
- 1【数字IC设计/FPGA】FIFO与流控机制_fifo 在实际应用过程中 是空的full 还是almost full
- 2Gitea:轻量级Git服务的开源之选
- 3C++实现通用的文件(万能)加密方案——包含源码_c++做一个加密程序
- 4【智能金融】机器学习在风控领域的应用_风控 机器学习
- 5黑马程序员Java面试专题(2)|并发编程篇(1)线程基础_程序猿面试
- 6YoLov5从环境搭建到训练自己的数据,以良性皮肤痣和恶性皮肤痣的分类与血红细胞类型目标检测识别为例(非常详细,包括环境安装配置、源码下载、配置运行环境、代码改写、数据集制作、训练、预测和优化)等_yolov5皮肤病分割
- 7pip安装requests模块_pip install requests
- 8车载Android应用开发与分析 - 初试 SystemUI Plugin_systemuiplugin
- 9ZYNQ基本用法------DDR(1)_zynq ddr
- 10webpack+Vue多个axios接口代理问题_web 页面地址有二级路径 接口如何代理
分享利用 IDM 批量爬取网站静态资源!简单操作采集网站PDF 资源。_idm抓不到pdf文件怎么办
赞
踩
昨天一个小伙伴让写一个爬虫爬某网站全站 PDF 文档 ,我一听开始 有点头大,全站那数量不得相当惊人了,网站简单看了下,发现这类静态网站好像无须爬虫,借助强大的 IDM 就可以解决问题了。因为 IDM 有一个重要的功能就是站能抓取,和以前早期的一些整站搬运功能类似,以前做网站的人比较懒的时候,就直接 copy 别人整个网站,改改名字就 OK 了。
考虑到老外的网站也就没有这么多版权考虑,目录网址:
https://www.math-salamanders.com/
目的,爬取此网站内所有的 PDF 文件(包括外链中涉及到 PDF 的)
如果要写程序的,你就遍历所有 a 标签再遍历所有页面中的 a 标签,再如此循环,其实自己也不知道要循环多少次,有没有重复的。
IDM 站点抓取
捕获过程如下:
第一步:找到想要捕获图片的网站,将网站地址复制下来。
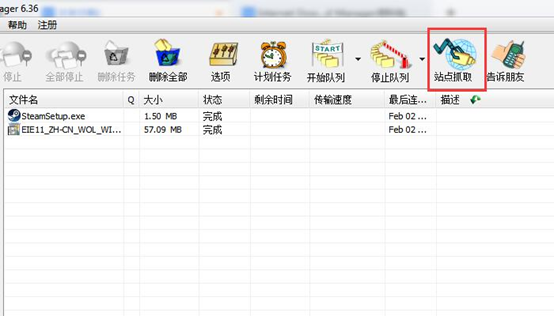
图 1:IDM 站点抓取功能
第二步:在 IDM 下载器中,点击界面上方的 “站点抓取” 选项。这里要选择整个站点,方便数据完整性,不然有可能文档 不全。

图 2:设置开始页面
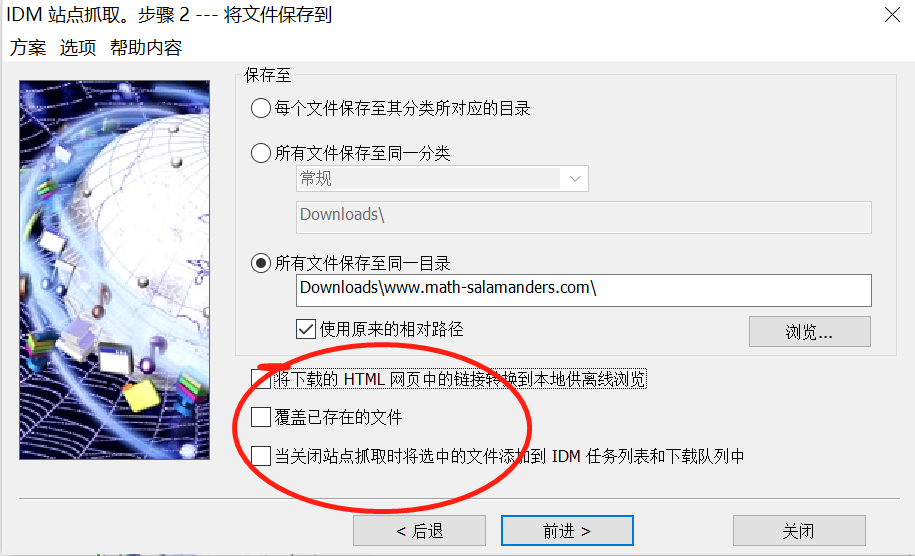
图 3:文件保存地址
第三步:将每个文件保存至其分类所对应的目录。这里取消下载 HTML 文件本地浏览
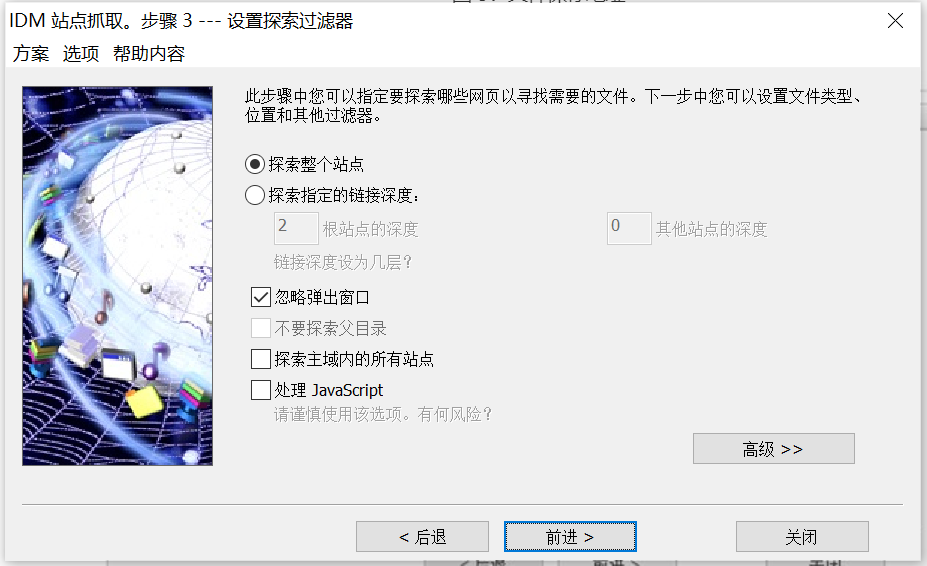
图 4:设置探索过滤器
第四步:过滤整个站点的图片,包括根站点与子链接的所有站点图片,并且忽略弹出的窗口进行搜索。
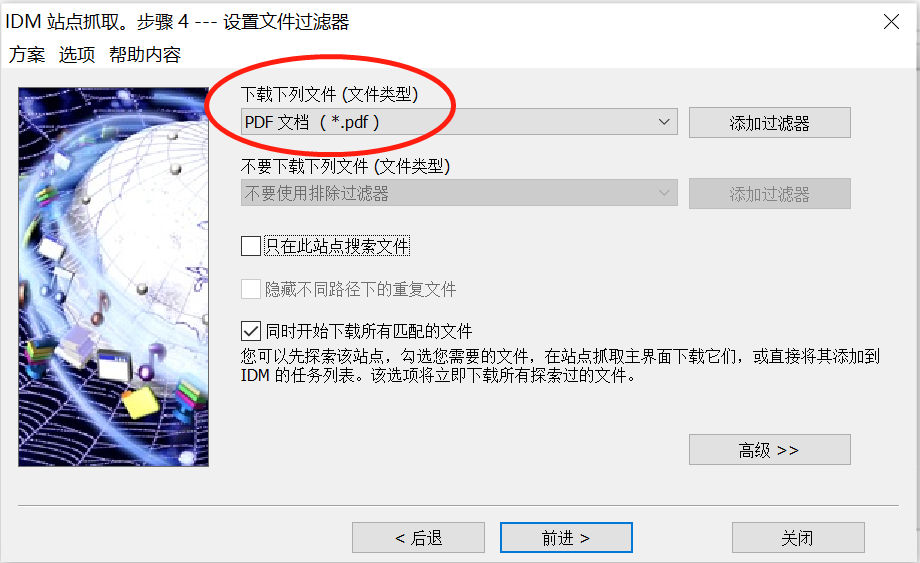
图 5:设置文件过滤器
第五步:选择过滤的文档类型(.pdf),默认下面的文件过滤器,点击 “前进” 进行下一步。
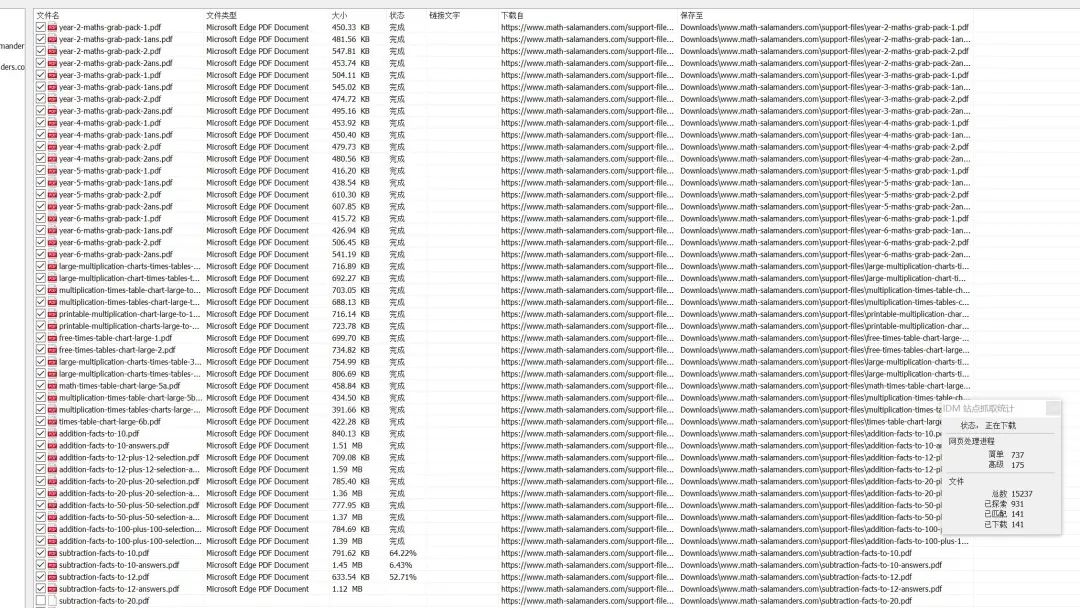
图 6:站点抓取过程
第六步:等待对站点图片进行检索,检索到的文档会在右边信息框内显示,并且 IDM 会自动对抓取的文件进行统计,实时查看抓取状态以及抓取文件数量。
图 7:下载选中图片并保存到队列中
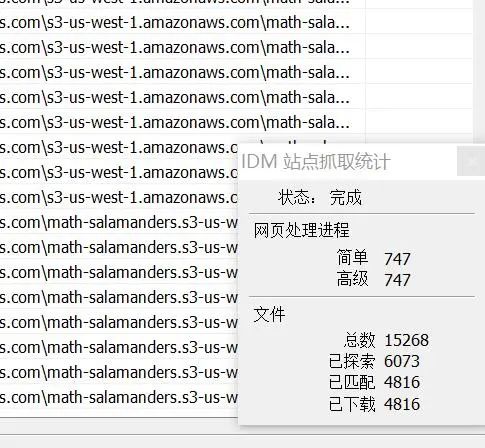
最后完成的数量高达 4800 多个文档 ,如果你手动下载,估计至少 2 天吧。
站点抓取是 IDM 中非常实用的一项特色功能,能够方便用户各项操作的同时提高用户的工作效率。除此之外,站点抓取功能也可以配合 “计划任务” 来实现定时下载,满足用户的多样化需求。
当然如果你运气足够好的话,某些网站的付费资源也是一并可以爬取的,这种通常情况 下好像出现在小程序中比较多,也许是开发者只考虑到了小程序前端的限制,没有考虑到一旦获取文件路径,那么就有可能出现不设防。

