
- 1Fall-detection_fall detection
- 2fiddler 经常抓不到浏览器的包_fiddler抓不到浏览器接口
- 3关于“Python”的核心知识点整理大全61
- 4【机器学习300问】39、高斯分布模型如何实现异常检测?
- 5Retinex图像增强算法_retinex理论适用于灰度图像么
- 6微软(TTS)文本转语音服务API实现_microsoft speech api
- 7HCIA-HarmonyOS设备开发认证V2.0-IOT硬件子系统-ADC
- 8lda 可以处理中文_中文分词(jieba)和语料库制作(gensim)
- 9vue3+vite+ts项目中简单的二次封装axios_ts 二次封装axios
- 10【OpenCV】人脸检测和识别_opencv人脸特征提取与检测
ICML 2018 | 从强化学习到生成模型:40篇值得一读的论文
赞
踩
感谢阅读腾讯AI Lab微信号第34篇文章。当地时间 7 月 10-15 日,第 35 届国际机器学习会议(ICML 2018)在瑞典斯德哥尔摩成功举办。ICML 2018 所接收的论文的研究主题非常多样,涵盖深度学习模型/架构/理论、强化学习、优化方法、在线学习、生成模型、迁移学习与多任务学习、隐私与安全等,在本文中,腾讯 AI Lab 的研究者结合自身的研究重心和研究兴趣对部分 ICML 2018 论文进行了简要介绍和解读。
当地时间7月10-15日,第 35 届国际机器学习会议(ICML 2018)在瑞典斯德哥尔摩成功举办。和计算机科学领域内的很多其它顶级会议一样,今年 ICML 会议的投稿量和接受量都出现了大幅增长。如下图所示,ICML 2018 共有 2473 篇有效投稿,较上年增长 45%,其中 618 篇被接收,接收率为 25.1%。
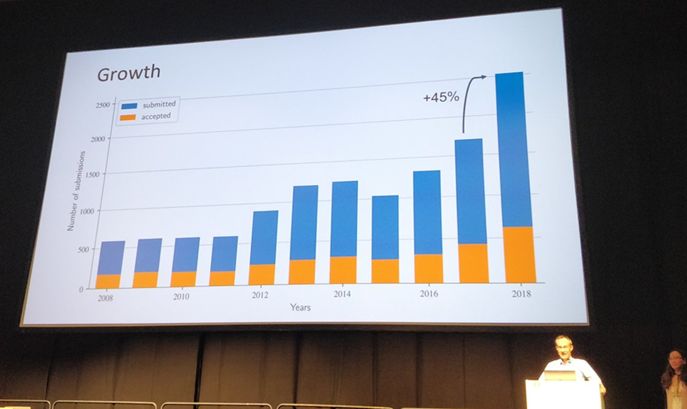
大会主席 Francis Bach 介绍 ICML 2018 论文接收情况
腾讯 AI Lab 今年共有 16 篇论文入选,远远超出上一年的 4 篇,详情请参阅腾讯 AI Lab 微信公众号之前发布的文章《ICML 2018 | 腾讯AI Lab详解16篇入选论文》。
ICML 2018 所接收的论文的研究主题非常多样,涵盖深度学习模型/架构/理论、强化学习、优化方法、在线学习、生成模型、迁移学习与多任务学习、隐私与安全等,具体统计情况见下图:
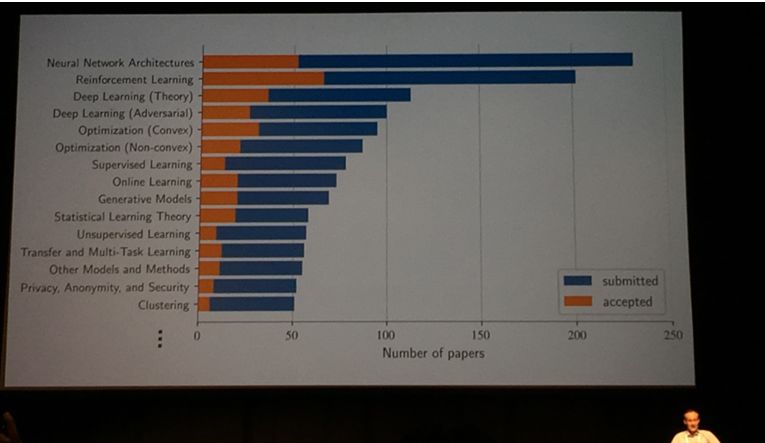
ICML 2018 论文的研究主题分布情况
在本文中,腾讯 AI Lab 的研究者结合自身的研究重心和研究兴趣对部分 ICML 2018 论文进行了简要介绍和解读,其中涉及的主题包括强化学习、元学习/迁移学习、自动超参数调节/架构搜索。当然,文中提到的论文一般都涉及多个主题,所提供的划分方式仅作参考。
强化学习
自从 AlphaGo 横空出世,击败世界顶级棋手李世石以来,机器学习领域对强化学习的研究热情一直有增无减。今年的 ICML 同样接收了大量强化学习方面的研究成果,这些研究可概括为以下类别:理论、网络、算法、优化方法、探索、奖励、基于模型的方法、分布式、分层式、元学习、迁移学习、应用。下面列出了部分值得关注的论文:
强化学习理论
The Uncertainty Bellman Equation and Exploration
不确定性贝尔曼方程及探索
链接:https://arxiv.org/abs/1709.05380:
这项研究由 DeepMind 完成,研究了强化学习中的探索与利用(exploration/exploitation)问题。对于利用,贝尔曼方程能将任意时间步骤的值连接到后续时间步骤的预期值。研究者在这篇论文中提出了一种类似的不确定贝尔曼方程(UBE),可将任意时间步骤的不确定性连接到后续时间步骤的预期不确定性,由此能将策略的潜在探索效益扩展到多个时间步骤。这种方法能自然地扩展用于具有复杂的泛化问题的大型系统并且能在一些强化学习问题上更好地替代 ε-greedy 策略。

使用线性不确定性估计的一步式 UBE 探索
搜索与规划
Efficient Gradient-Free Variational Inference using Policy Search
使用策略搜索的高效无梯度变分推理
链接:http://proceedings.mlr.press/v80/arenz18a/arenz18a.pdf
代码:https://github.com/OlegArenz/VIPS
这项研究由德国达姆施塔特工业大学和英国林肯大学合作完成。文中提出了一种高效的无梯度方法,可基于来自随机搜索方法的近期见解学习多模态分布的广义 GMM 近似。该方法会建立一个信息几何信任区域,以确保有效探索采样空间和 GMM 更新的稳定性,从而实现对多变量高斯变分分布的有效估计。相关实现的代码已公布。

元学习
Been There, Done That: Meta-Learning with Episodic Recall
去过那里,做过那事:使用情景回调的元学习
链接:https://arxiv.org/abs/1805.09692
这项研究由 DeepMind、普林斯顿神经科学研究所、MPS-UCL 计算精神病学中心、伦敦大学学院 Gatsby 计算神经科学部合作完成。元学习智能体很擅长根据开放式的任务分布快速学习新任务,但它们在学习下一个任务时就会忘记已经学过的任务。针对这一问题,研究者提出了一个可以生成一系列开放式并且可重复的任务环境,从而使得元学习只能可以不断温故而知新。不过这种方法在元学习的算法端没有太大的创新,采用了“短时 LSTM 记忆+外部可微分记忆”的方法。
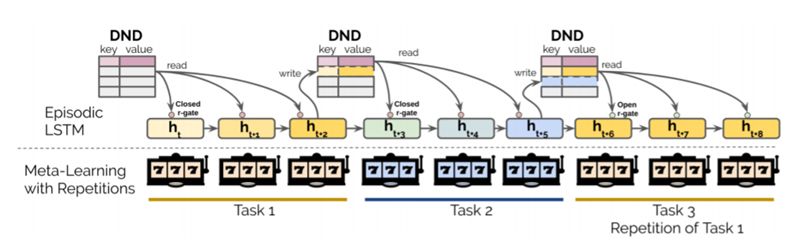
模型架构和环境结构
分布式学习
Implicit Quantile Networks for Distributional Reinforcement Learning
用于分布式强化学习的隐式分位数网络
链接:https://arxiv.org/abs/1806.06923
这项研究由 DeepMind 完成,文中构建了一种可广泛应用的、灵活的、当前最佳的 DQN 分布式变体——隐式分位数网络(IQN)。研究者使用了分位数回归(quantile regression)来近似状态-动作回报分布的全分位数函数。通过在样本空间上重新参数化一个分布,这能得到一个隐式地定义的回报分布并带来一大类对风险敏感的策略。这种 IQN 相比 QR-DQN 更有优势。
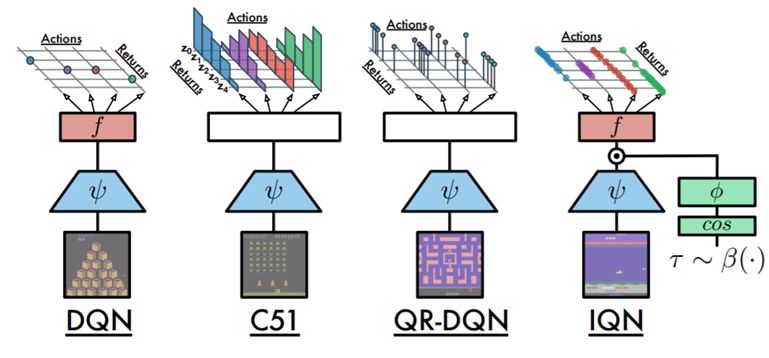
DQN 和近期几种分布式强化学习算法的网络架构
分层式强化学习
Self-Consistent Trajectory Autoencoder: Hierarchical Reinforcement Learning with Trajectory Embeddings
自洽的轨迹自编码器:使用轨迹嵌入的分层式强化学习
链接:https://arxiv.org/abs/1806.02813
实验:https://sites.google.com/view/sectar
这项研究由加利福尼亚大学伯克利分校和谷歌大脑合作完成,其中提出了一种全新的分层式强化学习算法 SeCTAR。该算法的灵感来自变分自动编码器,使用了一种自下而上的方式来学习轨迹的连续表征,而没有对人工设定的指标或子目标信息的明确需求。该研究基于两个主要思想:第一,研究者提出构建一个 skill 的连续潜在空间;第二,研究者提出使用一个能够同时学习产生 skill 和预测它们的结果的概率隐含变量模型。
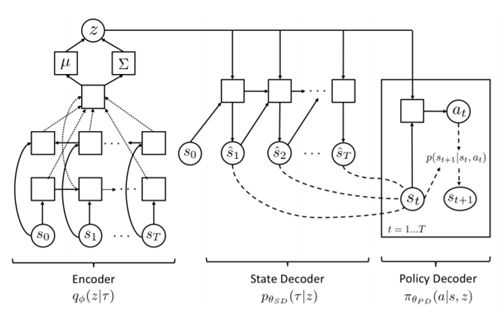
SeCTAR 模型计算图
Hierarchical Imitation Learning and Reinforcement Learning
分层式模拟学习与强化学习
链接:https://arxiv.org/abs/1803.00590
实验:https://sites.google.com/view/hierarchical-il-rl
这项研究由加州理工学院、微软研究院和马里兰大学帕克分校合作完成,研究了有效利用专家反馈来学习序列决策策略的方法。研究者提出了一种分层式引导(hierarchical guidance)算法框架,能利用问题的层次结构来集成不同模式的专家交互。该框架可以在不同层面整合模拟学习(IL)与强化学习(RL)的不同组合,从而显著降低专家工作量和探索成本。
奖励设计
Using Reward Machines for High-Level Task Specification and Decomposition in Reinforcement Learning
在强化学习中使用奖励机进行高级任务规范和分解
链接:http://proceedings.mlr.press/v80/icarte18a/icarte18a.pdf
这项研究由多伦多大学计算机科学系、Vector Institute 和 Element AI 完成。该论文有两大贡献。第一,研究者引入了一种用于定义奖励的有限状态机——奖励机(Reward Machine)。奖励机能以灵活的方式(包括连接、循环和条件规则)分解不同的奖励函数。当智能体在环境中的状态之间变化时,它也会在奖励机中发生状态变化。在每次变化后,奖励机都会输出该智能体此时应该使用的奖励函数。第二,研究者引入了一种“用于奖励机的 Q 学习(QRM)”算法,可利用奖励机的内在结构来分解问题,从而提升样本效率。

算法
Soft Actor-Critic: Off-Policy Maximum Entropy Deep Reinforcement Learning with a Stochastic Actor
Soft Actor-Critic:使用随机 actor 的离策略最大熵深度强化学习
链接:https://arxiv.org/abs/1801.01290
这项研究由加州大学伯克利分校电气工程与计算机科学系完成。无模型深度强化学习算法往往有两大主要难题:非常高的样本复杂度和脆弱的收敛性质;需要很细致的超参数调节才能解决。针对这一问题,研究者提出了一种基于最大熵强化学习框架的离策略 actor-critic 深度强化学习算法 soft actor-critic。在这个框架中,actor 的目标是在最大化熵的同时最大化预期的回报——即在成功完成任务的同时尽可能随机地行动。之前基于这一框架的深度强化学习方法已被形式化为 Q 学习方法。通过将离策略更新与稳定的随机 actor-critic 形式相结合,新方法在一系列连续控制的基准任务上都取得了当前最佳表现。

An Efficient, Generalized Bellman Update for Cooperative Inverse Reinforcement Learning
一种用于协作式逆向强化学习的高效广义 Bellman 更新
链接:https://arxiv.org/abs/1806.03820
这项研究由加州大学伯克利分校电气工程与计算机科学系完成。为了让 AI 系统能正确识别人类用户的目标并据此采取适当行动,协作式逆向强化学习(CIRL)将这个价值对齐(value alignment)问题当作是人类和机器人之间的双玩家博弈问题,其中仅有人类知道奖励函数的参数,而机器人需要通过交互学习它们。研究者在这篇论文中利用了 CIRL 的一个特定性质——人类是具有完全信息的智能体,来推导对标准 Bellman 更新的一种修改方式,使其能保留其中的最优性质;这能大幅降低问题的复杂性并能放宽 CIRL 对人类理性的假设。
探索
Learning to Explore via Meta-Policy Gradient
使用元策略梯度学习探索
链接:https://arxiv.org/abs/1803.05044
这项研究由百度研究院、德克萨斯大学奥斯汀分校和伊利诺伊大学香槟分校完成。离策略学习方法很依赖对探索策略的选择,而现有的探索方法基本都基于为正在进行的 actor 策略添加噪声,而且只能探索 actor 策略规定的附近局部区域。研究者在这篇论文中开发了一种简单的元策略梯度算法,能够自适应地学习 DDPG(深度确定性策略梯度)中的探索策略。这种算法可以训练独立于 actor 策略的灵活的探索行为,实现全局探索,从而显著加速学习过程。
优化
Stochastic Variance-Reduced Policy Gradient
随机的方差降低的策略梯度
链接:https://arxiv.org/abs/1806.05618
这项研究由意大利米兰理工大学和法国国家信息与自动化研究所(INRIA)完成。论文中提出了一种全新的强化学习算法,其中包含一个用于求解马尔可夫决策过程(MDP)的策略梯度的随机式方差降低的版本。尽管 SVRG 方法在监督学习领域很成功,但却难以应用到策略梯度方面。针对其中的难题,研究者提出了 SVRPG,能够利用重要度权重来保留梯度估计的无偏差性。在 MDP 的标准假设下,SVRPG 能保证收敛。

Global Convergence of Policy Gradient Methods for the Linear Quadratic Regulator
线性二次调节器的策略梯度方法的全局收敛性
链接:https://arxiv.org/abs/1801.05039
这项研究由华盛顿大学和杜克大学合作完成。直接策略梯度方法是一种常用于强化学习和连续控制问题的方法,但也有一个显著的缺点:即使是在最基本的连续控制问题(线性二次调节器)中,这些方法都必须求解一个非凸优化问题,而人们在计算方面和统计方面对它们的效果的理解都知之甚少。相对而言,最优控制理论中的系统辨识和基于模型的规划具有更加坚实的理论基础。这篇论文填补了这一空白,研究表明(无模型的)策略梯度方法能全局收敛到最优解,并且在采样和计算复杂度方面是有效的。
多智能体强化学习
Competitive Multi-Agent Inverse Reinforcement Learning with Sub-optimal Demonstrations
具有次优演示的竞争性多智能体逆向强化学习
链接:https://arxiv.org/abs/1801.02124
这项研究由美国西北大学完成,研究了零和随机博弈中当专家演示已知不是最优时的逆向强化学习问题。相比于之前通过假设专家策略中的最优性来解耦博弈中的智能体的工作,该论文引入了一个新的目标函数,可直接让专家与纳什均衡策略斗争。研究者设计了一个算法,可以在以深度神经网络作为模型近似的逆向强化学习背景中求解其奖励函数。在这样的设置中,模型和算法不会被解耦。研究者还提出了一种用于零和随机博弈的对抗训练算法,可用于寻找大规模博弈中的纳什均衡。
Modeling Others Using Oneself in Multi-Agent Reinforcement Learning
在多智能体强化学习中使用自身建模其它智能体
链接:https://arxiv.org/abs/1802.09640
这项研究由纽约大学计算机科学系和 Facebook 人工智能研究中心完成。论文中提出了一种名为 Self Other-Modeling(SOM)的新方法,其中智能体可使用自己的策略以在线的形式来预测其它智能体的动作并更新自己对它们的隐藏状态的信念。这样,不管是以协作方式还是以对抗方式,多个智能体都能基于对其它智能体的估计来学习更好的策略。
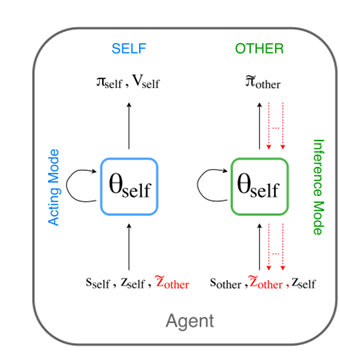
一个给定智能体的 SOM 架构
QMIX: Monotonic Value Function Factorisation for Deep Multi-Agent Reinforcement Learning
QMIX:用于深度多智能体强化学习的单调价值函数因子分解
链接:https://arxiv.org/abs/1803.11485
这项研究由牛津大学和 Russian-Armenian 大学完成。论文中提出了一种能以中心化的端到端的方式训练去中心化策略的基于价值的全新方法 QMIX。QMIX 能够将仅基于局部观察的每个智能体的价值以复杂的非线性方式组合起来,估计联合的动作-价值。研究者在一组高难度《星际争霸2》微操作任务上评估了 QMIX,得到了很好的结果。
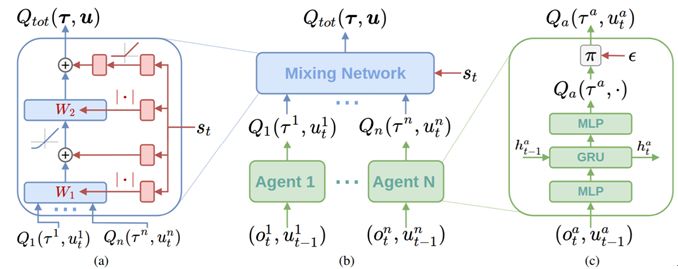
(a)混合网络结构。蓝色是混合网络的层,红色是为混合网络产生权重和偏置的超网络;(b)整体 QMIX 架构;(c)智能体的网络结构
Mean Field Multi-Agent Reinforcement Learning
平均场多智能体强化学习
链接:https://arxiv.org/abs/1802.05438
这项研究由完成。现有的多智能体强化学习方法的智能体数量通常很小,因为维度灾难和巨量智能体交互让更多智能体的强化学习难以真正实现。针对这一难题,研究者提出了平均场强化学习,其中多智能体之间的交互是由一个单个智能体与群体智能体或邻近智能体的平均效应之间的交互近似得到的;这两个实体之间的相互作用能互相强化:单个智能体的最优策略的学习取决于群体的动态,而群体的动态会根据单个策略的集体模式而变化。
强化学习中的元学习/迁移学习
Transfer in Deep Reinforcement Learning Using Successor Features and Generalised Policy Improvement
使用后继特征和广义策略提升的深度强化学习迁移
链接:http://proceedings.mlr.press/v80/barreto18a/barreto18a.pdf
这项研究由 DeepMind 完成,其研究基础是可通过迁移之前任务的知识/技巧到新的任务来实现强化学习加速。这项工作基于 SF&GPI 框架,其中 SF 是指后继特征,GPI 是指广义策略提升,并做了以下两点改进:1)放松了后继特征必须为一个固定特征集的线性组合这个假设;2)可以把前序任务的奖励函数作为特征迁移到后序任务并改善该任务。研究者在一个复杂的 3D 环境上进行了实验验证,结果表明 SF&GPI 推动实现的迁移几乎立刻就能在未曾见过的任务上得到非常优良的策略。

Policy and Value Transfer in Lifelong Reinforcement Learning
终身强化学习中的策略和价值迁移
链接:http://proceedings.mlr.press/v80/abel18b/abel18b.pdf
代码:https://github.com/david-abel/transfer_rl_icml_2018
这项研究由布朗大学计算机科学系完成,研究了如何最好地使用之前的经验来提升终身学习效果的问题。首先,针对终身学习的越来越复杂类别的策略和任务分布,研究者先确定能优化在这些任务分布上的预期表现的初始策略。考虑到策略初始化这种简单的迁移策略的效果不是很理想,因此研究者提出使用价值函数来初始化迁移策略。研究者证明后者不但可以提升迁移表现,而且可以保证 PAC 理论的完备性。相关实验的代码已经开放。
State Abstractions for Lifelong Reinforcement Learning
用于终身强化学习的状态抽象
链接:https://david-abel.github.io/papers/lifelong_sa_icml_18.pdf
代码:https://github.com/david-abel/rl_abstraction
这项研究同样由布朗大学计算机科学系完成,试图从表征压缩(即状态抽象)的角度来解决终身强化学习问题。研究者指出,由于在终身强化学习中需要同时完成知识迁移、探索、信度分配等问题,因此对通用表征进行压缩可以提高计算效率。文中提出了两种状态抽象方法:1)过渡式状态抽象,其最优形式可有效地计算得到;2)PAC 状态抽象,其能保证与任务分布一致。研究者表明过渡式 PAC 抽象的联合方法能够有效得到、能保留接近最优的行为、还能降低简单域中的样本复杂性,从而得到一系列可用于终身强化学习的所需抽象。相关实验的代码已经开放。
Continual Reinforcement Learning with Complex Synapses
使用复杂突触的持续强化学习
链接:https://arxiv.org/abs/1802.07239
这项研究由伦敦帝国理工学院计算系和生物工程系与 DeepMind 合作完成。为了解决灾难性遗忘(catastrophic forgetting)问题,研究者提出在表格式的深度强化学习算法中加入一个具备生物复杂性的突触模型,并且证实该改进确实可以在不同时间尺度上减轻灾难性遗忘问题。值得一提的是,研究者还发现这种方法除了能在两个简单任务的序列训练上实现持续学习之外,还能通过降低对经历重放数据库的需求而克服任务内的遗忘问题。
元学习/迁移学习
从以上的统计信息中可以看出来,迁移学习和多任务学习这个主题虽不如强化学习这么火爆,也占据了很大一席位置。迁移学习这个方向的发展已从过去一两年的基于深度学习的一系列无监督域适应方法跳了出来,往更有意义且更具挑战性的迁移学习本身的理论以及优化方法发展,这也是一个趋势。重点论文总结如下:
CyCADA: Cycle-Consistent Adversarial Domain Adaptation
CyCADA:循环一致的对抗域适应
链接:https://arxiv.org/abs/1711.03213
这项研究由伯克利人工智能研究实验室(BAIR)、OpenAI 和波士顿大学合作完成。该论文和下一篇论文是仅有的两篇基于深度学习和对抗损失的无监督域适应研究。这篇论文的核心思想是把 CycleGAN 里的核心思想引入到无监督域适应,以在从源域生成目标域后再从目标域生成源域,能使得生成的源域和原来的源域保持足够接近。研究者提出的 CyCADA 模型在像素层面和特征层面上都能进行适应,在利用任务损失的同时能保持循环一致性,而且无需对齐的配对。研究者在数字分类和道路场景形义分割等多个适应任务上进行了实验,取得了新的当前最佳结果。
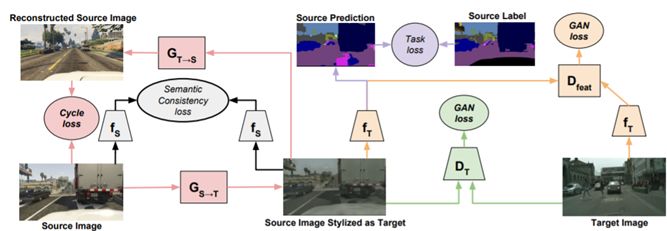
使用像素空间输入的循环一致性对抗适应。通过直接将源训练数据再次映射到目标域,能够移除这些域之间的低层面差异,确保任务模型能很好地立足于目标数据
Learning Semantic Representations for Unsupervised Domain Adaptation
学习用于无监督域适应的语义表征
链接:http://proceedings.mlr.press/v80/xie18c/xie18c.pdf
代码:https://github.com/Mid-Push/Moving-Semantic-Transfer-Network
这项研究由中山大学完成。这篇论文的贡献在于通过伪标签(pseudo label),用一种有监督的类别判别式方法对齐两个领域之间的距离。预计在同一类别但不同域中的特征会被映射在临近的位置,从而导致目标分类准确度提升。相关实验的代码已经开放。
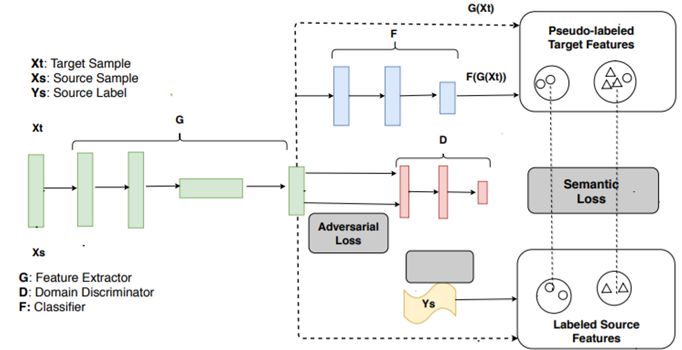
除了标准的源分类损失,其中也使用了域对抗损失来对齐两个域的分布
GradNorm: Gradient Normalization for Adaptive Loss Balancing in Deep Multitask Networks
GradNorm:用于深度多任务网络中自适应损失平衡的梯度归一化
链接:https://arxiv.org/abs/1711.02257
这项研究由 Magic Leap 完成。这篇论文解决了一个非常有意思并且非常实用的问题,即多任务学习中多个任务难易程度不同所导致的优化不同步问题。作者提出了一种梯度传播机制,其核心思想是动态调整多个任务的权重,这些权重通过各个任务的实时梯度再进行反向传播和更新。研究表明,GradNorm 算法对多种不同的网络架构都有效,而且无论是回归任务还是分类任务,无论是合成数据集还是真实数据集,GradNorm 在多个任务上都能实现优于单任务网络的准确度并降低过拟合。GradNorm 也能得到比肩或超过穷举网格搜索方法的表现,尽管其仅涉及到单个不对称超参数 α。因此,曾经每增加一个任务都会导致计算需求指数增长的繁琐的搜索过程现在只需几次训练就能完成了,而且无论任务有多少都一样。研究者还表明梯度操作能实现对多任务网络的训练动态的更好控制。
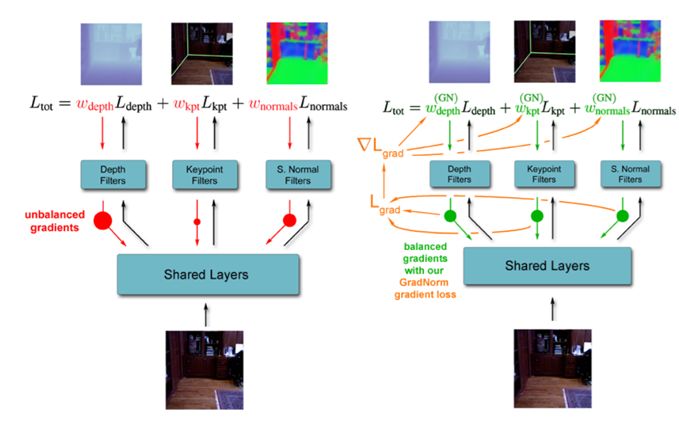
梯度归一化。不同任务上不平衡的梯度范数(左图)会导致多任务网络训练效果次优。GradNorm 通过计算一个全新的梯度损失 Lgrad(右图)来调节损失权重,从而解决梯度范数中的不平衡。
Detecting and Correcting for Label Shift with Black Box Predictors
使用黑箱预测器检测和校正标签偏移
链接:https://arxiv.org/abs/1802.03916
这项研究由卡内基·梅隆大学和 Amazon AI联合完成。克服并减小域偏移(domain shift)是迁移学习中非常重要的问题。这篇工作首次提出了黑箱偏移估计(BBSE)方法——其在标签偏移的情形下可以量化和纠正标签偏移。虽然更好的预测因子能带来更严格的估计,但即使预测因子有偏差、不准确或未校准,只要它们的混淆矩阵是可逆的,BBSE 就有效。

Meta-Learning by Adjusting Priors Based on Extended PAC-Bayes Theory
通过调整基于扩增 PAC-贝叶斯理论的先验的元学习
链接:https://arxiv.org/abs/1711.01244
代码:https://github.com/ron-amit/meta-learning-adjusting-priors
这项研究由以色列理工学院Viterbi 电气工程学院的 Ron Amit 和 Ron Meir 完成。ICML 2018 上单纯研究元学习的工作不多,大多数是元学习与强化学习等结合的工作,所以这算其中之一。这篇论文本质上是扩展了经典的元学习方法 MAML——鼓励初始值是之前任务的参数的一个由先验函数(prior function)所决定的概率分布。同时, MAML 的作者 Chelsea Finn 也在今年 NIPS 提交了一篇概率 MAML(probabilistic MAML)。两者基本思路类似。相关实验的代码已经开放。
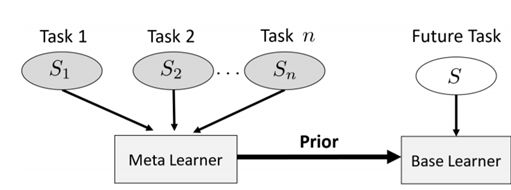
元学习器使用被观察任务的数据集来推理“先验知识”,这反过来又能促进该任务环境中未来任务中的学习
Gradient-Based Meta-Learning with Learned Layerwise Metric and Subspace
使用所学习到的逐层式度量和子空间的基于梯度的元学习
链接:https://arxiv.org/abs/1801.05558
这项研究由韩国浦项科技大学计算机科学与工程系完成。这篇元学习的工作相对较有意思。首先,它不但迁移了参数作为初始值,同时迁移了每层的激活。这个思路应该是借鉴了知识蒸馏(knowledge distillation)的相关工作。更重要的是其中关于相似度度量的定义,该方法是直接学习一个新的适合各个任务进行比较的度量空间。
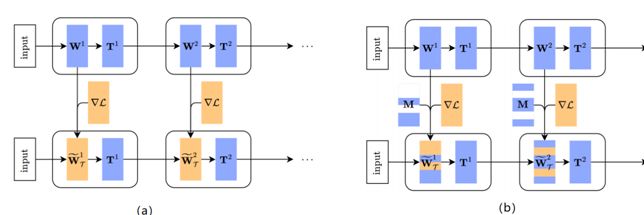
(a)一个变换网络(T-net)的适应过程图示,(b)一个掩模变换网络(MT-net)的适应过程图示
自动超参数调节/架构搜索
现代深度学习方法往往具有大量超参数,而且这些超参数对模型的性能和表现有很大的影响,因此高效实用的调节方法具有很重要的价值。因此,自动超参数调节可以说是机器学习领域的核心研究方向之一,所以这方面的研究非常多,下面列出了 2 篇这个方向的论文,另外还有 2 篇研究架构搜索的论文。
BOHB: Robust and Efficient Hyperparameter Optimization at Scale
BOHB:规模化的稳健且高效型超参数优化
链接:https://arxiv.org/abs/1807.01774
这项研究由德国弗莱堡大学计算机科学系完成。这篇文章的出发点是结合 TPE 的探索(exploration)过程和 GP 的利用(exploitation)工作,用以解决当前长时间序列下现在 GP 优化时间长开销大以及 TPE 效能不足的问题。研究者提出了一种新的超参数优化方法,能在多种不同问题类型上都得到优于贝叶斯优化和 Hyperband 的表现,其中包括支持向量机、贝叶斯神经网络和卷积神经网络等。

BOHB 中采样过程的伪代码
Fast Information-theoretic Bayesian Optimisation
快速信息论贝叶斯优化
链接: https://arxiv.org/abs/1711.00673
代码:https://github.com/rubinxin/FITBO
这项研究主要由牛津大学工程科学系完成。这篇工作基于信息论提出了一个新的算法 FITBO。该算法可以直接量化两个域之间的距离大小。其基本逻辑是,FITBO 可以避免重复采样全局极小化量(global minimizer)。并且,该算法中核(kernel)的选择相对较多,因此性能上可能会更优。研究者已公开 FITBO 的 Matlab 代码。

FITBO 采集函数
Efficient Neural Architecture Search via Parameter Sharing
通过参数共享实现高效神经架构搜索
链接:https://arxiv.org/abs/1802.03268
这项研究由 Google Brain、卡内基梅隆大学语言技术研究所和斯坦福大学计算机科学系合作完成。这篇工作很有名,即自动学习神经网络的结构。研究者提出了高效神经架构搜索(ENAS),这是一种快速且低成本的自动模型设计方法。相比于在前 N 个数据上得到结果,ENAS 通过参数共享有效地迁移了一部分知识进来;相比于 NAS 等其它基准,效果提高了将近 1000 倍。
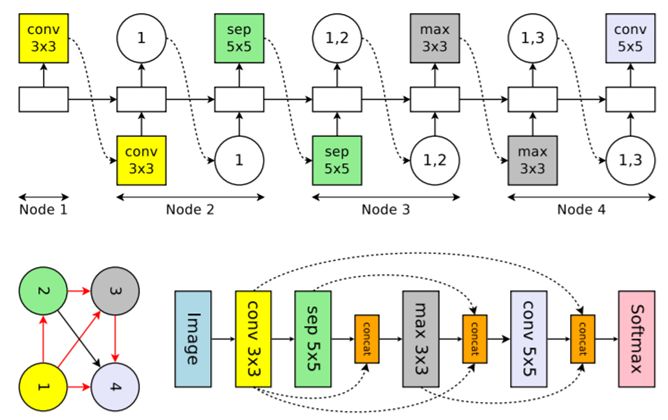
在有 4 个计算节点(表明卷积网络有 4 层)的搜索空间中一个卷积单元的运行示例。上图:控制器 RNN 的输出。左下图:对应于该网络架构的计算 DAG,红色箭头表示活动的计算路径。右下图:完整网络,虚线箭头表示 skip 连接。
Learning to search with MCTSnets
使用 MCTSnets 学习搜索
链接:https://arxiv.org/abs/1802.04697
这项研究由 DeepMind 完成。通常人工智能规划用树搜索来实现。这篇文章中就提出了一个基于蒙特卡洛树搜索(MCTS)进行自动结构搜索的方法 MCTSnet,该方法可以自动学习搜索的位置/内容/方法(where/what/how)。该方法的大致思路即是在神经网络内部建立一种类似于 MCTS 的模拟机制,从而进行扩展/评估/存储向量嵌入等操作。

MCTSnet 算法
深度学习架构
深度网络架构的设计一直以来都是深度学习的关键问题,针对不同目的(例如提高模型分类能力、提高多任务场景能力、复用已有模型知识),在结构设计上也有不同的考虑,下面将介绍几篇有代表性的网络结构设计论文。
Beyond Finite Layer Neural Networks: Bridging Deep Architectures and Numerical Differential Equations
超越有限层数的神经网络:搭建深度架构和数值微分方程之间的桥梁
链接:https://arxiv.org/abs/1710.10121
这项研究的作者所属机构非常多,包括北京大学多个机构、哈佛医学院、北京大数据研究院等。这篇论文讨论了深度神经网络的设计与微分方程(ODE 和 PDE)之间的关系,认为神经网络结构设计很多其实与微分方程原理不谋而合,举例说了 ResNet、PolyNet、RevNet 等经典网络可如何表达成微分方程的形式。并且依据 ODE 原理设计了一种新型结构 LM-ResNet,该结构在 ImageNet、CIFAR 等数据集上超过了 ResNet 的效果。
Deep Asymmetric Multi-task Feature Learning
深度非对称多任务特征学习
链接:https://arxiv.org/abs/1708.00260
这项研究由韩国蔚山科技大学、AItrics 和韩国科学技术院合作完成。这篇论文提出了一种新的多任务学习模型,该模型是 ICML 16 工作 AMTL 的扩展,AMTL提出了一种非对称的多任务学习框架,认为容易的任务学习到的信息需要更多传递给难任务以帮助难任务的学习,而难任务学习到的信息传递给容易任务的必要性低,因而提出一种参数重建(weight reconstruction)的方法,实现了不同任务参数的不对称重建,但该框架对多类别的可扩展性差,也不易于与深度网络结合,本文提出一种基于自动编码器的方法,让不同任务学习到的信息能不对称地传递到共有特征层,效果优于 ATML。
Born-Again Neural Networks
再生神经网络
链接:https://arxiv.org/abs/1805.04770
这项研究由南加州大学、卡内基梅隆大学、Amazon AI、苏黎世联邦理工工学院和加州理工学院合作完成。这篇论文用已有网络学到的知识重新训练一个相同结构的网络模型,如此递进式地训练,最终将中间得到的多个模型融合,能取得最佳的效果,该训练方式对现有 ResNet、DenseNet 等经典结构都适用。
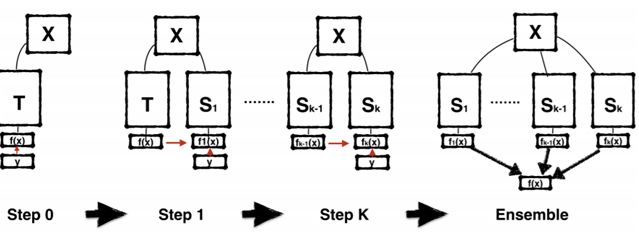
再生网络训练流程图示。第 1 步,根据标签 Y 训练教师模型 T;然后在后续每一步,根据不同的随机种子初始化并根据前一代的监督训练一个相同的新模型。在这个流程最后,可以使用多代学生模型的集合来实现额外的增益。
Disentangled Sequential Autoencoder
解开的序列自动编码器
链接:https://arxiv.org/abs/1803.02991
这项研究由剑桥大学和迪斯尼研究院合作完成。研究者提出了一种用于编码和生成视频或音频等高维序列数据的 VAE 架构。相比于之前的方法,研究者通过精心设计概率图模型实现了解开的表征。这种架构使用了隐含变量来表征内容(即在序列中不变的信息),并使用了与每一帧相关的一组隐含变量来表征动态信息(比如姿态和位置)。这种方法重在通过学习视频/音频内容和动态的分布来实现序列生成,而不是基于被观察到的序列来预测未来帧。因此,这种模型还能用于未曾见过的序列。
Attention-based Deep Multiple Instance Learning
基于注意的深度多实例学习
链接:https://arxiv.org/abs/1802.04712
这项研究由阿姆斯特丹大学完成。多实例学习(MIL)是一种将单个类别标签分配给一袋(bag)实例的监督学习。研究者在这篇论文中将 MIL 问题描述成了学习袋标签(bag label)的伯努利分布的问题,其中袋标签的概率可通过神经网络完全参数化。此外,研究者还提出了一种基于神经网络的排列不变聚合算子,可对应于注意机制。这种基于注意的算子能帮助了解每个实例对袋标签的贡献。
生成模型
自生成对抗网络(GAN)被提出以来,生成模型近几年来一直是机器学习各大会议的研究热点。在这次 ICML 中一共有 20 余篇关于生成模型的论文,每天都至少有一个独立的生成模型的议程。我们主要关注以下几篇论文:
Chi-square Generative Adversarial Network
卡方生成对抗网络
链接:http://proceedings.mlr.press/v80/tao18b/tao18b.pdf
这项研究由杜克大学与复旦大学完成。为了评估真实数据和合成数据之间的差异,可使用分布差异度量来训练生成对抗网络(GAN)。信息论散度、积分概率度量和 Hilbert 空间差异度量是三种应用比较广泛的度量。在这篇论文中,研究者阐述了这三种流行的 GAN 训练标准之间的理论联系,并提出了一种全新的流程——(χ²)卡方GAN,其概念简单、训练稳定且能够耐受模式崩溃。这个流程可用于解决多个分布的同时匹配问题。此外,研究者还提出了一种重采样策略,可通过一种重要度加权机制为训练后的 critic 函数重新设定目标,从而显著提升样本质量。

RadialGAN: Leveraging multiple datasets to improve target-specific predictive models using Generative Adversarial Networks
RadialGAN:使用生成对抗网络利用多个数据集来改进特定目标的预测模型
链接:https://arxiv.org/abs/1802.06403
这项研究由加州大学、牛津大学和阿兰·图灵研究所完成。训练机器学习预测模型的数据并不总是足够的,研究者在这篇论文中提出了一种可以利用来自相关但不同的来源的数据的新方法,即使用多个 GAN 架构来学习将一个数据集“翻译”成另一个数据集,由此有效地扩增目标数据集。
First Order Generative Adversarial Networks
一阶生成对抗网络
链接:https://arxiv.org/abs/1802.04591
代码:https://github.com/zalandoresearch/first_order_gan
这项研究由 Zalando Research 和奥地利林茨约翰·开普勒大学完成。在最早的 GAN 和 WGAN-GP 等变体中,在更新生成器参数的方向上都存在问题——不对应于目标的最陡的下降方向。研究者在这篇论文中引入了一个描述最优更新方向的理论框架,该框架可推导散度和用于确定更新方向的对应方法的条件要求,这些条件要求能够确保在最陡的下降方向上完成无偏差的 mini-batch 更新。研究者还提出了一种能在近似 Wasserstein 距离的同时正则化 critic 的一阶信息的新散度。配合相应的更新方向,这种散度能够满足无偏差最陡下降更新的要求。
GAIN: Missing Data Imputation using Generative Adversarial Nets
GAIN:使用生成对抗网络的缺失数据插补
链接:https://arxiv.org/abs/1806.02920
这项研究由加州大学、牛津大学和阿兰·图灵研究所完成。研究者提出了一种通过调整生成对抗网络(GAN)框架插补缺失数据的新方法——生成对抗插补网络(GAIN)。其中,生成器(G)观察一个真实数据向量的某些分量,然后基于所观察的内容插补缺失的分量,输出完整向量。而鉴别器(D)则以完整向量为输入,然后判定其中哪些分量是真实的,哪些是插补的。为了确保 D 能让 G 学习到所需分布,研究者以“暗示”向量的形式向 D 提供了一些额外信息。这些暗示会让 D 获得有关原始样本的缺失情况的部分信息,这可被 D 用于将注意重点放在特定分量的插补质量上。从而确保 G 确实能学习根据真实数据分布生成结果。
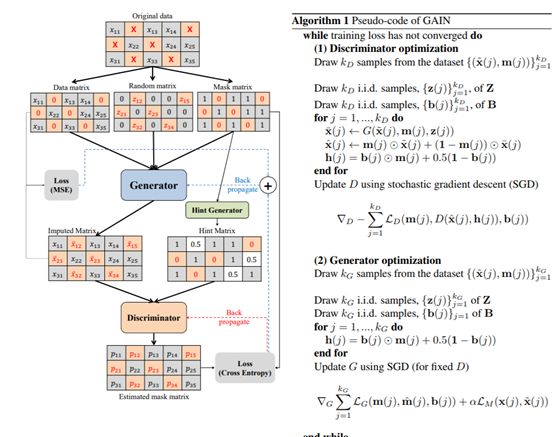
GAIN 架构和伪代码
PixelSNAIL: An Improved Autoregressive Generative Model
PixelSNAIL:一种改进型自回归生成模型
链接:https://arxiv.org/abs/1712.09763
代码:https://github.com/neocxi/pixelsnail-public
这项研究由 Embodied Intelligence 和加利福尼亚大学伯克利分校完成。受元强化学习的近期研究的启发,研究者提出了一种新的生成模型架构,将因果卷积(causal convolutions)和自注意(self attention)结合到了一起。其中因果卷积能够更好地访问序列的更早部分,从而帮助 RNN 更好地建模长程依赖;而自注意可将序列转换为无序的键值存储并能根据内容查询,它们具有无限的感受野,能实现对序列中相距较远的信息的无损访问。两者具有互补性,前者能实现在有限上下文规模上的高带宽访问,而后者能实现在无限大上下文上的访问。两者结合,可让模型实现信息量无限制的高带宽访问。
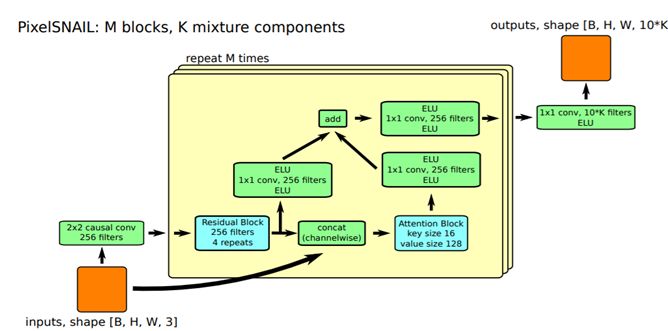
PixelSNAIL 模型架构


