
- 1init.php on line 211,php – 使用未定义的常量
- 2xp系统能不能安装mysql_XP系统不能安装SQL Server 2000?
- 3Android 10 下拉状态栏定制,定制十:隐藏导航栏或状态栏
- 4MPU9250 九轴 EKF扩展卡尔曼滤波数据融合算法 使用扩展卡尔曼滤波(EKF)将数据融合
- 5Linux安装git(1),2024年最新硬核_linux git 安装
- 6leetcode之动态规划刷题总结7_leetcode [7,2,5,12] 严格
- 7免费好用的API接口汇总,赶紧收藏_免费的api接口
- 8树莓派4B安装64位桌面版ubuntu20_树莓派4 ubuntu20 桌面
- 9Windows下安装伪分布式Hadoop_windows中下载hadoop3.2.0
- 10逆向思维到底有多厉害,10个小故事让你学会逆向思维
达梦数据库: DM8中管理模式对象的基本操作手册_上届值
赞
踩
一、DM支持的数据类型
1.1.字符数据类型
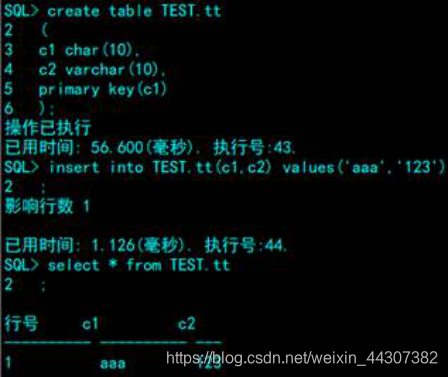
CHAR
CHARACTER
VARCHAER/VARCHAR2
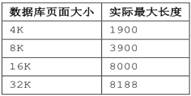
CHAR、CHARACTER:在表达式计算中,该类型的长度上限不受页面大小限制,为32767。但实际插入表中的列长度要受到记录长度的约束,每条记录长度不能大于页面大小的一半。
VARCHAER/VARCHAR2:没指定USING LONG ROW存储选项时,实际最大存储长度由数据页大小决定;指定则不受数据页大小限制。
CHAR 同 VARCHAR 的区别在于前者长度不足时,系统自动填充空格,而后者只占用实际的字节空间。
1.2数值数据类型
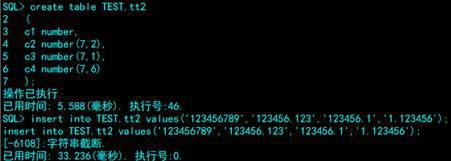
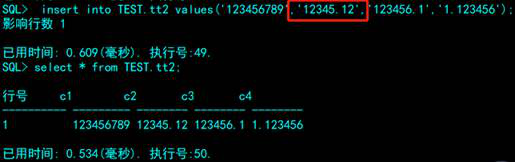
数值类型有numberic、decimal、float、double等等,达梦中,默认精度是20字节。
规律: number(a,b),b是小数位,a是表示整数位+小数位不能超过的和,可以等于。
另外整数位留下的机会是a-b得到的机会。
比如number(5,1), 表示留给整数位的有4位的机会(5-1=4),类似8.8888这类
比如number(5,4), 表示留给整数位的有1位的机会(5-4=1)。
比如number(5,0), 表示留给整数位的有5位的机会(5-0=5)。
1.3日期/时间类型
达梦数据库的日期相关类型:date、time、datetime(也可以写成timestamp),data类型把日期和时间分成了两个部分,对应两种不同的类型data和time,date的精度只到天,而time的精度到毫秒。达梦中也有即包括年月日也包括时分秒的数据类型datetime,也就是timestamp类型。
1.4大文本/多媒体类型
大文本/多媒体类型:text、blob、clob、image等等,text类型类似oracle中的long,不过没有long那么多的限制。text、blob、clob、image的最大长度都是1-2G,相当于oracle long字段的长度,blob和image类型的字段内容必须存储十六进制数字串内容。
二、DMsql表达式
& 按位与 如果两个相应的二进制位都为1,则该位的结果值为1,否则为0
| 按位或 两个相应的二进制位中只要有一个为1,该位的结果值为1
^ 按位异或 若参加运算的两个二进制位值相同则为0,否则为1
~ 取反 ~是一元运算符,用来对一个二进制数按位取反,即将0变1,将1变0
<< 左移 用来将一个数的各二进制位全部左移N位,右补0
>> 右移 将一个数的各二进制位右移N位,移到右端的低位被舍弃,对于无符号数,高位0 1:
2.1数值表达式
1. 一元算符 + 和 –
语法:+exp 、-exp
2. 一元算符 ~
语法:~exp
按位非算符,要求参与运算的操作数都为整数数据类型。
3. 二元算符 +、-、*、/
语法:exp1+exp2 、exp1- exp2 、exp1*exp2 、exp1/exp2
1) 只有精确数值数据类型的运算
两个相同类型的整数运算的结果类型不变,两个不同类型的整数运算的结果类型转换为范围较大的那个整数类型。
2) 有近似数值数据类型的运算
对于 exp1+exp2 、exp1- exp2 、exp1*exp2 、exp1/exp2 中 exp1 和 exp2只要有一个为近似数值数据类型,则结果为近似数值数据类型。
4. 二元算符 &
语法:exp1 & exp2(二进制)
按位与算符,要求参与运算的操作数都为整数数据类型。
参与运算的两个数据,按照二进制位进行“与运算”。
运算规则:0&0=0; 0&1=0; 1&0=0; 1&1=1;
即:两位同时为1,则值为1。否则为0
5. 二元算符 |
语法:exp1 | exp2
按位或算符,要求参与运算的操作数都为整数数据类型。
参与运算的两个数据,按照二进制位进行“或运算”。
运算规则:0&0=0; 0&1=1; 1&0=1; 1&1=1;
即:参与运算的两个数据只要有一个值为1 那么值为1
6. 二元算符 ^
语法:exp1 ^ exp2
按位异或算符,要求参与运算的操作数都为整数数据类型。
参与 运算的两个数据,按照二进制位进行“异或运算”。
运算规则: 0&0=0; 0&1=1; 1&0=1; 1&1=0;
即:参加运算的两个对象,如果两个相应位为“异”(值不同),则该位结果为1,否则为0。
7. 二元算符<<、>>
语法:exp1 << exp2
exp1 >> exp2
左移、右移运算符,要求参与运算的操作数只能为整数数据类型、精确数据类型。
2.2字符串表达式
连接 ||
语法:STR1 || STR2
(STR1 代表字符串 1,STR2 代表字符串 2)
连接操作符对两个运算数进行运算,其中每一个都是对属于同一字符集的字符串的求值。它以给定的顺序将字符串连接在一起,并返回一个字符串。其长度等于两个运算数长度之和。如果两个运算数中有一个是 NULL,则 NULL 等价为空串。
2.3运算符的优先级

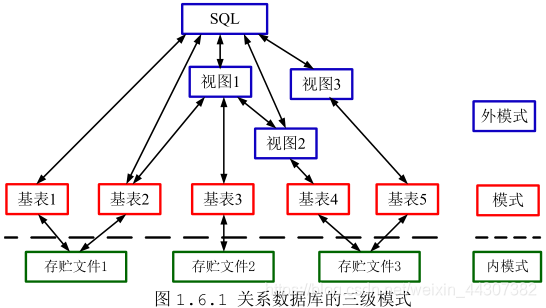
三、DMsql支持的数据库模式
DM_SQL 语言支持关系数据库的三级模式,外模式对应于视图和部分基表,模式对应于基表,基表是独立存在的表。一个或若干个基表存放于一个存贮文件中,存贮文件中的逻辑结构组成了关系数据库的内模式。DM_SQL 语言本身不提供对内模式的操纵语句。
四、管理表
表是数据库中数据存储的基本单元,是对用户数据进行读和操纵的逻辑实体。表由列和行组成,每一行代表一个单独的记录。如果要在所在模式创建表,需要有create table权限,在其他用户的模式中船建表,需要create any table权限。创建时,需要指定表空间,否则就在main中创建。
4.1设计表
1. 规范化表,估算并校正表结构,使数据冗余达到最小;
2. 为每个列选择合适的数据类型,是否允许为空等,并根据实际情况判断是否需要对列进行加密或压缩处理;
3. 建立合适的完整性约束,管理约束可查看 15 章管理完整性约束的内容;
4. 建立合适的聚集索引。每个表(列存储表,堆表除外)都含一个聚集索引,默认以ROWID 建立,而建立合适的聚集索引,可以有效加快表的检索效率;
5. 根据实际需要,建立合适类型的表。DM 支持的表类型包括普通表、临时表、水平分区表、堆表和列存储表。本章只介绍普通表和临时表,其他类型表将在其他章节中重点介绍。
4.2指定表的存储空间上限
在创建表时指定 SPACE LIMIT 子句,可以对表的存储空间指定上限。DM 支持对表的存储空间指定大小,单位是 MB,即表的大小可由管理员指定,便于表的规模管理。当表的所有索引所占用的存储空间超过指定大小时,表将不能再新增数据。
1、指定表TEST对象的最大磁盘空间为500M;
CREATE TABLE TEST (SNO INT, MYINFO VARCHAR) DISKSPACE LIMIT 500;
2、修改表TEST的磁盘空间相知为50M;
ALTER TABLE TEST MODIFY DISKSPACE LIMIT 50;
4.3指定表的存储位置
1、创建表时,在STORAGE子句中指定存储表的表空间;
2、不指定位置则在默认表空间MAIN中。
指定表存储位置的优点为:
不同的数据库对应不同的数据文件的话,相同文件的竞争会减少,从而提高数据库管理的性能。据库表分布在不同的表空间里,即使一个表空间随坏了,不妨碍其他表空间上数据库表的访问,不至于整个数据库都停摆。
4.4创建表(行表)
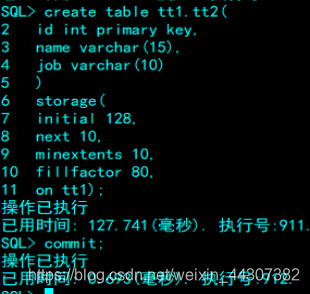
如果要在所在模式创建表,需要有create table权限,在其他用户的模式中船建表,需要create any table权限。创建时,需要指定表空间,否则就在main中创建。
例:在tt1表空间上建立tt2表,指定表的填充因子FILLFACTOR为80%
原则上,在只读表上应该设置填充因子高,而有大量更新的表上应该设置较低的值。
SQL> create table tt1.tt2(
2 id int primary key,
3 name varchar(15),
4 job varchar(10)
5 )
6 storage(
7 initial 128,
8 next 10,
9 minextents 10,
10 fillfactor 80,
11 on tt1);
4.5查询建表
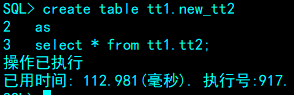
为了创建一个与已有表相同的新表,或者为了创建一个只包含另一个表的一些行和列的新表,可以使用 CREATE TABLE AS SELECT(CTAS)命令。使用该命令,可以通过使用WHERE条件将已有表中的一部分数据装载到一个新表中,或者可以通过 SELECT * FROM 子句将已有表的所有数据装载到创建的表中。
如果用户通过单表的全表查询进行建表操作,则可以通过将INI参数CTAB_SEL_WITH_CONS 置为1进行原始表上约束的拷贝,列上能拷贝的约束包括默认值属性、自增属性、非空属性以及加密属性,表上能拷贝的约束包括唯一约束、PK 约束以及 CHECK约束。
4.6创建临时表
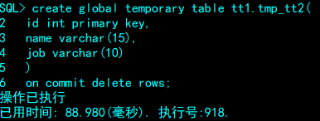
当处理复杂的查询或事务时,由于在数据写入永久表之前需要暂时存储一些行信息或需要保存查询的中间结果,可能需要一些表来临时存储这些数据。DM 允许创建临时表来保存会话甚至事务中的数据。在会话或事务结束时,这些表上的数据将会被自动清除。
临时表 ON COMMIT 关键词指定表中的数据是事务级还是或会话级的,默认情况下是事务级的。
1. ON COMMIT DELETE ROWS:指定临时表是事务级的,每次事务提交或回滚之后,表中所有数据都被删除;
2. ON COMMIT PRESERVE ROWS:指定临时表是会话级的,会话结束时才清空表,并释放临时 B 树。
SQL> create global temporary table tt1.tmp_tt2(
2 id int primary key,
3 name varchar(15),
4 job varchar(10)
5 )
6 on commit delete rows;
4.7更改表
想更改的表如果在所属的模式中,用户必须具有 ALTER TABLE 数据库权限;若在其他
模式中,用户必须有 ALTER ANY TABLE 的数据库权限。
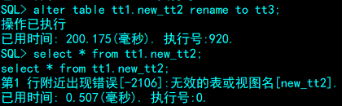
- 重命名
SQL> alter table tt1.new_tt2 rename to tt3;
2. 增加列
alter table tt1.tt3 add age int
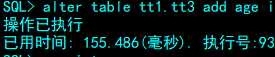
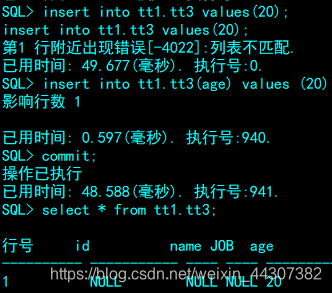
3. 删除列
SQL> alter table tt1.tt3 drop name;
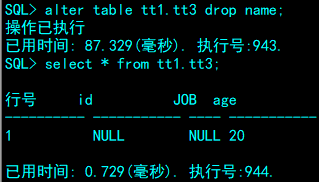
4.8删除表
当一个表不再使用时,可以将其删除。删除表时,将产生以下结果:
1. 表的结构信息从数据字典中删除,表中的数据不可访问;
2. 表上的所有索引和触发器被一起清除;
3. 所有建立在该表上的同义词、视图和存储过程变为无效;
4. 所有分配给表的簇标记为空闲,可被分配给其他的数据库对象。
一般情况下,普通用户只能删除自己模式下的表。若要删除其他模式下的表,则必须具有DROP ANY TABLE 数据库权限。
例:删除tmp_tt2表
SQL> drop table tt1.tmp_tt2;
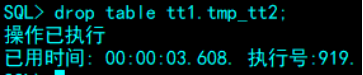
如果要删除的表被其他表应用,即其他表的外键引用了表的任何主键或唯一键,则需要
在 DROP TABLE 语句最后加CASCADE。
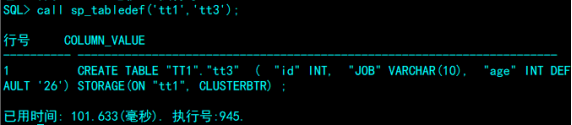
4.9查看表定义
SQL> call sp_tabledef('tt1','tt3');
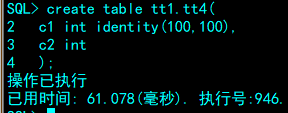
4.10查看自增列信息
DM 支持 INT 和 BIGINT 两种数据类型的自增列,并提供以下函数查看表上自增列当
前值、种子和增量等信息:
1. IDENT_CURRENT:获得表上自增列的当前值;
2. IDENT_SEED:获得表上自增列的种子信息;
3. IDENT_INCR:获得表上自增列的增量信息。
SQL> select ident_current('tt1.tt4');
SQL> select ident_seed('tt1.tt4');
SQL> select ident_incr('tt1.tt4');
4.11查看表的空间使用情况
查看已分配给表的页面数:SQL> select table_used_space('tt1','tt4');
查看表已使用的页面数:SQL> select table_used_pages('tt1','tt4');
五、管理HUGE表
5.1 HUGE表
列存储是以列为单位进行存储的,每一个列的所有行数据都存储在一起,而且一个指定的页面中存储的都是某一列的连续数据。Huge File System(检查 HFS)是达梦数据库实现的,针对海量数据进行分析的一种高效、简单的列存储机制。列存储表(也称为 HUGE 表)就是建立在 HFS 存储机制上的一种表。
HUGE 表与普通行表一样,可以进行增、删、改操作,操作方式也是一样的。但 HUGE表的删除与更新操作的效率会比行表低一些,并发操作性能也会比行表差一些,因此在HUGE中不宜做频繁的删除及更新操作。总之,HUGE 表比较适合做分析型表的存储。
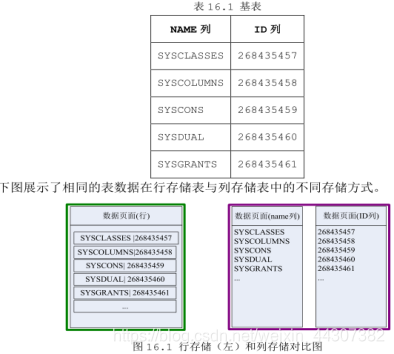
HUGE表建立在自己特有的表空间HTS上,最多可创建32767个HUGE表空间,相关信息存储动态视图在V$HUGE_TABLESPACE中。HUGE表是通过HTS存储机制来管理的,姓党与一个文件系统。创建一个HTS,就是创建要给空的文件目录。在创建一个 HUGE 表并插入数据时,数据库会在指定的 HTS 表空间目录下创建一系列的目录及文件。
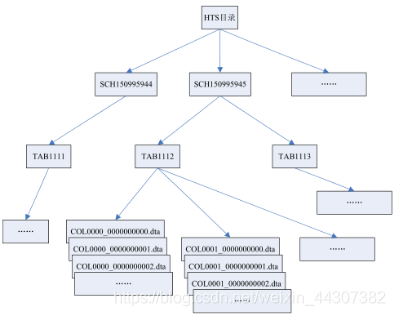
成功创建HUGE表,需以下步骤:
1)在HTS目录下创建这个表对应的模式目录,录名为“SCH+长度为9的ID号”组成的字符串。
2)在模式目录下创建对应的表目录。表目录名为”TAB+长度为4的ID号”,表目录中存放的是这个表中所有的文件。
3)在新创建表后插入数据时,每一个列对应一个以dta为后缀的文件,文件大小可以在建表时指定,默认为64M,文件名为”COL+长度为4的列号_长度为10的行号”。
系统对于一个文件,其内部存储是按照区来管理的,区是文件内部数据管理的最小单位,也是唯一的单位。一个区中,可以存储单列数据的行数是在创建表时指定的,一经指定,在这个表的生命过程就不能再修改。所以,对于定长数据,一个区的大小是固定的;而对于变长数据,一般情况下区大小都是不相同的。每一个区的开始位置及长度在文件内都是 4K 对齐的。
HUGE 表的存储方式有以下几个优点:
1. 同一个列的数据都是连续存储的,可以加快某一个列的数据查询速度;
2. 连续存储的列数据,具有更大的压缩单元和数据相似性,可以获得远优于行存储的压缩效率,压缩的单位是区;
3. 条件扫描借助数据区的统计信息进行精确过滤,可以进一步减少 IO,提高扫描效率;
4. 允许建立二级索引;
5. 支持以 ALTER TABLE 的方式添加或者删除 PK 和 UNIQUE 约束。会自动创建新的文件来存储不断增长的数据。
5.2创建过程
- 创建一个HUGETABLECE(HTS)
SQL> create HUGE TABLESPACE huge1 path '/home/dmdba/dmdbms/test/DAMENG/HTS';

5.3查看HUGE表定义
SQL> call sp_tabledef('SYSDBA','h1');
5.4查看数据存储情况
HUGE 表有一个很好的特点就是有 AUX 辅助表,其中用户可以利用的信息很多,因为每一条记录对应一个区,所以可以查看每一个区的存储情况,每一个列的存储情况及每一个列中具有相同区ID的所有数据的情况等,还包括了很精确的统计信息,用户可以通过观察AUX辅助表中的信息对表进行一些相应的操作。
六、管理分区表
6.1分区表
分区是指将表、索引等数据库对象划分为较小的可管理片段的技术,每一个片段称为分区子表或分区索引。一个表被分区后,对表的查询操作可以局限于某个分区进行,而不是整个表,这样可以大大提高查询速度。
1. 减少所有数据都损坏的可能性,一个表空间损坏不影响其他表空间,提高可用性;
2. 恢复时间大大减少;
3. 可以将同一个表中的数据分布在不同的磁盘上,从而均衡磁盘上的 I/O 操作;
4. 提高了表的可管理性、可利用性和访问效率。
分区表使用注意事项:
分区表建议取消主键,建唯一性本地索引防止数据重复
如果表中一定要主键,则分区范围一定要包含主键列
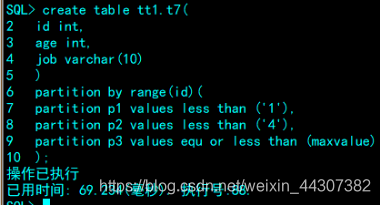
6.2创建范围(range)分区表
范围(range)水平分区:对表中的某些列上值的范围进行分区,根据某个值的范
围,决定将该数据存储在哪个分区上;范围分区非常适用于数据按时间范围组织的表,不同的时间段的数据属于不同的分区。
指定根据id上的值进行分区:partition by range(id)
P2的上届的值设定为4:partition p2 values less than ('4'),下届为p1的上届1,则p2包含的是(1,2,3),不包含上届值。
P3的上届值设定为maxvalue,下届为p2的上届4,且包含设定的上届值:
partition p3 values equ or less than (maxvalue)
当在分区表中执行 DML 操作时,实际上是在各个分区子表上透明地修改数据。当执行SELECT 命令时,可以指定查询某个分区上的数据。
SQL> select * from tt1.t7 partition (p1);
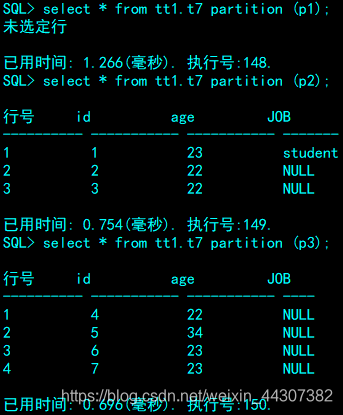
6.3创建LIST分区表
对于字符型数据,取值比较固定的,适合于采用 LIST 分区的方法。
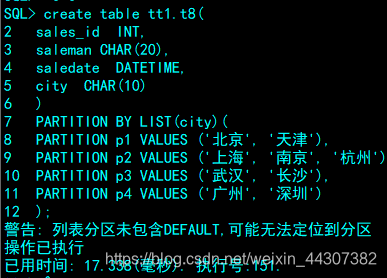
SQL> select * from tt1.t8 partition(p2);
![]()
6.4创建哈希分区表
在很多情况下,用户无法预测某个列上的数据变化范围,因而无法实现创建固定数量的范围分区或 LIST 分区。在这种情况下,DM 哈希分区提供了一种在指定数量的分区中均等地划分数据的方法,基于分区键的散列值将行映射到分区中。当用户向表中写入数据时,数据库服务器将根据一个哈希函数对数据进行计算,把数据均匀地分布在各个分区中。在哈希分区中,用户无法预测数据将被写入哪个分区中。
6.4.1指定表名创建HASH分表

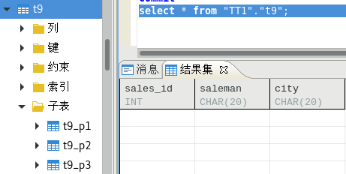
6.4.2指定哈希分区个数建立哈希分区表

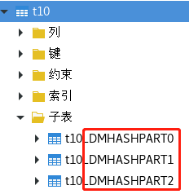
使用这种方式建立的哈希分区表分区名是匿名的,DM 统一使用DMHASHPART+分区号(从 0 开始)作为分区名。
执行以下语句进行查询。
SQL> select * from tt1.t10 partition (dmhashpart0);
6.5创建多级分区表
在很多情况下,经一次分区并不能精确地对数据进分类,这时需要多级分区表。
例:制定了子分区模板为GRADE,同时子分区P1,P2,P3有五个分区Q1,Q2,R1,R2,R3.。
查询一级分区:
SQL> select * from tt1.t11 partition(P1);
查询二级分区:
SQL> select * from tt1.t11 subpartition (P1_Q2);
查询三级分区:
SQL> select * from tt1.t11 subpartition(P1_Q2_R2);
6.6增加分区
只能对范围分区和 LIST 分区增加分区,不能对哈希分区增加分区。并且增加分区不会影响分区索引,因为分区索引只是局部索引,新增分区仅是新增分区子表,并更新分区主表的分区信息,其他分区并不发生改变。
6.6.1范围表增加分区
用 ALTER TABLE ADD PARTITION 语句将新分区增加到最后一个现存分区的后面。对于范围分区,增加分区必须在最后一个分区范围值的后面添加,要想在表的开始范围或中间增加分区,应使用 SPLIT PARTITION 语句。
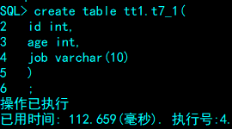
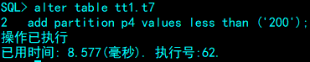
SQL> alter table tt1.t7
2 add partition p3 values less than ('100') storage (on tbs1);
6.6.2LIST表增加分区
对于 LIST 分区,增加分区包含的离散值不能已存在于某个分区中。
6.7删除分区
只能对范围分区和 LIST 分区进行删除分区,哈希分区不支持删除分区。跟增加分区一样,删除分区不会影响分区索引,因为分区索引只是局部索引,删除分区仅是删除分区子表,并更新分区主表的分区信息,其他分区并不发生改变。
用 ALTER TABLE DROP PARTITION 语句将分区删除。
6.8交换分区
采用数据字典信息交换的技术,几乎不涉及 IO 操作,因此效率非常高。仅范围分区和 LIST 分区支持交换分区,哈希分区表不支持。并且分区交换要求分区表跟交换表具有相同的结构(相同的表类型、相同的 BRANCH 选项、相同的列结构、相同的索引、相同的分布方式),分区交换但并不会校验数据,如交换表的数据是否符合分区范围等,即不能保证分区交换后的分区上的数据符合分区范围。
进行交换的两张表,如果包含加密列,对应的加密列要求加密信息完全一致。


6.9合并分区
ALTER TABLE callinfo MERGE PARTITIONS p3, p4 into partition p3_4;
仅范围分区表支持合并分区,并且合并的分区必须是范围相邻的两分区。另外,合并的分区会导致数据的重组和分区索引的重建,因此,合并分区可能会比较耗时,所需时间取决于分区数据量的大小。
6.10拆分分区
ALTER TABLE callinfo SPLIT PARTITION p3_4 AT ('2010-9-30') INTO (PARTITION p3, PARTITION p4);
仅范围分区表和 LIST 分区表支持拆分分区。拆分分区另一个重要用途是作为新增分区的补充。通过拆分分区,可以对范围分区表的开始或中间范围添加分区。另外,拆分分区会导致数据的重组和分区索引的重建,因此,拆分分区可能会比较耗时,所需时间取决于分区数据量的大小。
七、管理索引
7.1索引的作用
DM8索引能提供访问表的数据更快的路径,可以更快地定位信息。索引在逻辑上和物
理上都与相关的表的数据无关,作为无关的结构,索引需要存储空间。创建或删除一个索引,不会影响基本的表、数据库应用或其他索引。当插入、更改和删除相关的表的行时,DM8 会自动管理索引。如果删除索引,所有的应用仍继续工作,但访问以前被索引了的数据时速度可能会变慢。
7.2创建索引
7.2.1达梦支持的索引类型
1. 聚集索引:每一个普通表有且只有一个聚集索引;
2. 唯一索引:索引数据根据索引键唯一;
3. 函数索引:包含函数/表达式的预先计算的值;
4. 位图索引:对低基数的列创建位图索引;
5. 位图连接索引:针对两个或者多个表连接的位图索引,主要用于数据仓中;
6. 全文索引:在表的文本列上而建的索引。
7.2.2明确地创建索引
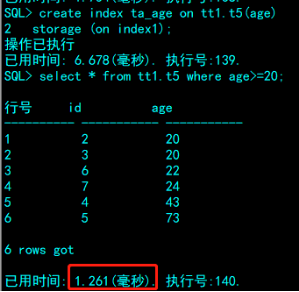
CREATE INDEX 索引名称 ON 表名(列名);
可在STORAGE语句中指定存储设置和表空间。
|
|
7.2.3创建聚集索引
CREATE CLUSTER INDEX 索引名 ON 表名(列名);
每一个普通表都有且仅有一个聚集索引,数据都通过聚集索引键排序,根据聚集索引键可以快速查询任何记录。
建表后,DM8 也可以用创建新聚集索引的方式来重建表数据,并按新的聚集索引排序。但是,新建聚集索引会重建这个表以及其所有索引,包括二级索引、函数索引,是一个代价非常大的操作。
7.2.4创建唯一索引
CREATE UNIQUE INDEX 索引名 ON 表名(列名);
用户可以在希望的列上定义 UNIQUE 完整性约束,DM8 通过自动地在唯一键上定义一个唯一索引来保证 UNIQUE 完整性约束。
7.2.5自动创建与约束相关的唯一索引
ALTER TABLE EMP ADD CONSTRAINT PK_EMP_NAME PRIMARY KEY (NAME);
DM8 通过在唯一键或主键上创建一个唯一索引来在表上实施 UNIQUE KEY 或 PRIMARYKEY 完整性约束。当启用约束时DM8自动创建该索引。
7.2.6基于函数的索引
REATE INDEX IDX ON EXAMPLE_TAB(COLUMN_A + COLUMN_B);
基于函数的索引促进了限定函数或表达式的返回值的查询,该函数或表达式的值被预先计算出来并存储在索引中。
7.2.7位图索引
CREATE BITMAP INDEX 索引名 ON 模式名.表名 (列名);
位图索引主要针对含有大量相同值的列而创建。对低基数(不同的值很少)的列创建位图索引,能够有效提高基于该列的查询效率。且执行查询语句的 where 子句中带有 AND 和 OR 谓词时,效率更加明显。
7.2.8位图链接索引
create bitmap index SALES_CUSTOMER_NAME_IDX
on SALES.SALESORDER_HEADER(SALES.CUSTOMER.PERSONID)
from SALES.CUSTOMER, SALES.SALESORDER_HEADER
where SALES.CUSTOMER.CUSTOMERID = SALES.SALESORDER_HEADER.CUSTOMERID;
位图连接索引是一种提高通过连接实现海量数据查询效率的有效方式,主要用于数据仓库环境中。位图连接索引是针对两个或者多个表的连接而建立的位图索引,同时保存了连接的位图结果。对于索引列中的每一个值,位图连接索引在索引表中保存了对应行的 ROWID。
7.2.9查看表的索引
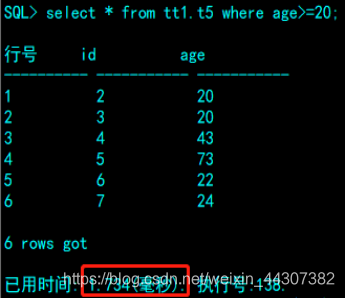
SQL> select table_name,index_name from dba_indexes where table_name='t5';
直接加表名
7.3维护索引
7.3.1重建索引

当一个表经过大量的增删改操作后,表的数据在物理文件中可能存在大量碎片,从而影响访问速度。另外,当删除表的大量数据后,若不再对表执行插入操作,索引所处的段可能占用了大量并不使用的簇,从而浪费了存储空间。可以使用重建索引来对索引的数据进行重组,使数据更加紧凑,并释放不需要的空间,从而提高访问效率和空间效率。
7.3.2删除索引
DROP INDEX [<模式名>.]<索引名>;
要想删除索引,则该索引必须包含在用户的模式中或用户必须具有 DROP ANY INDEX数据库权限。索引删除之后,该索引的段的所有簇都返回给包含它的表空间,并可用于表空间中的其他对象。
八、管理触发器
触发器(TRIGGER)定义为当某些与数据库有关的事件发生时,数据库应该采取的操作。
这些事件包括全局对象、数据库下某个模式、模式下某个基表上的 INSERT、DELETE 和
UPDATE 操作。触发器是在相关的事件发生时由服务器自动地隐式地激发。
触发器是一种用来保障参照完整性的特殊的存储过程,它维护不同表中数据间关系的有关规则。
触发器分为表触发器、事件触发器和时间触发器。表触发器是对表里数据操作引发的数
据库的触发;事件触发器是对数据库对象操作引起的数据库的触发;时间触发器是一种特殊
的事件触发器。
DIsql中,创建触发器时需用“/”结束。
8.1创建触发器
8.1.1创建表触发器
CREATE [OR REPLACE] TRIGGER [<模式名>.]触发器名[WITH ENCRYPTION]
BEFORE|AFTER|INSTEAD OF
DELETE|INSERT|UPDATE [OF 列名]
ON 表名
[FOR EACH ROW [WHEN 条件]]
BEGIN
DMSQL 程序语句
END;
CREATE TRIGGER:创建触发器
CREATE OR REPLACE TRIGGER:已存在同名的触发器,删除重建
BEFORE|AFTER:选择前激发还是后激发
INSTEAD OF:仅用于视图上的触发器,表示用触发器体内定义的操作代替原操作
DELETE|INSERT|UPDATE:触发器可以被任何 DML 命令激发,如果希望其中的
一种、两种或者三种命令能够激发该触发器,则可以指定它们之间的任意组合,两种同的命令之间用 OR 分开。如果指定了 UPDATE 命令,还可以进一步指定当表中的哪个列受到UPDATE 命令的影响时激发该触发器。
FOR EACH ROW:指定创建的触发器为元组级触发器。如果没有这样的子句,则创建触
发器为语句级触发器。INSTEAD OF 触发器固定为元组级触发器。
在触发器中可以定义变量,但必须以 DECLARE 开头。触发器也可以进行异常处理,如
果发生异常,就执行相应的异常处理程序。
8.1.2创建时间触发器
时间触发器是一种特殊的事件触发器。时间触发器的特点是用户可以定义在任何时间点、
时间区域、每隔多长时间等等的方式来激发触发器,而不是通过数据库中的某些操作包括
DML、DDL 操作等来激发,它的最小时间精度为分钟。
CREATE [OR REPLACE] TRIGGER 触发器名 WITH ENCRYPTION
AFTER TIMER ON DATABASE
{时间定义语句}
BEGIN
执行语句
END;
时间触发器实用性很强,如在凌晨(此时服务器的负荷比较轻)做一些数据的备份操作,
对数据库中表的统计信息的更新操作等类似的事情。同时也可以作为定时器通知一些用户在
未来的某些时间要做哪些事情。
- 1.3创建事件触发器
CREATE [OR REPLACE] TRIGGER [<模式名>.]<触发器名> [WITH ENCRYPTION]
BEFORE| AFTER <触发事件子句>
ON <触发对象名>[WHEN <条件表达式>]<触发器体>
BEGIN
DMSQL语句;
END;
<触发事件子句>:=<DDL 事件子句>| <系统事件子句>
<DDL 事件子句>:=<DDL 事件>{OR <DDL 事件>}
<DDL 事件>:=DDL|<<CREATE>|<ALTER>|<DROP>|<GRANT>|<REVOKE>|<TRUNCATE>
|<COMMENT>>
<系统事件子句>:=<系统事件>{OR <系统事件>}
<系统事件>:= <LOGIN> | <LOGOUT> | <SERERR>|<BACKUP DATABASE>
|<RESTORE DATABASE>|<AUDIT>|<NOAUDIT>|<TIMER>|<STARTUP>|<SHUTDOWN>
<触发对象名>:=[<模式名>.]SCHEMA|DATABASE
8.2删除触发器
DROP TRIGGER 触发器名;
8.3使触发器失效
ALTER TRIGGER 触发器名 DISABLE;
8.4使触发器有效
ALTER TRIGGER 触发器 ENABLE;
- 管理视图
视图是关系数据库系统提供给用户以多种角度观察数据库中数据的重要机制,从系统实
现的角度讲,视图是从一个或几个基表(或视图)导出的表,但它是一个虚表,即数据字典中只存放视图的定义(由视图名和查询语句组成),而不存放对应的数据,这些数据仍存放在原来的基表中。
DM 提供了一些以"V$"开头的视图来供用户了解当前服务器的使用情况。用户对动态性能视图只能进行查询操作。
视图分为简单视图,复杂视图,物化视图注:简单视图和复杂视图不占磁盘空间,物化
视图占磁盘空间。
9.1创建视图
CREATE [OR REPLACE] VIEW
[<模式名>.]<视图名>[(<列名> {,<列名>})]
AS <查询说明>
[WITH [LOCAL|CASCADED]CHECK OPTION]|[WITH READ ONLY];
<查询说明>::=<表查询> | <表连接>
<表查询>::=<子查询表达式>[ORDER BY 子句]
WITH CHECK OPTION:指明往该视图中 insert 或update 数据时,插入行或更新行的数据必须满足视图定义中<查询说明>所指定的条件。只有当视图是可更新的时候,才可以选择 WITH CHECK OPTION 项。(MPP系统不支持)
[LOCAL|CASCADED:当通过视图向基表中 insert 或 update 数据时,LOCAL|CASCADED 决定了满足 CHECK 条件的范围。指定 LOCAL,要求数据必须满足当前视图定义中<查询说明>所指定的条件;指定 CASCADED,数据必须满足当前视图,以及所有相关视图定义中<查询说明>所指定的条件。
WITH READ ONLY:指明该视图是只读视图,只可以查询。
视图也可以建立在多个基表之上。
9.2查询视图
Select () from (模式名.视图名)
Select () from dba_views where view_name=’视图名’;
9.3修改视图
一个视图依赖于其基表或视图,如果基表定义发生改变,如增删一列,或者视图的相关
权限发生改变,可能导致视图无法使用。在这种情况下,可对视图重新编译,检查视图的合
法性。
ALTER VIEW [<模式名>.]<视图名> COMPILE;
9.4更新视图数据
视图数据的更新包括插入(INSERT)、删除(DELETE)和修改(UPDATE)三类操作。由于视图是虚表,并没有实际存放数据,因此对视图的更新操作均要转换成对基表的操作。
DM 系统有
这样的规定:
1. 如果视图建在单个基表或单个可更新视图上,且该视图包含了表中的全部聚集索引
键,则该视图为可更新视图;
2. 如果视图由两个以上的基表导出时,则该视图不允许更新;
3. 如果视图列是集函数,或视图定义中的查询说明包含集合运算符、GROUP BY 子句
或 HAVING 子句,则该视图不允许更新;
4. 如果视图的基表为远程表,则该视图不允许更新;
5. 在不允许更新视图之上建立的视图也不允许更新。
9.5删除视图
DROP VIEW [IF EXISTS][<模式名>.]<视图名> [RESTRICT | CASCADE];
RESTRICT/CASCADE 方式。其中 RESTRICT 为缺省值。当设置dm.ini中的参数DROP_CASCADE_VIEW值为1时,如果在该视图上建有其它视图,必须使用 CASCADE 参数才可以删除所有建立在该视图上的视图,否则删除视图的操作不会成功;当设置 dm.ini 中的参数 DROP_CASCADE_VIEW 值为 0 时,RESTRICT 和 CASCADE方式都会成功,且只会删除当前视图,不会删除建立在该视图上的视图;
9.6物化视图
物化视图是从一个或几个基表导出的表,同视图相比,它存储了导出表的真实数据。当
基表中的数据发生变化时,物化视图所存储的数据将变得陈旧,用户可以通过手动刷新或自
动刷新来对数据进行同步。
- 管理序列
序列(sequence)是 DM 数据库中的数据库实体之一。通过使用序列,多个用户可以
产生和使用一组不重复的有序整数值。比如可以用序列来自动地生成主关键字值。序列通过提供唯一数值的顺序表来简化程序设计工作。
10.1创建序列
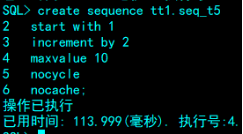
CREATE SEQUENCE [ <模式名>.] <序列名> [ <序列选项列表>];
<序列选项列表> ::= <序列选项>{<序列选项>}
<序列选项> ::=
INCREMENT BY <增量值>|(自增多少,序列数之间的间隔)
START WITH <初值>|(指定生成的抵押给序列数)
MAXVALUE <最大值>|(序列能生成的最大值)
NOMAXVALUE|
MINVALUE <最小值>|(能生产的最小值)
NOMINVALUE|
CYCLE|(是否循环)
NOCYCLE|
CACHE <缓存值>|(是否缓存)
NOCACHE|
ORDER |
NOORDER |
GLOBAL |
LOCAL
10.2使用序列
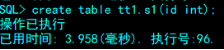
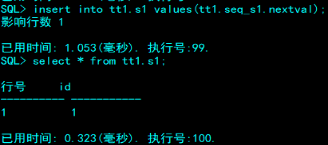
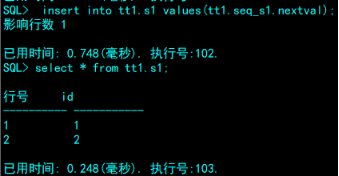
tt1.seq_s1.nextval就是一个你设置好最大最小值,增长模式的数值,可以插入在表中。
![]()
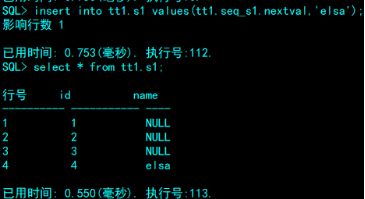
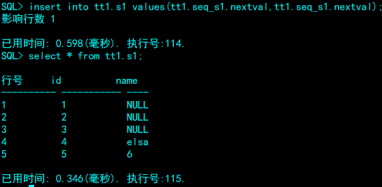
10.3修改序列
ALTER SEQUENCE [ <模式名>.] <序列名> [ <序列修改选项列表>];
10.4删除序列
DROP SEQUENCE [ <模式名>.]<序列名>;
十一、管理同义词
同义词相当于模式对象的别名,起着连接数据库模式对象和应用程序的作用。假如模式对象需要更换或者修改,则不用修改应用程序而直接修改同义词就可以了。
同义词是用来实现下列用途的数据库对象:
1. 为可以存在于本地或远程服务器上的其他数据库对象(称为基础对象)提供备用名
称;
2. 提供抽象层以免客户端应用程序对基础对象的名称或位置进行更改。
同义词的好处在于用户可能需要某些对象在不同的场合采用不用的名字,使其适合不同
人群的应用环境。例如,创建表 product,如果客户不认识这个英文词,这时可以增加同义
词,命名―产品‖,这样客户就有较直观的观念,一目了然。同义词可以替换模式下的表、视图、序列、函数、存储过程等对象。
11.1创建同义词
CREATE [OR REPLACE] [PUBLIC] SYNONYM [<模式名>.]<同义词名> FOR [<模式名>.]<
对象名>
1.<同义词名> 指被定义的同义词的名字;
2.<对象名> 指示同义词替换的对象。
公共:SQL> create public synonym ss1 for dmhr.employee;
普通:SQL> create synonym ss2 for dmhr.employee;
11.2修改同义词
SQL> create or replace synonym ss2 for dmhr.city;
11.3删除同义词
DROP [PUBLIC] SYNONYM <同义词名>
十二、管理DM自增列
自增列即标识列,它是表层面的,是列的一种属性,标识列的作用是在表(仅限单个表)
中添加行时自动生成列值;sequence序列是一种数据库对象,它相对于表来说是独立的,特别适合生成唯一键值这个任务,序列不与特定表列相关,任何SQL语句都可以使用序列的值。
12.1自增列信息
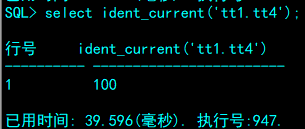
DM 支持 INT 和 BIGINT 两种数据类型的自增列,并提供以下函数查看表上自增列当前值、种子和增量等信息:
1. IDENT_CURRENT:获得表上自增列的当前值;
2. IDENT_SEED:获得表上自增列的种子信息;
3. IDENT_INCR:获得表上自增列的增量信息。
SQL> select ident_current('tt1.tt4');
SQL> select ident_seed('tt1.tt4');
SQL> select ident_incr('tt1.tt4');
12.2 SET IDENTITY_INSERT属性
设置是否允许将显式值插入表的自增列中。
SET IDENTITY_INSERT [<模式名>.]<表名> ON | OFF;
十三、管理外部链接
13.1创建外部链接
CREATE [OR REPLACE] [PUBLIC] LINK <外部链接名> CONNECT ['<连接库类型>'] WITH <
登录名> IDENTIFIED BY <登录口令> USING '<外部连接串>';
<连接库类型> ::= DAMENG | ORACLE | ODBC
<DAMENG 外部链接串>支持三种格式,分别对应目标节点在 dmmal.ini 中的配置
项,具体如下:
a.<实例 IP 地址>/<实例端口号> 对应 mal_inst_host/mal_inst_port
b.<MAL IP 地址>/<MAL 端口号> 对应 mal_host/mal_port
c.实例名 对应 mal_inst_name
<ORACLE外部链接串>可以使用配置的网络服务名tsn_name(网络服务名需要配置),或者连接描述符 description(连接描述符是网络连接目标特殊格式的描述,它包括网络协议、主库 IP 地址、端口号和服务名),或者<IP 地址>/<服务名>;
<ODBC 外部链接串>DSN 需要用户手动配置。
13.2删除外部链接
DROP [PUBLIC] LINK [<模式名>.]<外部链接名>;

