
- 1深度学习 - 张量的广播机制和复杂运算
- 2各个版本的tensorflow和python, cuda,cudnn对应的版本_tensorflow历史版本
- 3git分支打tag_gitlab 给分支设置 tag操作
- 4base64 前端显示 data:image/jpg;base64_base64 jpg
- 5AI大模型应用开发实践:3.使用 tiktoken 计算 token 数量_tiktoken 统计token
- 6CNN中的卷积的作用及原理通俗理解_添加卷积cnn的作用是什么?
- 7使用git将本地代码上传到gitee远程仓库_git上传本地代码到指定的仓库
- 8Python の TypeError 及解决方案(一)_typeerror: argument of type 'int' is not iterable
- 9【软件安装】结合树莓派4B(4G)和Ubuntu20.04的GitLab服务器搭建和使用_烧录ubuntu20系统树莓派需要更新的软件
- 10OpenCV 教程_machine learning classes
【论文笔记】UniVision: A Unified Framework for Vision-Centric 3D Perception
赞
踩
原文链接:https://arxiv.org/pdf/2401.06994.pdf
1. 引言
目前,同时处理基于图像的3D检测任务和占用预测任务还未得到充分探索。3D占用预测需要细粒度信息,多使用体素表达;而3D检测多使用BEV表达,因其更加高效。
本文提出UniVision,同时处理3D检测与占用预测任务的统一网络。网络结构为合-分-合,先使用共享的网络提取多视图图像特征,并使用新的视图变换模块,组合了基于深度的提升和基于查询的采样方法,以进行2D-3D视图变换。然后,网络分为两个分支,分别进行体素和BEV特征提取。然后,使用自适应特征交互使特征彼此增强,并输入任务头。此外,还提出联合的占用-检测数据增广方式,以及多任务高效训练策略。
3. 方法
3.1 整体结构
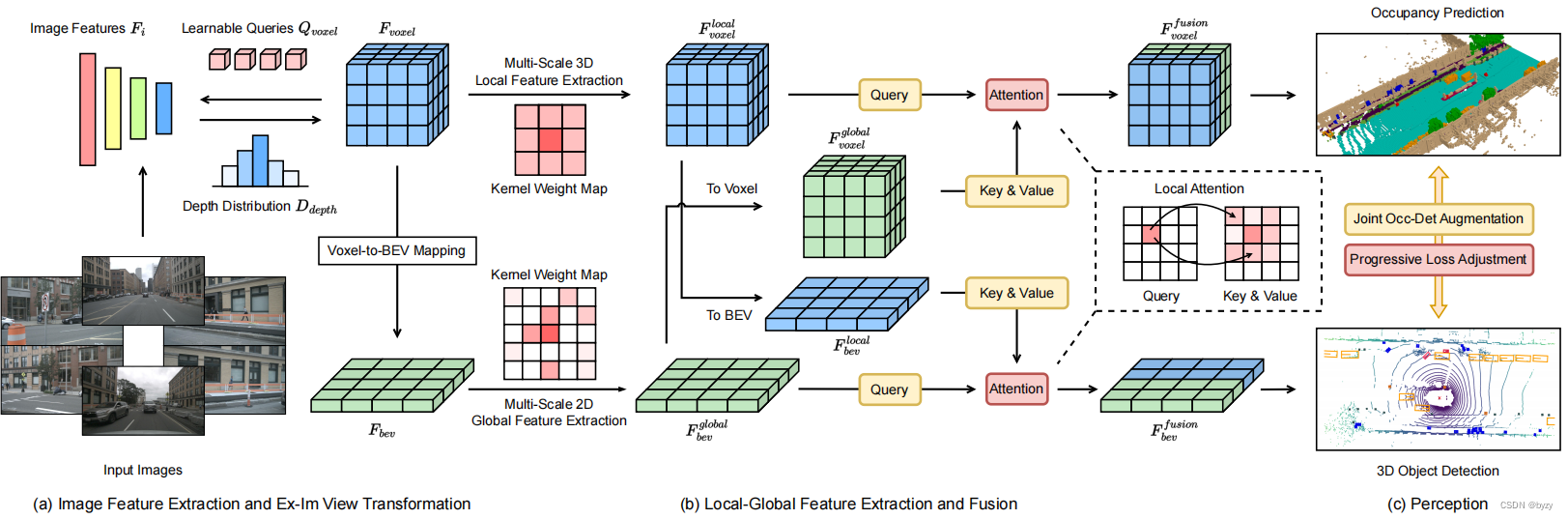
如上图所示为本文模型总体结构。给定
N
N
N视图图像
{
I
i
∣
I
i
∈
R
W
I
×
H
I
×
3
}
,
i
∈
{
1
,
⋯
,
N
}
\{I^i|I^i\in\mathbb{R}^{W_I\times H_I\times 3}\},i\in\{1,\cdots,N\}
{Ii∣Ii∈RWI×HI×3},i∈{1,⋯,N},首先使用特征提取网络提取特征
F
i
m
g
F_{img}
Fimg。然后,通过显式-隐式(Ex-Im)视图变换模块,联合使用深度指导的显式特征提升以及查询指导的隐式特征采样,将图像特征转化为体素特征
F
v
o
x
e
l
F_{voxel}
Fvoxel。然后,输入局部-全局特征提取和融合模块提取局部上下文感知的体素特征和全局上下文感知的BEV特征,并使用跨表达特征交互模块进行体素特征与BEV特征的信息交换,输入到不同的任务头中。训练中,还会使用联合占用-检测(Occ-Det)数据增广和渐进损失权重调整策略,以高效训练UniVision。
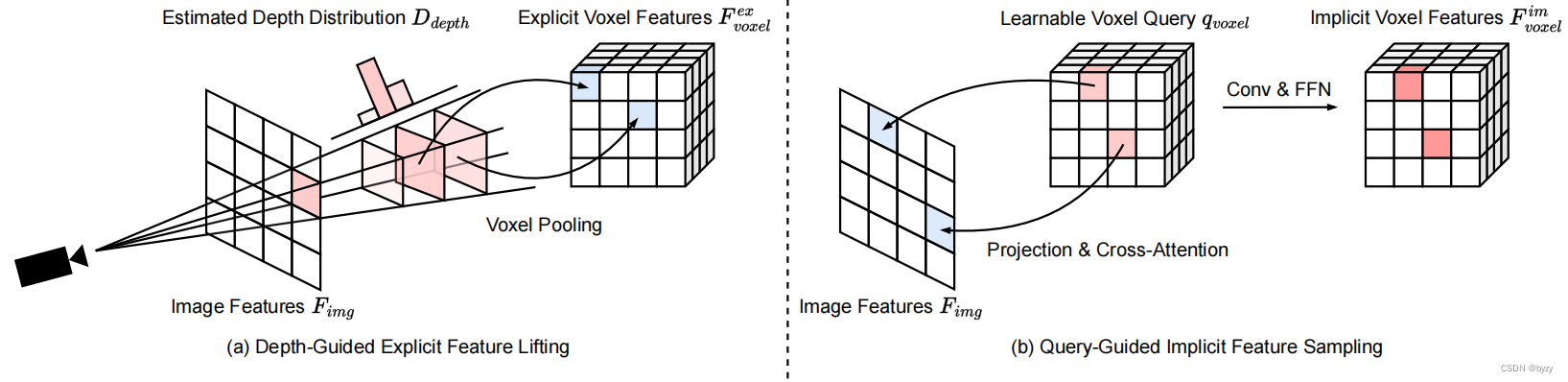
3.2 Ex-Im视图变换
深度指导的显式特征提升:根据LSS,使用基于像素深度分布
D
d
e
p
t
h
∈
R
D
×
H
×
W
D_{depth}\in\mathbb{R}^{D\times H\times W}
Ddepth∈RD×H×W与图像特征
F
i
m
g
∈
R
C
×
H
×
W
F_{img}\in\mathbb{R}^{C\times H\times W}
Fimg∈RC×H×W的体素池化操作:
F
v
o
x
e
l
e
x
=
VoxelPooling
(
D
d
e
p
t
h
,
F
i
m
g
)
F_{voxel}^{ex}=\text{VoxelPooling}(D_{depth},F_{img})
Fvoxelex=VoxelPooling(Ddepth,Fimg)
其中 F v o x e l e x F_{voxel}^{ex} Fvoxelex称为显式体素特征。
查询指导的隐式特征采样:由于显式体素特征的精度与深度分布的估计精度高度相关,且LSS生成的点云是不均匀的,本文进一步使用查询指导的特征采样来补偿。定义可学习体素查询
q
v
o
x
e
l
∈
R
C
×
X
×
Y
×
Z
q_{voxel}\in\mathbb{R}^{C\times X\times Y\times Z}
qvoxel∈RC×X×Y×Z,使用3D Transformer从图像采样特征。对每个体素查询,通过校准矩阵
P
P
P将其中心
c
c
c投影到图像平面得到参考点
p
p
p,后接
N
N
N个由可变形交叉注意力(DCA)、3D卷积(Conv)和前馈网络(FFN)组成的Transformer块:
p
=
P
×
c
q
i
+
1
=
F
F
N
(
C
o
n
v
(
D
C
A
(
q
i
,
p
,
F
i
m
g
)
)
)
F
v
o
x
e
l
i
m
=
q
N
p=P\times c\\ q^{i+1}=FFN(Conv(DCA(q^i,p,F_{img})))\\ F_{voxel}^{im}=q^N
p=P×cqi+1=FFN(Conv(DCA(qi,p,Fimg)))Fvoxelim=qN
体素查询在3D空间中均匀分布,且学习到了所有训练样本的统计信息,这与LSS的深度先验信息独立。因此显式体素特征和隐式体素特征互补,拼接后作为视图变换模块的输出。
F
v
o
x
e
l
=
F
v
o
x
e
l
e
x
∣
∣
F
v
o
x
e
l
i
m
F_{voxel}=F_{voxel}^{ex}||F_{voxel}^{im}
Fvoxel=Fvoxelex∣∣Fvoxelim
Ex-Im视图变换模块如下图所示。
3.3 局部-全局特征提取和融合
给定体素特征
F
v
o
x
e
l
∈
R
C
×
X
×
Y
×
Z
F_{voxel}\in\mathbb{R}^{C\times X\times Y\times Z}
Fvoxel∈RC×X×Y×Z输入,首先堆叠
Z
Z
Z轴特征并使用卷积减小通道数,得到BEV特征
F
b
e
v
∈
R
C
×
X
×
Y
F_{bev}\in\mathbb{R}^{C\times X\times Y}
Fbev∈RC×X×Y:
F
b
e
v
=
C
o
n
v
(
S
t
a
c
k
(
F
v
o
x
e
l
,
d
i
m
=
Z
)
)
F_{bev}=Conv(Stack(F_{voxel},dim=Z))
Fbev=Conv(Stack(Fvoxel,dim=Z))
然后,模型分为两个并行分支,进行特征提取和加强。
局部特征提取:对 F v o x e l F_{voxel} Fvoxel,使用由3D卷积组成的局部特征提取分支提取各空间位置的局部特征。将ResNet扩展为ResNet3D,以提取多尺度体素特征 { F v o x e l i ∣ F v o x e l i ∈ R ( 2 i C ) × X 2 i × Y 2 i × Z 2 i } \{F^i_{voxel}|F^i_{voxel}\in\mathbb{R}^{(2^iC)\times \frac X {2^i} \times \frac Y {2^i}\times \frac Z {2^i}}\} {Fvoxeli∣Fvoxeli∈R(2iC)×2iX×2iY×2iZ},然后使用SECOND中的FPN结构,将多尺度体素特征融合为 F v o x e l l o c a l ∈ R C × X × Y × Z F_{voxel}^{local}\in\mathbb{R}^{C\times X\times Y\times Z} Fvoxellocal∈RC×X×Y×Z
全局特征提取:BEV特征 F b e v F_{bev} Fbev保留了物体级别的信息,计算高效。本文提出带全局感受野的全局特征提取分支,使用由可变形卷积v3(DCNv3)组成的网络动态聚合全局信息,得到多尺度BEV特征 { F b e v i ∣ F b e v i ∈ R ( 2 i C ) × X 2 i × Y 2 i } \{F_{bev}^i|F_{bev}^i\in\mathbb{R}^{(2^iC)\times \frac X {2^i} \times \frac Y {2^i}}\} {Fbevi∣Fbevi∈R(2iC)×2iX×2iY}。同样输入SECOND FPN结构,得到融合的BEV特征 F b e v g l o b a l ∈ R C × X × Y F_{bev}^{global}\in\mathbb{R}^{C\times X\times Y} Fbevglobal∈RC×X×Y。
跨表达特征交互:进行两表达的自适应信息交换,以进一步加强特征。首先,通过
Z
Z
Z轴复制将BEV特征转化为体素特征,通过求和将体素特征转化为BEV特征:
F
v
o
x
e
l
g
l
o
b
a
l
=
r
e
p
e
a
t
(
F
b
e
v
g
l
o
b
a
l
,
d
i
m
=
Z
)
F
b
e
v
l
o
c
a
l
=
a
d
d
(
F
v
o
x
e
l
l
o
c
a
l
,
d
i
m
=
Z
)
F_{voxel}^{global}=repeat(F_{bev}^{global},dim=Z)\\ F_{bev}^{local}=add(F_{voxel}^{local},dim=Z)
Fvoxelglobal=repeat(Fbevglobal,dim=Z)Fbevlocal=add(Fvoxellocal,dim=Z)
对于体素表达,将
F
v
o
x
e
l
l
o
c
a
l
F_{voxel}^{local}
Fvoxellocal作为查询,
F
v
o
x
e
l
g
l
o
b
a
l
F_{voxel}^{global}
Fvoxelglobal作为键与值。将自注意力中的邻域注意力Transformer扩展为交叉注意力,以进行局部感受野
Δ
p
\Delta p
Δp内的信息聚合。对BEV特征,使用相似的方式:
F
v
o
x
e
l
f
u
s
i
o
n
=
A
t
t
n
(
q
=
F
v
o
x
e
l
l
o
c
a
l
,
k
&
v
=
F
v
o
x
e
l
g
l
o
b
a
l
,
Δ
p
)
F
b
e
v
f
u
s
i
o
n
=
A
t
t
n
(
q
=
F
b
e
v
g
l
o
b
a
l
,
k
&
v
=
F
b
e
v
l
o
c
a
l
,
Δ
p
)
F_{voxel}^{fusion}=Attn(q=F_{voxel}^{local},k\&v=F_{voxel}^{global},\Delta p)\\ F_{bev}^{fusion}=Attn(q=F_{bev}^{global},k\&v=F_{bev}^{local},\Delta p)
Fvoxelfusion=Attn(q=Fvoxellocal,k&v=Fvoxelglobal,Δp)Fbevfusion=Attn(q=Fbevglobal,k&v=Fbevlocal,Δp)
其中 Δ p = 3 × 3 \Delta p=3\times3 Δp=3×3或 3 × 3 × 3 3\times3\times3 3×3×3。
3.4 头部与损失
对于占用任务,使用两层MLP将特征通道数转化为占用类别数;损失与OpenOccupancy相同( L o c c L_{occ} Locc),包含交叉熵损失、lovasz softmax损失、几何亲和性损失与语义亲和性损失。
对于检测任务,使用基于中心的头部和损失函数( L d e t L_{det} Ldet),后者包含分类损失与回归损失。
此外,还加入了与BEVDepth相同的深度损失( L i m g L_{img} Limg)。
渐进损失权重调整策略:直接结合上述损失会导致训练失败,网络不能收敛。

为解决这一问题,本文为占用损失和检测损失添加控制参数
δ
\delta
δ,以调整损失权重。一开始,
δ
=
V
min
\delta=V_{\min}
δ=Vmin很小,然后在
N
N
N个epoch内逐渐增大到
V
max
V_{\max}
Vmax,如上图所示:
L
=
L
i
m
g
+
δ
L
d
e
t
+
δ
L
o
c
c
δ
=
max
(
V
min
,
min
(
V
max
,
i
N
⋅
V
max
)
)
L=L_{img}+\delta L_{det}+\delta L_{occ}\\ \delta=\max(V_{\min},\min(V_{\max},\frac i N\cdot V_{\max}))
L=Limg+δLdet+δLoccδ=max(Vmin,min(Vmax,Ni⋅Vmax))
其中 i i i表示当前的训练epoch数。这样,优化过程在早期关注图像级别的信息(深度)以生成合理的体素表达,然后关注后续的感知任务。
3.5 联合Occ-Det空间数据增广
3D检测任务中,空间层面的数据增广作为图像级别数据增广的补充,在提高模型性能方面同样有效。但对占用任务来说,使用空间层面的增广较为困难,如对离散占用标签进行随机缩放与旋转会导致难以确定结果的标签。因此,目前的方法仅使用简单的空间层面增广方式,如随机翻转。
本文提出联合Occ-Det空间数据增广,可同时对两个任务进行。本文按照BEVDet的增广方式,并通过插值与采样转化体素特征,进行体素数据增广。
具体来说,首先采样空间数据增广并计算相应的3D变换矩阵
M
a
u
g
M_{aug}
Maug。对于占用标签
G
o
c
c
∈
R
X
×
Y
×
Z
G_{occ}\in\mathbb{R}^{X\times Y\times Z}
Gocc∈RX×Y×Z和其体素索引
I
o
r
g
∈
R
X
×
Y
×
Z
×
3
I_{org}\in\mathbb{R}^{X\times Y\times Z\times3}
Iorg∈RX×Y×Z×3,计算3D坐标
C
o
r
g
∈
R
X
×
Y
×
Z
×
3
C_{org}\in\mathbb{R}^{X\times Y\times Z\times3}
Corg∈RX×Y×Z×3,并进一步得到增广体素索引
I
a
u
g
I_{aug}
Iaug:
C
o
r
g
=
P
i
−
c
×
I
o
r
g
I
a
u
g
=
P
c
−
i
×
M
a
u
g
×
C
o
r
g
C_{org}=P_{i-c}\times I_{org}\\ I_{aug}=P_{c-i}\times M_{aug}\times C_{org}
Corg=Pi−c×IorgIaug=Pc−i×Maug×Corg
其中
P
i
−
c
P_{i-c}
Pi−c和
P
c
−
i
P_{c-i}
Pc−i为体素索引与空间坐标的变换矩阵。然后,使用体素索引
I
a
u
g
I_{aug}
Iaug对体素特征
F
a
u
g
F_{aug}
Faug采样:
F
o
r
g
=
S
(
F
a
u
g
,
I
o
r
g
)
F_{org}=S(F_{aug},I_{org})
Forg=S(Faug,Iorg)
其中
S
S
S表示采样,
F
o
r
g
F_{org}
Forg为采样的体素特征,与原始占用标签
G
o
c
c
G_{occ}
Gocc对应,可以进行损失计算。对于采样时位于范围外的位置,使用二值掩膜
M
o
c
c
∈
{
0
,
1
}
X
×
Y
×
Z
M_{occ}\in\{0,1\}^{X\times Y\times Z}
Mocc∈{0,1}X×Y×Z忽视之:
L
o
c
c
=
f
(
G
o
c
c
,
F
o
r
g
)
×
M
o
c
c
L_{occ}=f(G_{occ},F_{org})\times M_{occ}
Locc=f(Gocc,Forg)×Mocc
其中
f
f
f为损失函数。Occ-Det增广如下所示。

4. 实验与讨论
4.2 实验设置
OpenOccupancy:由于GT占用标签分辨率高,非常占用空间,本文在训练时下采样到一半分辨率;测试时将输出上采样到原始分辨率。
4.3 结果
nuScenes激光雷达分割:UniVision大幅超过视觉SOTA方法OccFormer和一些激光雷达方法。
nuScenes 3D目标检测:UniVision能超过其余方法的性能;扩大模型后并使用时序输入后,能在输入分辨率低和不使用CBGS的情况下,大幅超过多帧SOTA检测器。
OpenOccupancy:UniVision能超过基于视觉的占用方法,以及一些基于激光雷达的方法。
Occ3D:UniVision能在不使用预训练权重和多帧输入的情况下达到比其余方法更高的性能。
4.4 消融研究
检测任务中组件的有效性:加入基于BEV的全局特征提取分支、基于体素的占用任务作为辅助任务、以及跨表达交互后,检测性能均有提升。
占用任务中组件的有效性:加入基于体素的局部特征提取分支、基于BEV的检测任务作为辅助任务、以及跨表达交互后,占用性能均匀提升。
**检测任务与占用任务如何互相影响?**对检测任务,占用监督能提高mAP与mATE指标,这表明逐体素语义学习能提高检测器对物体几何(中心和尺度)的感知。对占用任务,检测监督能极大提高前景物体处的性能。
联合Occ-Det增广、Ex-Im视图变换和渐进损失权重调整的有效性:实验表明,空间增广和视图变换模块对两个任务均有性能提升;去掉损失权重调整策略,网络不能收敛,性能很低。

