
- 1Storm详细配置及应用_storm.zookeeper.servers 配置端口
- 2数据结构(顺序表)_数据结构顺序表的问题导入
- 3基于Java开发的全文检索、知识图谱、工作流审批机制的知识库系统_java知识图谱项目
- 4STM32核心版PCB设计及总结
- 5【海思Hi3516CV610】是面向新一代视频编解码标准、网络安全和隐私保护、人工智能行业应用方面的IPC SoC
- 6Anaconda3、TensorFlow和keras简单安装方法(不好用)_tensorflow keras安装
- 7时序分解 | Matlab实现TVF-EMD时变滤波器的经验模态分解信号分量可视化
- 8小白搭建RTX3090环境对应的深度学习环境~tensorflow环境搭建/pytorch环境搭建_tensorflow gpu 没有调用
- 9Docker套件之Mysql服务配置_docker mysql 配置文件
- 10PHP+mysql+微信小程序疫情社区管理系统-计算机毕业设计源码03157_php小程序远程控制源码
Hadoop环境搭建(全网最详细,保姆级教程)
赞
踩
全网首发最详细、手把手保姆级教你使用VirtualBox搭建基于Linux的Hadoop环境
前言
本博主在半年前学习hadoop时搭建的是稳定的版本2.6.0,后续会讲解2.0和3.0的具体区别。
如果你原来的虚拟机安装了JDK请阅读第三步跟着敲命令行即可
下一篇文章 Hadoop全分布式集群搭建
第一步:下载安装虚拟机软件VirtualBox
VirtualBox的下载和安装
官方下载网址:https://download.virtualbox.org/virtualbox/6.1.4/VirtualBox-6.1.4-136177-Win.exe
然后一步一步点击示安装
设置VirtualBox存储文件
点击“管理”——>“全局设定”
选择“常规”,更改存储virtualbox虚拟机文件的文件夹
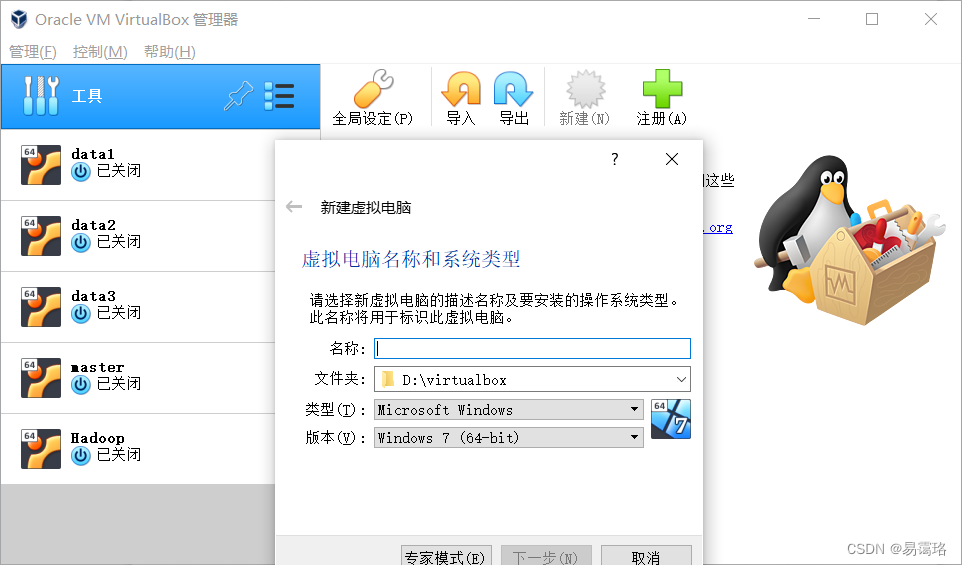
创建虚拟机
点击“新建”按钮,输入虚拟机的名称,选择类型,选择版本,将类型更改为Linux;版本改为ubuntu(64-bit)
接着点击 “下一步”
分配内存大小,点击“下一步”

选择“现在创建虚拟硬盘”再点击“创建”
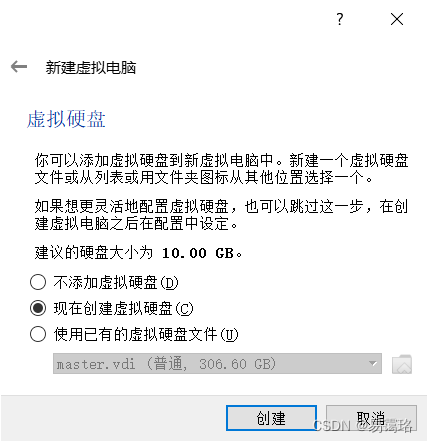
选择默认的“VDI”类型,点击“下一步”
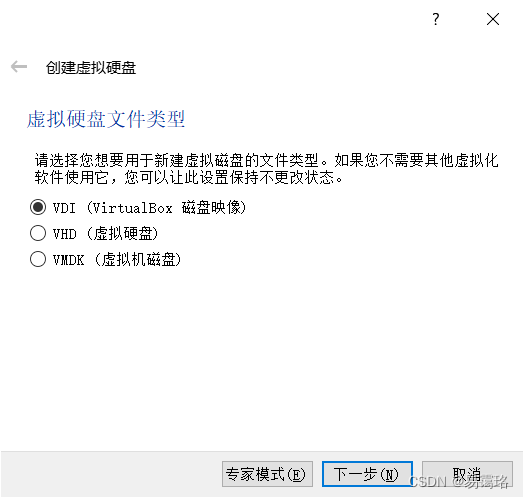
选择“动态分配”
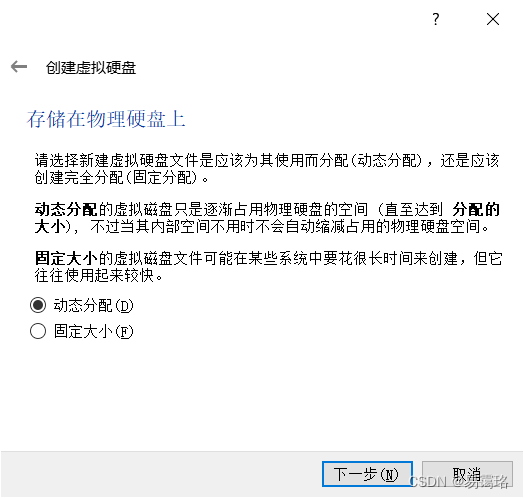
设定为50G,(50G是上限值并非实际值,当虚拟机文件达到50G大小就不再增加)点击“创建”
至此虚拟机创建完毕
第二步:安装ubuntu操作系统
下载并安装光盘镜像
选择华为云镜像下载:https://repo.huaweicloud.com/ubuntu-releases/22.04/ubuntu-22.04-desktop-amd64.iso
设置ubuntu光盘映像文件
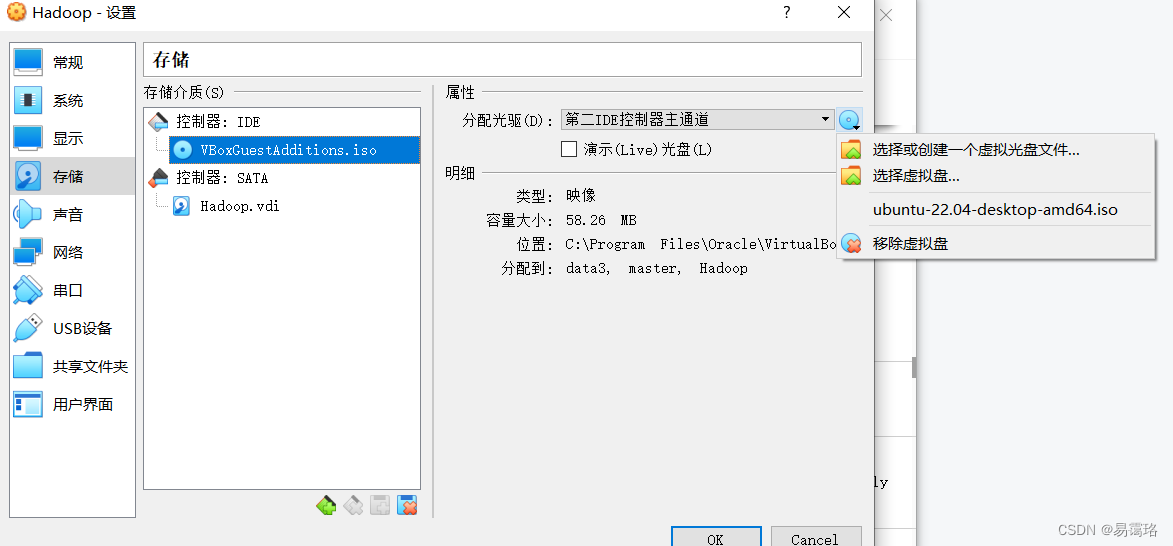
单击选择你创建的虚拟机 点击“设置”——>点击“存储”——>点击“控制器:IDE”下的光盘图标,再点击选择你之前下载的光盘镜像,设置好之后点击完成即可。
安装ubuntu
由于本人在此次安装ubutun时忘记截图,可以参考这篇博客(在欢迎界面记得更改语言为简体中文)刚开始的屏幕分辨率太小,按钮无法显示,使用“ctrl+alt+T”快捷键打开终端执行xrandr -s 1280x800命令即可
(55条消息) 使用VirtualBox一步一步安装Ubuntu 22.04_一种记忆的博客-CSDN博客_virtualbox 安装ubuntu
安装完后进行重启。如果重启后再次遇到分辨率太低,右键选择显示设置——>显示器——>分辨率
安装增强功能
点击安装增强功能后按照提示一步步走即可
安装完成后进行共享粘贴板设置
如果遇到安装增强功能失败
打开终端分别执行下列命令(VBox_GAs_6.1.4,看自己安装的VirtualBox是什么版本,6.1.4就是版本号)
sudo su
cd /media/“你的主机名”/VBox_GAs_6.1.4/
sudo sh VBoxLinuxAdditions.run
- 1
- 2
- 3
如果在执行第三行指令后屏幕出现下面这种提示:
Please install the gcc make perl packages from your distribution
执行下面的命令即可
sudo apt-get install gcc make perl
- 1
安装完毕后再次执行
sudo sh BoxLinuxAdditions.run
- 1
sudo apt-get install gcc make perl
- 1
安装完毕后再次执行
sudo sh BoxLinuxAdditions.run
- 1
再重启虚拟机
第三步单机伪分布式环境搭建
安装JDK
查看是否有默认的jdk
java -version
- 1
若没有则需要下载
连接到APTServer,更新软件包信息
sudo apt-get update
- 1
通过apt-get安装JDK(这种方法由于没有镜像,下载速度很慢但流程简单,另一种方法通过解压下载的压缩包配置jdk)
sudo apt-get install default-jdk
- 1
按照提示输入Y等待下载完成
查看java版本
java -version
- 1
查看java的安装路径
update-alternatives --display java
- 1
注意:此路径在后面会用到
设置SSH无密码登录
安装ssh
sudo apt-get install ssh
- 1
安装rsync
sudo apt-get install rsync
- 1
生成ssh密钥进行身份验证
ssh-keygen -t dsa -P ' ' -f ~/.ssh/id_dsa
- 1
查看生成的SSH密钥
~/.ssh
- 1
将密钥放入到许可证文件中
cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
- 1
下载安装Hadoop()
下载hadoop-2.6.0.tar.gz
Wget https://downloads.apache.org/hadoop/common/hadoop-2.6.0/hadoop-2.6.0.tar.gz
- 1
解压hadoop-2.6.0.tar.gz
sudo tar -zxvf hadop-2.6.0.tar.gz
- 1
移动hadoop目录到/usr/local/hadoop
sudo mv hadoop-2.6.0 /usr/local/hadoop
- 1
查看目录/usr/local/hadoop下的文件
/usr/local/hadoop
- 1
设置hadoop环境变量
sudo gedit ~/.bashrc
- 1
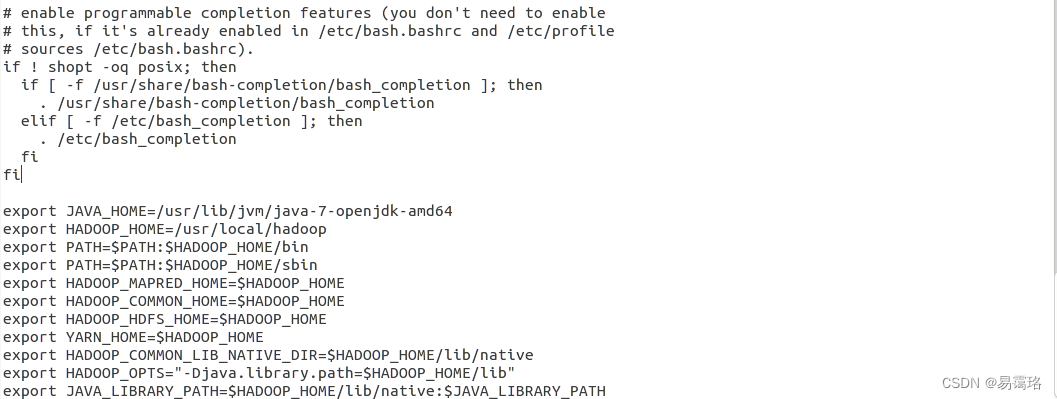
在该文件的下方加以下配置
export JAVA_HOME=/usr/lib/jvm/java-7-openjdk-amd64
//第一行是你的jdk安装路径,安装你自己下载的版本以及安装路径更改
export HADOOP_HOME=/usr/local/hadoop
//第二行是hadoop的安装路径
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib"
export JAVA_LIBRARY_PATH=$HADOOP_HOME/lib/native:$JAVA_LIBRARY_PATH
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
样图
让~/.bashrc设置生效
source ~/.bashrc
- 1
修改Hadoop配置设置文件
编辑hadoop-env.sh
sudo gedit /usr/local/hadoop/etc/hadoop/hadoop-env.sh
- 1
原本文件的设置是
export JAVA_HOME=${JAVA_HOME}
- 1
将${JAVA_HOME}更改为"你的jdk安装路径"
export JAVA_HOME=/usr/lib/jvm/java-7-openjdk-amd64
- 1
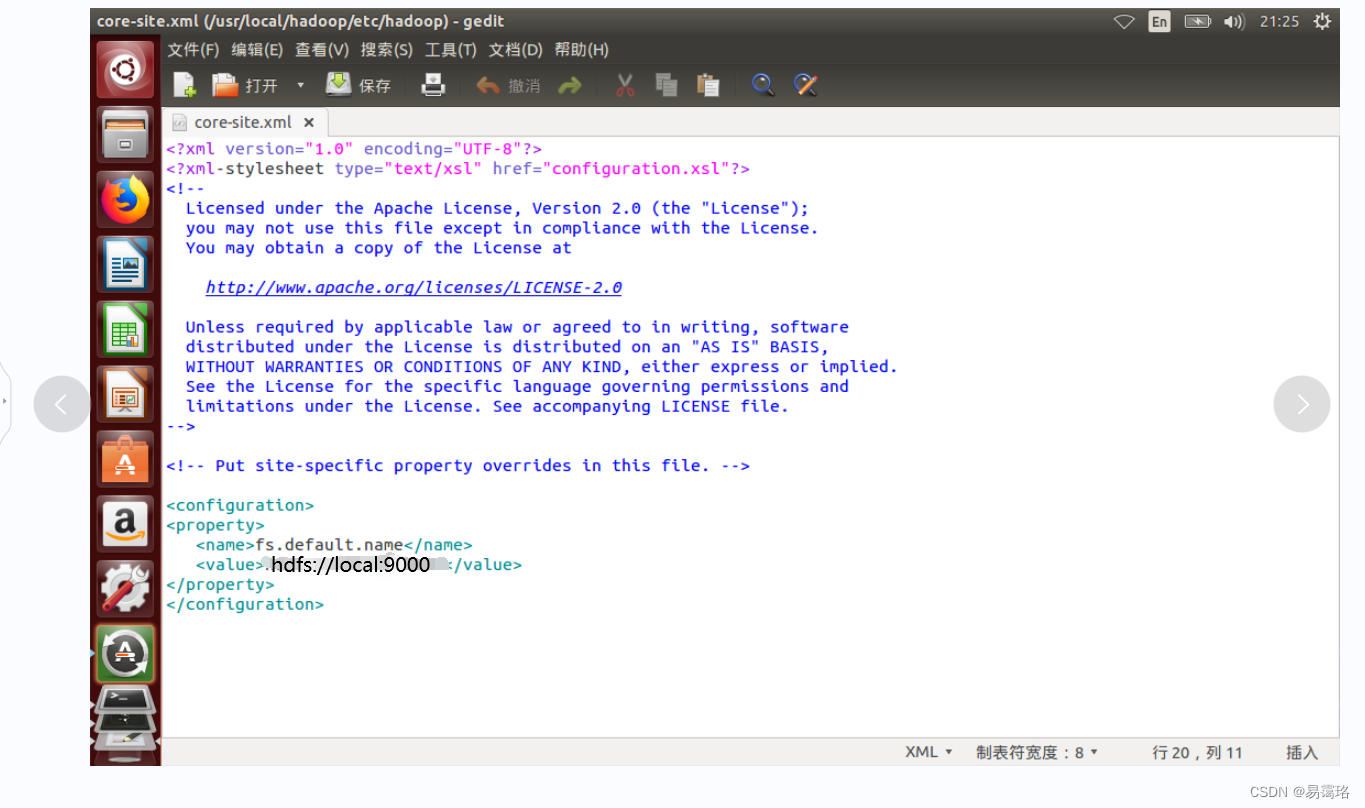
修改core-site.xml
sudo gedit /usr/local/hadoop/etc/hadoop/core-site.xml
- 1
设置HDFS的默认名称
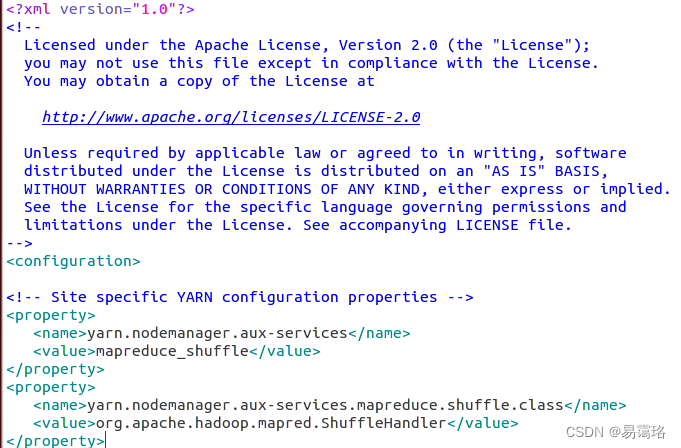
修改yarn-site.xml
sudo gedit /usr/local/hadoop/etc/hadoop/yarn-site.xml
- 1
输入以下内容
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
设置mapred-site.xml
复制模板文件
sudo cp /usr/local/hadoop/etc/hadoop/mapred-site.xml.template /usr/local/hadoop/etc/hadoop/mapred-site.xml
- 1
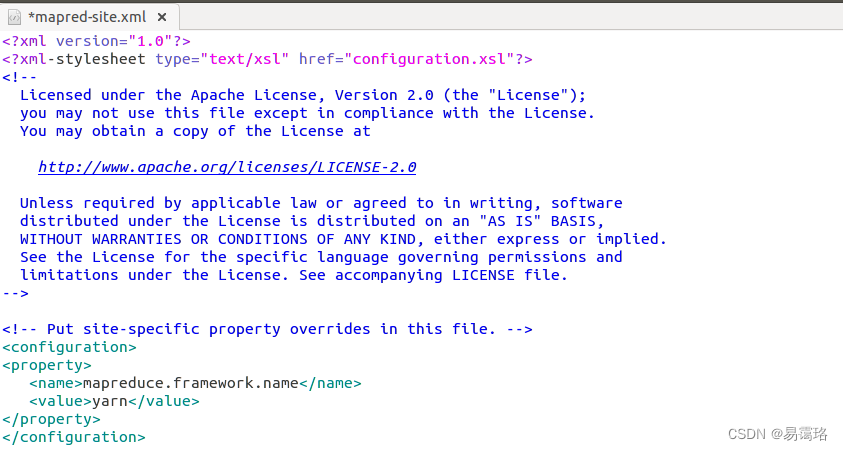
编辑mapred-site.xml
sudo gedit /usr/local/hadoop/etc/hadoop/mapred-site.xml
- 1
将mapreduce框架改为yarn
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
- 1
- 2
- 3
- 4
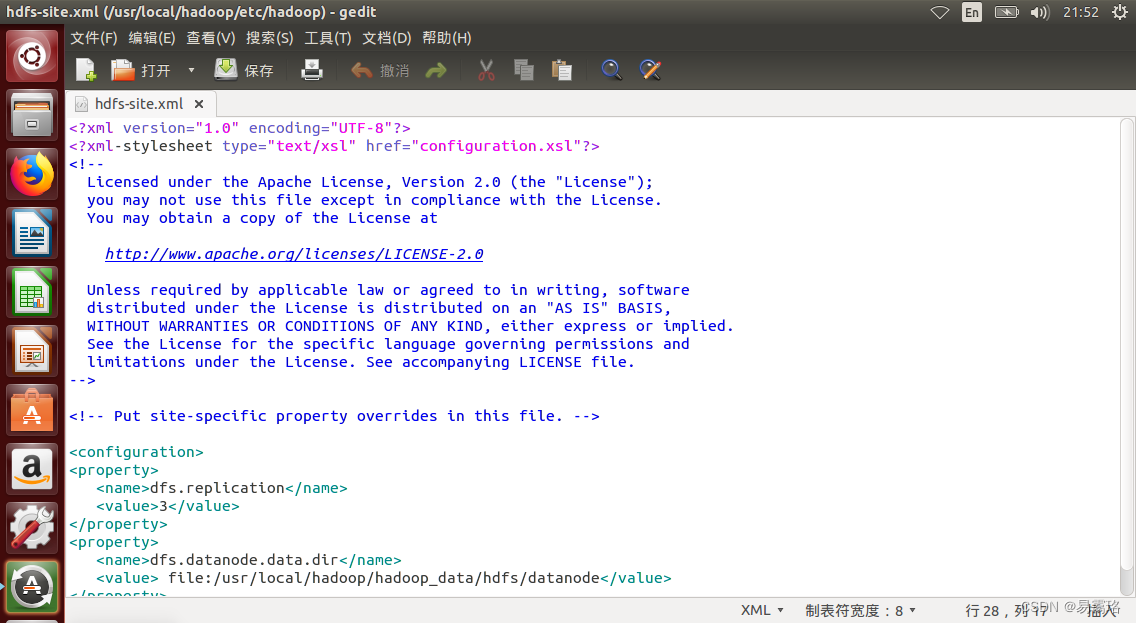
设置hdfs-site.xml
sudo gedit /usr/local/hadoop/etc/hadoop/hdfs-site.xml
- 1
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/hadoop_data/hdfs/datanode</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/hadoop_data/hdfs/namenode</value>
</property>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
创建并格式化HDFS目录
创建NameNode数据存储目录
sudo mkdir -p /usr/local/hadoop/hadoop_data/hdfs/namenode
- 1
创建DataNode数据存储目录
sudo mkdir -p /usr/local/hadoop/hadoop_data/hdfs/datanode
- 1
修改hadoop目录的所有者(你的主机名)
sudo chown hduser:hduser -R /usr/local/hadoop
- 1
将HDFS格式化(此语句有版本差异,如果执行后报错,请安装提示执行正确的语句)
hdfs namenode -format
- 1
启动Hadoop
start-all.sh
- 1
查看NameNode,DataNode进程是否启动
jps
- 1

打开浏览器分别输入以下两个网址都能正常打开代表hadoop单机伪分布式环境搭建成功
(Hadoop ResourceManager Web界面网址)
http://localhost:8088/
(Namenode HDFS Web 界面网址)
http://localhost:50070/

