
- 1IDEA中连接Redis集群时抛出异常:CLUSTERDOWN Hash slot not served 的问题解决_redis.clients.jedis.exceptions.jedisclusterexcepti
- 2华为云配置安全组策略开放端口_华为云端口
- 3Go语言金融领域常用加密算法02国密SM4算法_golang sm4
- 4XILINX偶然加载不成功的问题原因及解决方法_fpga加载不起来的原因
- 5c语言图像均值,opencv利用视频的前n帧求平均图像
- 6嵌入式学习——3——UDP TFTP简易文件传输
- 7sparksql代码执行过于缓慢_warn jdbcutils: requested isolation level 1 is not
- 8【PCIE】DMA读写速度测试----Linux系统
- 9【javaSE】抽象类和接口(2)(接口部分)
- 10vue列表-查询筛选功能_vue表单查询
【AI+大模型】从媲美GPT4能力的国产DeepSeek-V2浅聊MOE模型_deepseek-v2-chat
赞
踩
5月6日,私募巨头幻方量化官微宣布,其探索AGI(通用人工智能)的新组织“深度求索(DeepSeek)”正式开源。
媲美GPT4能力
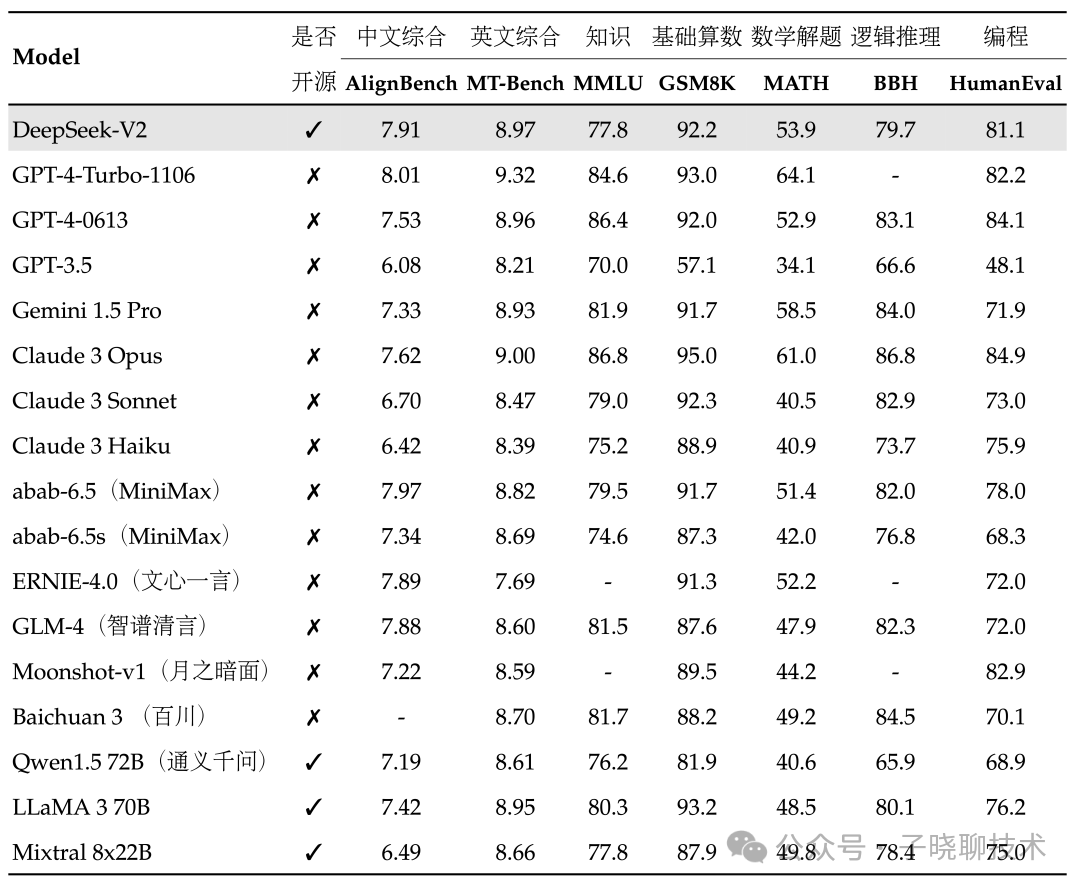
在目前大模型主流榜单中,DeepSeek-V2均表现出色:
-
中文综合能力(AlignBench)开源模型中最强,与GPT-4-Turbo,文心4.0等闭源模型在评测中处于同一梯队
-
英文综合能力(MT-Bench)与最强的开源模型LLaMA3-70B同处第一梯队,超过最强MoE开源模型Mixtral 8x22B
-
知识、数学、推理、编程等榜单结果也位居前列
-
支持128K上下文窗口
-
模型权重:
https://huggingface.co/deepseek-ai
技术报告:
https://github.com/deepseek-ai/DeepSeek-V2/blob/main/deepseek-v2-tech-report.pdf
自己注册账号试了下 https://chat.deepseek.com/ , 问题回答确实很快。可能训练的知识不够新,一些回答没得到自己想要的答案。感觉最新知识获取赶不上平时用得多的智谱清言或kimichat 。 注: 国内特色功能,感觉chatGPT4的回答也赶不上国内的几款主流大模型。

写了这么多,其实我最关注的是DeepSeek 是国内首个开源的MOE模型。这里, 我浅谈下大模型的研究新方向:混合专家模型(MoE)。据说GPT-4是8个2200亿MoE模型。
MOE(Mixture of Experts)模型是一种机器学习的集成方法,旨在通过结合多个“专家”(即模型),对任务进行建模。其特点、优势和缺点如下:
特点:
-
专家系统集成: MOE模型将数据分配给一群“专家”,每个专家负责处理数据的一个子集。
-
门控网络(Gating Network): 有一个门控网络或装置,用来决定哪个专家对给定的输入最为适用。
-
自动分工: MOE可以在训练过程中自动学习到数据的分工,使得不同的专家可以专注于解决特定问题领域的任务。
-
并行处理: 理论上,所有的“专家”可以并行处理数据,提高了模型的处理速度。
-
灵活性: 可以根据任务需求轻松添加或删除专家,使模型的规模和复杂性可控。
优势:
-
表现力强: MOE通过集成多个专家的知识,理论上有更强的表现力,能捕捉到数据的不同方面。
-
处理复杂任务: 对于复杂和多样化的任务,MOE因其专家分工能更好地处理。
-
泛化能力: 分布式表示和处理可以改进泛化能力,避免过度依赖单个模型的局限。
-
扩展性: 非常适合大规模、分布式的学习系统。
缺点:
-
训练难度: 调整和优化MOE模型中的门控机制和专家可以是复杂的,需要精细的调参。
-
资源消耗: 维护多个专家可能会消耗更多的计算资源。
-
冗余风险: 如果专家之间学习的特征有重叠,可能会造成冗余。
-
协调困难: 保持多个模型的同步和效率协调可能会带来额外的困难。
-
解释性差: MOE模型往往较为复杂,其决策路径可能不如单一模型容易解释。
总的来说,MOE模型提供了一种通过集成多个模型来解决问题的强大框架,尤其在任务十分复杂并且需要模型间分工合作的场景中表现出色。然而,这种模型也可能会增加设计和计算的复杂性,并且在理解模型行为方面存在一定挑战。
看完MOE模型的介绍, 有没有感觉和平时的项目管理很像。遇到需要冲刺的复杂项目,把任务拆解多个子项目, 对应任务经过项目经理拆解分配给 该部分擅长的同学, 通过具体分工,达到项目提前完成或按时完成的效果。虽然项目过程会存在资源冗余,协调困难的情况。但为了达到老板的上线要求,这不失为一个好的管理方式。
原文链接:【AI+大模型】从媲美GPT4能力的国产DeepSeek-V2浅聊MOE模型


