
- 1计算机视觉 Code 合集_code 视觉
- 2AUTOSAR-OS上层需求总结_autosar os软件需求
- 3solaris迅速查找手册_solaris 查找僵尸进程
- 4宿舍管理系统--毕业设计
- 5Unity常见问题(一)缺少引用_unity对象未设置引用怎么办
- 6git添加文件到码云gitee或者GitHub的时候出现警告warning: adding embedded git repository:_warning: adding embedded git repository: spoon-kni
- 7MATLAB矩阵操作与编程技巧_matlab中如何将保存的矩阵用到代码中
- 8身份证识别_身份证识别 csdn
- 9Android 课设之个人音乐播放器_桂电android课设
- 10和君商学院推荐读书单——第四章 | 推荐阅读报刊和网站 39个_和君商学院推荐书籍
Flink第一章:环境搭建
赞
踩
系列文章目录
Flink第一章:环境搭建
前言
Flink也是现在现在大数据技术中火爆的一门,反正大数据的热门技术学的也差不多了,啃完Flink基本的大数据技术就差不多哦学完了.
一、Idea项目
1.创建项目
略
2.pom.依赖
这里说明一下我选择的环境.
java8
scala2.12
flink采用最新的1.17
请大家根据自己的环境更换版本
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>groupId</groupId>
<artifactId>FlinkTutorial</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
<flink.version>1.17.0</flink.version>
<target.java.version>1.8</target.java.version>
<scala.binary.version>2.12</scala.binary.version>
</properties>
<dependencies>
<!-- 引入 Flink 相关依赖-->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-scala_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-scala_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients</artifactId>
<version>${flink.version}</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>3.2.0</version>
<executions>
<execution>
<!-- 声明绑定到 maven 的 compile 阶段 -->
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-assembly-plugin</artifactId>
<version>3.0.0</version>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
3.DataSet
注:这里使用DataSet对数据进行批处理,但是在新版本flink中DataStreaming已经做到了流批一体,未来会慢慢移除DataSet接口,所以这里只是做个示例.
BatchWC.scala
package com.atguigu.chapter01
import org.apache.flink.api.scala.{AggregateDataSet, DataSet, ExecutionEnvironment, GroupedDataSet, createTypeInformation}
object BatchWC {
def main(args: Array[String]): Unit = {
//1.创建执行环境
val env: ExecutionEnvironment = ExecutionEnvironment.getExecutionEnvironment
//2.读取文本数据
val lineData: DataSet[String] = env.readTextFile("input/word.txt")
//3.对数据进行处理
val wordAneOne: DataSet[(String, Int)] = lineData.flatMap(_.split(" ")).map(word => (word, 1))
val wordAndOneGroup: GroupedDataSet[(String, Int)] = wordAneOne.groupBy(0)
val sum: AggregateDataSet[(String, Int)] = wordAndOneGroup.sum(1)
sum.print()
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
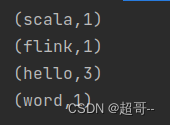
4.DataStreaming
DataStreaming进行批处理
BoundedStreamingWordCount.scala
package com.atguigu.chapter01
import org.apache.flink.streaming.api.scala._
object BoundedStreamingWordCount{
def main(args: Array[String]): Unit = {
//1.创建一个流式执行环境
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
//2.读取文本文件
val lineDataStreaming: DataStream[String] = env.readTextFile("input/word.txt")
//3.对数据进行处理
val wordAneOne: DataStream[(String, Int)] = lineDataStreaming.flatMap(_.split(" ")).map(word => (word, 1))
val wordAndOneGroup: KeyedStream[(String, Int), String] = wordAneOne.keyBy(_._1)
val sum: DataStream[(String, Int)] = wordAndOneGroup.sum(1)
sum.print()
//4.执行方法
env.execute()
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
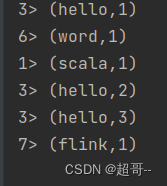
DataStreaming进行流处理
StreamingWC.scala
package com.atguigu.chapter01
import org.apache.flink.streaming.api.scala._
object StreamingWC{
def main(args: Array[String]): Unit = {
//1.创建一个流式执行环境
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
//2.读取文本文件
val lineDataStreaming: DataStream[String] = env.socketTextStream("hadoop102",7777)
//3.对数据进行处理
val wordAneOne: DataStream[(String, Int)] = lineDataStreaming.flatMap(_.split(" ")).map(word => (word, 1))
val wordAndOneGroup: KeyedStream[(String, Int), String] = wordAneOne.keyBy(_._1)
val sum: DataStream[(String, Int)] = wordAndOneGroup.sum(1)
sum.print()
//4.执行方法
env.execute()
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
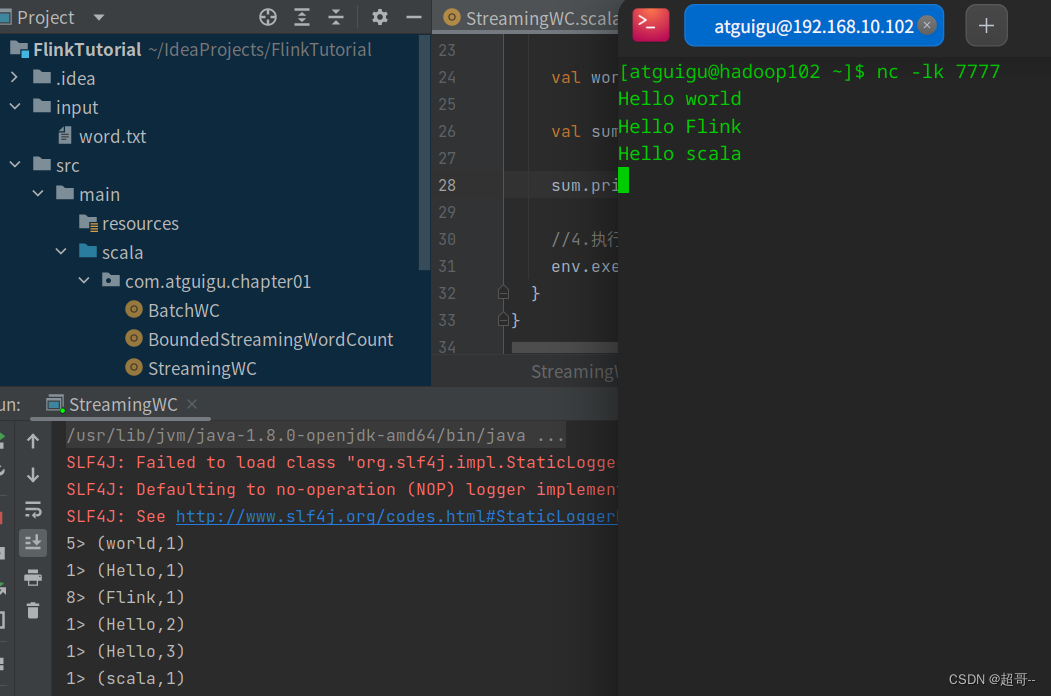
这里我们选择对hadoop102的7777端口进行监听,所以要提前打开虚拟机.
输入数据查看结果
二、环境搭建

我们直接使用官方推荐最新版.
官方下载连接
1.Standalone
但节点模式,一般用于数据测试,我们在hadoop102上进行.
上传并解压文件
tar -xvf flink-1.17.0-bin-scala_2.12.tgz -C /opt/module/
cd ../module/
mv flink-1.17.0/ flink
- 1
- 2
- 3
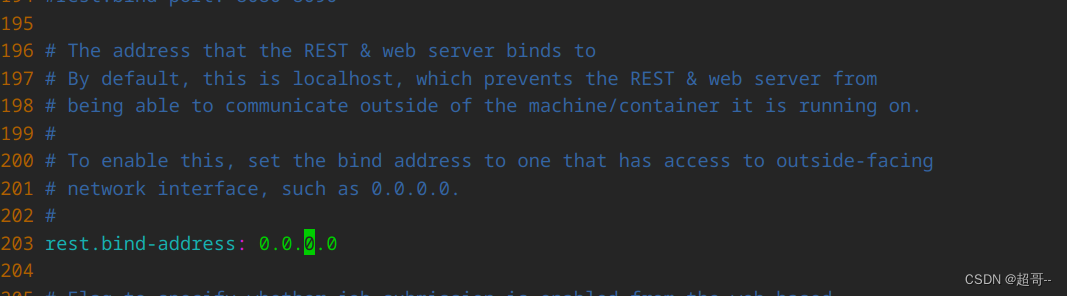
修改配置
本来单节点是不需要修改配置的,但是咱们虚拟机没有桌面,需要从外部访问,所以还是需要修改一下.

在203行修改,或者用vim的搜索功能.
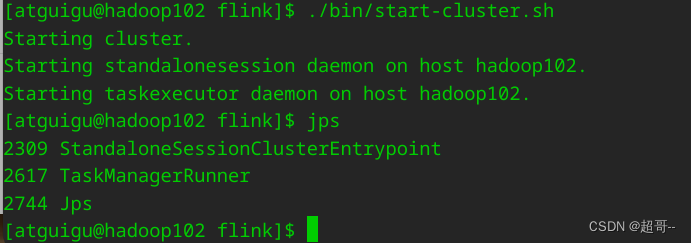
启动Flink
./bin/start-cluster.sh
- 1
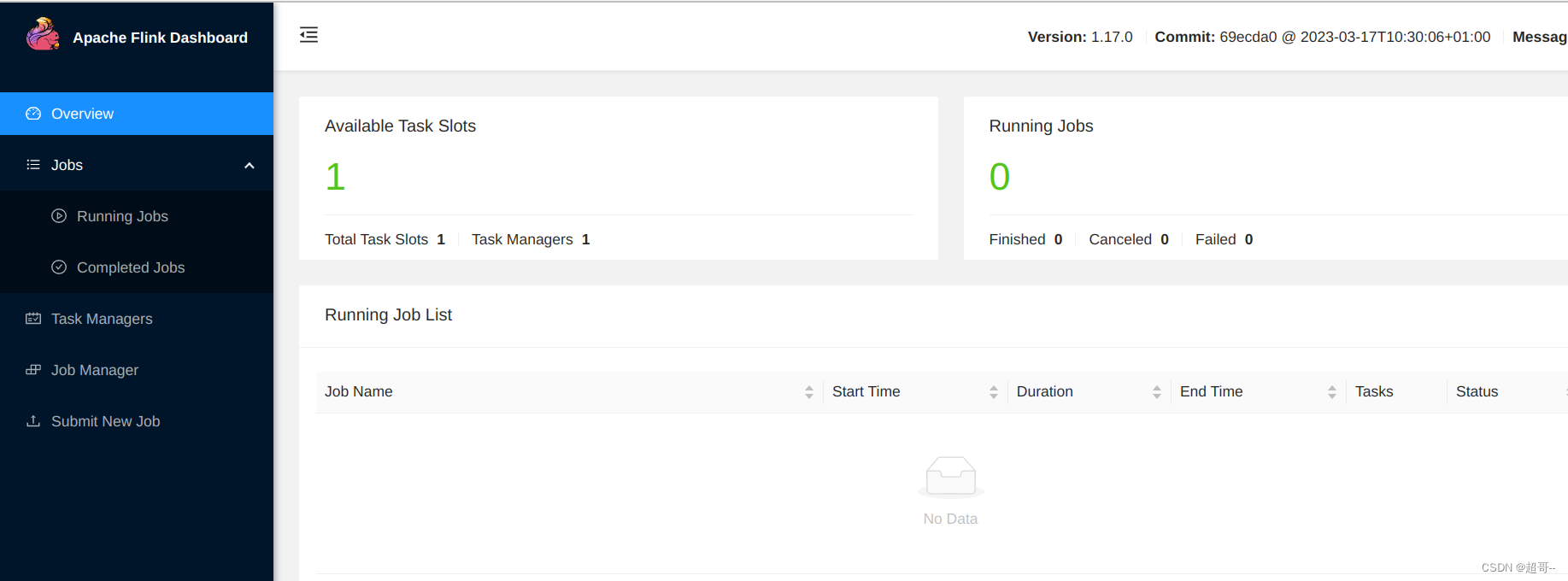
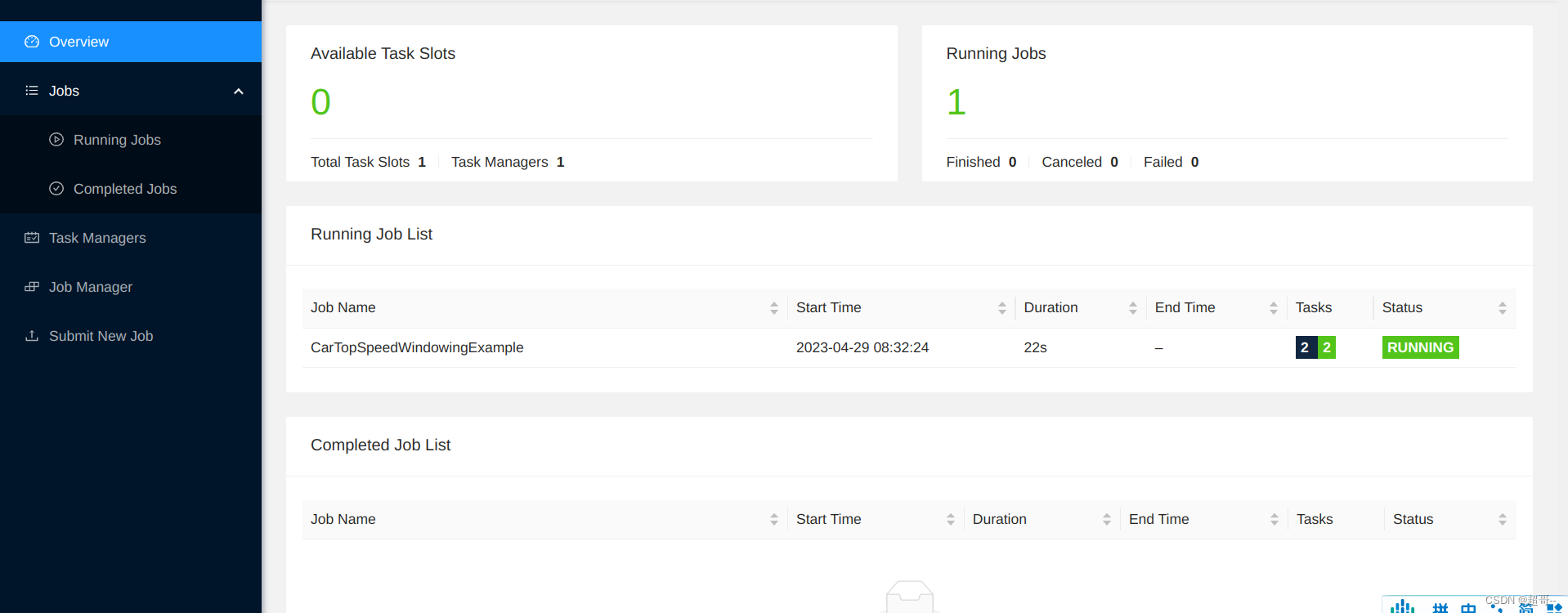
在Web UI界面查看一下
hadoop102:8081
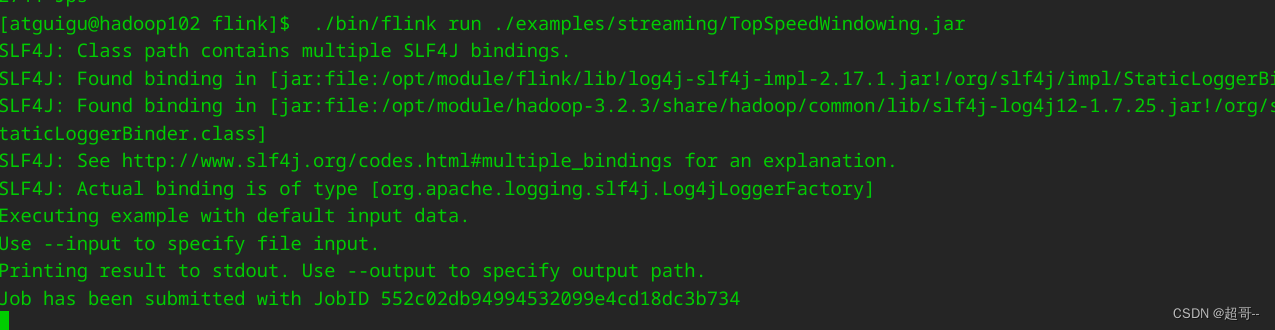
现在我们跑一下官方的测试案例进行测试.
./bin/flink run ./examples/streaming/TopSpeedWindowing.jar
- 1
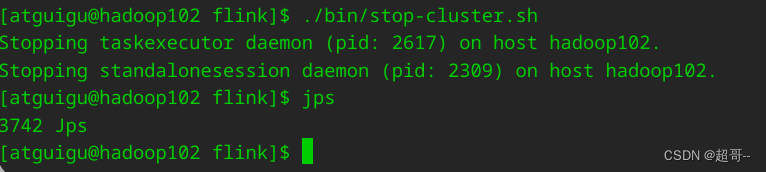
然后直接停掉集群Flink就行了,命令行操作,咱们后边再说.
./bin/stop-cluster.sh
- 1
2.Flink on Yarn
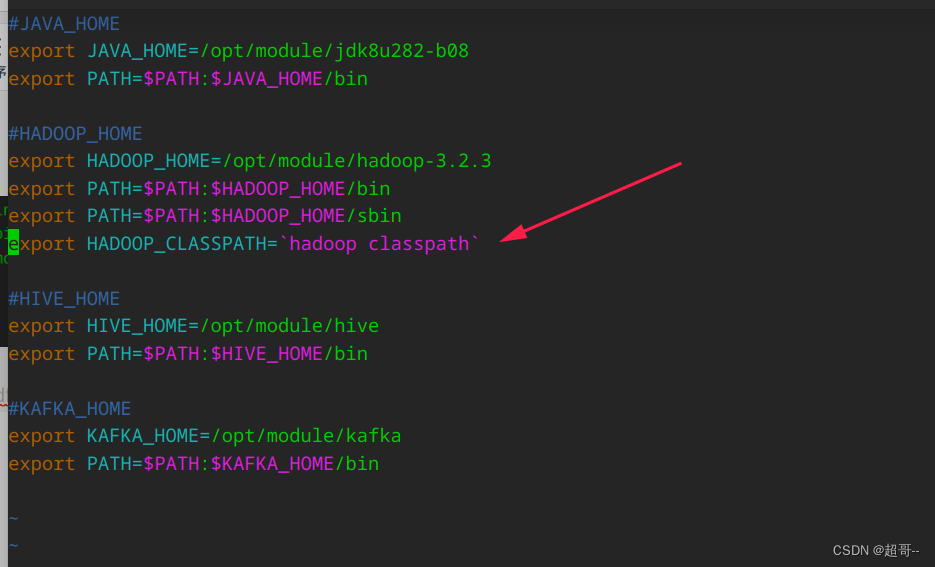
修改环境变量
vim /etc/profile.d/my_env.sh
- 1
新增这一行是Flink文档中要求,我也不知道啥意思
然后source环境.
修改配置文件
vim ./conf/masters
- 1
vim ./conf/workers
- 1
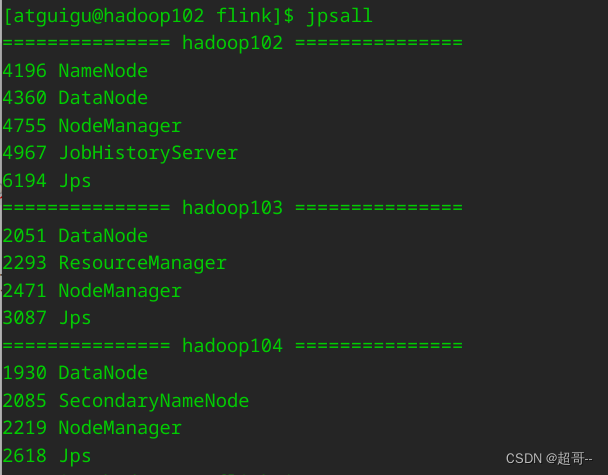
修改完之后,启动集群.
因为我们在Yarn上完成任务,所以我们要启动Hadoop集群.
向Yar提交任务,有三证模式,其中包括.
会话模式,应用模式,单作业模式.
应用程序模式将在 YARN 上启动一个 Flink 集群,其中应用程序 jar 的 main() 方法在 YARN 中的 JobManager 上执行。 应用程序完成后,群集将立即关闭。您可以使用或通过取消 Flink 作业手动停止集群。
会话模式有两种操作模式:
附加模式(默认):客户端将 Flink 集群提交到 YARN,但客户端继续运行,跟踪集群的状态。如果群集失败,客户端将显示错误。如果客户端被终止,它也会向群集发出关闭信号。yarn-session.sh
分离模式(或):客户端将 Flink 集群提交到 YARN,然后客户端返回。需要再次调用客户端或 YARN 工具来停止 Flink 集群。-d–detachedyarn-session.sh
单作业模式
单作业集群模式将在 YARN 上启动一个 Flink 集群,然后在本地运行提供的应用程序 jar,最后将 JobGraph 提交给 YARN 上的 JobManager。如果传递参数,则客户端将在接受提交后停止。–detached
官方建议使用应用模式,并且单作业模式已经从1.15之后就被移除了,所以咱们只演示前两种.
如果日后工作有需要,自己看看文档就行了
应用模式
这里直接跑官方给的案例了.
./bin/flink run-application -t yarn-application ./examples/streaming/TopSpeedWindowing.jar
- 1

记住这里给的项目appID 后边要用
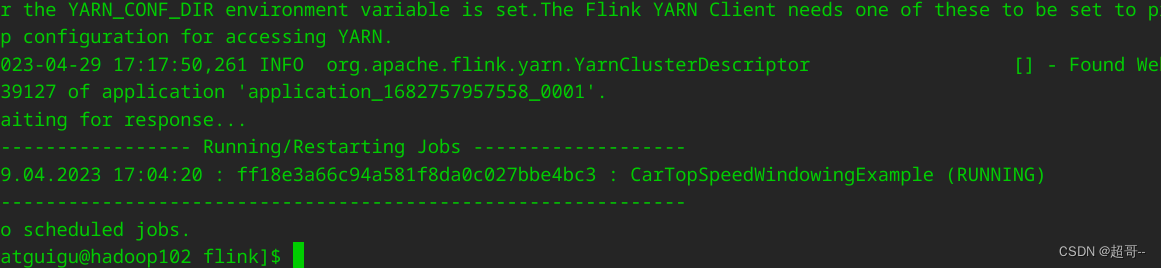
查看项目
./bin/flink list -t yarn-application -Dyarn.application.id=application_1682757957558_0001
- 1
停止项目
./bin/flink cancel -t yarn-application -Dyarn.application.id=application_1682757957558_0001 ff18e3a66c94a581f8da0c027bbe4bc3
- 1

当集群上没有项目时,项目就会停止,这时在查看项目,就会报错.
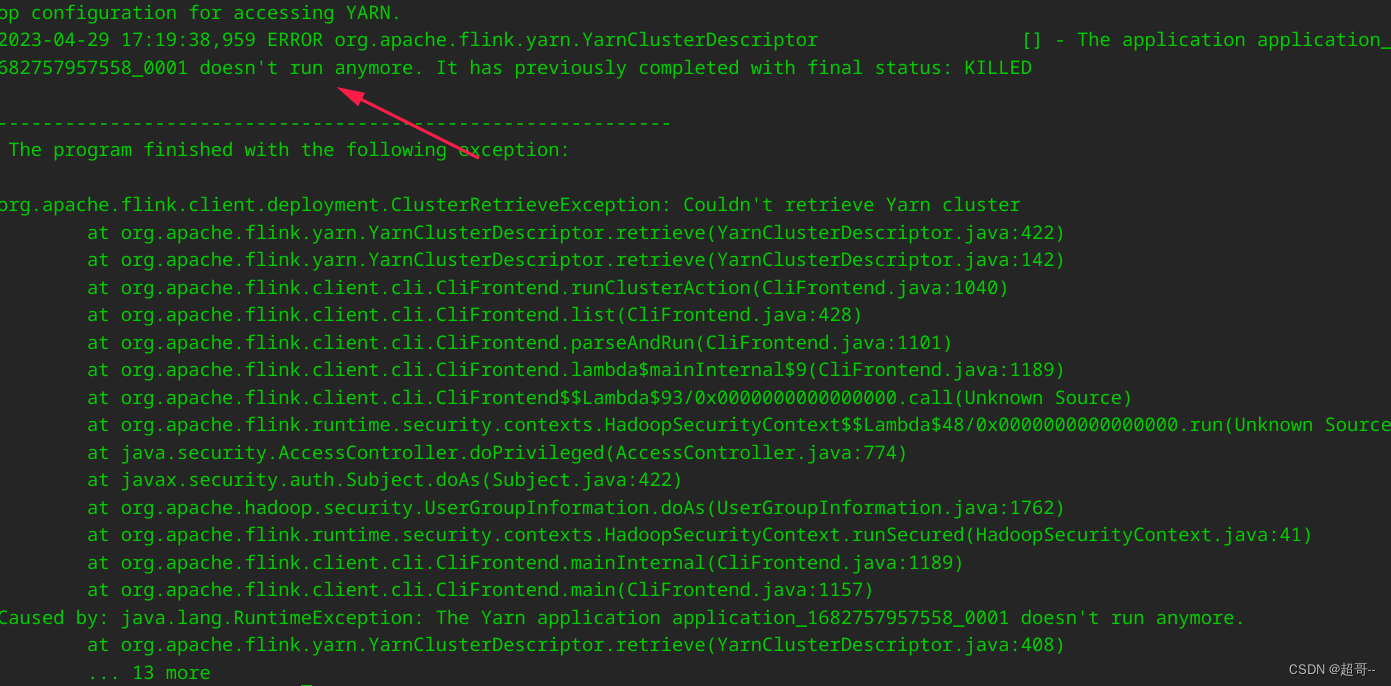
由于当项目全部停止后,集群就会停止,所以当你的集群经常只跑单个项目时,就总会重启集群,所以生产中也不是最常用的.
生产中最常用的还是会话模式,它可以在没有项目运行的时候也使Flink集群处于启动状态.
会话模式
创建会话
bin/yarn-session.sh -nm test -d
- 1
-nm 指定会话名称
-d 将当前会话挂载到后台
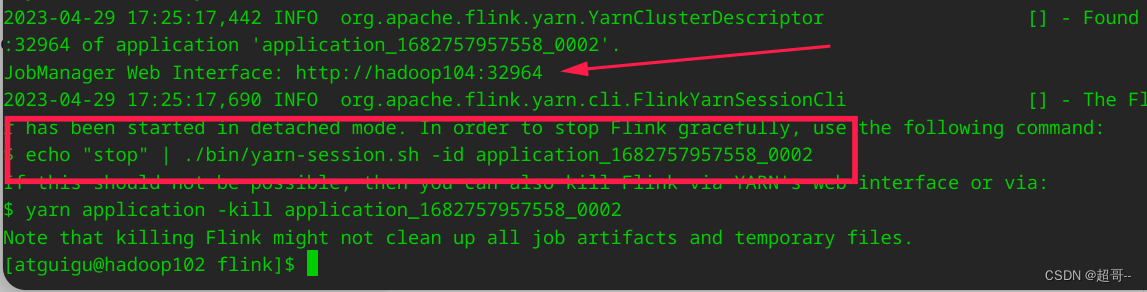
启动成功后,有两条日志需要注意一下,一个是Web UI的网址,一个是关掉会话的方法.
我们先去Web查看一下
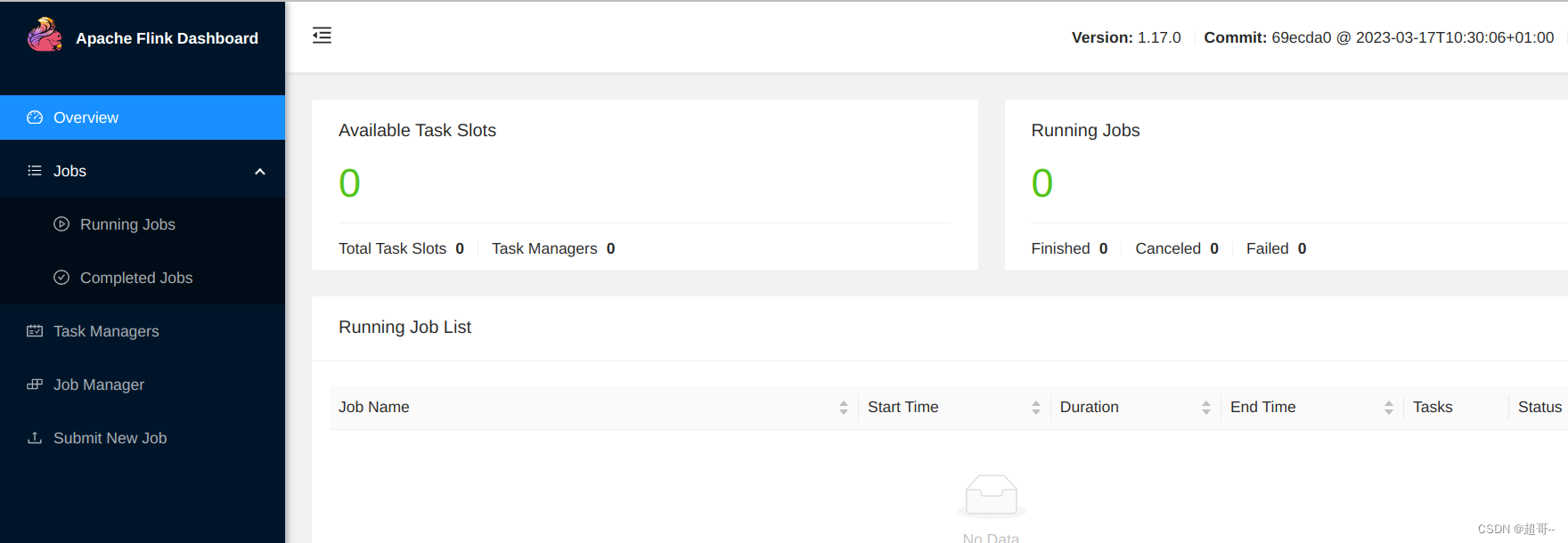
因为他是动态分配,所以显示的可用资源永远都是0,当任务提交时,他会向Yarn申请资源,然后执行任务.
我们将之前写的代码打包然后将其提交到hadoop102Flink文件

提交任务
记得要开启nc
./bin/flink run -c com.atguigu.chapter01.StreamingWC ./FlinkTutorial-1.0-SNAPSHOT.jar
- 1

Web查看一下
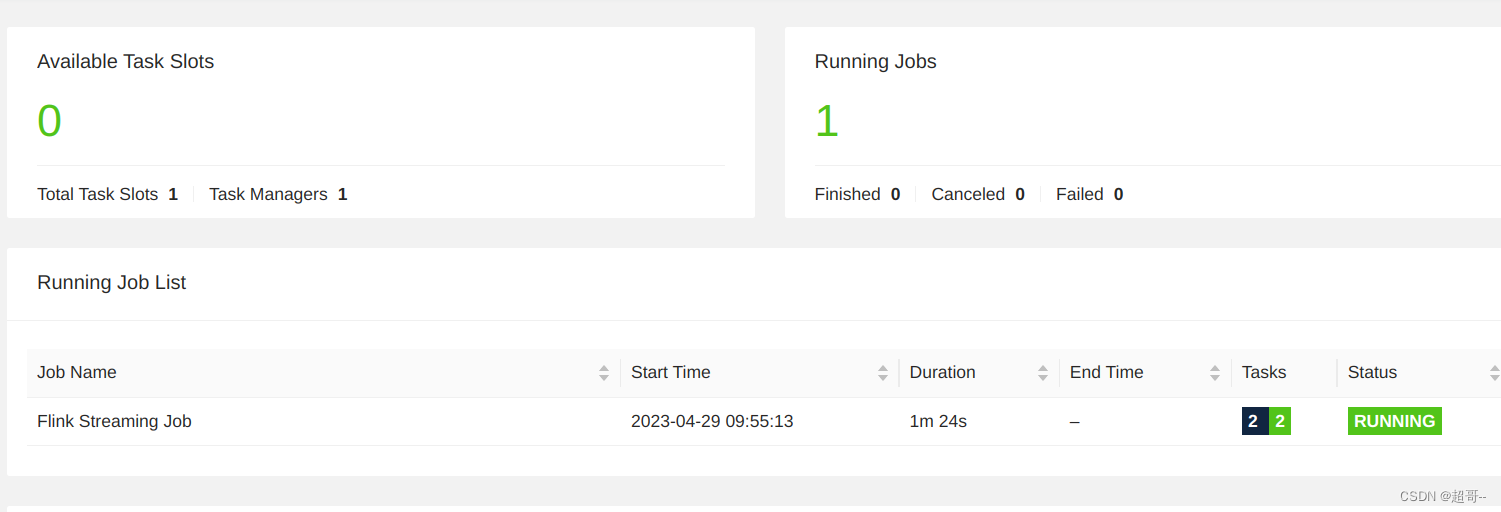
可用资源还是0,但是这个任务已经跑一起来了,现在查看一下效果.
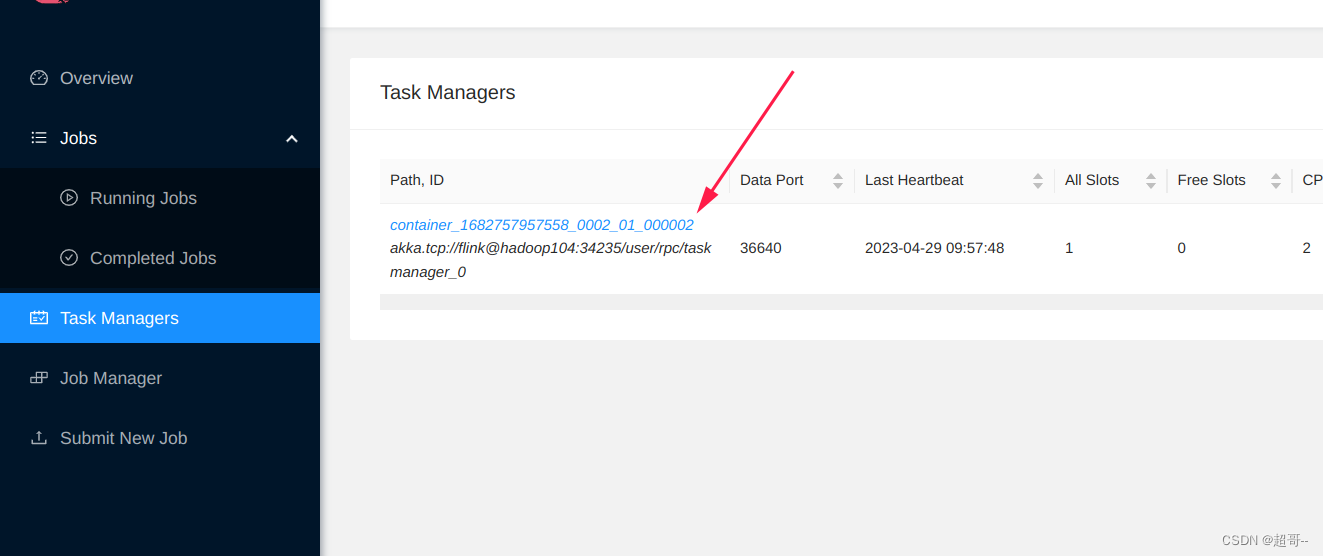
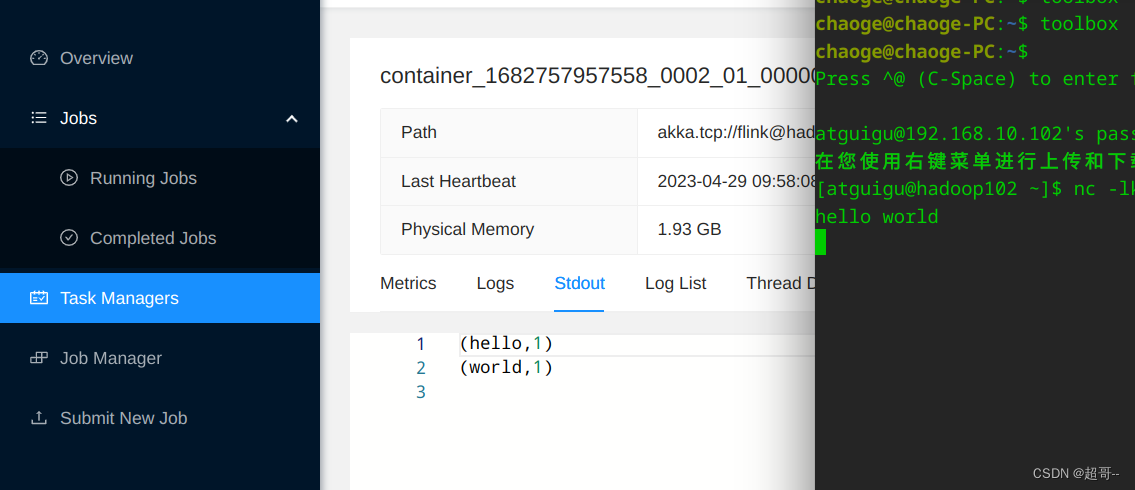
关闭项目.
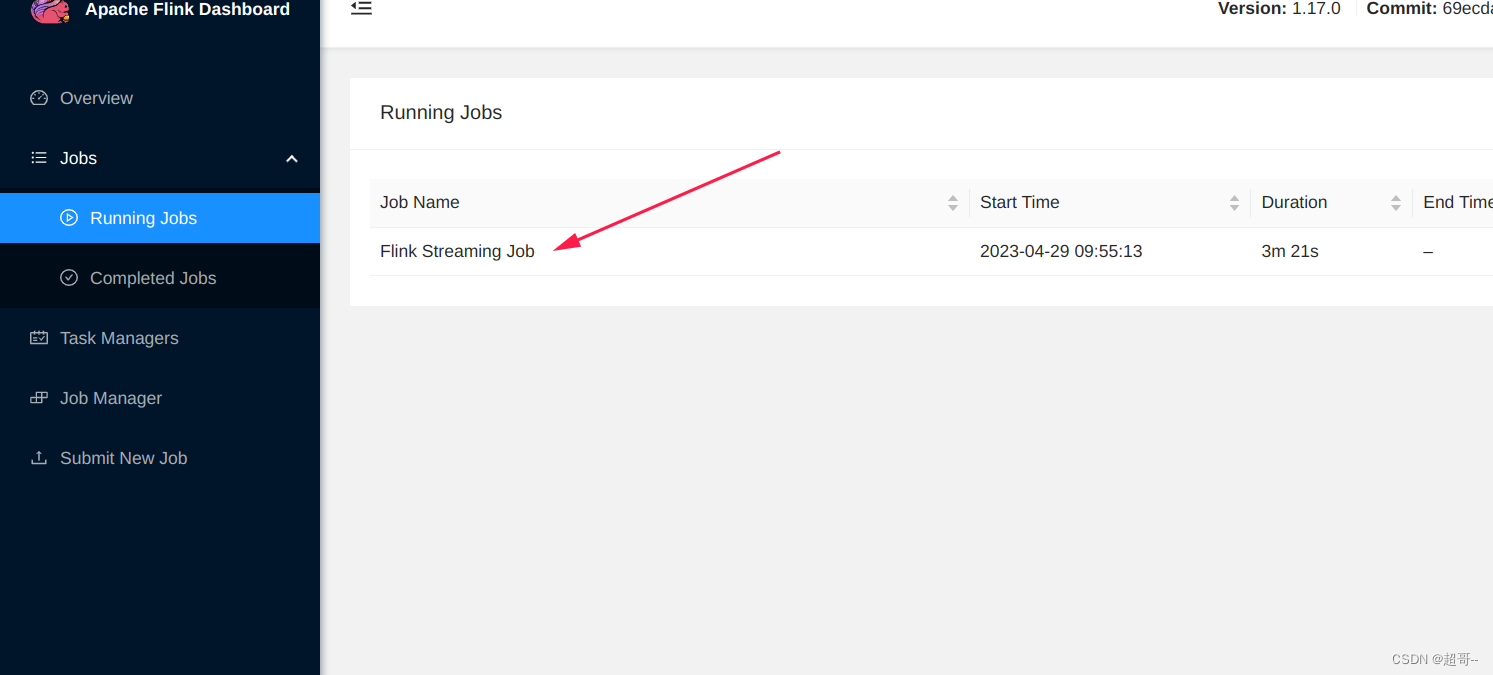
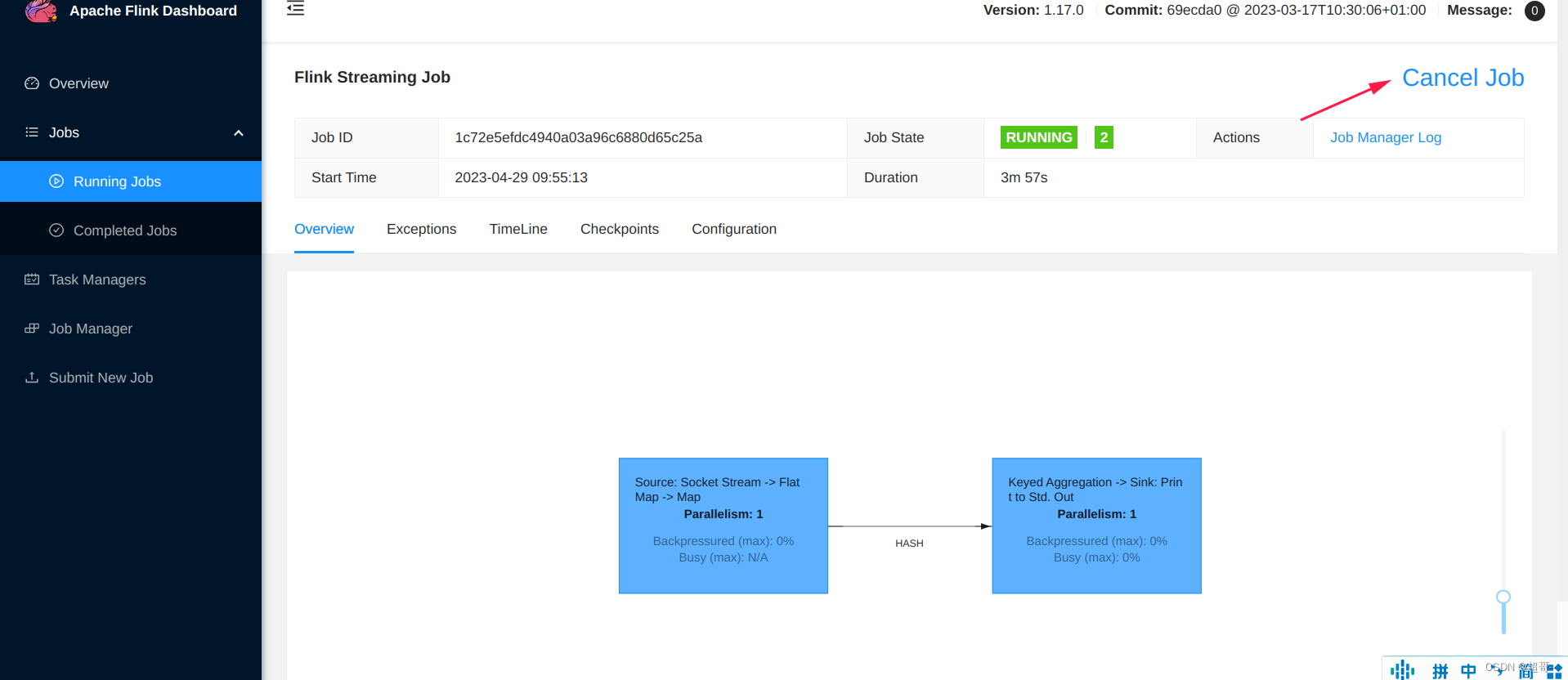
关闭会话
echo "stop" | ./bin/yarn-session.sh -id application_1682757957558_0002
- 1
至此Flink环境搭建完成,建议保留快照
总结
Flink是做数据实时分析必不可少的技术,也要学习.

