
热门标签
热门文章
- 1python使用fabric之只看这篇就够了_python fabric
- 2结构与算法(05):二叉树与多叉树_多叉树数据结构
- 3Neo4j 图形数据库中有哪些构建块?
- 4Android Studio使用命令行工具生成keystore的方法_android studio 生成keystore
- 5【学习教程系列】最通俗的 Python3 网络爬虫入门_python3 爬虫
- 6axios 请求超时处理方法_axios请求超时处理
- 7基础数据结构与算法总结1(附有完整代码,适合小白)_基本的数据结构与算法
- 8海量数据处理数据结构之Hash与布隆过滤器_布隆过滤器hash函数
- 97个Python爬虫实战项目教程_7个爬虫案例
- 10【Hadoop】-Hive部署[12]
当前位置: article > 正文
Hadoop学习笔记(9)-Spark的jupyter notebook开发环境搭建_jupyter notebook 管理hadoop
作者:凡人多烦事01 | 2024-04-13 12:51:22
赞
踩
jupyter notebook 管理hadoop
Spark的jupyter notebook开发环境搭建
安装Python
更新软件包,以免有些安装包找不到。
sudo apt-get update
- 1
安装 python3,默认 python3 将安装最新版本,一般Ubuntu都自带python在 /usr/local目录下
sudo apt-get install python3
- 1
安装python第三方安装工具:
sudo apt-get install python3-pip
- 1
查看Python版本信息
python3 -V
- 1

jupyter notebook介绍与安装
jupyter notebook简介
Jupyter Notebook是基于网页的用于交互计算的应用程序。其可被应用于全过程计算:开发、文档编写、运行代码和展示结果。
简而言之,Jupyter Notebook是以网页的形式打开,可以在网页页面中直接编写代码和运行代码,代码的运行结果也会直接在代码块下显示。如在编程过程中需要编写说明文档,可在同一个页面中直接编写,便于作及时的说明和解释。
jupyter notebook的安装
命令行下载 jupyter notebook
pip3 install jupyter -i https://pypi.tuna.tsinghua.edu.cn/simple
- 1

这时已经装好了,但是运行jupyter notebook会显示找不到命令,这就需要配置环境变量。
利用find命令查找jupyter的安装路径。
find -name jupyter
- 1

利用gedit命令编辑相关文件。
sudo gedit ~/.bashrc
- 1
将上面我们查找的jupter路径添加到环境变量中,也就是以下路径。
export PATH=~/.local/bin:${PATH}
- 1
令环境变量生效
source ~/.bashrc
- 1
运行 jupyter notebook
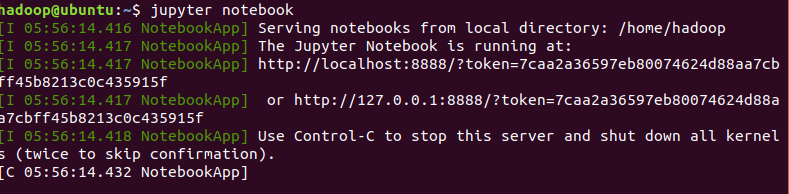
这时会自动跳转到jupter的网页,要是没有跳转可以在浏览器输入 http://localhost:8888/tree

连接jupyter与spark
安装 findspark
pip3 install findspark
- 1
测试 jupyter 是否成功连接 spark
import findspark
findspark.init("/usr/local/spark") # 指明SPARK_HOME
import pyspark
from pyspark import SparkContext, SparkConf
print("hello spark")
- 1
- 2
- 3
- 4
- 5
- 6
成功连接则会输出hello spark。

Spark环境下的一些基本操作
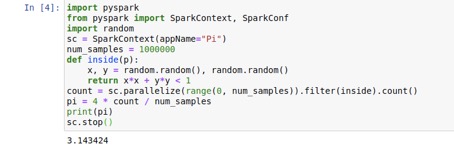
Spark环境下的Pi值计算
import findspark
findspark.init("/usr/local/spark") # 指明SPARK_HOME
import pyspark
from pyspark import SparkContext, SparkConf
import random
sc = SparkContext(appName="Pi")
num_samples = 1000000
def inside(p):
x, y = random.random(), random.random()
return x*x + y*y < 1
count = sc.parallelize(range(0, num_samples)).filter(inside).count()
pi = 4 * count / num_samples
print(pi)
sc.stop()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
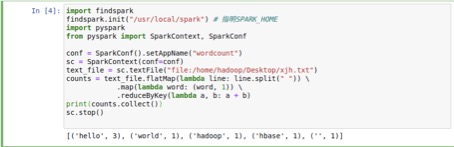
Spark环境下的WordCount计算
import findspark
findspark.init("/usr/local/spark") # 指明SPARK_HOME
import pyspark
from pyspark import SparkContext, SparkConf
conf = SparkConf().setAppName("wordcount")
sc = SparkContext(conf=conf)
text_file = sc.textFile("file:/home/hadoop/Desktop/xjh.txt")
counts = text_file.flatMap(lambda line: line.split(" ")) \
.map(lambda word: (word, 1)) \
.reduceByKey(lambda a, b: a + b)
print(counts.collect())
sc.stop()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
Spark Streaming计算
import findspark findspark.init("/usr/local/spark") # 指明SPARK_HOME import pyspark from pyspark import SparkContext from pyspark.streaming import StreamingContext sc = SparkContext("local[2]", "NetworkWordCount") ssc = StreamingContext(sc, 10) from operator import add from pyspark import SparkContext, SparkConf from pyspark.streaming import StreamingContext lines = ssc.textFileStream("file:/home/hadoop/Desktop") words = lines.flatMap(lambda line: line.split(' ')) wordCounts = words.map(lambda x: (x,1)).reduceByKey(add) wordCounts.pprint() ssc.start() ssc.awaitTermination()

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17

以上就是此次给大家分享的Hadoop学习笔记-Spark的jupyter notebook开发环境搭建,以及利用spark进行的一些基本的操作,在这个过程中也学到了很多,写下来分享给大家,有什么不太清楚的地方还需要大家指点迷津。
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/凡人多烦事01/article/detail/416552
推荐阅读
相关标签

