
alexnet实现cifar-10分类_cifar10 alexnet
赞
踩
Alexnet
alexnet网络结构
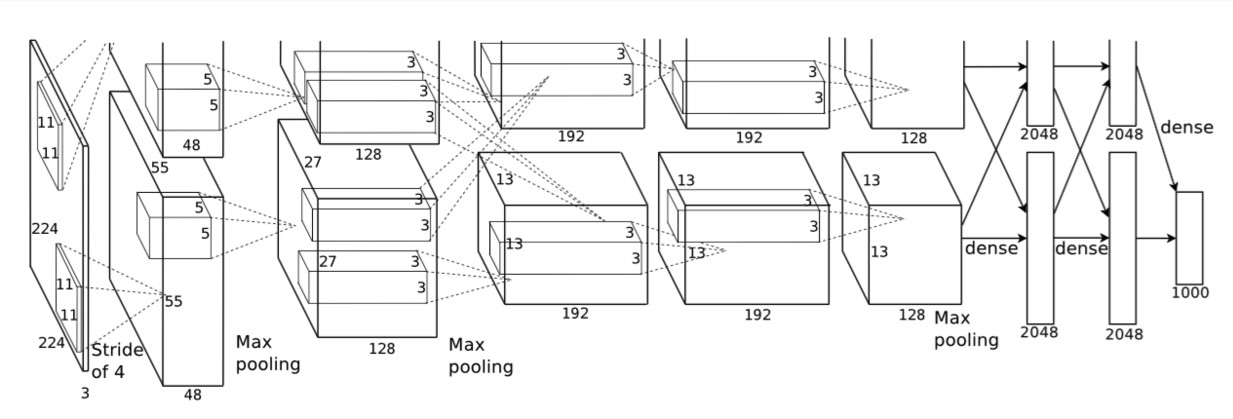
网络各层
网络包含8个带权重的层;前5层是卷积层,剩下的3层是全连接层。最后一层全连接层的输出是1000维softmax的输入,softmax会产生1000类c标签的分布网络包含8个带权重的层;前5层是卷积层,剩下的3层是全连接层。最后一层全连接层的输出是1000维softmax的输入,softmax会产生1000类标签的分布。
- 卷积层C1
该层的处理流程是: 卷积–>ReLU–>池化–>归一化。- 卷积,输入是227×227227×227,使用96个11×11×311×11×3的卷积核,得到的FeatureMap为55×55×9655×55×96。
- ReLU,将卷积层输出的FeatureMap输入到ReLU函数中。
- 池化,使用3×33×3步长为2的池化单元(重叠池化,步长小于池化单元的宽度),输出为27×27×9627×27×96((55−3)/2+1=27(55−3)/2+1=27)
- 局部响应归一化,使用k=2,n=5,α=10−4,β=0.75k=2,n=5,α=10−4,β=0.75进行局部归一化,输出的仍然为27×27×9627×27×96,输出分为两组,每组的大小为27×27×4827×27×48
- 卷积层C2
该层的处理流程是:卷积–>ReLU–>池化–>归一化- 卷积,输入是2组27×27×4827×27×48。使用2组,每组128个尺寸为5×5×485×5×48的卷积核,并作了边缘填充padding=2,卷积的步长为1. 则输出的FeatureMap为2组,每组的大小为27×27 times12827×27 times128. ((27+2∗2−5)/1+1=27(27+2∗2−5)/1+1=27)
- ReLU,将卷积层输出的FeatureMap输入到ReLU函数中
- 池化运算的尺寸为3×33×3,步长为2,池化后图像的尺寸为(27−3)/2+1=13(27−3)/2+1=13,输出为13×13×25613×13×256
- 局部响应归一化,使用k=2,n=5,α=10−4,β=0.75k=2,n=5,α=10−4,β=0.75进行局部归一化,输出的仍然为13×13×25613×13×256,输出分为2组,每组的大小为13×13×12813×13×128
- 卷积层C3
该层的处理流程是: 卷积–>ReLU- 卷积,输入是13×13×25613×13×256,使用2组共384尺寸为3×3×2563×3×256的卷积核,做了边缘填充padding=1,卷积的步长为1.则输出的FeatureMap为13×13 times38413×13 times384
- ReLU,将卷积层输出的FeatureMap输入到ReLU函数中
- 卷积层C4
该层的处理流程是: 卷积–>ReLU
该层和C3类似。- 卷积,输入是13×13×38413×13×384,分为两组,每组为13×13×19213×13×192.使用2组,每组192个尺寸为3×3×1923×3×192的卷积核,做了边缘填充padding=1,卷积的步长为1.则输出的FeatureMap为13×13 times38413×13 times384,分为两组,每组为13×13×19213×13×192
- ReLU,将卷积层输出的FeatureMap输入到ReLU函数中
- 卷积层C5
该层处理流程为:卷积–>ReLU–>池化- 卷积,输入为13×13×38413×13×384,分为两组,每组为13×13×19213×13×192。使用2组,每组为128尺寸为3×3×1923×3×192的卷积核,做了边缘填充padding=1,卷积的步长为1.则输出的FeatureMap为13×13×25613×13×256
- ReLU,将卷积层输出的FeatureMap输入到ReLU函数中
- 池化,池化运算的尺寸为3×3,步长为2,池化后图像的尺寸为 (13−3)/2+1=6(13−3)/2+1=6,即池化后的输出为6×6×2566×6×256
- 全连接层FC6
该层的流程为:(卷积)全连接 -->ReLU -->Dropout- 卷积->全连接: 输入为6×6×2566×6×256,该层有4096个卷积核,每个卷积核的大小为6×6×2566×6×256。由于卷积核的尺寸刚好与待处理特征图(输入)的尺寸相同,即卷积核中的每个系数只与特征图(输入)尺寸的一个像素值相乘,一一对应,因此,该层被称为全连接层。由于卷积核与特征图的尺寸相同,卷积运算后只有一个值,因此,卷积后的像素层尺寸为4096×1×14096×1×1,即有4096个神经元。
- ReLU,这4096个运算结果通过ReLU激活函数生成4096个值
- Dropout,抑制过拟合,随机的断开某些神经元的连接或者是不激活某些神经元
- 全连接层FC7
流程为:全连接–>ReLU–>Dropout- 全连接,输入为4096的向量
- ReLU,这4096个运算结果通过ReLU激活函数生成4096个值
- Dropout,抑制过拟合,随机的断开某些神经元的连接或者是不激活某些神经元
- 输出层
第七层输出的4096个数据与第八层的1000个神经元进行全连接,经过训练后输出1000个float型的值,这就是预测结果。
AlexNet参数数量
卷积层的参数 = 卷积核的数量 * 卷积核 + 偏置
- C1: 96个11×11×311×11×3的卷积核,96×11×11×3+96=3484896×11×11×3+96=34848
- C2: 2组,每组128个5×5×485×5×48的卷积核,(128×5×5×48+128)×2=307456(128×5×5×48+128)×2=307456
- C3: 384个3×3×2563×3×256的卷积核,3×3×256×384+384=8851203×3×256×384+384=885120
- C4: 2组,每组192个3×3×1923×3×192的卷积核,(3×3×192×192+192)×2=663936(3×3×192×192+192)×2=663936
- C5: 2组,每组128个3×3×1923×3×192的卷积核,(3×3×192×128+128)×2=442624(3×3×192×128+128)×2=442624
- FC6: 4096个6×6×2566×6×256的卷积核,6×6×256×4096+4096=377528326×6×256×4096+4096=37752832
- FC7: 4096∗4096+4096=167813124096∗4096+4096=16781312
- output: 4096∗1000=40960004096∗1000=4096000
卷积层 C2,C4,C5中的卷积核只和位于同一GPU的上一层的FeatureMap相连。从上面可以看出,参数大多数集中在全连接层,在卷积层由于权值共享,权值参数较少。
使用到的激活函数
Relu函数激活函数
Relu激活函数简介
Relu函数为现在使用比较广泛的激活函数,其表达式为 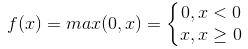
Relu函数相对于前边2种激活函数,有以下优点:
-
relu函数的计算十分简单,前向计算时只需输入值和一个阈值(这里为0)比较,即可得到输出值。在反向传播时,relu函数的导数为
。计算也比前边2个函数的导数简单很多。
-
由于relu函数的导数为
,即反向传播时梯度要么为0,要么不变,所以梯度的衰减很小,即使网路层数很深,前边层的收敛速度也不会很慢。
Relu函数也有很明显的缺点,就是在训练的时候,网络很脆弱,很容易出现很多神经元值为0,从而再也训练不动。一般我们将学习率设置为较小值来避免这种情况的发生。
为了解决上面的问题,后来又提出很多修正过的模型,比如Leaky-ReLU、Parametric ReLU和Randomized ReLU等,其思想一般都是将x<0的区间不置0值,而是设置为1个参数与输入值相乘的形式,如αx,并在训练过程对α进行修正。
通俗讲解激活函数:
激活函数可以引入非线性因素,解决线性模型所不能解决的问题。
为什么引入Relu呢
- 采用sigmoid函数,算激活函数时(指数运算),计算量大。而使用Relu,整个计算节省了很多。
- 对于深层网络,sigmoid函数反向传播时,很容易出现梯度消失的情况,(sigmoid接近饱和区的时候,变化太缓慢,导数趋于0)从而无法完成深层网络的训练。
- Relu会使一部分神经元的输出为0,这样就造成了网络的稀疏性,并且减少了参数之间互相依存的关系,缓解了过拟合的发生。
Relu激活函数代码实现
class Relu(): """Relu函数,反向传播时,x>0则会将上游的值原封不动的传递给下游(dx = dout) x<0则会将信号停在这里(dout=0) 先将输入数据转换为True和False的mask数组""" def __init__(self): self.mask = None # mask轮廓的含义,mask是由True/Fase组成的numpy数组。 def forward(self, x): self.mask = (x <= 0) # mask会将x元素小于等于0的地方保存为True,其他地方都保存为False out = x.copy() # False的地方输出为x out[self.mask] = 0 # 将True的地方输出为0 return out def backward(self, dout): dout[self.mask] = 0 # 前面保存了mask,True的地方反向传播会停在这个地方,故TRUE的地方设置为0,False的地方是将上游的值原封不动的传递给下游 dx = dout return dx
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
softmax激活函数
Softmax 是用于多类分类问题的激活函数,在多类分类问题中,超过两个类标签则需要类成员关系。对于长度为 K 的任意实向量,Softmax 可以将其压缩为长度为 K,值在(0,1)范围内,并且向量中元素的总和为 1 的实向量。
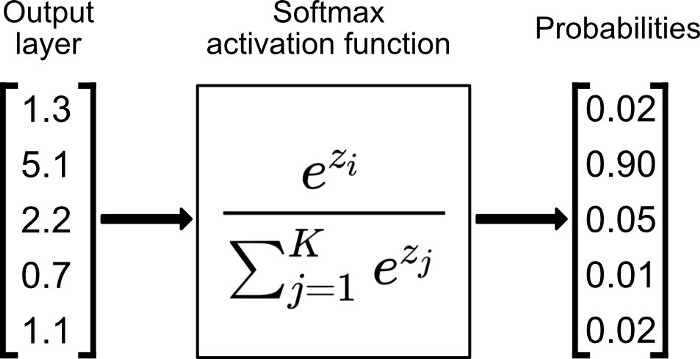
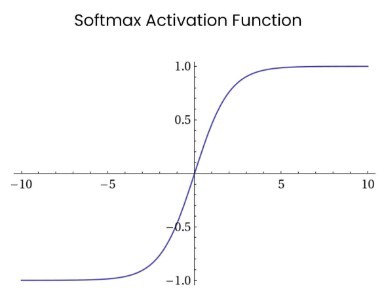
Softmax 与正常的 max 函数不同:max 函数仅输出最大值,但 Softmax 确保较小的值具有较小的概率,并且不会直接丢弃。我们可以认为它是 argmax 函数的概率版本或「soft」版本。
Softmax 函数的分母结合了原始输出值的所有因子,这意味着 Softmax 函数获得的各种概率彼此相关。
Softmax 激活函数的主要缺点是:
- 在零点不可微
- 负输入的梯度为零,这意味着对于该区域的激活,权重不会在反向传播期间更新,因此会产生永不激活的死亡神经元。
keras
Keras是什么
Keras:基于Theano和TensorFlow的深度学习库
Keras是一个高层神经网络API,Keras由纯Python编写而成并基Tensorflow、Theano以及CNTK后端。Keras 为支持快速实验而生,能够把你的idea迅速转换为结果,
特点:
- 简易和快速的原型设计(keras具有高度模块化,极简,和可扩充特性)
- 支持CNN和RNN,或二者的结合
- 无缝CPU和GPU切换
keras常用函数
Dense()函数–全连接层
-
函数
keras.layers.core.Dense ( units, activation=None, use_bias=True, kernel_initializer='glorot_uniform', bias_initializer='zeros', kernel_regularizer=None, bias_regularizer=None, activity_regularizer=None, kernel_constraint=None, bias_constraint=None )- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
-
函数参数
- units:大于0的整数,代表该层的输出维度。
- activation:激活函数,为预定义的激活函数名(参考激活函数),或逐元素(element-wise)的Theano函数。如果不指定该参数,将不会使用任何激活函数(即使用线性激活函数:a(x)=x)
- use_bias: 布尔值,是否使用偏置项
- kernel_initializer:权值初始化方法,为预定义初始化方法名的字符串,或用于初始化权重的初始化器。参考initializers
- bias_initializer:权值初始化方法,为预定义初始化方法名的字符串,或用于初始化权重的初始化器。参考initializers
- kernel_regularizer:施加在权重上的正则项,为Regularizer对象
- bias_regularizer:施加在偏置向量上的正则项,为Regularizer对象
- activity_regularizer:施加在输出上的正则项,为Regularizer对象
- kernel_constraints:施加在权重上的约束项,为Constraints对象
- bias_constraints:施加在偏置上的约束项,为Constraints对象
- input_dim:可以指定输入数据的维度
Conv2D()函数–卷积层
-
函数
keras.layers.Conv2D(filters, kernel_size, strides=(1, 1), padding='valid', data_format=None, dilation_rate=(1, 1), activation=None, use_bias=True, kernel_initializer='glorot_uniform', bias_initializer='zeros', kernel_regularizer=None, bias_regularizer=None, activity_regularizer=None, kernel_constraint=None, bias_constraint=None)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
-
函数参数
- filters: 整数,输出空间的维度 (即卷积中滤波器的输出数量)。
- kernel_size: 一个整数,或者 2 个整数表示的元组或列表, 指明 2D 卷积窗口的宽度和高度。 可以是一个整数,为所有空间维度指定相同的值。
- strides: 一个整数,或者 2 个整数表示的元组或列表, 指明卷积沿宽度和高度方向的步长。 可以是一个整数,为所有空间维度指定相同的值。 指定任何 stride 值 != 1 与指定 dilation_rate 值 != 1 两者不兼容。
- padding: “valid” 或 “same” (大小写敏感)。
- data_format: 字符串, channels_last (默认) 或 channels_first 之一,表示输入中维度的顺序。 channels_last 对应输入尺寸为 (batch, height, width, channels), channels_first 对应输入尺寸为 (batch, channels, height, width)。 它默认为从 Keras 配置文件 ~/.keras/keras.json 中 找到的 image_data_format 值。 如果你从未设置它,将使用 “channels_last”。
dilation_rate: 一个整数或 2 个整数的元组或列表, 指定膨胀卷积的膨胀率。 可以是一个整数,为所有空间维度指定相同的值。 当前,指定任何 dilation_rate 值 != 1 与 指定 stride 值 != 1 两者不兼容。 - activation: 要使用的激活函数 (详见 activations)。 如果你不指定,则不使用激活函数 (即线性激活: a(x) = x)。
- use_bias: 布尔值,该层是否使用偏置向量。
- kernel_initializer: kernel 权值矩阵的初始化器 (详见 initializers)。
- bias_initializer: 偏置向量的初始化器 (详见 initializers)。
- kernel_regularizer: 运用到 kernel 权值矩阵的正则化函数 (详见 regularizer)。
- bias_regularizer: 运用到偏置向量的正则化函数 (详见 regularizer)。
- activity_regularizer: 运用到层输出(它的激活值)的正则化函数 (详见 regularizer)。
- kernel_constraint: 运用到 kernel 权值矩阵的约束函数 (详见 constraints)。
- bias_constraint: 运用到偏置向量的约束函数 (详见 constraints)。
MaxPooling2D()函数–池化层
-
函数
keras.layers.pooling.MaxPooling2D( pool_size=(2, 2), strides=None, padding='valid', data_format=None )- 1
-
函数参数
- pool_size:整数或长为2的整数tuple,代表在两个方向(竖直,水平)上的下采样因子,如取(2,2)将使图片在两个维度上均变为原长的一半。为整数意为各个维度值相同且为该数字。
- strides:整数或长为2的整数tuple,或者None,步长值。
- padding:‘valid’或者‘same’
- data_format:字符串,“channels_first”或“channels_last”之一,代表图像的通道维的位置。该参数是Keras 1.x中的image_dim_ordering,“channels_last”对应原本的“tf”,“channels_first”对应原本的“th”。以128x128的RGB图像为例,“channels_first”应将数据组织为(3,128,128),而“channels_last”应将数据组织为(128,128,3)。该参数的默认值是~/.keras/keras.json中设置的值,若从未设置过,则为“channels_last”。
Dropout()函数–抛弃一些参数防止过拟合
Dropout(x)
X可以取0–1之间,代表百分比抛弃数据
Dropout(0.5)随机抛弃百分之五十的数据
Model()函数–代表模型图
-
函数
inputs = Input((n_ch, patch_height, patch_width)) conv1 = Convolution2D(32, 3, 3, activation='relu', border_mode='same')(inputs) conv1 = Dropout(0.2)(conv1) conv1 = Convolution2D(32, 3, 3, activation='relu', border_mode='same')(conv1) up1 = UpSampling2D(size=(2, 2))(conv1) # conv2 = Convolution2D(16, 3, 3, activation='relu', border_mode='same')(up1) conv2 = Dropout(0.2)(conv2) conv2 = Convolution2D(16, 3, 3, activation='relu', border_mode='same')(conv2) pool1 = MaxPooling2D(pool_size=(2, 2))(conv2) # conv3 = Convolution2D(32, 3, 3, activation='relu', border_mode='same')(pool1) conv3 = Dropout(0.2)(conv3) conv3 = Convolution2D(32, 3, 3, activation='relu', border_mode='same')(conv3) pool2 = MaxPooling2D(pool_size=(2, 2))(conv3) # conv4 = Convolution2D(64, 3, 3, activation='relu', border_mode='same')(pool2) conv4 = Dropout(0.2)(conv4) conv4 = Convolution2D(64, 3, 3, activation='relu', border_mode='same')(conv4) pool3 = MaxPooling2D(pool_size=(2, 2))(conv4) # conv5 = Convolution2D(128, 3, 3, activation='relu', border_mode='same')(pool3) conv5 = Dropout(0.2)(conv5) conv5 = Convolution2D(128, 3, 3, activation='relu', border_mode='same')(conv5) # up2 = merge([UpSampling2D(size=(2, 2))(conv5), conv4], mode='concat', concat_axis=1) conv6 = Convolution2D(64, 3, 3, activation='relu', border_mode='same')(up2) conv6 = Dropout(0.2)(conv6) conv6 = Convolution2D(64, 3, 3, activation='relu', border_mode='same')(conv6) # up3 = merge([UpSampling2D(size=(2, 2))(conv6), conv3], mode='concat', concat_axis=1) conv7 = Convolution2D(32, 3, 3, activation='relu', border_mode='same')(up3) conv7 = Dropout(0.2)(conv7) conv7 = Convolution2D(32, 3, 3, activation='relu', border_mode='same')(conv7) # up4 = merge([UpSampling2D(size=(2, 2))(conv7), conv2], mode='concat', concat_axis=1) conv8 = Convolution2D(16, 3, 3, activation='relu', border_mode='same')(up4) conv8 = Dropout(0.2)(conv8) conv8 = Convolution2D(16, 3, 3, activation='relu', border_mode='same')(conv8) # pool4 = MaxPooling2D(pool_size=(2, 2))(conv8) conv9 = Convolution2D(32, 3, 3, activation='relu', border_mode='same')(pool4) conv9 = Dropout(0.2)(conv9) conv9 = Convolution2D(32, 3, 3, activation='relu', border_mode='same')(conv9) # conv10 = Convolution2D(2, 1, 1, activation='relu', border_mode='same')(conv9) conv10 = core.Reshape((2,patch_height*patch_width))(conv10) conv10 = core.Permute((2,1))(conv10) ############ conv10 = core.Activation('softmax')(conv10) model = Model(input=inputs, output=conv10)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
-
作用
将模型的输入和输出给model函数就会自己组建模型运行图结构
ModelCheckpoint()函数–保存模型参数
-
函数
checkpointer = ModelCheckpoint(filepath='./'+name_experiment+'/'+name_experiment +'_best_weights.h5', verbose=1, monitor='val_loss', mode='auto', save_best_only=True) model.fit(patches_imgs_train, patches_masks_train, epochs=N_epochs, batch_size=batch_size, verbose=1, shuffle=True, validation_split=0.1, callbacks=[checkpointer])- 1
- 2
- 3
-
作用
- ModelCheckpoint函数可以指定一定训练次数后保存中间训练的最佳参数
- ModelCheckpoint函数作为model.fit()函数中回调函数使用
model.fit()函数–模型运行函数
-
函数
fit(self, x, y, batch_size=32, epochs=10, verbose=1, callbacks=None, validation_split=0.0, validation_data=None, shuffle=True, class_weight=None, sample_weight=None, initial_epoch=0 )- 1
- 2
-
函数参数
- x:输入数据。如果模型只有一个输入,那么x的类型是numpy array,如果模型有多个输入,那么x的类型应当为list,list的元素是对应于各个输入的numpy array
- y:标签,numpy array
- batch_size:整数,指定进行梯度下降时每个batch包含的样本数。训练时一个batch的样本会被计算一次梯度下降,使目标函数优化一步。
- epochs:整数,训练的轮数,每个epoch会把训练集轮一遍。
- verbose:日志显示,0为不在标准输出流输出日志信息,1为输出进度条记录,2为每个epoch输出一行记录
- callbacks:list,其中的元素是keras.callbacks.Callback的对象。这个list中的回调函数将会在训练过程中的适当时机被调用,参考回调函数
- validation_split:0~1之间的浮点数,用来指定训练集的一定比例数据作为验证集。验证集将不参与训练,并在每个epoch结束后测试的模型的指标,如损失函数、精确度等。注意,validation_split的划分在shuffle之前,因此如果你的数据本身是有序的,需要先手工打乱再指定validation_split,否则可能会出现验证集样本不均匀。
- validation_data:形式为(X,y)的tuple,是指定的验证集。此参数将覆盖validation_spilt。
- shuffle:布尔值或字符串,一般为布尔值,表示是否在训练过程中随机打乱输入样本的顺序。若为字符串“batch”,则是用来处理HDF5数据的特殊情况,它将在batch内部将数据打乱。
- class_weight:字典,将不同的类别映射为不同的权值,该参数用来在训练过程中调整损失函数(只能用于训练)
- sample_weight:权值的numpy array,用于在训练时调整损失函数(仅用于训练)。可以传递一个1D的与样本等长的向量用于对样本进行1对1的加权,或者在面对时序数据时,传递一个的形式为(samples,sequence_length)的矩阵来为每个时间步上的样本赋不同的权。这种情况下请确定在编译模型时添加了sample_weight_mode=‘temporal’。
- initial_epoch: 从该参数指定的epoch开始训练,在继续之前的训练时有用。
load_weights()函数–直接导入训练好的模型
# 加载训练好的模型
model.load_weights('./weights.h5')
- 1
- 2
predict()函数–测试数据
predictions = model.predict(patches_imgs_test, batch_size=32, verbose=2)
print("predicted images size :")
print(predictions.shape)
- 1
- 2
- 3
代码实现
环境安装
基础配置,环境不做解释
python,Tensorflow,Keras版本匹配
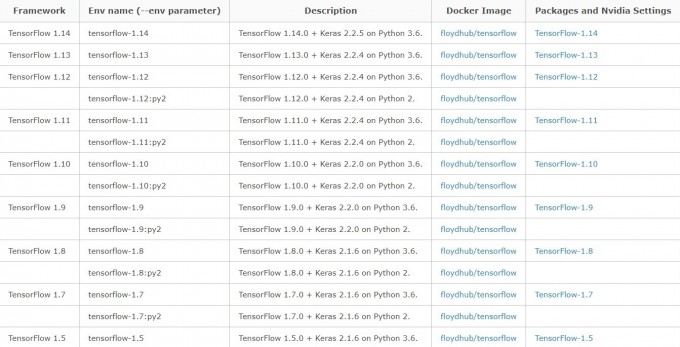
训练代码
# 基于keras的Alexnet做cifar10数据集分类 import tensorflow as tf from tensorflow.keras import Model from tensorflow.keras.layers import Conv2D, BatchNormalization, Activation from tensorflow.keras.layers import MaxPool2D, Flatten, Dense, Dropout import os from matplotlib import pyplot as plt # 完成数据集的导入 # 使用keras库darasets下载cifar10 cifar10 = tf.keras.datasets.cifar10 # 下载数据训练集,训练集标签,测试集合,测试集标签 (x_train, y_trian), (x_test, y_test) = cifar10.load_data() # 归一化处理 # 归一化是指归纳同意样本的统计分布性,归一化在0-1之间是统计概率分布 # 归一化处理的目的 # 为了后面数据处理方便,归一化可以避免一些不必要的数值问题。 # 为了程序运行时收敛加快。 # 统一量纲。样本数据的评价标准不一样,需要对其量纲化,统一评价标准。 x_train, x_test = x_train / 255.0, x_test / 255.0 # 定义AlexNet网络结构继承Model class AlexNet8(Model): # 构造函数 def __init__(self): # 父类构造一下 super(AlexNet8, self).__init__() # 第一次的卷积池化 就完成了 # 第一层卷积层 卷积核96(最后输出通道数) 使用3*3卷积核 self.c1 = Conv2D(filters=96, kernel_size=(3, 3)) # 深度神经网络训练过程中使得每一层神经网络的输入保持相同分布的。 self.b1 = BatchNormalization() # 将每一个batch进行归一化(一个batch是一组,之后权重清空) # 激活层ReLU(x) = max(0,x) self.a1 = Activation('relu') # 池化 # 整个图像中的这种“卷积”会产生大量的信息,这可能会很快成为一个计算噩梦。进入池化层,可将其全部缩小成更通用和可消化的形式。 # 有很多方法可以解决这个问题,最受欢迎的是“最大池”(Max Pooling),它将每个特征图编辑成自己的“读者文摘”版本 # 使用3*3卷积核,卷积步长2 self.p1 = MaxPool2D(pool_size=(3, 3), strides=2) # 第二次卷积池化 完成 self.c2 = Conv2D(filters=256, kernel_size=(3, 3)) self.b2 = BatchNormalization() self.a2 = Activation('relu') self.p2 = MaxPool2D(pool_size=(3, 3), strides=2) # 第三层 # 第三层没有使用池化层,只有一个卷积层与另外一个激活函数 self.c3 = Conv2D(filters=384, kernel_size=(3, 3), padding='same', activation='relu') # 第四层 同上 self.c4 = Conv2D(filters=384, kernel_size=(3, 3), padding='same', activation='relu') # 第五层 同上 self.c5 = Conv2D(filters=256, kernel_size=(3, 3), padding='same', activation='relu') # 第三次池化 self.p3 = MaxPool2D(pool_size=(3, 3), strides=2) # 最后一次池化操作后将特征图拉直输入到全连接层 # flatten返回一个一维数组。 将三维拉伸到一维 self.flatten = Flatten() # 将特征图送入第一层全连接网络 神经元个数(输出个数)2048 激活函数relu self.f1 = Dense(2048, activation='relu') # 加入Dropout层 随机丢弃 随机丢弃率0.5 self.d1 = Dropout(0.5) # 第二个全连接层 self.f2 = Dense(2048, activation='relu') # 加入Dropout层 随机丢弃 随机丢弃率0.5 self.d2 = Dropout(0.5) # 将所有元素映射到第三个全连接网络中 神经元10(cifar是10分类) 激活函数softmax 完成10分类 self.f3 = Dense(10, activation='softmax') def call(self, x): # 输入经过第一个卷积层 x = self.c1(x) x = self.b1(x) x = self.a1(x) x = self.p1(x) # 第二个 x = self.c2(x) x = self.b2(x) x = self.a2(x) x = self.p2(x) # 第三个 x = self.c3(x) # 第四个 x = self.c4(x) # 第五个 x = self.c5(x) # 数据池化 x = self.p3(x) # 数据拉为一维 x = self.flatten(x) # 经过各个全连接层 x = self.f1(x) x = self.d1(x) x = self.f2(x) x = self.d2(x) # 将结果输出 y = self.f3(x) return y model = AlexNet8() model.compile(optimizer='adam', # 稀疏分类交叉熵损失函数 loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=False), # 系数分类准确率指标 metrics=['sparse_categorical_accuracy']) # 导入上次训练结果 checkpoint_save_path = "checkpoint/AlexNet8.ckpt" if os.path.exists(checkpoint_save_path + '.index'): print(" load the model") model.load_weights(checkpoint_save_path) # ModelCheckpoint()函数--保存模型参数 cp_callback = tf.keras.callbacks.ModelCheckpoint(filepath=checkpoint_save_path, save_weights_only=True, # 是否只保留模型参数 save_best_only=True # 是否只保留最优结果 ) # fit函数 返回的是history对象,history.history 记录损失函数和其他指标的数值变化(epoch) history = model.fit(x_train, y_trian, batch_size=32, epochs=5, validation_data=(x_test, y_test), validation_freq=1, # 每一轮之后验证集验证 callbacks=[cp_callback] ) # model.summary()输出模型各层的参数状况 model.summary() # # 可视化图 # acc = history.history['sparse_categorical_accuracy'] # val_acc = history.history['val_sparse_categorical_accuracy'] # loss = history.history['loss'] # val_loss = history.history['val_loss'] # # plt.subplot(1, 2, 1) # plt.plot(acc, label='Training Accuracy') # plt.plot(val_acc, label='Validation Accuracy') # plt.title('Training and Validation Accuracy') # plt.legend() # # plt.subplot(1, 2, 2) # plt.plot(loss, label='Training Loss') # plt.plot(val_loss, label='Validation Loss') # plt.title('Training and Validation Loss') # plt.legend() # plt.show()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
训练结果(各层参数)
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-wALtI4Rl-1629277241681)(https://z3.ax1x.com/2021/06/04/2Gzy5V.png)]
可视化显示
如图显示:识别正确率>65%
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-4DjscpFr-1629277241684)(https://z3.ax1x.com/2021/06/04/2GzLxe.md.png)]
应用代码
import numpy as np from tensorflow.keras.preprocessing import image from tensorflow.keras.layers import Conv2D, BatchNormalization, Activation, MaxPool2D, Dropout, Flatten, Dense from tensorflow.keras import Model # 模型存储路径 model_save_path = './checkpoint/AlexNet8.ckpt' # 加载网络模型 class AlexNet8(Model): def __init__(self): super(AlexNet8, self).__init__() self.c1 = Conv2D(filters=96, kernel_size=(3, 3)) self.b1 = BatchNormalization() self.a1 = Activation('relu') self.p1 = MaxPool2D(pool_size=(3, 3), strides=2) self.c2 = Conv2D(filters=256, kernel_size=(3, 3)) self.b2 = BatchNormalization() self.a2 = Activation('relu') self.p2 = MaxPool2D(pool_size=(3, 3), strides=2) self.c3 = Conv2D(filters=384, kernel_size=(3, 3), padding='same', activation='relu') self.c4 = Conv2D(filters=384, kernel_size=(3, 3), padding='same', activation='relu') self.c5 = Conv2D(filters=256, kernel_size=(3, 3), padding='same', activation='relu') self.p3 = MaxPool2D(pool_size=(3, 3), strides=2) self.flatten = Flatten() self.f1 = Dense(2048, activation='relu') self.d1 = Dropout(0.5) self.f2 = Dense(2048, activation='relu') self.d2 = Dropout(0.5) self.f3 = Dense(10, activation='softmax') def call(self, x): x = self.c1(x) x = self.b1(x) x = self.a1(x) x = self.p1(x) x = self.c2(x) x = self.b2(x) x = self.a2(x) x = self.p2(x) x = self.c3(x) x = self.c4(x) x = self.c5(x) x = self.p3(x) x = self.flatten(x) x = self.f1(x) x = self.d1(x) x = self.f2(x) x = self.d2(x) y = self.f3(x) return y model = AlexNet8() # 加载已经训练好的网络模型 model.load_weights(model_save_path) # cafir10数据集 32*32大小 3通道 即:32*32*3 输入特征需要batch*32*32*3 # 将图片加载为指定像素 test_image = image.load_img('img/青蛙.jpg', target_size=(32, 32)) # 转换成array格式 32*32*3 test_image = image.img_to_array(test_image) # 将3维array格式数据增加一维变成4维 与所需要输入一致 test_image = np.expand_dims(test_image, axis=0) test_image = test_image / 255. # 输入图片进行预测 prediction = model.predict(test_image) # 选出最大概率 pred = max([int(i * 10) for i in prediction[0]]) # 含batchsize的维度 resultDict = {1: '飞机', 2: '汽车', 3: '鸟', 4: '猫', 5: '鹿', 6: '狗', 7: '青蛙', 8: '马', 9: '船', 10: '卡车'} print("预测图为:", resultDict[pred])
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
应用代码结果
预测图为: 青蛙
- 1
附加
上文代码仅仅可以识别32*32分辨率图片,网上下载图片需要更改分辨率。
为了方便导入训练集,以下是把cifar-10转化成jpg的python实现
import numpy as np import pickle as pkl import imageio # 将cifar10数据转化为图片+标签格式 # 定义反序列函数 def unpickle(file): fo = open(file, 'rb') dict = pkl.load(fo, encoding='bytes') # 以二进制的方式加载 fo.close() return dict # 转换train数据集 for j in range(1, 6): dataName = "data_batch_" + str(j) Xtr = unpickle(dataName) print(dataName + " is loading...") for i in range(0, 10000): img = np.reshape(Xtr[b'data'][i], (3, 32, 32)) img = img.transpose(1, 2, 0) picName = 'train/' + str(Xtr[b'labels'][i]) + '/' + str( i + (j - 1) */0000) + '.jpg' imageio.imwrite(picName, img) print(dataName + " loaded.") print("test_batch is loading...") # 转换test数据集 testXtr = unpickle("test/") for i in range(0, 10000): img = np.reshape(testXtr[b'data'][i], (3, 32, 32)) img = img.transpose(1, 2, 0) picName = 'test' + str(testXtr[b'labels'][i]) + '_' + str(i) + '.jpg' imageio.imwrite(picName, img) print("test_batch loaded.")
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
提示: 运行以上python需要手动创建相应folder,以下是批量新建0-9文件夹shell命令
mkdir {1..10}
- 1

