
- 1基于YOLOv8的船舶目标检测系统(Python源码+Pyqt6界面+数据集)_yolov8目标检测数据集
- 2使用Opencv实现Halcon中的动态阈值
- 3揭示IP查询结果偏差的现象及其影响
- 4【Linux驱动篇】长延时、短延时和睡眠延时_schedule_timeout_uninterruptible的替代函数
- 5DQN算法&流程图&代码实现(Tensorflow2.x / Keras)_dqn算法流程图
- 6吴恩达深度学习笔记——神经网络与深度学习(Neural Networks and Deep Learning)_吴恩达deeplearning 笔记
- 7给开源大模型带来Function Calling、 Respond With Class
- 8QTCreator包含多个子项目&如何将cpp/h源代码按文件夹分类_qt源码分文件夹
- 9理解Batch Normalization(批量归一化)_batch normalizaton是高斯
- 10简单音乐播放器html+css+基础vue+含源码,有搜索和播放mv功能,代码可直接复制用。_音乐播放器html简单
分类算法(二)—— FastText(原理介绍)_fasttext 算法
赞
踩
分类算法(二)—— FastText 包括文本分类相关调用和操作
文本表示(一)—— word2vec(skip-gram CBOW) glove, transformer, BERT
这里整理FastText的相关原理介绍
参考link
简介
fasttext是facebook开源的一个词向量与文本分类工具,在2016年开源,典型应用场景是“带监督的文本分类问题”。提供简单而高效的文本分类和表征学习的方法,性能比肩深度学习而且速度更快。
fastText架构类似于word2vec的CBOW,使用词袋以及n-gram袋表征语句,还有使用子字(subword)信息,并通过隐藏表征在类别间共享信息。并且在分类层采用了一个softmax层级(利用了类别不均衡分布的优势)来加速运算过程。
可以说,fastText利用了深度学习的原理,但是比深度学习更快。
fasttext应用的两个不同任务:
- 有效文本分类 :有监督学习
- 学习词向量表征:无监督学习
代码
文本分类之前已经介绍过,训练模型的代码参见这里: 分类算法(二)—— FastText
词向量代码: 文本表示(三)—— fasttext 词向量调用代码
原理
终于该说原理了
CBOW(Continuous Bog-Of-Words):
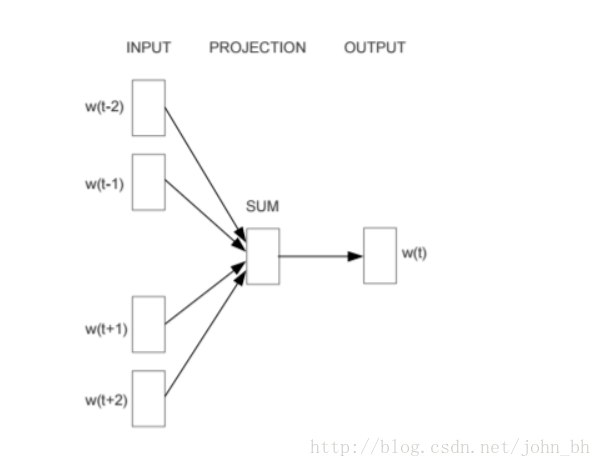
fastText
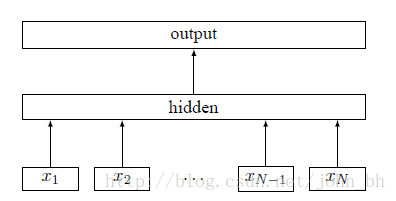
fastText 的模型架构和 word2vec 中的 CBOW 模型的结构很相似。CBOW 模型是利用上下文来预测中间词,而fastText 是利用上下文来预测文本的类别。而且从本质上来说,word2vec是属于无监督学习,fastText 是有监督学习。但两者都是三层的网络(输入层、单层隐藏层、输出层)
上面图中 xixi 表示的是文本中第 ii 个词的特征向量,该模型的负对数似然函数如下:
上面式子中的矩阵 A 是词查找表,整个模型是查找出所有的词表示之后取平均值,用该平均值来代表文本表示,然后将这个文本表示输入到线性分类器中,也就是输出层的 softmax 函数。式子中的 B 是函数 ff 的权重系数。
层次SoftMax
softmax 公式
类别非常多的时候,利用softmax 计算的代价是非常大的,时间复杂度为 O(kh)O(kh) ,其中 kk 是类别的数量,hh 是文本表示的维度。而基于霍夫曼树否建的层次 softmax 的时间复杂度为 O(h;log2(k))O(h;log2(k)) (二叉树的时间复杂度是 O(log2(k))O(log2(k)) )。霍夫曼树是从根节点开始寻找,而且在霍夫曼树中权重越大的节点越靠近根节点,这也进一步加快了搜索的速度。
fastText 也利用了类别(class)不均衡这个事实(一些类别出现次数比其他的更多),通过使用 Huffman 算法建立用于表征类别的树形结构。因此,频繁出现类别的树形结构的深度要比不频繁出现类别的树形结构的深度要小,这也使得进一步的计算效率更高。
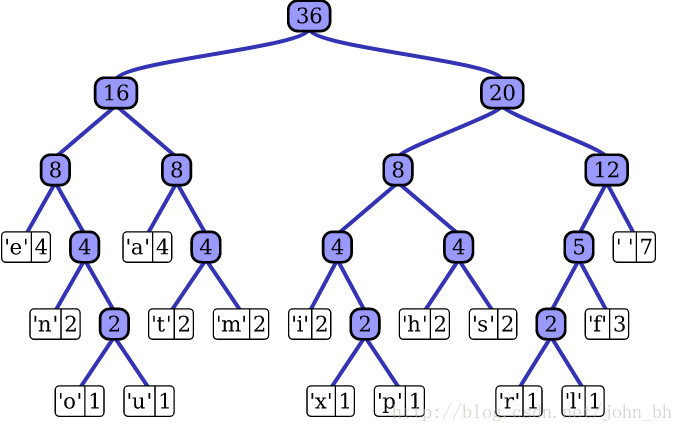
N-gram特征
fastText 可以用于文本分类和句子分类。不管是文本分类还是句子分类,我们常用的特征是词袋模型。但词袋模型不能考虑词之间的顺序,因此 fastText 还加入了 N-gram 特征。“我 爱 她” 这句话中的词袋模型特征是 “我”,“爱”, “她”。这些特征和句子 “她 爱 我” 的特征是一样的。如果加入 2-Ngram,第一句话的特征还有 “我-爱” 和 “爱-她”,这两句话 “我 爱 她” 和 “她 爱 我” 就能区别开来了。当然啦,为了提高效率,我们需要过滤掉低频的 N-gram。
fasttext和CBOW这么像,那怎么区分呢:
相同点:
1. 都采用embedding向量形式,可以得到word的向量表达;
2. 都采用了很多相似的优化方法,例如多层次softmax
不同点:
1. word2vec是无监督模型, fasttext是有监督模型,用来做分类任务
2. 模型输入层:word2vec输入层是context window内的term,并采用负采样来提高速度; fasttext对应的是整个sentence的内容,包括term和ngram内容
3. 模型输出层:word2vec输出是term,计算某term概率最大,fasttext输出层对应的是分类的label。 但是两者对应的vector都会被保留和使用
4. softmax使用:word2vec目的得到词向量,最终在输入层得到,输出层对应的h-softmax,也会省测绘给你一系列向量,但是都会被抛弃; fasttext充分利用了h-softmax的分类功能,遍历分类树所有叶子节点,找到概率最大的label(一个或N个)
总结:
fasttext速度较快,适用于分类类别非常大且数据集足够多的情况。分类类别少或者数据集少的时候容易过拟合。
fasttext支持多语言表达,对于包含中英混合的语料效果较好。
参考链接:
NLP︱高级词向量表达(二)——FastText(简述、学习笔记)
FastText情感分析和词向量训练实战——Keras算法练习 https://www.jianshu.com/p/87d4e4b4f9d2 https://www.jianshu.com/p/fba7df3a76fa
NLP︱高级词向量表达(二)——FastText(简述、学习笔记) https://blog.csdn.net/sinat_26917383/article/details/54850933
fastText原理及实践 https://zhuanlan.zhihu.com/p/32965521

