exp(-0.5 * np.dot((x - m) / v, x - m)) return p class sampleInfo: def __init__(self): self.smpl_wav = [] self.smpl_data = [] self.seg = [] def set_smpl_wav(self, wav): self.smpl_wav.append(wav) def set_smpl_data(self, data): self.smpl_data.append(data) def set_segment(self, seg_list): self.seg = seg_list class mixInfo: def __init__(self): self.Cmean = [] self.Cvar = [] self.Cweight = [] self.CM = [] class hmmInfo: def __init__(self): self.init = [] # 初始矩阵 self.trans = [] # 转移概率矩阵 self.mix = [] # 高斯混合模型参数 self.N = 0 # 状态数 class gmm_hmm: def __init__(self): self.hmm = [] # 单个hmm序列, self.gmm_hmm_model = [] # 把所有的训练好的gmm-hmm写入到这个队列 self.samples = [] # 0-9 所有的音频数据 self.smplInfo = [] # 这里面主要是单个数字的音频数据和对应mfcc数据 # 每一个HMM对应len(stateInfo)个状态,每个状态指定高斯个数(3) self.stateInfo = [gParam.NPDF, gParam.NPDF, gParam.NPDF, gParam.NPDF] def loadWav(self, pathTop): for i in range(gParam.NUM): tmp_data = [] for j in range(gParam.NUM): wavPath = pathTop + str(i) + str(j) + '.wav' f = wave.open(wavPath, 'rb') params = f.getparams() nchannels, sampwidth, framerate, nframes = params[:4] str_data = f.readframes(nframes) # print shape(str_data) f.close() wave_data = np.fromstring(str_data, dtype=short) / 32767.0 #wave_data.shape = -1,2 #wave_data = wave_data.T #wave_data = wave_data.reshape(1,wave_data.shape[0]*wave_data.shape[1]) # print shape(wave_data),type(wave_data) tmp_data.append(wave_data) self.samples.append(tmp_data) # 循环读数据,然后进行训练 def hmm_start_train(self): Nsmpls = len(self.samples) for i in range(Nsmpls): tmpSmplInfo0 = [] n = len(self.samples[i]) for j in range(n): tmpSmplInfo1 = sampleInfo() tmpSmplInfo1.set_smpl_wav(self.samples[i][j]) tmpSmplInfo0.append(tmpSmplInfo1) # self.smplInfo.append(tmpSmplInfo0) print('现在训练第' + str(i) + '个HMM模型') hmm0 = self.trainhmm(tmpSmplInfo0, self.stateInfo) print('第' + str(i) + '个模型已经训练完毕') # self.gmm_hmm_model.append(hmm0) # 训练hmm def trainhmm(self, sample, state): K = len(sample) print('首先进行语音参数计算-MFCC') for k in range(K): tmp = self.mfcc(sample[k].smpl_wav) sample[k].set_smpl_data(tmp) # 设置MFCCdata hmm = self.inithmm(sample, state) pout = zeros((gParam.MAX_ITER_CNT, 1)) for my_iter in range(gParam.MAX_ITER_CNT): print('第' + str(my_iter) + '训练') hmm = self.baum(hmm, sample) for k in range(K): pout[my_iter, 0] = pout[my_iter, 0] + \ self.viterbi(hmm, sample[k].smpl_data[0]) if my_iter > 0: if(abs((pout[my_iter, 0] - pout[my_iter - 1, 0]) / pout[my_iter, 0]) < 5e-6): print('收敛') self.gmm_hmm_model.append(hmm) return hmm self.gmm_hmm_model.append(hmm) # 获取MFCC参数 def mfcc(self, k): M = 24 # 滤波器的个数 N = 256 # 一帧语音的采样点数 arr_mel_bank = self.melbank(M, N, 8000, 0, 0.5, 'm') arr_mel_bank = arr_mel_bank / np.amax(arr_mel_bank) #计算DCT系数, 12*24 rDCT = 12 cDCT = 24 dctcoef = [] for i in range(1, rDCT + 1): tmp = [np.cos((2 * j + 1) * i * math.pi * 1.0 / (2.0 * cDCT)) for j in range(cDCT)] dctcoef.append(tmp) # 归一化倒谱提升窗口 w = [1 + 6 * np.sin(math.pi * i * 1.0 / rDCT) for i in range(1, rDCT + 1)] w = w / np.amax(w) # 预加重 AggrK = double(k) AggrK = signal.lfilter([1, -0.9375], 1, AggrK) # ndarray #AggrK = AggrK.tolist() # 分帧 FrameK = self.enframe(AggrK[0], N, 80) n0, m0 = FrameK.shape for i in range(n0): #temp = multiply(FrameK[i,:],np.hamming(N)) # print shape(temp) FrameK[i, :] = multiply(FrameK[i, :], np.hamming(N)) FrameK = FrameK.T # 计算功率谱 S = (abs(np.fft.fft(FrameK, axis=0)))**2 # 将功率谱通过滤波器组 P = np.dot(arr_mel_bank, S[0:129, :]) # 取对数后做余弦变换 D = np.dot(dctcoef, log(P)) n0, m0 = D.shape m = [] for i in range(m0): m.append(np.multiply(D[:, i], w)) n0, m0 = shape(m) dtm = zeros((n0, m0)) for i in range(2, n0 - 2): dtm[i, :] = -2 * m[i - 2][:] - m[i - 1][:] + \ m[i + 1][:] + 2 * m[i + 2][:] dtm = dtm / 3.0 # cc = [m,dtm] cc = np.column_stack((m, dtm)) # cc.extend(list(dtm)) cc = cc[2:n0 - 2][:] # print shape(cc) return cc # melbank def melbank(self, p, n, fs, f1, fh, w): f0 = 700.0 / (1.0 * fs) fn2 = floor(n / 2.0) lr = math.log((float)(f0 + fh) / (float)(f0 + f1)) / (float)(p + 1) tmpList = [0, 1, p, p + 1] bbl = [] for i in range(len(tmpList)): bbl.append(n * ((f0 + f1) * math.exp(tmpList[i] * lr) - f0)) #b1 = n*((f0+f1) * math.exp([x*lr for x in tmpList]) - f0) # print bbl b2 = ceil(bbl[1]) b3 = floor(bbl[2]) if(w == 'y'): pf = np.log((f0 + range(b2, b3) / n) / (f0 + f1)) / lr # note fp = floor(pf) r = [ones((1, b2)), fp, fp + 1, p * ones((1, fn2 - b3))] c = [range(0, b3), range(b2, fn2)] v = 2 * [0.5, ones((1, b2 - 1)), 1 - pf + fp, pf - fp, ones((1, fn2 - b3 - 1)), 0.5] mn = 1 mx = fn2 + 1 else: b1 = floor(bbl[0]) + 1 b4 = min([fn2, ceil(bbl[3])]) - 1 pf = [] for i in range(int(b1), int(b4 + 1), 1): pf.append(math.log((f0 + (1.0 * i) / n) / (f0 + f1)) / lr) fp = floor(pf) pm = pf - fp k2 = b2 - b1 + 1 k3 = b3 - b1 + 1 k4 = b4 - b1 + 1 r = fp[int(k2 - 1):int(k4)] r1 = 1 + fp[0:int(k3)] r = r.tolist() r1 = r1.tolist() r.extend(r1) #r = [fp[int(k2-1):int(k4)],1+fp[0:int(k3)]] c = list(range(int(k2), int(k4 + 1))) c2 = list(range(1, int(k3 + 1))) # c = c.tolist() # c2 = c2.tolist() c.extend(c2) #c = [range(int(k2),int(k4+1)),range(0,int(k3))] v = 1 - pm[int(k2 - 1):int(k4)] v = v.tolist() v1 = pm[0:int(k3)] v1 = v1.tolist() v.extend(v1) # [1-pm[int(k2-1):int(k4)],pm[0:int(k3)]] v = [2 * x for x in v] mn = b1 + 1 mx = b4 + 1 if(w == 'n'): v = 1 - math.cos(v * math.pi / 2) elif (w == 'm'): tmpV = [] # for i in range(v): # tmpV.append(1-0.92/1.08*math.cos(v[i]*math)) v = [1 - 0.92 / 1.08 * math.cos(x * math.pi / 2) for x in v] # print type(c),type(mn) col_list = [x + int(mn) - 2 for x in c] r = [x - 1 for x in r] x = sparse.coo_matrix((v, (r, col_list)), shape=(p, 1 + int(fn2))) matX = x.toarray() #np.savetxt('./data.csv',matX, delimiter=' ') return matX # x.toarray() # 分帧函数 def enframe(self, x, win, inc): nx = len(x) try: nwin = len(win) except Exception as err: # print err nwin = 1 if (nwin == 1): wlen = win else: wlen = nwin # print inc,wlen,nx # here has a bug that nf maybe less than 0 nf = fix(1.0 * (nx - wlen + inc) / inc) f = zeros((int(nf), wlen)) indf = [inc * j for j in range(int(nf))] indf = (mat(indf)).T inds = mat(range(wlen)) indf_tile = tile(indf, wlen) inds_tile = tile(inds, (int(nf), 1)) mix_tile = indf_tile + inds_tile for i in range(int(nf)): for j in range(wlen): f[i, j] = x[mix_tile[i, j]] # print x[mix_tile[i,j]] if nwin > 1: # TODOd w = win.tolist() #w_tile = tile(w,(int)) return f # init hmm def inithmm(self, sample, M): K = len(sample) N0 = len(M) self.N = N0 # 初始概率矩阵 hmm = hmmInfo() hmm.init = zeros((N0, 1)) hmm.init[0] = 1 hmm.trans = zeros((N0, N0)) hmm.N = N0 # 初始化转移概率矩阵 for i in range(self.N - 1): hmm.trans[i, i] = 0.5 hmm.trans[i, i + 1] = 0.5 hmm.trans[self.N - 1, self.N - 1] = 1 # 概率密度函数的初始聚类 # 分段 for k in range(K): T = len(sample[k].smpl_data[0]) #seg0 = [] seg0 = np.floor(arange(0, T, 1.0 * T / N0)) #seg0 = int(seg0.tolist()) seg0 = np.concatenate((seg0, [T])) # seg0.append(T) sample[k].seg = seg0 # 对属于每个状态的向量进行K均值聚类,得到连续混合正态分布 mix = [] for i in range(N0): vector = [] for k in range(K): seg1 = int(sample[k].seg[i]) seg2 = int(sample[k].seg[i + 1]) tmp = [] tmp = sample[k].smpl_data[0][seg1:seg2][:] if k == 0: vector = np.array(tmp) else: vector = np.concatenate((vector, np.array(tmp))) # vector.append(tmp) # tmp_mix = mixInfo() # print id(tmp_mix) tmp_mix = self.get_mix(vector, M[i], mix) # mix.append(tmp_mix) hmm.mix = mix return hmm # get mix data def get_mix(self, vector, K, mix0): kmeans = KMeans(n_clusters=K, random_state=0).fit(np.array(vector)) # 计算每个聚类的标准差,对角阵,只保存对角线上的元素 mix = mixInfo() var0 = [] mean0 = [] #ind = [] for j in range(K): #ind = [i for i in kmeans.labels_ if i==j] ind = [] ind1 = 0 for i in kmeans.labels_: if i == j: ind.append(ind1) ind1 = ind1 + 1 tmp = [vector[i][:] for i in ind] var0.append(np.std(tmp, axis=0)) mean0.append(np.mean(tmp, axis=0)) weight0 = zeros((K, 1)) for j in range(K): tmp = 0 ind1 = 0 for i in kmeans.labels_: if i == j: tmp = tmp + ind1 ind1 = ind1 + 1 weight0[j] = tmp weight0 = weight0 / weight0.sum() mix.Cvar = multiply(var0, var0) mix.Cmean = mean0 mix.CM = K mix.Cweight = weight0 mix0.append(mix) return mix0 # baum-welch 算法实现函数体 def baum(self, hmm, sample): mix = copy.deepcopy(hmm.mix) # 高斯混合 N = len(mix) # HMM状态数 K = len(sample) # 语音样本数 SIZE = shape(sample[0].smpl_data[0])[1] # 参数阶数,MFCC维数 print('计算样本参数.....') c = [] alpha = [] beta = [] ksai = [] gama = [] for k in range(K): c0, alpha0, beta0, ksai0, gama0 = self.getparam( hmm, sample[k].smpl_data[0]) c.append(c0) alpha.append(alpha0) beta.append(beta0) ksai.append(ksai0) gama.append(gama0) # 重新估算概率转移矩阵 print('----- 重新估算概率转移矩阵 -----') for i in range(N - 1): denom = 0 for k in range(K): ksai0 = ksai[k] tmp = ksai0[:, i, :] # ksai0[:][i][:] denom = denom + sum(tmp) for j in range(i, i + 2): norm = 0 for k in range(K): ksai0 = ksai[k] tmp = ksai0[:, i, j] # [:][i][j] norm = norm + sum(tmp) hmm.trans[i, j] = norm / denom # 重新估算发射概率矩阵,即GMM的参数 print('----- 重新估算输出概率矩阵,即GMM的参数 -----') for i in range(N): for j in range(mix[i].CM): nommean = zeros((1, SIZE)) nomvar = zeros((1, SIZE)) denom = 0 for k in range(K): gama0 = gama[k] T = shape(sample[k].smpl_data[0])[0] for t in range(T): x = sample[k].smpl_data[0][t][:] nommean = nommean + gama0[t, i, j] * x nomvar = nomvar + gama0[t, i, j] * \ (x - mix[i].Cmean[j][:])**2 denom = denom + gama0[t, i, j] hmm.mix[i].Cmean[j][:] = nommean / denom hmm.mix[i].Cvar[j][:] = nomvar / denom nom = 0 denom = 0 # 计算pdf权值 for k in range(K): gama0 = gama[k] tmp = gama0[:, i, j] nom = nom + sum(tmp) tmp = gama0[:, i, :] denom = denom + sum(tmp) hmm.mix[i].Cweight[j] = nom / denom return hmm # 前向-后向算法 def getparam(self, hmm, O): T = shape(O)[0] init = hmm.init # 初始概率 trans = copy.deepcopy(hmm.trans) # 转移概率 mix = copy.deepcopy(hmm.mix) # 高斯混合 N = hmm.N # 状态数 # 给定观测序列,计算前向概率alpha x = O[0][:] alpha = zeros((T, N)) #----- 计算前向概率alpha -----# for i in range(N): # t=0 tmp = hmm.init[i] * self.mixture(mix[i], x) alpha[0, i] = tmp # hmm.init[i]*self.mixture(mix[i],x) # 标定t=0时刻的前向概率 c = zeros((T, 1)) c[0] = 1.0 / sum(alpha[0][:]) alpha[0][:] = c[0] * alpha[0][:] for t in range(1, T, 1): # t = 1~T for i in range(N): temp = 0.0 for j in range(N): temp = temp + alpha[t - 1, j] * trans[j, i] alpha[t, i] = temp * self.mixture(mix[i], O[t][:]) c[t] = 1.0 / sum(alpha[t][:]) alpha[t][:] = c[t] * alpha[t][:] #----- 计算后向概率 -----# beta = zeros((T, N)) for i in range(N): # T时刻 beta[T - 1, i] = c[T - 1] for t in range(T - 2, -1, -1): x = O[t + 1][:] for i in range(N): for j in range(N): beta[t, i] = beta[t, i] + beta[t + 1, j] * \ self.mixture(mix[j], x) * trans[i, j] beta[t][:] = c[t] * beta[t][:] # 过渡概率ksai ksai = zeros((T - 1, N, N)) for t in range(0, T - 1): denom = sum(np.multiply(alpha[t][:], beta[t][:])) for i in range(N - 1): for j in range(i, i + 2, 1): norm = alpha[t, i] * trans[i, j] * \ self.mixture(mix[j], O[t + 1][:]) * beta[t + 1, j] ksai[t, i, j] = c[t] * norm / denom # 混合输出概率 gama gama = zeros((T, N, max(self.stateInfo))) for t in range(T): pab = zeros((N, 1)) for i in range(N): pab[i] = alpha[t, i] * beta[t, i] x = O[t][:] for i in range(N): prob = zeros((mix[i].CM, 1)) for j in range(mix[i].CM): m = mix[i].Cmean[j][:] v = mix[i].Cvar[j][:] prob[j] = mix[i].Cweight[j] * pdf(m, v, x) if mix[i].Cweight[j] == 0.0: print(pdf(m, v, x)) tmp = pab[i] / pab.sum() tmp = tmp[0] temp_sum = prob.sum() for j in range(mix[i].CM): gama[t, i, j] = tmp * prob[j] / temp_sum return c, alpha, beta, ksai, gama def mixture(self, mix, x): prob = 0.0 for i in range(mix.CM): m = mix.Cmean[i][:] v = mix.Cvar[i][:] w = mix.Cweight[i] tmp = pdf(m, v, x) # print tmp prob = prob + w * tmp # * pdf(m,v,x) if prob == 0.0: prob = 2e-100 return prob # 维特比算法 def viterbi(self, hmm, O): init = copy.deepcopy(hmm.init) trans = copy.deepcopy(hmm.trans) # hmm.trans mix = hmm.mix N = hmm.N T = shape(O)[0] # 计算Log(init) n_init = len(init) for i in range(n_init): if init[i] <= 0: init[i] = -inf else: init[i] = log(init[i]) # 计算log(trans) m, n = shape(trans) for i in range(m): for j in range(n): if trans[i, j] <= 0: trans[i, j] = -inf else: trans[i, j] = log(trans[i, j]) # 初始化 delta = zeros((T, N)) fai = zeros((T, N)) q = zeros((T, 1)) # t=0 x = O[0][:] for i in range(N): delta[0, i] = init[i] + log(self.mixture(mix[i], x)) # t=2:T for t in range(1, T): for j in range(N): tmp = delta[t - 1][:] + trans[:][j].T tmp = tmp.tolist() delta[t, j] = max(tmp) fai[t, j] = tmp.index(max(tmp)) x = O[t][:] delta[t, j] = delta[t, j] + log(self.mixture(mix[j], x)) tmp = delta[T - 1][:] tmp = tmp.tolist() prob = max(tmp) q[T - 1] = tmp.index(max(tmp)) for t in range(T - 2, -1, -1): q[t] = fai[t + 1, int(q[t + 1, 0])] return prob # 用于测试的程序 def vad(self, k, fs): k = double(k) k = multiply(k, 1.0 / max(abs(k))) # 计算短时过零率 FrameLen = 240 FrameInc = 80 FrameTemp1 = self.enframe(k[0:-2], FrameLen, FrameInc) FrameTemp2 = self.enframe(k[1:], FrameLen, FrameInc) signs = np.sign(multiply(FrameTemp1, FrameTemp2)) signs = list(map(lambda x: [[i, 0][i > 0] for i in x], signs)) signs = list(map(lambda x: [[i, 1][i < 0] for i in x], signs)) diffs = np.sign(abs(FrameTemp1 - FrameTemp2) - 0.01) diffs = list(map(lambda x: [[i, 0][i < 0] for i in x], diffs)) zcr = sum(multiply(signs, diffs), 1) # 计算短时能量 amp = sum(abs(self.enframe(signal.lfilter( [1, -0.9375], 1, k), FrameLen, FrameInc)), 1) # print '短时能量%f' %amp # 设置门限 print('设置门限') ZcrLow = max([round(mean(zcr) * 0.1), 3]) # 过零率低门限 ZcrHigh = max([round(max(zcr) * 0.1), 5]) # 过零率高门限 AmpLow = min([min(amp) * 10, mean(amp) * 0.2, max(amp) * 0.1]) # 能量低门限 AmpHigh = max([min(amp) * 10, mean(amp) * 0.2, max(amp) * 0.1]) # 能量高门限 # 端点检测 MaxSilence = 8 # 最长语音间隙时间 MinAudio = 16 # 最短语音时间 Status = 0 # 状态0:静音段,1:过渡段,2:语音段,3:结束段 HoldTime = 0 # 语音持续时间 SilenceTime = 0 # 语音间隙时间 print('开始端点检测') StartPoint = 0 for n in range(len(zcr)): if Status == 0 or Status == 1: if amp[n] > AmpHigh or zcr[n] > ZcrHigh: StartPoint = n - HoldTime Status = 2 HoldTime = HoldTime + 1 SilenceTime = 0 elif amp[n] > AmpLow or zcr[n] > ZcrLow: Status = 1 HoldTime = HoldTime + 1 else: Status = 0 HoldTime = 0 elif Status == 2: if amp[n] > AmpLow or zcr[n] > ZcrLow: HoldTime = HoldTime + 1 else: SilenceTime = SilenceTime + 1 if SilenceTime < MaxSilence: HoldTime = HoldTime + 1 elif (HoldTime - SilenceTime) < MinAudio: Status = 0 HoldTime = 0 SilenceTime = 0 else: Status = 3 elif Status == 3: break if Status == 3: break HoldTime = HoldTime - SilenceTime EndPoint = StartPoint + HoldTime return StartPoint, EndPoint def recog(self, pathTop): N = gParam.NUM for i in range(N): wavPath = pathTop + str(i) + '.wav' f = wave.open(wavPath, 'rb') params = f.getparams() nchannels, sampwidth, framerate, nframes = params[:4] str_data = f.readframes(nframes) # print shape(str_data) f.close() wave_data = np.fromstring(str_data, dtype=short) / 32767.0 x1, x2 = self.vad(wave_data, framerate) O = self.mfcc([wave_data]) O = O[x1 - 3:x2 - 3][:] print('第' + str(i) + '个词的观察矢量是:' + str(i)) pout = [] for j in range(N): pout.append(self.viterbi(self.gmm_hmm_model[j], O)) n = pout.index(max(pout)) print('第' + str(i) + '个词,识别是:' + str(n)) if __name__ == "__main__": pass
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
- 173
- 174
- 175
- 176
- 177
- 178
- 179
- 180
- 181
- 182
- 183
- 184
- 185
- 186
- 187
- 188
- 189
- 190
- 191
- 192
- 193
- 194
- 195
- 196
- 197
- 198
- 199
- 200
- 201
- 202
- 203
- 204
- 205
- 206
- 207
- 208
- 209
- 210
- 211
- 212
- 213
- 214
- 215
- 216
- 217
- 218
- 219
- 220
- 221
- 222
- 223
- 224
- 225
- 226
- 227
- 228
- 229
- 230
- 231
- 232
- 233
- 234
- 235
- 236
- 237
- 238
- 239
- 240
- 241
- 242
- 243
- 244
- 245
- 246
- 247
- 248
- 249
- 250
- 251
- 252
- 253
- 254
- 255
- 256
- 257
- 258
- 259
- 260
- 261
- 262
- 263
- 264
- 265
- 266
- 267
- 268
- 269
- 270
- 271
- 272
- 273
- 274
- 275
- 276
- 277
- 278
- 279
- 280
- 281
- 282
- 283
- 284
- 285
- 286
- 287
- 288
- 289
- 290
- 291
- 292
- 293
- 294
- 295
- 296
- 297
- 298
- 299
- 300
- 301
- 302
- 303
- 304
- 305
- 306
- 307
- 308
- 309
- 310
- 311
- 312
- 313
- 314
- 315
- 316
- 317
- 318
- 319
- 320
- 321
- 322
- 323
- 324
- 325
- 326
- 327
- 328
- 329
- 330
- 331
- 332
- 333
- 334
- 335
- 336
- 337
- 338
- 339
- 340
- 341
- 342
- 343
- 344
- 345
- 346
- 347
- 348
- 349
- 350
- 351
- 352
- 353
- 354
- 355
- 356
- 357
- 358
- 359
- 360
- 361
- 362
- 363
- 364
- 365
- 366
- 367
- 368
- 369
- 370
- 371
- 372
- 373
- 374
- 375
- 376
- 377
- 378
- 379
- 380
- 381
- 382
- 383
- 384
- 385
- 386
- 387
- 388
- 389
- 390
- 391
- 392
- 393
- 394
- 395
- 396
- 397
- 398
- 399
- 400
- 401
- 402
- 403
- 404
- 405
- 406
- 407
- 408
- 409
- 410
- 411
- 412
- 413
- 414
- 415
- 416
- 417
- 418
- 419
- 420
- 421
- 422
- 423
- 424
- 425
- 426
- 427
- 428
- 429
- 430
- 431
- 432
- 433
- 434
- 435
- 436
- 437
- 438
- 439
- 440
- 441
- 442
- 443
- 444
- 445
- 446
- 447
- 448
- 449
- 450
- 451
- 452
- 453
- 454
- 455
- 456
- 457
- 458
- 459
- 460
- 461
- 462
- 463
- 464
- 465
- 466
- 467
- 468
- 469
- 470
- 471
- 472
- 473
- 474
- 475
- 476
- 477
- 478
- 479
- 480
- 481
- 482
- 483
- 484
- 485
- 486
- 487
- 488
- 489
- 490
- 491
- 492
- 493
- 494
- 495
- 496
- 497
- 498
- 499
- 500
- 501
- 502
- 503
- 504
- 505
- 506
- 507
- 508
- 509
- 510
- 511
- 512
- 513
- 514
- 515
- 516
- 517
- 518
- 519
- 520
- 521
- 522
- 523
- 524
- 525
- 526
- 527
- 528
- 529
- 530
- 531
- 532
- 533
- 534
- 535
- 536
- 537
- 538
- 539
- 540
- 541
- 542
- 543
- 544
- 545
- 546
- 547
- 548
- 549
- 550
- 551
- 552
- 553
- 554
- 555
- 556
- 557
- 558
- 559
- 560
- 561
- 562
- 563
- 564
- 565
- 566
- 567
- 568
- 569
- 570
- 571
- 572
- 573
- 574
- 575
- 576
- 577
- 578
- 579
- 580
- 581
- 582
- 583
- 584
- 585
- 586
- 587
- 588
- 589
- 590
- 591
- 592
- 593
- 594
- 595
- 596
- 597
- 598
- 599
- 600
- 601
- 602
- 603
- 604
- 605
- 606
- 607
- 608
- 609
- 610
- 611
- 612
- 613
- 614
- 615
- 616
- 617
- 618
- 619
- 620
- 621
- 622
- 623
- 624
- 625
- 626
- 627
- 628
- 629
- 630
- 631
- 632
- 633
- 634
- 635
- 636
- 637
- 638
- 639
- 640
- 641
- 642
- 643
- 644
- 645
- 646
- 647
这里是运行结果:



声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/不正经/article/detail/390602
推荐阅读
相关标签

