
热门标签
热门文章
- 1DOT:视觉SLAM的动态目标物跟踪
- 204 Mybatis应用篇---XML映射文件之select,insert,update,delete基础介绍_mybatis.xml映射文件中 insert select 结合
- 3Redis面试题(2020最新版)
- 4SSM流程及核心原理_ssm核心
- 5阿里云RDS 读写分离_阿里云rds读写分离如何实现
- 6掌握Python中的“容器”,你只需要这一篇!_python如何实现 结构体的容器
- 7非常适合自学人工智能大模型的10个公众号号
- 8鸿蒙Harmony应用开发—ArkTS声明式开发(基础手势:TextArea)
- 9各节点共享主节点文件的实现方法_共享节点
- 10Android线程池的使用及demo_android newcachedthreadpool
当前位置: article > 正文
随机森林,随机森林中进行特征重要性_随机森林贡献值的分析
作者:你好赵伟 | 2024-03-15 05:56:11
赞
踩
随机森林贡献值的分析
随机森林(RF)简介
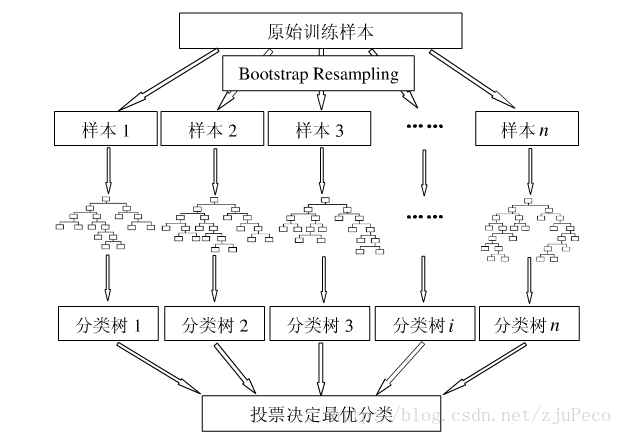
只要了解决策树的算法,那么随机森林是相当容易理解的。随机森林的算法可以用如下几个步骤概括:
- 用有抽样放回的方法(bootstrap)从样本集中选取n个样本作为一个训练集
- 用抽样得到的样本集生成一棵决策树。在生成的每一个结点:
- 随机不重复地选择d个特征
- 利用这d个特征分别对样本集进行划分,找到最佳的划分特征(可用基尼系数、增益率或者信息增益判别)
- 重复步骤1到步骤2共k次,k即为随机森林中决策树的个数。
- 用训练得到的随机森林对测试样本进行预测,并用票选法决定预测的结果。
下图比较直观地展示了随机森林算法(图片出自文献2)
特征重要性评估
现实情况下,一个数据集中往往有成百上前个特征,如何在其中选择比结果影响最大的那几个特征,以此来缩减建立模型时的特征数是我们比较关心的问题。这样的方法其实很多,比如主成分分析,lasso等等。不过,这里我们要介绍的是用随机森林来对进行特征筛选。
用随机森林进行特征重要性评估的思想其实很简单,说白了就是看看每个特征在随机森林中的每颗树上做了多大的贡献,然后取个平均值,最后比一比特征之间的贡献大小。
好了,那么这个贡献是怎么一个说法呢?通常可以用基尼指数(Gini index)或者袋外数据(OOB)错误率作为评价指标来衡量
判断每个特征在随机森林中的每颗树上做了多大的贡献,然后取个平均值,最后比一比特征之间的贡献大小。其中关于贡献的计算方式可以是基尼指数或袋外数据错误率


https://blog.csdn.net/zjuPeco/article/details/77371645?locationNum=7&fps=1
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/你好赵伟/article/detail/239177
推荐阅读

相关标签

