
- 1视频无损放大修复工具Topaz Video AI 新手入门教程_topaz video ai 报错
- 2Android Studio使用签名打包发布APP(安卓生成apk文件)_android studio 发布
- 3使用python快速搭建接口自动化测试脚本实战总结
- 4harmony 鸿蒙安全和高效的使用N-API开发Native模块_鸿蒙native开发(1)
- 5python版期货量化交易(AlgoPlus)案例(多进程处理子任务)
- 6DevExpress WinForms中文教程 - HTML & CSS支持的实战应用(二)
- 7使用案例总结Vlookup函数的30种用法
- 8基于spring boot架构和word分词器的分词检索,排序,分页实现_java word分词器maven
- 9最好的商业模式_切高端客户背后的原理
- 10SAP PM 入门系列7 - 常用Function Modules_sap pm模块 常用function
大模型llm(1):Ollama部署llama3学习入门llm_ollama 3模型
赞
踩
一、llama3简介
Llama 3 是一个自回归语言模型(an auto-regressive language),它使用优化的 transformer 架构。调整后的版本使用监督微调 (SFT) 和带有人类反馈的强化学习 (RLHF),以符合人类对有用性和安全性的偏好。
相关参数
| | 训练数据 | 参数量 | 上下文长度 | 分组查询注意力 (GQA) | 预训练数据 | 知识截至日期 |
| Llama 3 | 公开在线数据集 | 8B | 8K | 是 | 15T+ | 2023 年 3 月 |
| Llama 3 | | 70B | 8K | 是 | 15T+ | 2023 年 12 月 |
Llama3这个模型是在Meta新建的两座数据中心集群中训练的,包括超4.9万张英伟达H100GPU。
Llama3大型模型则达到400B,仍在训练中,目标是实现多模态、多语言的功能,预计效果将与GPT 4/GPT 4V相当。
二、Ollama安装
1、Ollama简介
Ollama 是一个开源的大型语言模型(LLM)服务工具,它允许用户在本地机器上运行和部署大型语言模型。Ollama 设计为一个框架,旨在简化在 Docker 容器中部署和管理大型语言模型的过程,使得这一过程变得简单快捷。用户可以通过简单的命令行操作,快速在本地运行如 Llama 3 这样的开源大型语言模型。
官网地址:https://ollama.com/download
Ollama 支持多种平台,包括 Mac 和 Linux,并提供了 Docker 镜像以简化安装过程。用户可以通过编写 Modelfile 来导入和自定义更多的模型,这类似于 Dockerfile 的作用。Ollama 还具备一个 REST API,用于运行和管理模型,以及一个用于模型交互的命令行工具集。
ollama 生态
- 客户端 桌面、Web
- 命令行工具
- 数据库工具
- 包管理工具
- 类库
2、安装ollama
Linux自动安装很简单,直接执行:
yum update -y nss curl libcurl
curl -fsSL https://ollama.com/install.sh >>install.sh
下载curl证书:
wget https://curl.se/ca/cacert.pem --no-check-certificate
添加curl证书
cat cacert.pem >> /etc/pki/tls/certs/ca-bundle.crt
sh install.sh
curl -fsSL https://ollama.com/install.sh | sh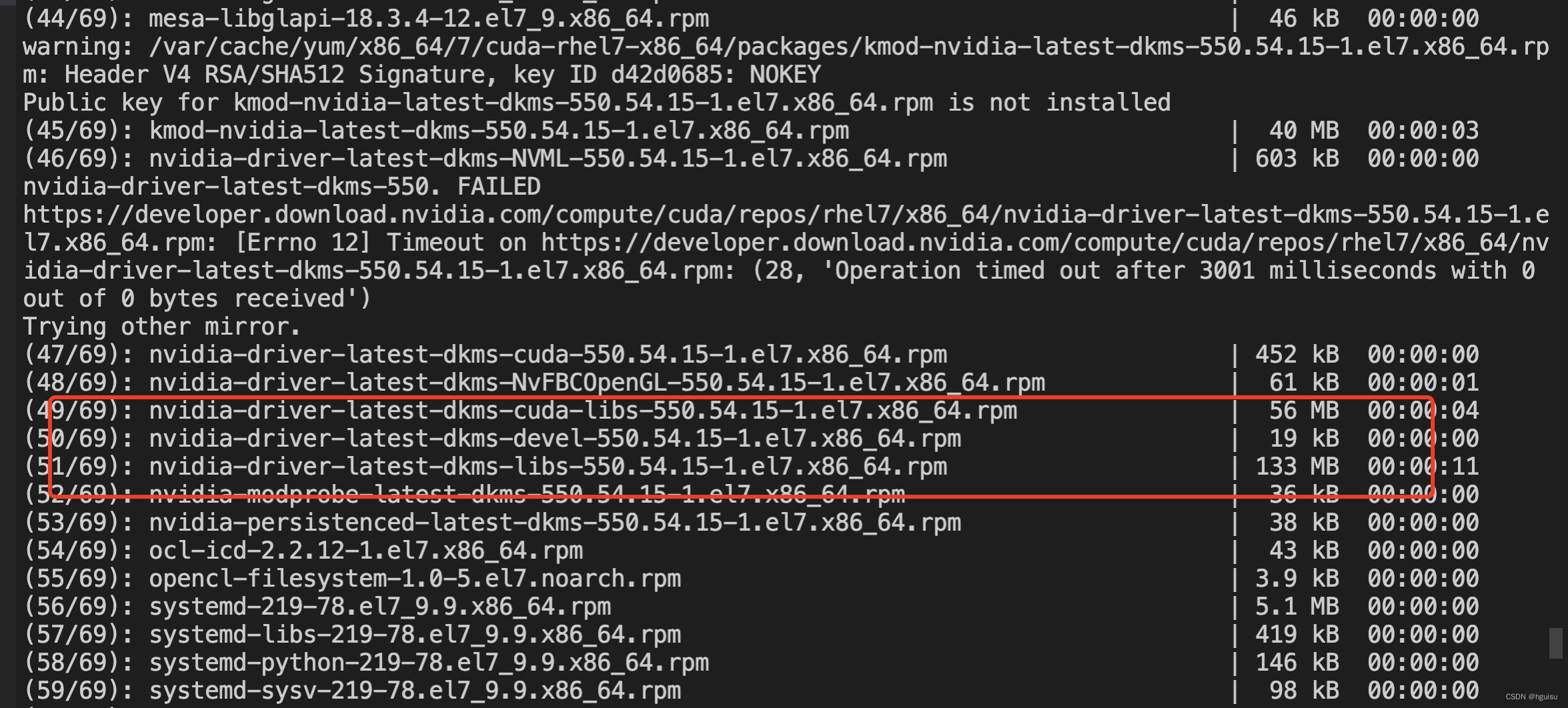
3、启动ollama
nohup ollama serve &
访问 Ollama Web 界面:打开您的浏览器,并访问 http://localhost:11434
若页面出现Ollama is running。则说明程序正常。
(如果您的 Docker 守护进程运行在远程主机上,则将 localhost 替换为相应的 IP 地址)。您将会看到 Ollama 的 Web 界面,通过它您可以开始构建、训练和部署深度学习模型。
Ensure that the Ollama server is properly configured to accept incoming connections from all origins. To do this, make sure the server is launched with the OLLAMA_ORIGINS=* environment variable, as shown in the following command:
OLLAMA_HOST=0.0.0.0 OLLAMA_ORIGINS=* ollama serve
This configuration allows Ollama to accept connections from any source.
所有地方都可以访问,使用变量设置,要不然只能是127.0.0.1访问:
export OLLAMA_HOST=0.0.0.0
export OLLAMA_ORIGINS=*
nohup ollama serve &
为使外网环境能够访问到服务,需要对HOST进行配置。
打开配置文件:vim /etc/systemd/system/ollama.service,根据情况修改变量Environment:
服务器环境下:Environment="OLLAMA_HOST=0.0.0.0:11434"
虚拟机环境下:Environment="OLLAMA_HOST=服务器内网IP地址:11434"
方法一:执行curl http://ip:11434命令,若返回“Ollama is running”,则表示连接正常。
方法二:在浏览器访问http://ip:11434,若页面显示文本“Ollama is running”,则表示连接正常。
三、llama3 模型下载安装
1、llama3 下载
默认下载的是llama3:8b。这里冒号前面代表模型名称,冒号后面代表tag,可以从这里查看llama3的所有tag
ollama pull llama3:8b默认下载的是llama3:8b。这里冒号前面代表模型名称,冒号后面代表tag,可以从这里查看llama3的所有tag
ollama pull llama3:70b
2、运行llama3模型
ollama run llama3
上述命令将自动拉取模型,并进行sha256验签。处理完毕后自动进入llama3的运行环境,可以使用中文或英文进行提问,ctrl+D退出。
四、访问 api 服务
1、prompt接口:
- curl http://localhost:11434/api/generate -d '{
- "model":"llama3:70b",
- "prompt": "请分别翻译成中文、韩文、日文 -> Meta Llama 3: The most capable openly available LLM to date",
- "stream": false
- }'
参数解释如下:
-
model(必需):模型名称。
-
prompt:用于生成响应的提示文本。
-
images(可选):包含多媒体模型(如llava)的图像的base64编码列表。
高级参数(可选):
- format:返回响应的格式。目前仅支持json格式。
- options:模型文件文档中列出的其他模型参数,如温度(temperature)。
- system:系统消息,用于覆盖模型文件中定义的系统消息。
- template:要使用的提示模板,覆盖模型文件中定义的模板。
- context:从先前的/generate请求返回的上下文参数,可以用于保持简短的对话记忆。
- stream:如果为false,则响应将作为单个响应对象返回,而不是一系列对象流。
- raw:如果为true,则不会对提示文本应用任何格式。如果在请求API时指定了完整的模板化提示文本,则可以使用raw参数。
- keep_alive:控制模型在请求后保持加载到内存中的时间(默认为5分钟)。
返回 json 数据
- {
-
-
- "model": "llama3",
- "created_at": "2024-04-23T08:05:11.020314Z",
- "response": "Here are the translations:\n\n**Chinese:** 《Meta Llama 3》:迄今最强大的公开可用的LLM\n\n**Korean:** 《Meta Llama 3》:현재 가장 강력한 공개 사용 가능한 LLM\n\n**Japanese:**\n\n《Meta Llama 3》:現在最強の公開使用可能なLLM\n\n\n\nNote: (Meta Llama 3) is a literal translation, as there is no direct equivalent for \"Meta\" in Japanese. In Japan, it's common to use the English term \"\" or \"\" when referring to Meta.",
- "done": true,
- "context": [
- ...
- ],
- "total_duration": 30786629492,
- "load_duration": 3000782,
- "prompt_eval_count": 32,
- "prompt_eval_duration": 6142245000,
- "eval_count": 122,
- "eval_duration": 24639975000
- }

返回值的解释如下:
- total_duration:生成响应所花费的总时间。
- load_duration:以纳秒为单位加载模型所花费的时间。
- prompt_eval_count:提示文本中的标记(tokens)数量。
- prompt_eval_duration:以纳秒为单位评估提示文本所花费的时间。
- eval_count:生成响应中的标记数量。
- eval_duration:以纳秒为单位生成响应所花费的时间。
- context:用于此响应中的对话编码,可以在下一个请求中发送,以保持对话记忆。
- response:如果响应是以流的形式返回的,则为空;如果不是以流的形式返回,则包含完整的响应。
要计算生成响应的速度,以标记数每秒(tokens per second,token/s)为单位,可以将 eval_count / eval_duration 进行计算。
2、聊天接口
curl http://localhost:11434/api/chat -d '{
"model": "llama3:70b",
"messages": [
{ "role": "user", "content": "why is the sky blue?" }
]
}'
五、配置Open-WebUI
可以直接使用dify开源的llm ops集成:https://guisu.blog.csdn.net/article/details/138978737?spm=1001.2014.3001.5502
两种安装方式:
1、docker部署:
docker run -d -p 3000:8080 --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main查看网关:查找标记为default或0.0.0.0的路由条目,它的网关地址即是你需要的host-gateway。
ip route

docker run -d -p 3000:8080 --add-host=host.docker.internal:172.25.191.253 -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main
要使用 Docker 安装 Open-webui,您可以创建一个 Docker 容器,并在其中运行 Open-webui 服务。以下是安装 Open-webui 的步骤:
拉取 Open WebUI 镜像:
首先,您需要从 Docker Hub 上拉取 Open WebUI的镜像。在终端或命令提示符中运行以下命令:
docker search open-webui
docker pull wanjinyoung/open-webui-main
运行 Open WebUI 容器:
使用以下命令在容器中运行 Open WebUI 服务:
docker run -d -p 3000:8080 --add-host=host.docker.internal:172.25.191.253 -v open-webui:/app/backend/data --name open-webui --restart always docker.io/wanjinyoung/open-webui-main:main
这将在后台运行一个名为 “open-webui” 的容器,并将容器内的端口 3000 映射到宿主机的端口 3000。
访问 Open WebUI: 打开您的浏览器,并访问 http://localhost:3000。您应该会看到 Open WebUI的用户界面,通过它您可以与 Ollama 平台进行交互,管理模型和监控训练过程。
2、源码部署:
安装Node.js
支持Ollama的WebUI非常多,笔者体验过热度第一的那个WebUI(github.com/open-webui/…%EF%BC%8C%E9%9C%80%E8%A6%81Docker%E6%88%96%E8%80%85Kubernetes%E9%83%A8%E7%BD%B2%EF%BC%8C%E6%9C%89%E7%82%B9%E9%BA%BB%E7%83%A6%EF%BC%8C%E8%80%8C%E4%B8%94%E9%95%9C%E5%83%8F%E4%B9%9F%E5%B7%AE%E4%B8%8D%E5%A4%9A1G%E3%80%82)
本文推荐使用ollama-webui-lite(github.com/ollama-webu…%EF%BC%8C%E9%9D%9E%E5%B8%B8%E8%BD%BB%E9%87%8F%E7%BA%A7%EF%BC%8C%E5%8F%AA%E9%9C%80%E8%A6%81%E4%BE%9D%E8%B5%96Node.js%E3%80%82)
设置国内NPM镜像
官方的NPM源国内访问有点慢,笔者推荐国内用户使用腾讯NPM源(mirrors.cloud.tencent.com/npm/),之前笔者使…
打开终端执行以下命令设置NPM使用腾讯源:
npm config set registry http://mirrors.cloud.tencent.com/npm/部署WebUI
打开终端,执行以下命令部署WebUI:
- git clone https://github.com/ollama-webui/ollama-webui-lite.git
- cd ollama-webui-lite
- npm install
- npm run dev
WebUI已经在本地3000端口进行监听:
3、配置及使用
进入到 Open WebUI 页面点击设置,在设置里面点击模型,输入我们需要下载的模型并点击下载,等下载完成之后我们就可以使用了。

