
热门标签
热门文章
- 1图谱可视化开源库_知识图谱可视化开源
- 2Hadoop_HA配置过程记录_hadoop配置ha详细步骤
- 32022的顺子日期数(C语言实现)_20220123 就是一个顺子日期,因为它出现了一个顺子:123; 而 20221023 则不是一个
- 4ChatGPT 与 OpenAI 的现代生成式 AI(下)
- 5自然语言处理(NLP)—— 语言学、结构的主要任务_自然语言处理实施者受试者
- 6jiagu、snownlp、jieba对比_jiagu jieba
- 7Mask Rcnn 实践小结 —— 训练自己的数据集_image_ids =np.random.choice(dataset_val10)aps = []
- 8js获取当前日期和前后“N天”日期,严谨版_js 当前日期的365天
- 9unable to load class 'org.*****'的问题_unable to load class 'org.gradle.tooling.unsupport
- 10【踩坑记录:vue3的项目安装element-ui失败报错,解决方案】_安装elment时vue3出错
当前位置: article > 正文
python爬虫获取子域名以及对“百度安全验证”问题的解决_爬虫 百度安全验证
作者:不正经 | 2024-04-10 10:22:15
赞
踩
爬虫 百度安全验证
编写的python代码是在借鉴老师给的资料的基础上实现的
进行课堂实践:模仿bing搜索引擎域名收集功能,实现baidu搜索引擎的域名搜集功能时,走了不少弯路,最后终于形成了完整的思路。尤其是在“百度安全验证”问题上耗费的时间之久,就因为忽略了cookie的有效获取
公开信息搜集之子域名搜集的语法
- bing搜索引擎获取子域名的语法为:domain:[域名]
eg:通过bing搜索引擎获取baidu.com域名下的子域名,需输入的语法为:domain:baidu.com - baidu搜索引擎获取子域名的语法为:site:[域名]
eg:通过baidu搜索引擎获取baidu.com域名下的子域名,需输入的语法为:site:baidu.com
编写python代码与实现过程
导入相应模块
import requests #用于请求网页资源
from bs4 import BeautifulSoup #用于处理获取的网页源码数据
from urllib.parse import urlparse #用于处理url
"""若没有这些模块,可在安装的python文件下执行命令“pip install requests”或“pip install bs4”或“pip install urllib.parse”进行下载"""
- 1
- 2
- 3
- 4
- 5
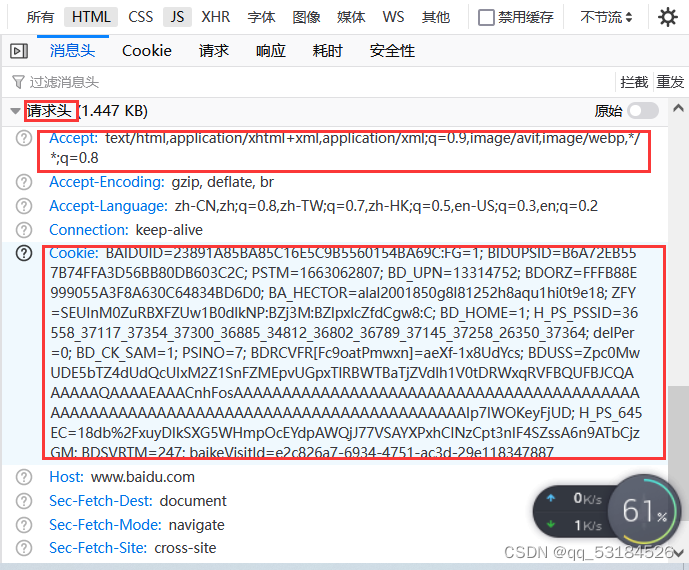
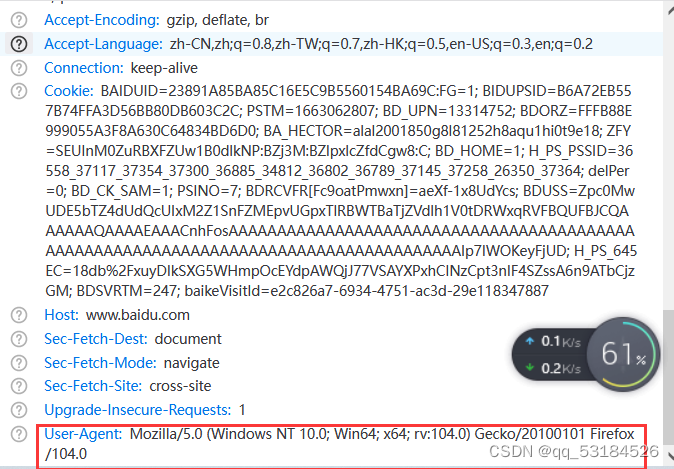
在baidu搜索引擎上获取请求相应网页资源时,需要的部分请求头信息
注意:在进行子域名搜集之前,请确保已登录百度,否则获取的cookie不起作用,其他搜索引擎同理
未登录时的界面

获取无效cookie的运行结果
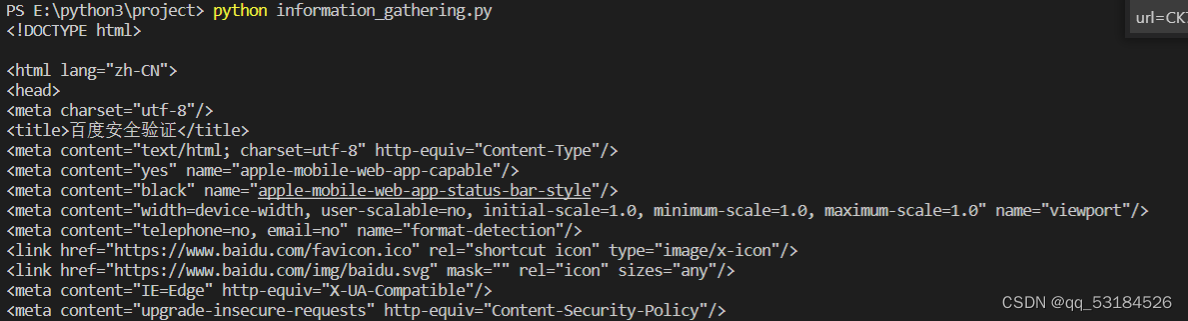
未登录时获取无效cookie来定义请求头,得到的响应内容为“百度安全验证”与“网络不给力,请稍后重试”、“返回首页”、“问题反馈”
出现此问题也还可能是请求头定义不完善被反爬了,从网上搜索的资料看大多是因为请求头缺少“Accept”
已登录后的界面

python爬虫需要定义请求头以绕过反扒机制,而定义请求头信息需从一下几步获取
- 进入百度搜索引擎首页,输入:site:baidu.com,这里以火狐浏览器为例


- 按F12键进入开发者工具=》点击网络项=》Ctrl+R更新
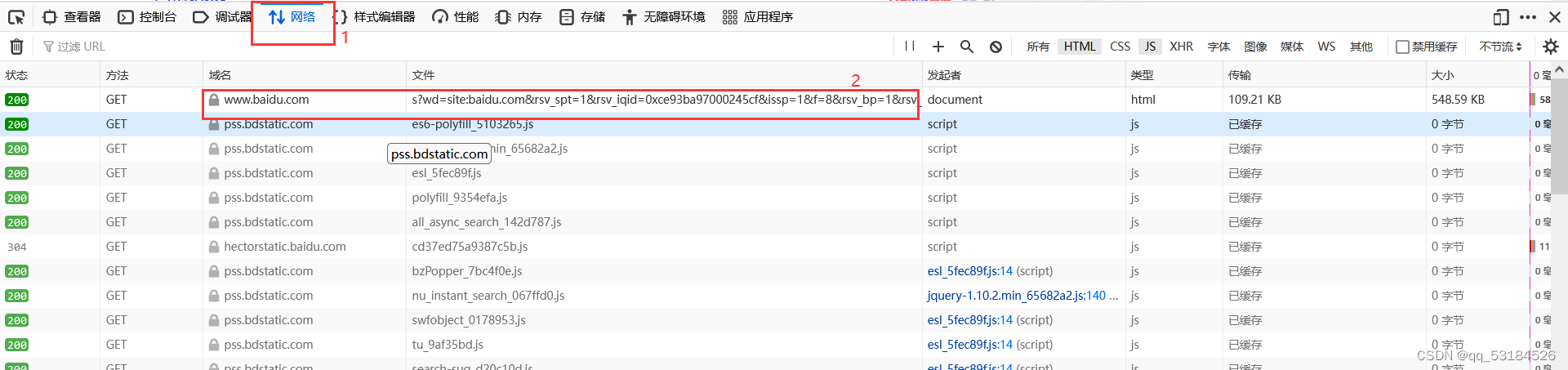
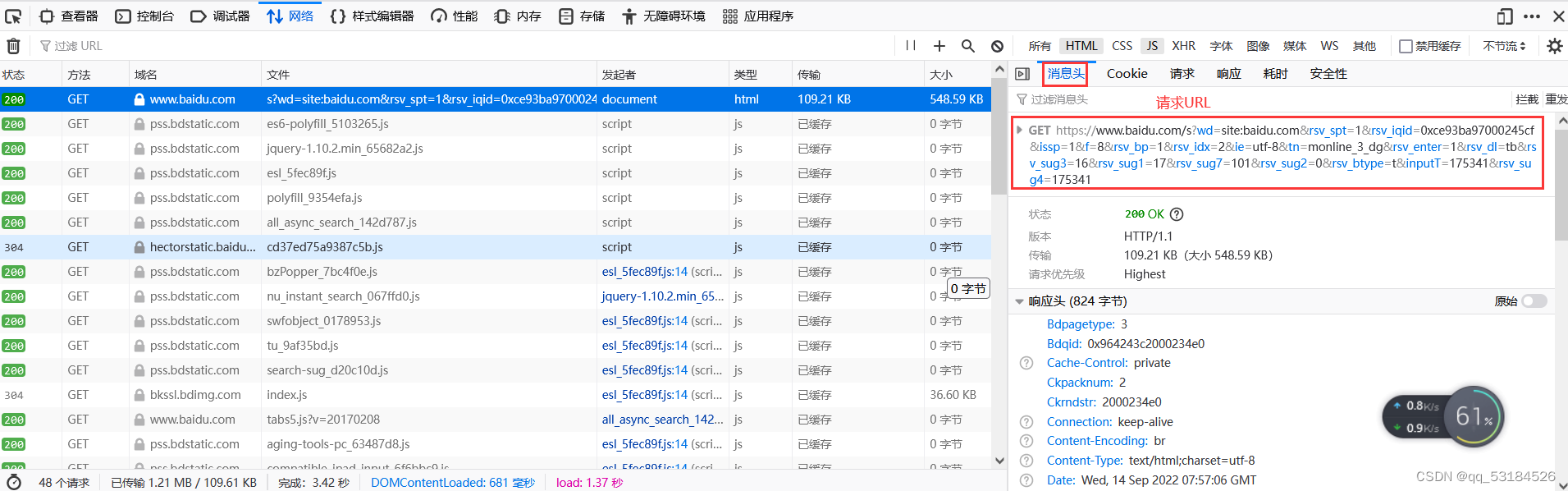
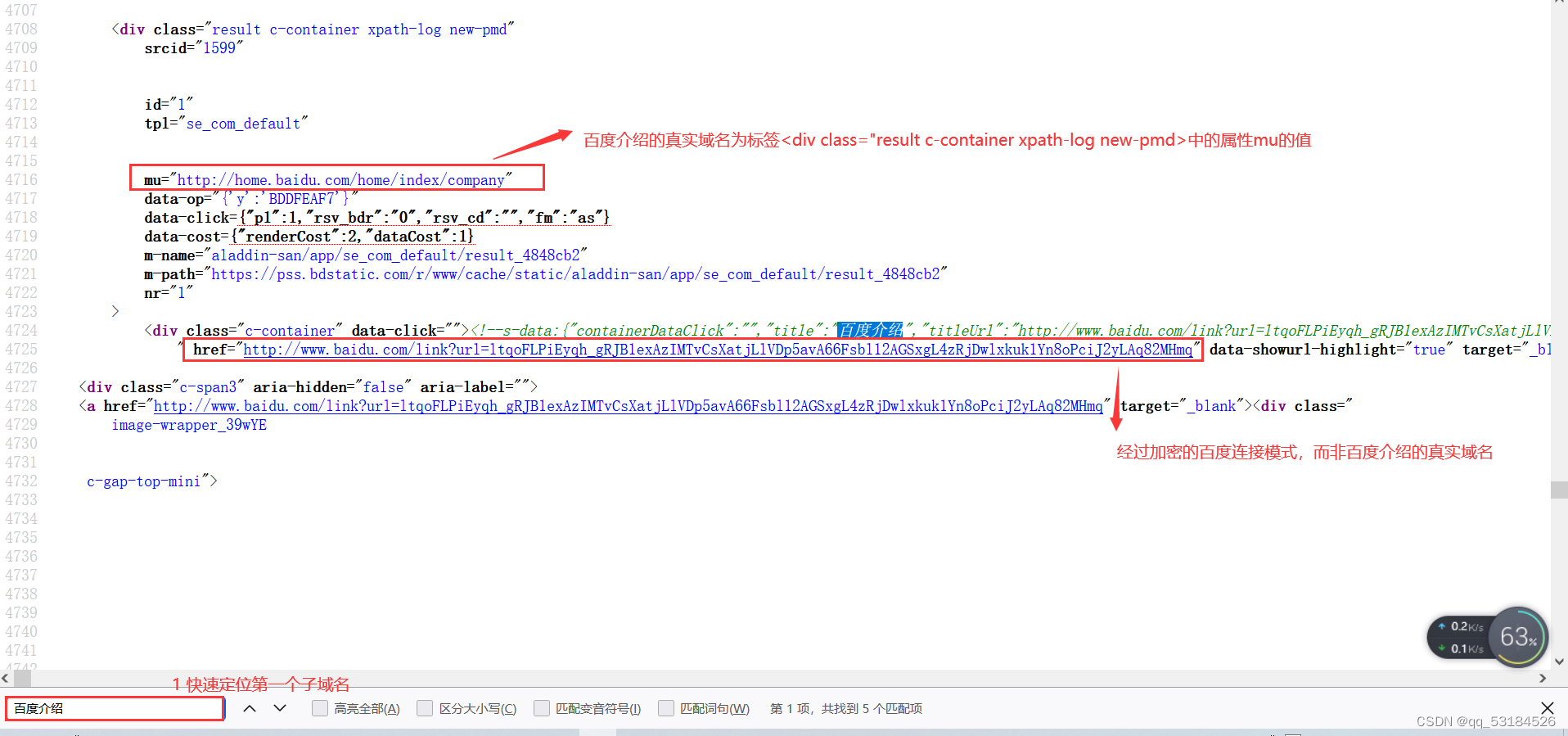
- 查看子域名收集返回网页的网页源码,找出子域名所在的标签和书写格式,以便于编写代码获取
- 代码编写
#定义baidu搜索引擎的子域名搜集功能的函数
def baidu_search(): Subdomain2 = [] #定义一个空列表用于存储收集到的子域名 #定义请求头,绕过反爬机制 hearders = { 'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:104.0) Gecko/20100101 Firefox/104.0', 'accept':'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,*/*;q=0.8', 'referer':'', #该请求没有来源网页可不填 'cookie':'BAIDUID=23891A85BA85C16E5C9B5560154BA69C:FG=1; BIDUPSID=B6A72EB557B74FFA3D56BB80DB603C2C; PSTM=1663062807; BD_UPN=13314752; BDORZ=FFFB88E999055A3F8A630C64834BD6D0; BA_HECTOR=alal2001850g8l81252h8aqu1hi0t9e18; ZFY=SEUInM0ZuRBXFZUw1B0dlkNP:BZj3M:BZlpxlcZfdCgw8:C; BD_HOME=1; H_PS_PSSID=36558_37117_37354_37300_36885_34812_36802_36789_37145_37258_26350_37364; delPer=0; BD_CK_SAM=1; PSINO=7; BDRCVFR[Fc9oatPmwxn]=aeXf-1x8UdYcs; BDUSS=Zpc0MwUDE5bTZ4dUdQcUIxM2Z1SnFZMEpvUGpxTlRBWTBaTjZVdlh1V0tDRWxqRVFBQUFBJCQAAAAAAQAAAAEAAACnhFosAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAIp7IWOKeyFjUD; H_PS_645EC=18db%2FxuyDIkSXG5WHmpOcEYdpAWQjJ77VSAYXPxhCINzCpt3nIF4SZssA6n9ATbCjzGM; BDSVRTM=247; baikeVisitId=e2c826a7-6934-4751-ac3d-29e118347887' } #定义请求url url = "https://www.baidu.com/s?wd=site:baidu.com&rsv_spt=1&rsv_iqid=0xce93ba97000245cf&issp=1&f=8&rsv_bp=1&rsv_idx=2&ie=utf-8&tn=monline_3_dg&rsv_enter=1&rsv_dl=tb&rsv_sug3=16&rsv_sug1=17&rsv_sug7=101&rsv_sug2=0&rsv_btype=t&inputT=175341&rsv_sug4=175341" resp = requests.get(url,headers=hearders) #访问url,获取网页源码 #print(resp.content.decode())等价于print(soup),变量soup在下面定义,是解析过的网页内容 soup = BeautifulSoup(resp.content,'html.parser') #创建一个BeautifulSoup对象,第一个参数是网页源码,第二个参数是Beautiful Soup 使用的 HTML 解析器, #print(soup) job_bt = soup.find_all('div',class_="result c-container xpath-log new-pmd") #find_all()查找源码中所有<div class_="result c-container xpath-log new-pmd"> 标签的内容 for i in job_bt: #遍历获取的标签 link = i.get('mu') #获取属性mu的值 #urlparse是一个解析url的工具,scheme获取url的协议名,netloc获取url的网络位置 domain = str(urlparse(link).scheme + "://" + urlparse(link).netloc) if domain in Subdomain2: #如果解析后的domain存在于Subdomain2中则跳过,否则将domain存入子域名表中 pass else: Subdomain2.append(domain) print(domain) #调用函数baidu_search() baidu_search()

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
-
运行结果

-
优化:给获取的子域名添加描述
查看网页源码,找到子域名描述的位置

#子域名的描述在标签<div class="result c-container xpath-log new-pmd">下的标签<div class="c-container">下的标签<h3>下的标签<a>的“标题”中
- 1
#获取标签“<a>"的“标题”的方法为get_text()
- 1
代码
for i in job_bt: #遍历获取的标签
link = i.get('mu') #获取属性mu的值
#获取子域名的描述,注意:变量的命名不可与关键字、方法名等重叠,否则会报错:"str" object is not callable
string=i.find('div',class_="c-container").find('h3').find('a').get_text()
#urlparse是一个解析url的工具,scheme获取url的协议名,netloc获取url的网络位置
domain = str(urlparse(link).scheme + "://" + urlparse(link).netloc)
if domain in Subdomain2: #如果解析后的domain存在于Subdomain2中则跳过,否则将domain存入子域名表中
pass
else:
Subdomain2.append(domain)
print(domain+'\t'+string) #输出进行字符串拼接
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
运行结果:

声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/不正经/article/detail/398125
推荐阅读
相关标签

