
- 1梅克尔工作室-鸿蒙app相关语法鸿蒙app前后端流程实现:登录验证,注册信息,前端获取数据反馈,Django后端连接_鸿蒙 语法
- 2DatawhaleChina -任务三 TF-IDF原理+互信息_互信息的缺点
- 3CUDA安装失败-Nsight compute安装失败-如何测试CUDA是否安装成功?Reason: VS** was not found
- 4caffe深度学习【十】编译错误:In file included from ./include/caffe/util/device_alternate.hpp:40:0,
- 5基于FPGA的图像白平衡算法实现,包括tb测试文件和MATLAB辅助验证_在fpga上实现白平衡
- 6转:Maven pom文件常用配置小结
- 7嵌入式linux/鸿蒙开发板(IMX6ULL)开发(十)gcc编译器的使用_imix6 uboot compiler-gcc7.h
- 8解决测试 centos 邮件发送失败问题_centos下mail无法发送
- 9Python 常用内置函数详解(二):print()函数----打印输出
- 10第四章分支结构程序设计总结_双分支if语句例题
基于 python 语言使用 werobot 开发微信公众号,接入 chatAI 大模型,实现连续对话!!文末提供解决微信5秒回复问题!!!!!_werobot csdn
赞
踩
随着AI的不断融入到我们的生活中,做一个机器人是很多人的憧憬。
本文使用python结合阿里云的通义千问大模型进行的。
里面有很多模型,百川大模型、千帆等等
这不是本文的重点,本文的重点是开发公众号,实现AI聊天。
1、前置条件
1.1你要有python3 版本好像要大于3.7
我装了很久,一直出错,Can‘t connect to HTTPS URL because the SSL module is not available.
解决办法如图所示,后来索性直接使用conda安装了,具体自己搜索吧,如果你是 SSL 等错误,可参考
1.2安装包
pip3 install dashscope
pip3 install werobot
- 1
- 2
1.3 需要有nginx或aapache
我这里是使用宝塔安装的 nginx
1.4新建网站,添加反向代理
需要添加一个一个网址,我这里直接是ip,然后添加一个反向代理
我开启的是8000端口,后续要用到这个端口


2、阿里云给的连续对话模板是
def conversation_with_messages(): messages = [{'role': Role.SYSTEM, 'content': 'You are a helpful assistant.'}, {'role': Role.USER, 'content': '如何做西红柿炖牛腩?'}] response = Generation.call( Generation.Models.qwen_turbo, messages=messages, result_format='message', # set the result to be "message" format. ) if response.status_code == HTTPStatus.OK: print(response) # append result to messages. messages.append({'role': response.output.choices[0]['message']['role'], 'content': response.output.choices[0]['message']['content']}) else: print('Request id: %s, Status code: %s, error code: %s, error message: %s' % ( response.request_id, response.status_code, response.code, response.message )) messages.append({'role': Role.USER, 'content': '不放糖可以吗?'}) # make second round call response = Generation.call( Generation.Models.qwen_turbo, messages=messages, result_format='message', # set the result to be "message" format. ) if response.status_code == HTTPStatus.OK: print(response) else: print('Request id: %s, Status code: %s, error code: %s, error message: %s' % ( response.request_id, response.status_code, response.code, response.message )) if __name__ == '__main__': conversation_with_messages()

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
因此,想做到连续对话就要对其进行改变。
3、werobot开发公众号
本次用了三个文件和一个文件夹,文件夹名字为 log, 这四个内容存在同一目录下即可
3.1第一个文件 读取json文件
op_file.py
# -*- coding: utf-8 -*-
# 关注微信公众号:右恩
# File : op_file.py
# date ; 2023/12/14 9:57
import os
import json
def read_json(file_path):
with open(file_path, 'r', encoding="utf-8") as json_file:
return json.load(json_file)
def write_json(file_path, data):
with open(file_path, 'w', encoding="utf-8") as json_file:
json.dump(data, json_file, ensure_ascii=False, indent=4)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
3.2 第二个文件用于大模型的连续对话:
文件名为:
tongyimodel_1.py
# -*- coding: utf-8 -*- # 关注微信公众号:右恩 # File : tongyimodel_1.py # date ; 2023/12/14 9:02 import os.path from http import HTTPStatus from dashscope import Generation import dashscope from dashscope.api_entities.dashscope_response import Role from functools import lru_cache from op_file import write_json from op_file import read_json # 大模型的api_key:在文章后面有说明怎么来的 本文最后的注释 1 dashscope.api_key = "sk-ffaadasdasdasdasdasdasdsadsadb" # @lru_cache(maxsize=256) 用于缓存数据,模型不一定5秒回复,这时微信会再次请求一次 # 使用后,可以解决多次回复的问题,意思是我缓存过答案了,不用再次请求了,具体百度吧。 @lru_cache(maxsize=256) # 用于缓存大模型得到的数据, def get_count(file_name, quest_data): # 传入两个参数,1个是用户的ID,一个是对话的文本 json_file_path = os.path.join("./log",f"{file_name}.json") # 检查文件是否存在,用于上下文理解 if os.path.exists(json_file_path): # 如果文件存在,说明之前有过对话 json_data = read_json(json_file_path) json_data.append({"role": Role.USER, "content": quest_data}) else: # 文件不存在,之前没有对话 需要新建一个用户信息模板 json_data = [{'role': Role.SYSTEM, 'content': 'You are a helpful assistant.'}, {'role': Role.USER, 'content': quest_data}] # 下面的内容就是来自阿里云官网 response = Generation.call( Generation.Models.qwen_turbo, messages=json_data, result_format='message', ) if response.status_code == HTTPStatus.OK: result_message = response.output.choices[0]['message'] # 拿到message所有的值,含有用户 json_data.append(result_message)# 将回答记录起来,用于多轮对话,这里是一个json文件,需要写入文件 write_json(json_file_path, json_data) # 写入到用户ID为文件名的JSON文件中 return result_message['content'] # 把AI给的结果返回给机器人 else: return f"Status code: {response.status_code}, error message: {response.message}" # Example usage if __name__ == "__main__": file_name = "asdasd" question_content = "关注微信公众号,右恩" get_count(file_name,question_content)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
3.3写的机器人
we_robot.py
# -*- coding: utf-8 -*- # 关注微信公众号:右恩 # File : wechat_robot.py # date ; 2023/12/14 15:08 import werobot import re import random from werobot.replies import SuccessReply from tongyimodel_1 import get_count from werobot.client import Client welcome_message = ("我躺在床上,月光洒在窗上\n" "此刻我抬头望见月光\n" "有人在小酒馆把酒言欢\n" "有人依偎在爱人肩头\n" "有人沿着路灯寻找回家的路\n" "有人靠着孤独的枕头掉着眼泪\n" "有人做着美梦\n" "每一个故事不一定有最完美的结局\n" "每个人相遇即是缘分\n" "很高兴遇见你,时间很长,我们慢慢相知。") robot = werobot.WeRoBot() class RobotConfig(object): HOST = "0.0.0.0" # 服务器是这样设置的,如果是在本地映射的,需要修改为127.0.0.1 PORT = "8000" # 这些参数的来源 ------ 本文最后的注释2 TOKEN = "e71b22291e98fbcf469c9f1bdc848419" APP_ID = "weqweqwerqweqweqewq" ENCODING_AES_KEY = "fsdfadfaerqwerqwerfsdfadfaerqwerqwerfsdfadf" robot.config.from_object(RobotConfig) # 关注后回复 @robot.subscribe def welcome_subscibe(f): print(f) return welcome_message @robot.text # 收到用户发来的消息, def replyTest(msg): # msg.source是用来记录用户的ID,记录这个值并生成一个文件,储存对话 # msg.Content是拿到用户发来的消息 return get_count(msg.source, msg.Content) robot.run()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
3.4运行
python3 we_robot.py

3.5加入守护进程
nohup python3 we_robot2.py >> output.out &
- 1
4、注释
4.1注释1
原文链接
https://help.aliyun.com/zh/dashscope/developer-reference/api-details?disableWebsiteRedirect=true
4.2注释2
这个8000端口,最前面我说了
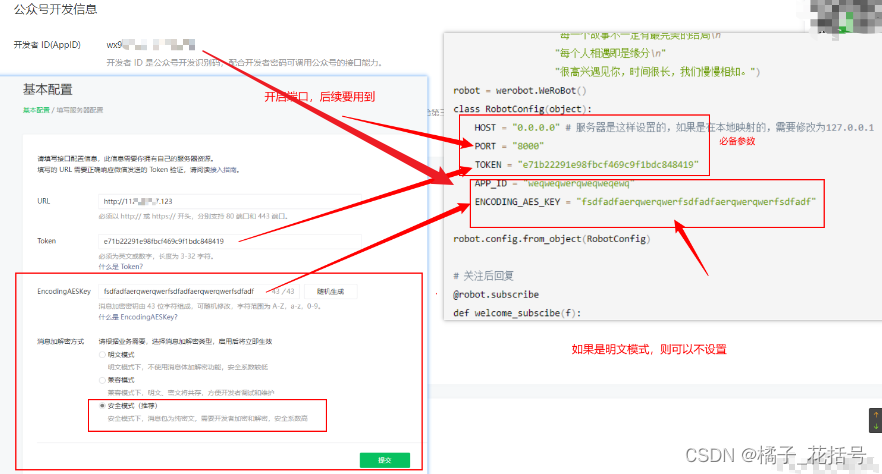
在这里插入图片描述](https://img-blog.csdnimg.cn/direct/9622f439f5c1406dbb3c5e2f130d6b95.png)
案例

来测试一下吧,一个关注不过分吧

注:werobot中提供了一个回复
微信公众号有一个5秒回复的限制,如果5秒内没有回复,就会再次进行请求,可回复success,此时微信就不会再次请求
我这里没有加入
给出
from werobot.replies import SuccessReply
return SuccessReply
- 1
- 2
- 3
但是要加入一个多线程之类的东西,可以自己试试
解决微信5秒回复的问题 ,提供两个方法
解决微信客户端5秒未拿到请求时的回复问题
都是两种方法
演示均已 werobot 模块为例,其余模块一样
第一种方法
使用缓存机制
import time import werobot from werobot.replies import SuccessReply from werobot.replies import TextReply from expiringdict import ExpiringDict robot = werobot.WeRoBot() class RobotConfig(object): HOST = "127.0.0.1" PORT = "8080" TOKEN = "11111111111" robot.config.from_object(RobotConfig) # 假设这是一个耗时长的任务 def longtime_reply(): time.sleep(7) return "hello world" cache = ExpiringDict(max_len=100, max_age_seconds=50) # 创建一个缓存,并设置最大长度和最大过期时间 @robot.text def replyTest(msg): usrFromId = msg.source # 用户ID recMsg = msg.content # 用户发来的消息 try: if usrFromId in cache: if cache[usrFromId] != "": print("这里是38行") reply = TextReply(message=msg, content=cache[usrFromId]) return reply # 将缓存内容发送给微信客户端 else: time.sleep(5) print("这里是42行") return SuccessReply() else: cache[usrFromId]= "" print("这里是47行") content = longtime_reply() # 模拟耗时间长做的任务 cache[usrFromId]= content # 将拿到耗时间长做的任务结果 time.sleep(5) reply = TextReply(message=msg, content=content) print("这里是51行","拿到了结果",content) return SuccessReply() except Exception as e: return e # return SuccessReply( robot.run()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50

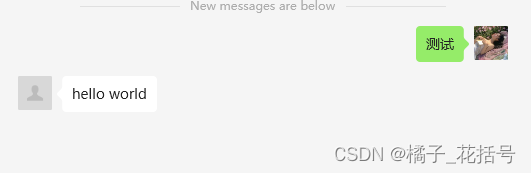
第二种方法
from functools import lru_cache
@lru_cache(maxsize=256)
def longtime_reply():
time.sleep(7)
return "hello world"
@robot.text
def replyTest(msg):
usrFromId = msg.source # 用户ID
recMsg = msg.content # 用户发来的消息
print(recMsg)
return longtime_reply()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
两种办法都可以

