
- 1通过可视化交互式闯关游戏帮你快速掌握Git的项目Learn Git Branching_git可视化游戏
- 2区间图着色问题:贪心算法设计及实现
- 3Windows系统搭建Appium 2 和 Appium Inspector 环境_appium2
- 4机器人控制算法——两轮差速驱动运动模型_基于imm算法的双轮差速驱动机器人的定位算法
- 5Git面试题整理(基本点)_git 面试
- 6第十三届蓝桥杯 个人经历回顾及经验总结_蓝桥杯教室有摄像头吗
- 7Stable Diffusion 插件开发经验
- 8DataSophon
- 9ImageNet数据集训练深度神经网络
- 10STM32F429开启FPU,使用ST自带DSP库函数_dsp fpu 函数
WebLangChain_ChatGLM:结合 WebLangChain 和 ChatGLM3 的中文 RAG 系统_tavily search
赞
踩
WebLangChain_ChatGLM 介绍

-
本文将详细介绍基于网络检索信息的检索增强生成系统,即 WebLangChain。通过整合 LangChain,成功将大型语言模型与最受欢迎的外部知识库之一——互联网紧密结合。鉴于中文社区中大型语言模型的蓬勃发展,有许多可供利用的开源大语言模型。ChatGLM、Baichuan、Qwen 等大语言模型针对中文交互场景进行了优化,以提升其对中文理解和问答的能力。所以我们还将介绍如何在检索增强生成应用中集成中文社区广泛使用的开源模型 ChatGLM3。这一步骤的实施将进一步拓展系统的适用性和性能,使其更好地服务于中文用户。
-
本文配套的代码仓库: https://github.com/kebijuelun/weblangchain_chatglm
检索增强生成 (RAG) 是什么?
检索增强生成(Retrieval-augmented generation, 简称 RAG)是一种通过从外部来源获取事实来增强生成式人工智能模型准确性和可靠性的技术。
法官根据他们对法律的一般理解听取和裁决案件。然而,在一些特殊情况下,例如医疗事故诉讼或劳资纠纷等案件,需要深入的专业知识。为了确保裁决的权威性和准确性,法官可能会派遣法庭书记员去法律图书馆查找可以引用的先例和具体案例。
就像一个优秀的法官需要深厚的法律知识一样,大型语言模型(LLMs)也能回答各种用户问题。然而,为了提供具有权威性的答案,并支持模型生成的信息,需要进行一些研究。这种过程类似于法庭书记员的工作,被称为检索增强生成。
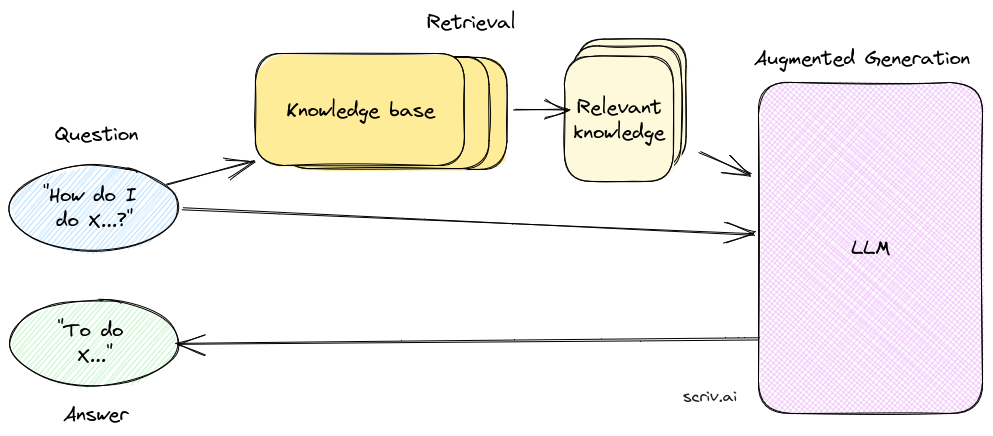
在检索增强生成过程中,模型会利用网络检索、知识库检索等工具,通过检索与用户问题相关的文献和先例,获取权威性引用来源。这样一来,模型生成的答案不仅基于其预训练的知识,还结合了最新的检索信息,提高了回答的准确性和可信度。这种综合性的方法使得大型语言模型更能胜任回答涉及专业领域的问题,类似于法庭书记员在法庭中为法官提供支持和参考的角色。
WebLangChain_ChatGLM 流程概述
一般的检索流程如下:
- 使用包装了 Tavily 的 Search API 的检索器拉取与用户初始查询相关的原始内容。
- 对于随后的对话轮次,我们还将原始查询重新表述为不包含对先前聊天历史的引用的 “独立查询 (standalone query)”。
- 由于原始文档的大小通常超过模型的最大上下文窗口大小,我们执行额外的 上下文压缩步骤 来筛选传递给模型的内容。
- 将检索到的上下文、聊天历史和原始问题传递给 LLM 作为最终生成的上下文。
WebLangChain_ChatGLM 运行方式介绍
环境准备
WebLangChain_ChatGLM 使用的代码基于 git 仓库进行管理,详细代码参考 github 上的 weblangchain_chatglm 代码仓库 weblangchain_chatglm 代码仓库。
首先需要下载代码库到本地:
git clone git@github.com:kebijuelun/weblangchain_chatglm.git
cd weblangchain_chatglm
- 1
- 2
然后参考下述流程分别对 ChatGLM3 和 WebLangChain 进行配置。
ChatGLM3 环境配置与运行方式
基于 conda 进行环境隔离:conda create -n chatglm python==3.10; conda activate chatglm (注意 ChatGLM3 和 WebLangChain 环境隔离很重要,能避免一些库版本不兼容问题)
- 拉取 ChatGLM3 代码模块:
git submodule update --init --recursive - 下载 ChatGLM3 的 huggingface 模型:
git clone https://huggingface.co/THUDM/chatglm3-6b - 添加 ChatGLM3 模型路径的环境变量:
export MODEL_PATH=$(realpath ./chatglm3-6b) - 安装环境依赖:
pip install -r requirements.txt - 部署 ChatGLM3 模型服务:
cd openai_api_demo; python3 openai_api.py
默认情况下,模型以 FP16 精度加载,部署 ChatGLM3 服务需要占用大概 13G 显存,如果读者的显存无法满足需求可以尝试使用 ChatGLM3 开源的低成本部署方式,以 4-bit 量化方式加载模型,可以将显存占用量缩小到 6G 左右。模型量化虽然会带来一定的性能损失,不过经过测试,ChatGLM3-6B 在 4-bit 量化下仍然能够进行自然流畅的生成。 ChatGLM3 代码仓库。
WebLangChain 环境配置与运行方式
基于 conda 进行环境隔离:conda create -n weblangchain python==3.10; conda activate weblangchain
- 安装后端依赖项:
poetry install. - 添加环境变量:
source env.sh
- 注:确保设置环境变量以配置应用程序,默认情况下,WebLangChain 使用 Tavily 从网页获取内容。可以通过 tavily 注册 获取 tavily API 密钥,并更新到
./env.sh中。同时需要在 openai 注册 获取 openai API 密钥更新到./env.sh中。如果想要添加或替换不同的基本检索器(例如,如果想要使用自己的数据源),可以在main.py中更新get_retriever()方法。
- 启动 Python 后端:
poetry run make start. - 运行 yarn 安装前端依赖项:
- 安装 Node Version Manager (NVM):
wget -qO- https://raw.githubusercontent.com/nvm-sh/nvm/v0.39.5/install.sh | zsh(可能需要替换zsh为用户使用的版本,如bash) - 设置 NVM 环境变量:
export NVM_DIR="${XDG_CONFIG_HOME:-$HOME}/.nvm"; [ -s "$NVM_DIR/nvm.sh" ] && \. "$NVM_DIR/nvm.sh" - 安装 Node.js 版本 18:
nvm install 18 - 使用 Node.js 版本 18:
nvm use 18 - 进入 “nextjs” 目录并使用 Yarn 安装依赖:
cd nextjs; yarn.
- 启动前端:
yarn dev. - 在浏览器中打开 localhost:3000.
聊天页面 Demo
-
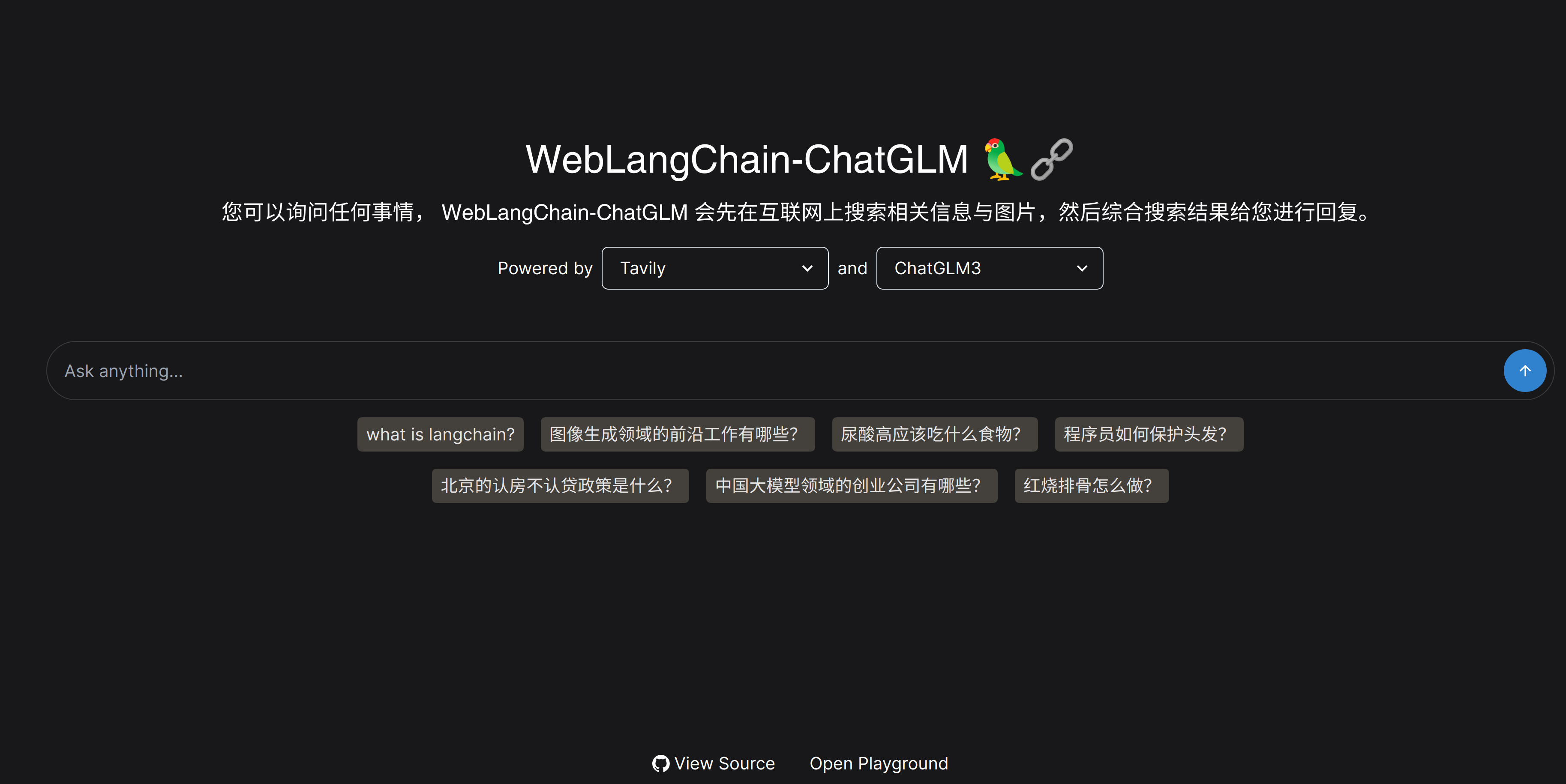
当成功完成以上环境配置和代码运行后,可以在网页端看到以下交互界面,该交互界面支持挑选搜索工具和大语言模型,默认使用 Tavily 作为搜索工具,ChatGLM3 作为大语言模型。在对话框中,读者可以尝试进行一些问题咨询,weblangchain 的设计就是让用户问一些需要检索互联网内容的问题时能够进行更准确的回复,所以对话框下也提供了一些问题样例。
-
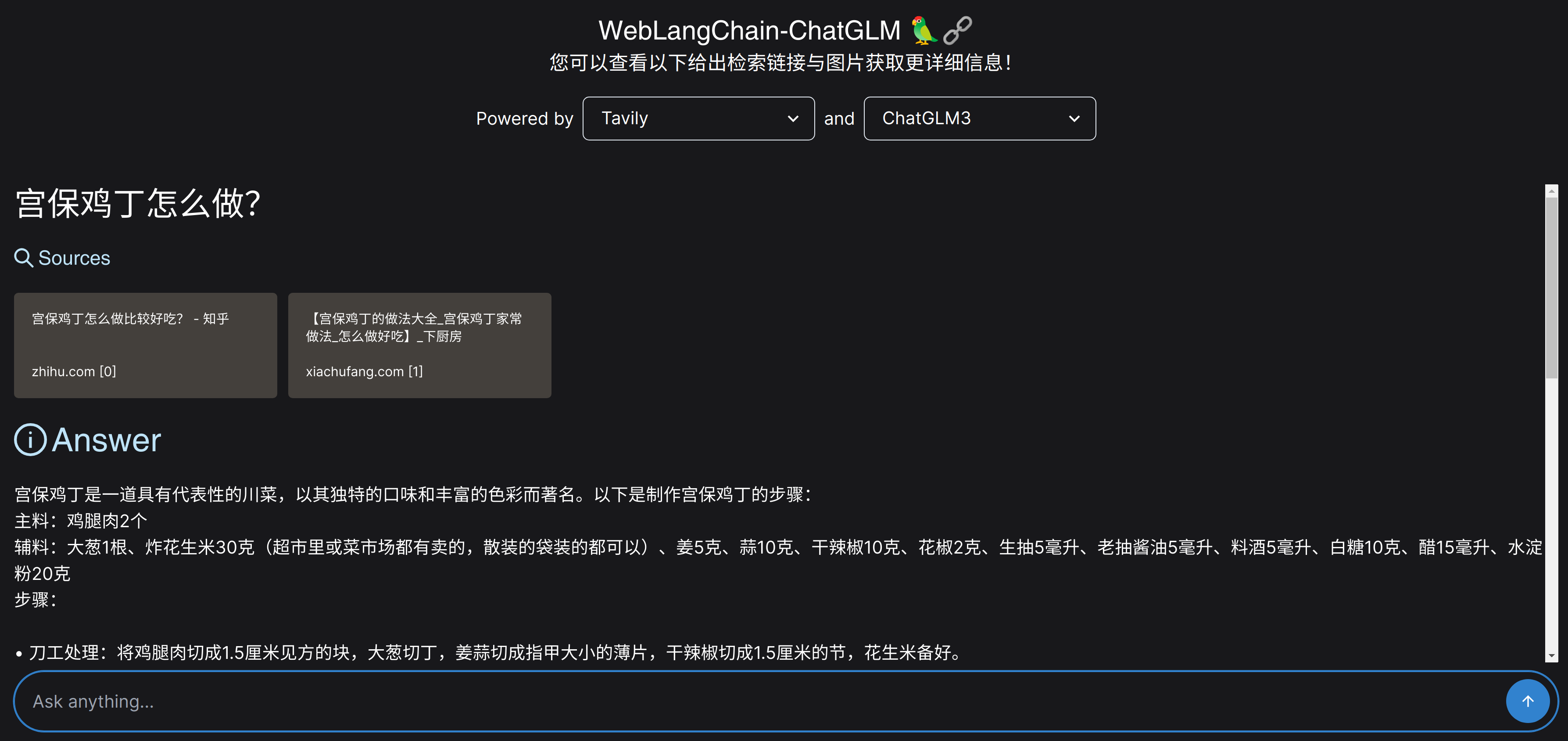
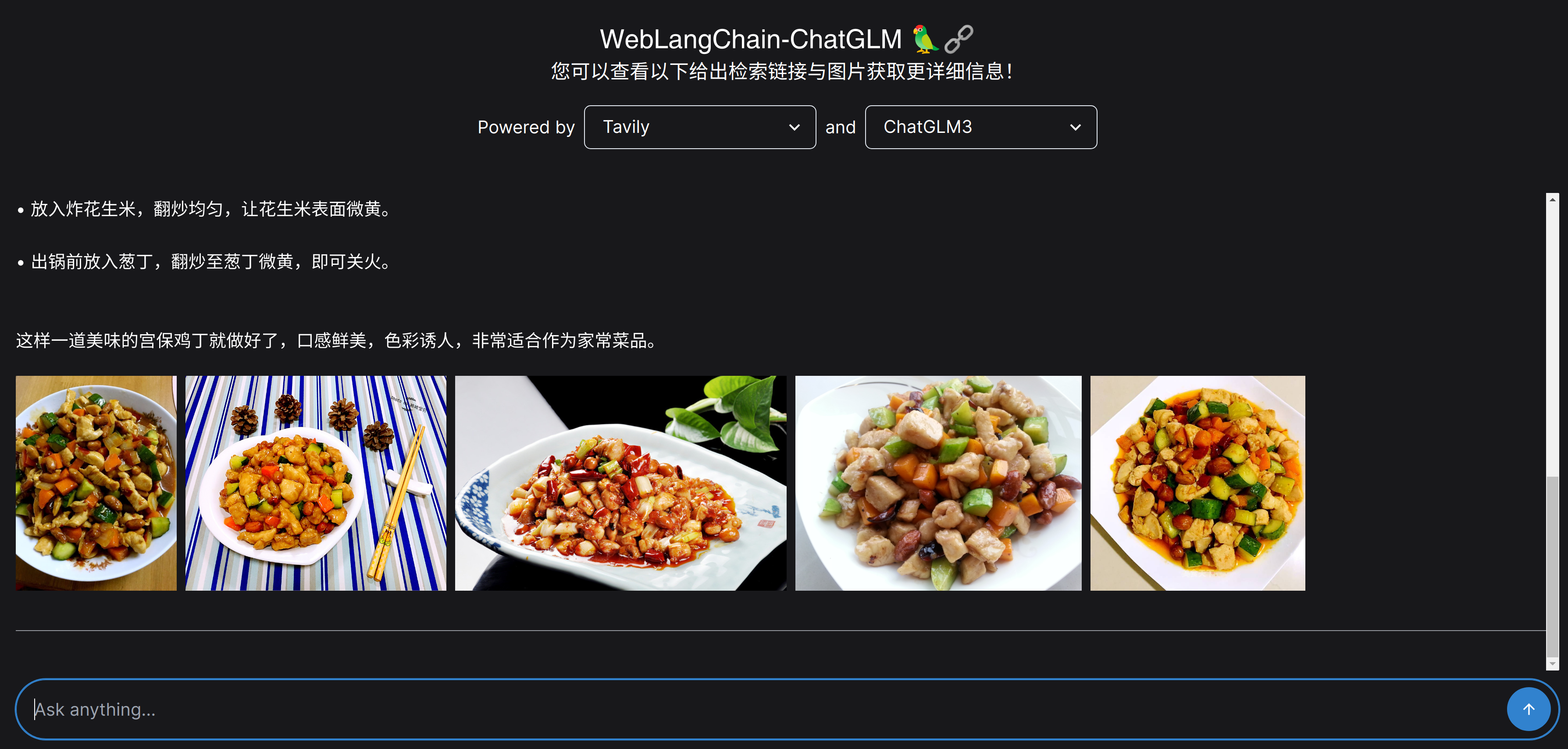
以下是一个问题样例,我们在前端页面输入 “宫保鸡丁怎么做?” 这个问题。weblangchain_chatglm 首先根据用户的输入问题在互联网检索相关内容,可以看到有两个内容被检索出来。然后大语言模型会根据检索内容生成回复,详细介绍宫保鸡丁的具体做法。最后,Tavily 的检索还会返回一些与用户问题相关的图片,可以在回复的最后看到一些与宫保鸡丁相关的图片。
WebLangChain_ChatGLM 底层实现介绍
(注意:本节内容的内容需要一定 LCEL 语法知识,如果读者不了解请先阅读 LCEL(Lang Chain Expression Language) 介绍:LangChain 的开发提效技巧 进行学习)
weblangchain_chatglm 代码库中有一些 JavaScript 代码用于搭建前端页面,这里我们主要对与 LangChain 相关的 Python 后端代码进行介绍,主要的代码逻辑在代码仓库根目录下的 main.py 文件中。
为了对代码的重点逻辑进行讲解,这里我们仅对功能主逻辑相关的代码按照顺序进行讲解。首先需要对大语言模型进行定义:
# OpenAI API的基本地址 (注意这里其实是本地部署的 ChatGLM3 模型服务地址)
openai_api_base = "http://127.0.0.1:8000/v1"
# ChatOpenAI 模型的配置
llm = ChatOpenAI(
model="gpt-3.5-turbo-16k",
streaming=True,
temperature=0.1,
).configurable_alternatives(
# 为字段设置标识符
# 在配置最终可运行时,我们可以使用此标识符配置此字段
ConfigurableField(id="llm"),
default_key="openai",
# ChatOpenAI 模型的备用配置(chatglm)
chatglm=ChatOpenAI(model="chatglm3-6b", openai_api_base=openai_api_base)
)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
这里代码支持了 OpenAI 的对话模型调用,同时也支持调用我们之前本地部署的 ChatGLM3 模型服务。在前端中我们设定了默认模型为 ChatGLM3,用户也可以选择 OpenAI 的模型来进行检索增强生成尝试。
然后我们需要定义检索器,这里我们默认使用 tavily 检索器。
# 获取与 Tavily 相关的检索器链
def get_retriever():
# 创建 OpenAI Embeddings 实例
embeddings = OpenAIEmbeddings()
# 创建 RecursiveCharacterTextSplitter 实例
splitter = RecursiveCharacterTextSplitter(chunk_size=800, chunk_overlap=20)
# 创建 EmbeddingsFilter 实例,用于过滤相似度低于 0.8 的文档
relevance_filter = EmbeddingsFilter(embeddings=embeddings, similarity_threshold=0.8)
# 创建 DocumentCompressorPipeline 实例,包含 splitter 和 relevance_filter
pipeline_compressor = DocumentCompressorPipeline(
transformers=[splitter, relevance_filter]
)
# 创建 TavilySearchAPIRetriever 实例,设置 k 值为 3,并包含原始内容和图像信息
base_tavily_retriever = TavilySearchAPIRetriever(
k=3,
include_raw_content=True,
include_images=True,
)
# 创建 ContextualCompressionRetriever 实例,包含 pipeline_compressor 和 base_tavily_retriever
tavily_retriever = ContextualCompressionRetriever(
base_compressor=pipeline_compressor, base_retriever=base_tavily_retriever
)
# 创建 GoogleCustomSearchRetriever 实例
base_google_retriever = GoogleCustomSearchRetriever()
# 创建 ContextualCompressionRetriever 实例,包含 pipeline_compressor 和 base_google_retriever
google_retriever = ContextualCompressionRetriever(
base_compressor=pipeline_compressor, base_retriever=base_google_retriever
)
# 创建 YouRetriever 实例,使用 YDC API 密钥
base_you_retriever = YouRetriever(
ydc_api_key=os.environ.get("YDC_API_KEY", "not_provided")
)
# 创建 ContextualCompressionRetriever 实例,包含 pipeline_compressor 和 base_you_retriever
you_retriever = ContextualCompressionRetriever(
base_compressor=pipeline_compressor, base_retriever=base_you_retriever
)
# 创建 KayAiRetriever 实例,设置数据集 ID、数据类型和上下文数量
base_kay_retriever = KayAiRetriever.create(
dataset_id="company",
data_types=["10-K", "10-Q"],
num_contexts=6,
)
# 创建 ContextualCompressionRetriever 实例,包含 pipeline_compressor 和 base_kay_retriever
kay_retriever = ContextualCompressionRetriever(
base_compressor=pipeline_compressor, base_retriever=base_kay_retriever
)
# 创建 KayAiRetriever 实例,设置数据集 ID、数据类型和上下文数量为 PressRelease
base_kay_press_release_retriever = KayAiRetriever.create(
dataset_id="company",
data_types=["PressRelease"],
num_contexts=6,
)
# 创建 ContextualCompressionRetriever 实例,包含 pipeline_compressor 和 base_kay_press_release_retriever
kay_press_release_retriever = ContextualCompressionRetriever(
base_compressor=pipeline_compressor,
base_retriever=base_kay_press_release_retriever,
)
# 返回 retriever 链,可配置不同的 retriever 作为默认值,并提供 Google、You、Kay 和 Kay Press Release 的备选项
return tavily_retriever.configurable_alternatives(
ConfigurableField(id="retriever"),
default_key="tavily",
google=google_retriever,
you=you_retriever,
kay=kay_retriever,
kay_press_release=kay_press_release_retriever,
).with_config(run_name="FinalSourceRetriever")
# 获取检索器
retriever = get_retriever()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
这里我们主要关注其中的 Tavily 检索器。Tavily 是一个搜索 API,转为人工智能体设计,专门用于 RAG 目的。通过 Tavily Search API,人工智能开发人员可以轻松将其应用程序与实时在线信息集成在一起。Tavily 的主要目标是从可信赖的来源提供真实可靠的信息,提高 AI 生成内容的准确性和可靠性。
Tavily 有以下几个特点对于 RAG 应用非常友好:
- 速度快
- 返回每个页面的良好摘要,因此不必加载每个页面
- 返回与检索问题相关的图像
让我们尝试一个简单的检索来了解 Tavily API 调用的方式和返回结果:
from langchain.retrievers.tavily_search_api import TavilySearchAPIRetriever
retriever = TavilySearchAPIRetriever(k=1)
result = retriever.invoke("2022年举办的足球世界杯冠军是?")
print(result[0])
# -> page_content='分享: 央视网消息:北京时间12月19日,2022年卡塔尔世界杯决赛,阿根廷对阵法国。 上半场迪马利亚制造点球,梅西点球破门,随后迪马里亚进球扩大领先优势,下半场姆巴佩梅开二度,加时阶段双方各入一球拖入点球大战。 最终,阿根廷战胜法国夺得第三个世界杯冠军。' metadata={'title': '世界杯-阿根廷点球大战战胜法国 时隔36年斩获第三冠_体育_央视网(cctv.com)', 'source': 'http://worldcup.cctv.com/2022/12/19/ARTIxD38qwfaQp1YAK9Mx608221219.shtml', 'score': 0.95291, 'images': None}
- 1
- 2
- 3
- 4
- 5
- 6
这里可以看到 Tavily 返回的内容有与检索问题相关的网页内容和网址等信息。
在获取大语言模型和检索器后,我们需要将这两个组件连接为链:
def create_retriever_chain(
llm: BaseLanguageModel, retriever: BaseRetriever
) -> Runnable:
# 从模板创建重新表达问题的提示
CONDENSE_QUESTION_PROMPT = PromptTemplate.from_template(REPHRASE_TEMPLATE)
# 创建重新表达问题的执行链,包含 CONDENSE_QUESTION_PROMPT、llm 和 StrOutputParser
condense_question_chain = (
CONDENSE_QUESTION_PROMPT | llm | StrOutputParser()
).with_config(
run_name="CondenseQuestion",
)
# 创建对话链,包含重新表达问题的执行链和检索器
conversation_chain = condense_question_chain | retriever
# 创建分支执行链,根据是否有聊天历史选择不同的路径
return RunnableBranch(
(
RunnableLambda(lambda x: bool(x.get("chat_history"))).with_config(
run_name="HasChatHistoryCheck"
),
conversation_chain.with_config(run_name="RetrievalChainWithHistory"),
),
(
RunnableLambda(itemgetter("question")).with_config(
run_name="Itemgetter:question"
)
| retriever
).with_config(run_name="RetrievalChainWithNoHistory"),
).with_config(run_name="RouteDependingOnChatHistory")
# 创建 LangChain 的执行链
def create_chain(
llm: BaseLanguageModel,
retriever: BaseRetriever,
) -> Runnable:
# 创建检索器链
retriever_chain = create_retriever_chain(llm, retriever) | RunnableLambda(
format_docs
).with_config(run_name="FormatDocumentChunks")
# 创建 _context 执行映射,包含 "context"、"question" 和 "chat_history" 字段
_context = RunnableMap(
{
"context": retriever_chain.with_config(run_name="RetrievalChain"),
"question": RunnableLambda(itemgetter("question")).with_config(
run_name="Itemgetter:question"
),
"chat_history": RunnableLambda(itemgetter("chat_history")).with_config(
run_name="Itemgetter:chat_history"
),
}
)
# 创建聊天提示
prompt = ChatPromptTemplate.from_messages(
[
("system", RESPONSE_TEMPLATE),
MessagesPlaceholder(variable_name="chat_history"),
("human", "{question}"),
]
)
# 创建响应合成器,包含 prompt、llm 和 StrOutputParser
response_synthesizer = (prompt | llm | StrOutputParser()).with_config(
run_name="GenerateResponse",
)
# 创建完整的执行链,包含 "question"、"chat_history" 和 _context 字段
return (
{
"question": RunnableLambda(itemgetter("question")).with_config(
run_name="Itemgetter:question"
),
"chat_history": RunnableLambda(serialize_history).with_config(
run_name="SerializeHistory"
),
}
| _context
| response_synthesizer
)
# 获取 LangChain 的执行链
chain = create_chain(llm, retriever)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
可以看到这里的链的调用方面使用了一定我们之前介绍的 LCEL 语法。整个链条的调用也是很清晰:
- 首选创建
retriever_chain,对于第一个问题,即没有对话历史的情况下会直接将问题直接传递给搜索引擎。而对于后续问题,根据对话历史生成一个单一的搜索查询传递给搜索引擎,使用 Tavily 获取搜索结果。 - 创建
_context执行映射,用于获取搜索结果作为上下文内容 - 将用户的问题 (
question)、对话历史 (chat_history)、搜索内容 (_context) 整合到prompt中 - 将
prompt送入大语言模型获取模型回复,最后提取文本输出作为最后的返回结果
这里的提示词的构造如下所示:
RESPONSE_TEMPLATE = """\
您是一位专业的研究员和作家,负责回答任何问题。
基于提供的搜索结果(URL 和内容),为给定的问题生成一个全面而且信息丰富、但简洁的答案,长度不超过 250 字。您必须只使用来自提供的搜索结果的信息。使用公正和新闻性的语气。将搜索结果合并成一个连贯的答案。不要重复文本。一定要使用 [${{number}}] 标记引用搜索结果。只引用最相关的结果,以准确回答问题。将这些引用放在提到它们的句子或段落的末尾 - 不要全部放在末尾。如果不同的结果涉及同名实体的不同部分,请为每个实体编写单独的答案。如果要在同一句子中引用多个结果,请将其格式化为 [${{number1}}] [${{number2}}]。然而,您绝对不应该对相同的数字进行这样的操作 - 如果要在一句话中多次引用 number1,只需使用 [${{number1}}],而不是 [${{number1}}] [${{number1}}]。
为了使您的答案更易读,您应该在答案中使用项目符号。在适用的地方放置引用,而不是全部放在末尾。
如果上下文中没有与当前问题相关的信息,只需说“嗯,我不确定。”不要试图编造答案。
位于以下context HTML 块之间的任何内容都是从知识库中检索到的,而不是与用户的对话的一部分。
<context>
{context}
<context/>
请记住:一定要在回答的时候带上检索的内容来源标号。如果上下文中没有与问题相关的信息,只需说“嗯,我不确定。”不要试图编造答案。位于上述 'context' HTML 块之前的任何内容都是从知识库中检索到的,而不是与用户的对话的一部分。
"""
REPHRASE_TEMPLATE = """\
考虑到以下对话和一个后续问题,请将后续问题重新表达为独立的问题。
聊天记录:
{chat_history}
后续输入:{question}
独立问题:"""
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
可以看出,提示词的主要目的是限制大型语言模型的响应,使其参考检索结果。同时,期望模型在响应中添加引用的具体编号。我们注意到,这一要求需要语言模型具有较强的指令跟随能力。使用 ChatGPT3.5 相对于 ChatGLM3 能够更高概率地获得期望的响应。然而,目前 ChatGLM3 以远低于 ChatGPT3.5 的参数量实现了相应的效果,这也表明了 ChatGLM3 具有一定的实力。
整个 RAG 流程通过 LangChain 实现起来非常直观和简洁。在后续的小结中,我们将进一步讨论 RAG 的系统设计。
RAG 系统设计逻辑探讨
这里我们将参考 weblangchain 的 RAG 系统设计思路简单讨论 RAG 系统中的注意事项 weblangchain RAG system。
什么时候要进行搜索?
在RAG应用程序的开发中,面临的一个关键决策是是否始终执行信息查找操作。为何要考虑避免无谓的信息查找呢?若应用程序更倾向于成为通用聊天机器人,过度频繁的信息查找可能并非理想选择。在这种情况下,用户仅仅与应用程序打招呼,如说“你好”,进行不必要的检索可能只是浪费时间和资源。制定是否执行信息查找的逻辑有多种方法。首先,可以使用一个简单的分类层,确定是否值得进行信息查找。另一种方法是允许大型语言模型生成搜索查询,并在不需要查找信息时生成一个空的搜索查询。然而,总是执行信息查找也存在一些潜在问题。首先,这种逻辑可能耗费过多时间和资源,超过了其实际价值(例如,可能需要额外的大型语言模型调用)。其次,如果过于假设用户主要将应用程序用作搜索工具而不是通用聊天机器人,可能增加犯错误的风险,即在应该查找信息时却未执行此操作。
对于应用程序而言,选择了始终执行信息查找。这一决策背后的原因在于 weblangchain 试图构建一个服务于上网咨询问题人员的应用。这使对用户行为有了强烈的先验认知,即用户通常寻求信息进行研究。在这种情况下,添加逻辑以确定是否执行信息查找可能不值得付出相应的成本(时间、金钱、错误的风险)。
然而,这一决策确实存在一些潜在问题——若始终执行信息查找,当有用户试图进行正常对话时,可能会显得有些不寻常。
直接使用用户的原始问题作为检索词还是其派生词作为检索词?
RAG 的最直接方法是使用用户的问题并直接搜索该短语,这种方式既迅速又简便。然而,这一方法可能存在一些缺陷,具体而言,用户的输入可能未充分反映他们实际欲查找的内容。
一个典型的例子是冗长的问题。冗长的问题通常包含大量词语,这些词语会分散注意力,使真正的问题难以辨认。考虑以下搜索查询作为例子:
“嗨!我想知道一个问题的答案。可以吗?假设可以。我的名字是哈里森,是 LangChain 的首席执行官。我喜欢大型语言模型和 OpenAI。梅西·彼得斯是谁?”
我们实际上欲回答的问题是 “梅西·彼得斯是谁”,但其中有许多分散注意力的文本。为解决这种情况,一种方法是不使用原始问题,而是从用户的问题生成一个专门的搜索查询。这样做的好处是生成了一个更为明确的搜索查询,但缺点是需要额外的大型语言模型调用。
对于我们的应用程序,我们假设大多数初始用户问题都相当直接,因此我们将选择直接查找原始查询。然而,这种方法可能对于类似上述问题的情况无法有效处理。
如何处理后续问题(即多轮问答)?
在基于聊天的RAG应用程序中,有效处理后续问题是至关重要的任务。这一重要性源自后续问题引入了以下情况:
- 涉及先前对话的间接后续问题如何处理?
- 完全与先前对话无关的后续问题应该如何应对?
一般而言,有两种常见的处理后续问题的方式:
- 直接搜索后续问题: 对于与先前对话毫不相干的问题,这种方式效果较好,但当后续问题涉及先前对话时可能存在问题。
- 利用大型语言模型生成新的搜索查询(或查询): 这种方式通常效果良好,但会增加一些额外的延迟。
对于后续问题而言,它们更有可能不是独立的良好搜索查询。因此,为了解决这一问题,额外的成本和延迟是值得的,以生成一个专门的搜索查询。
比如针对之前的样例在第一轮中问了 “梅西·彼得斯是谁?” 问题,第二轮中如果询问:“她的一些歌曲是什么?” ,针对前两轮问答生成一个搜索查询,以获得与之相关的有效搜索结果。这样就能够更好地处理冗长的问题。
查找多个搜索词还是只查找一个?
搜索词的数量也训练一定考量。是否总是一个搜索词?或者它可能是多个搜索词?如果是多个搜索词,是否有时可能是 0 个搜索词?允许可变数量的搜索词的好处是更加灵活。缺点是会引入更多的复杂性。这种复杂性是否值得呢?
允许 0 个搜索词的复杂性可能不值得。类似于之前是否总是查找信息的决策,我们假设用户使用我们的 weblangchain 应用是因为他们有意查找信息。因此,总是生成一个查询是合理的。生成多个查询会增加更长的搜索时间。为了保持系统的简洁性,weblangchain 应用程序中将只生成一个搜索查询。
然而,这也有其不足之处。考虑下面的问题:
“谁赢得了 2023 年第一场 NFL 比赛?谁赢得了 2023 年女足世界杯?”
这是在询问两个非常不同的事情,这种情况使用一个检索词往往无法获取最佳的结果。检索结果一般只与其中一个问题有关,然后另外一个问题往往大语言模型(未完全解决幻觉问题的前提下)在不知道事实的情况下会进行瞎编。
需要进行多次搜索吗?
大多数 RAG 应用程序只执行单个查找步骤。然而,让它执行多个查找步骤可能会有一些好处。
请注意,这与生成多个搜索查询是不同的。当生成多个搜索查询时,可以并行搜索这些查询。允许多次查找的动机是最终答案可能取决于先前查找步骤的结果,而这些查找必须按顺序进行。在 RAG 应用程序中,这样做相对较少见,因为它会增加更多的成本和延迟。
能够多次查找信息的应用程序开始变得更像智能体。这有其优缺点。优点是它使这些应用程序能够回答更复杂问题的更长尾部分。然而,这通常是以延迟为代价(这些应用程序更慢)和可靠性(它们有时可能偏离轨道)为代价的。
不能多次查找信息的应用程序则相反——它们通常更快,更可靠,但能力较差,难以处理更复杂问题的长尾。
举个例子,考虑一个问题:
“谁赢得了 2023 年女足世界杯?该国的 GDP 是多少?”
考虑到单次检索的应用程序不能多次查找信息,我们不会指望它能够很好地处理这种情况。而多次搜索的应用程序由于可以执行多个动作,它有可能正确回答这个问题。不过值得注意的是,回答所花费的时间可能会明显长于单次搜索的应用程序。weblangchain 为了更快的聊天体验使用了单次检索的设计思路。
是应该只给出答案?还是应该提供额外的信息?
一种广泛采用的做法是不仅提供答案,还提供答案所依据的来源引用。这对于用户具有重要意义,原因主要是它使得验证大语言模型在其响应中提出的任何主张变得容易(因为用户可以导航到引用的源并自行检查)。
weblangchain 的提示词的使用是在特定的约定下引用其来源。该特定约定涉及要求大语言模型生成以下注释中的来源:[N]。然后在客户端解析它并将其呈现为超链接。效果如下:

需要注意不是所有的大语言模型都能确保这样的来源引用效果,实际测试使用 ChagGPT3.5 还是有比较大概率能按照提示词的约束对每个重要的语句都给定参考链接的,如果不能正确给出则需要用户自行查看 weblangchain 给定的引用链接来确认信息来源的可靠性。
小结
在本文中,我们全面介绍了一个检索增强生成程序样例,具体涵盖了 weblangchain_chatglm 的环境安装、运行方式以及底层原理。我们深入了解了这一系统的设计要点,并强调了在检索增强生成的系统中需要特别注意的方面。这些设计决策往往是一种权衡,需要开发者在实际应用场景中做出明智的选择。例如,总是查找信息可能增加系统的复杂性,而允许多次查找信息可能引入更多的延迟。这些权衡需要根据具体的应用场景和用户需求做出,并在系统设计中找到最佳平衡点。

