
- 1MySQL 安装 audit 日志审计插件_audit-plugin-mysql
- 22021-03-07_wxid微信号在线转换
- 32024年8月PMP考试时间安排!请提前准备!
- 4天池零基础入门NLP竞赛实战:Task3 基于机器学习的文本分类_基于机器学习的文本分类-天池
- 5【Python】怎么在pip下载的时候设置镜像?(常见的清华镜像、阿里云镜像以及中科大镜像)_pip镜像
- 6v-for中为什么要用key?有什么作用,为什么不能以index作为key?_遍历数组的时候 为什么要加key属性,如果使用数组的index会发生什么问题
- 7商业源码_商业聚集代码
- 8AI+翻译 AI智能体平台扣子coze开发搭建
- 9【机器学习】基于YOLOv10实现你的第一个视觉AI大模型
- 10Java刷题总结——贪心算法篇_贪心算法入门题java
Phoenix二级索引_phoenix 二级索引同步
赞
踩
1. 为什么需要用二级索引?
对于HBase而言,如果想精确地定位到某行记录,唯一的办法是通过rowkey来查询。如果不通过rowkey来查找数据,就必须逐行地比较每一列的值,即全表扫瞄。对于较大的表,全表扫描的代价是不可接受的。但是,很多情况下,需要从多个角度查询数据。例如,在定位某个人的时候,可以通过姓名、身份证号、学籍号等不同的角度来查询,要想把这么多角度的数据都放到rowkey中几乎不可能(业务的灵活性不允许,对rowkey长度的要求也不允许)。所以,需要secondary index(二级索引)来完成这件事。secondary index的原理很简单,但是如果自己维护的话则会麻烦一些。现在,Phoenix已经提供了对HBase secondary index的支持。
2. Phoenix Global Indexing And Local Indexing
2.1 Global Indexing
Global indexing,全局索引,适用于读多写少的业务场景。使用Global indexing在写数据的时候开销很大,因为所有对数据表的更新操作(DELETE, UPSERT VALUES and UPSERT SELECT),都会引起索引表的更新,而索引表是分布在不同的数据节点上的,跨节点的数据传输带来了较大的性能消耗。在读数据的时候Phoenix会选择索引表来降低查询消耗的时间。在默认情况下如果想查询的字段不是索引字段的话索引表不会被使用,也就是说不会带来查询速度的提升。
2.2 Local Indexing
Local indexing,本地索引,适用于写操作频繁以及空间受限制的场景。与Global indexing一样,Phoenix会自动判定在进行查询的时候是否使用索引。使用Local indexing时,索引数据和数据表的数据存放在相同的服务器中,这样避免了在写操作的时候往不同服务器的索引表中写索引带来的额外开销。使用Local indexing的时候即使查询的字段不是索引字段索引表也会被使用,这会带来查询速度的提升,这点跟Global indexing不同。对于Local Indexing,一个数据表的所有索引数据都存储在一个单一的独立的可共享的表中。
3. Immutable index And Mutable index
3.1 immutable index
immutable index,不可变索引,适用于数据只增加不更新并且按照时间先后顺序存储(time-series data)的场景,如保存日志数据或者事件数据等。不可变索引的存储方式是write one,append only。当在Phoenix使用create table语句时指定IMMUTABLE_ROWS = true表示该表上创建的索引将被设置为不可变索引。Phoenix默认情况下如果在create table时不指定IMMUTABLE_ROW = true时,表示该表为mutable。不可变索引分为Global immutable index和Local immutable index两种。
3.2 mutable index
mutable index,可变索引,适用于数据有增删改的场景。Phoenix默认情况创建的索引都是可变索引,除非在create table的时候显式地指定IMMUTABLE_ROWS = true。可变索引同样分为Global immutable index和Local immutable index两种。
4.配置HBase支持Phoenix二级索引
如果要启用phoenix的二级索引功能,需要对HMaster以及每一个RegionServer上的hbase-site.xml进行额外的配置。首先,在每一个RegionServer的hbase-site.xml里加入如下属性:
<property>
<name>hbase.regionserver.wal.codec</name>
<value>org.apache.hadoop.hbase.regionserver.wal.IndexedWALEditCodec</value>
</property>
<property>
<name>hbase.region.server.rpc.scheduler.factory.class</name>
<value>org.apache.hadoop.hbase.ipc.PhoenixRpcSchedulerFactory</value>
<description>Factory to create the Phoenix RPC Scheduler that uses separate queues for index and metadata updates</description>
</property>
<property>
<name>hbase.rpc.controllerfactory.class</name>
<value>org.apache.hadoop.hbase.ipc.controller.ServerRpcControllerFactory</value>
<description>Factory to create the Phoenix RPC Scheduler that uses separate queues for index and metadata updates</description>
</property>
<property>
<name>hbase.coprocessor.regionserver.classes</name>
<value>org.apache.hadoop.hbase.regionserver.LocalIndexMerger</value>
</property>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
如果没有在每个regionserver上的hbase-site.xml里面配置如上属性,那么使用create index语句创建二级索引将会抛出如下异常:
Error: ERROR 1029 (42Y88): Mutable secondary indexes must have the hbase.regionserver.wal.codec property set to org.apache.hadoop.hbase.regionserver.wal.IndexedWALEditCodec in the hbase-sites.xml of every region server tableName=TEST_INDEXES (state=42Y88,code=1029)- 1
然后在每一个master的hbase-site.xml里加入如下属性:
<property>
<name>hbase.master.loadbalancer.class</name>
<value>org.apache.phoenix.hbase.index.balancer.IndexLoadBalancer</value>
</property>
<property>
<name>hbase.coprocessor.master.classes</name>
<value>org.apache.phoenix.hbase.index.master.IndexMasterObserver</value>
</property>- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
完成上述修改后重启hbase集群使配置生效。
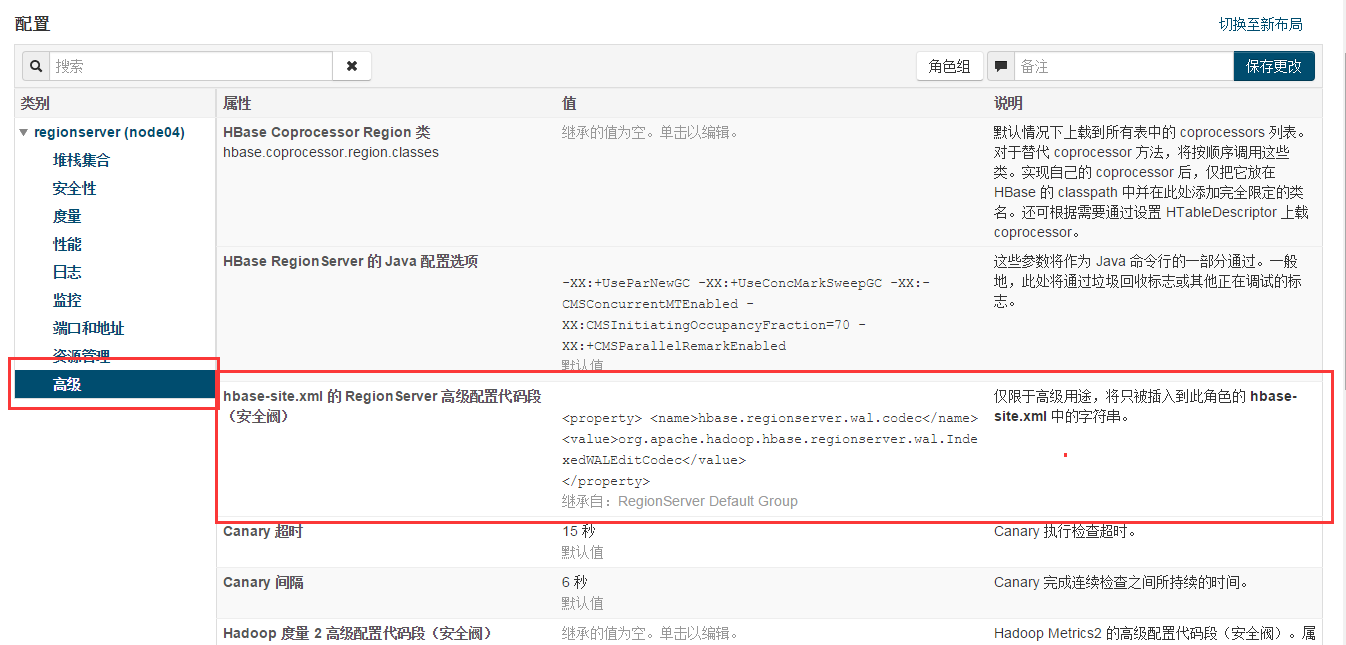
【特别注意】
如果使用的是CDH部署的HBase,需要在Cloudera Manager管理页面里面的HBase“配置”页面里的hbase-site.xml项增加上述配置,并在管理页面里面重启HBase才能使得配置生效。
5. 测试案例
5.1 测试案例1
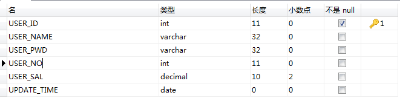
HBase 1000w数据
users_test表
【Global Indexing】
在没有创建二级索引之前查询特定USER_NAME的用户信息耗时大约16s左右。

在USER_NAME列上面创建二级索引:
create index USERS_TEST_IDX0 on "users_test ("info".USER_NAME)- 1
创建二级索引后查询特定USER_NAME的用户名称耗时为ms级别

【说明】 可以通过explain命令来查看查询是否用到二级索引

【注意】 如果在select条件里面选择了其他的列,如USER_NO,因为该列没有存在于索引表,因此查询不会走索引表。

如果想在select USER_NAME,USER_NO查询仍然走索引,必须创建如下索引:
- 方式一,采取INCLUDE(index cover,即索引覆盖)的方式:
create index USERS_TEST_IDX1 on "users_test"("info".USER_NAME) INCLUDE("info".USER_NO)- 1
索引覆盖其实就是将INCLUDE里面包含的列都存储到索引表里面,当检索的时候就可以从索引表里直接带回这些列值。要特别注意索引列和索引覆盖列的区别,索引列在索引表里面是以rowkey的形式存在,多个索引列以某个约定的字节分割然后一起存储在rowkey里面,也就是说当索引列有很多个的时候,rowkey的长度也相应会变长,大小取决于索引列值的大小。而索引覆盖列,是存储在索引表的列族中。
- 方式二,采取多列索引:
create index USERS_TEST_IDX2 on "users_test"("info".USER_NAME, "info".USER_NO) - 1
【说明】
多列索引在满足前缀式的情况才会用到,如创建了A,B,C顺序的多列索引,当在where条件指定A条件、A B条件或者A B C条件均会走索引,但是 B C条件则无法走索引。
【Local Indexing】
在users_test表创建local index类型的二级索引:
create local index USERS_TEST_LOCAL_IDX ON "users_test"("info".USER_NAME)- 1
与Global Indexing不同的是,如果select子句里面带有除了索引列(USER_NAME)以外的列,仍然可以走索引表。


【说明】
创建Local Indexing时候指定的索引名称会与实际创建在Hbase里面的表名称不一致,这应该是Phoenix做了映射的关系,而且对于同一个Hbase里面的table创建多个Local Indexing,索引表在Hbse list命令查询的时候也只有一个。
5.2 测试案例2
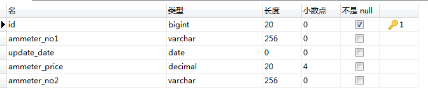
HBase 1e数据
ammeter_test表

【Global Indexing】
create index AMMETER_TEST_IDX
on AMMETER_TEST ("info"."ammeter_no1", "info"."ammeter_no2") include("info"."ammeter_price");- 1
- 2
(1) 条件查询包含rowkey
> explain select * from AMMETER_TEST where "info"."ammeter_no1" = '11000000005281' AND "ammeter_no2" = '11000000001004' and ROW = '11000002310462'
> select * from AMMETER_TEST where "info"."ammeter_no1" = '11000000005281' AND "ammeter_no2" = '11000000001004' and ROW = '11000002310462'- 1
- 2


(2) 条件查询不包含rowkey但满足二级索引查找条件
> explain select ROW,"ammeter_price" from AMMETER_TEST where "info"."ammeter_no1" = '11000000005281' and "ammeter_no2" = '11000000001004'
> select ROW,"ammeter_price" from AMMETER_TEST where "info"."ammeter_no1" = '11000000005281' and "ammeter_no2" = '11000000001004' LIMIT 5- 1
- 2


【分析】
- 对于包含rowkey的条件查询,Phoenix会启用服务器端过滤器快速筛选匹配的行并返回,亿级数据也能达到毫秒级别响应。
- 对于没有包含rowkey的条件查询,如果条件满足Phoenix二级索引查找,Phoenix会查二级索引表并快速返回记录。
6. 同步创建索引与异步创建索引
前面所讲的创建索引为同步创建索引,当执行create index的时候,索引表会直接与源数据表进行同步。但是,有时候我们的源表数据量很大,同步创建索引会抛出异常。异常信息大致如下所示:
15/12/11 14:20:08 WARN client.ScannerCallable: Ignore, probably already closed
org.apache.hadoop.hbase.UnknownScannerException: org.apache.hadoop.hbase.UnknownScannerException: Name: 37, already closed?
at org.apache.hadoop.hbase.regionserver.RSRpcServices.scan(RSRpcServices.java:2092)
at org.apache.hadoop.hbase.protobuf.generated.ClientProtos$ClientService$2.callBlockingMethod(ClientProtos.java:31443)
at org.apache.hadoop.hbase.ipc.RpcServer.call(RpcServer.java:2035)
at org.apache.hadoop.hbase.ipc.CallRunner.run(CallRunner.java:107)
at org.apache.hadoop.hbase.ipc.RpcExecutor.consumerLoop(RpcExecutor.java:130)
at org.apache.hadoop.hbase.ipc.RpcExecutor$1.run(RpcExecutor.java:107)
at java.lang.Thread.run(Thread.java:745)
at sun.reflect.GeneratedConstructorAccessor13.newInstance(Unknown Source)
at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45)
at java.lang.reflect.Constructor.newInstance(Constructor.java:526)
at org.apache.hadoop.ipc.RemoteException.instantiateException(RemoteException.java:106)
at org.apache.hadoop.ipc.RemoteException.unwrapRemoteException(RemoteException.java:95)
at org.apache.hadoop.hbase.protobuf.ProtobufUtil.getRemoteException(ProtobufUtil.java:313)
at org.apache.hadoop.hbase.client.ScannerCallable.close(ScannerCallable.java:329)
at org.apache.hadoop.hbase.client.ScannerCallable.call(ScannerCallable.java:184)
at org.apache.hadoop.hbase.client.ScannerCallableWithReplicas.call(ScannerCallableWithReplicas.java:136)
at org.apache.hadoop.hbase.client.ScannerCallableWithReplicas.call(ScannerCallableWithReplicas.java:56)
at org.apache.hadoop.hbase.client.RpcRetryingCaller.callWithoutRetries(RpcRetryingCaller.java:200)
at org.apache.hadoop.hbase.client.ClientScanner.call(ClientScanner.java:288)
at org.apache.hadoop.hbase.client.ClientScanner.close(ClientScanner.java:507)
at org.apache.phoenix.iterate.ScanningResultIterator.close(ScanningResultIterator.java:49)
at org.apache.phoenix.iterate.TableResultIterator.close(TableResultIterator.java:95)
at org.apache.phoenix.jdbc.PhoenixResultSet.close(PhoenixResultSet.java:162)
at org.apache.phoenix.compile.UpsertCompiler.upsertSelect(UpsertCompiler.java:199)
at org.apache.phoenix.compile.UpsertCompiler.access$000(UpsertCompiler.java:114)
at org.apache.phoenix.compile.UpsertCompiler$UpsertingParallelIteratorFactory.mutate(UpsertCompiler.java:229)
at org.apache.phoenix.compile.MutatingParallelIteratorFactory.newIterator(MutatingParallelIteratorFactory.java:62)
at org.apache.phoenix.iterate.ParallelIterators$1.call(ParallelIterators.java:109)
at org.apache.phoenix.iterate.ParallelIterators$1.call(ParallelIterators.java:100)
at java.util.concurrent.FutureTask.run(FutureTask.java:262)
at org.apache.phoenix.job.JobManager$InstrumentedJobFutureTask.run(JobManager.java:183)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1145)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:615)
at java.lang.Thread.run(Thread.java:745)
Caused by: org.apache.hadoop.hbase.ipc.RemoteWithExtrasException(org.apache.hadoop.hbase.UnknownScannerException): org.apache.hadoop.hbase.UnknownScannerException: Name: 37, already closed?
at org.apache.hadoop.hbase.regionserver.RSRpcServices.scan(RSRpcServices.java:2092)
at org.apache.hadoop.hbase.protobuf.generated.ClientProtos$ClientService$2.callBlockingMethod(ClientProtos.java:31443)
at org.apache.hadoop.hbase.ipc.RpcServer.call(RpcServer.java:2035)
at org.apache.hadoop.hbase.ipc.CallRunner.run(CallRunner.java:107)
at org.apache.hadoop.hbase.ipc.RpcExecutor.consumerLoop(RpcExecutor.java:130)
at org.apache.hadoop.hbase.ipc.RpcExecutor$1.run(RpcExecutor.java:107)
at java.lang.Thread.run(Thread.java:745)
at org.apache.hadoop.hbase.ipc.RpcClientImpl.call(RpcClientImpl.java:1199)
at org.apache.hadoop.hbase.ipc.AbstractRpcClient.callBlockingMethod(AbstractRpcClient.java:216)
at org.apache.hadoop.hbase.ipc.AbstractRpcClient$BlockingRpcChannelImplementation.callBlockingMethod(AbstractRpcClient.java:300)
at org.apache.hadoop.hbase.protobuf.generated.ClientProtos$ClientService$BlockingStub.scan(ClientProtos.java:31889)
at org.apache.hadoop.hbase.client.ScannerCallable.close(ScannerCallable.java:327)
... 20 more- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
这个时候,我们可以采用异步创建索引,方式如下:
CREATE INDEX async_index ON my_schema.my_table (v) ASYNC- 1
通过create index的时候指定 ASYNC 关键字来指定异步创建索引。执行这个命令之后并不会引起索引表与源表的直接同步。这个时候查询并不会使用这个索引表。那么索引数据的导入还需要采用phoenix提供的索引同步工具类 IndexTool , 这是一个mapreduce工具类,使用方式如下:
${HBASE_HOME}/bin/hbase org.apache.phoenix.mapreduce.index.IndexTool
--schema MY_SCHEMA --data-table MY_TABLE --index-table ASYNC_IDX
--output-path ASYNC_IDX_HFILES- 1
- 2
- 3
当mapreduce任务执行结束,这个索引表才会变成可用。
7. 参考
(1) 可变索引与不可变索引
(3) Local Indexing
(4) 配置二级索引及测试
(5) Phoenix官网文档


