
- 1hive的安装与基本配置(超详细,超简单)_hive.xml怎么配置
- 2hive(二) -- hive部署_启动hive元数据
- 3面试篇:Spring_spring面试
- 4redis数据库简介、redis下载及安装(win64位)、node操作redis、redis实现短信校验注册接口_redis官网下载
- 5实验室安全 考试 题库_如果得知有火,实验指导教师
- 6VS Code中使用已配置完成的git报错Permission denied_vscode git permission denied
- 7FTP_ftp server
- 8Mybatis系列第8篇:自动映射,使用需谨慎!
- 9亚信安全防毒墙网络版卸载,联软安全助手(lva_setupfull)卸载_卸载亚信安全防毒墙网络版
- 10python爬取网页的方法总结,python爬取网页数据步骤_遍历浏览器标签页程序
自然语言处理NLP:文本预处理Text Pre-Processing
赞
踩
大家好,自然语言处理(NLP)是计算机科学领域与人工智能领域中的一个重要方向,其研究能实现人与计算机之间用自然语言进行有效通信的各种理论和方法。本文将介绍文本预处理的本质、原理、应用等内容,助力自然语言处理和模型的生成使用。
1.文本预处理的本质
文本预处理是将原始文本数据转换为符合模型输入要求的格式的过程。在自然语言处理(NLP)中,文本预处理是一个基本且关键的步骤,因为它直接影响到模型的质量和性能。
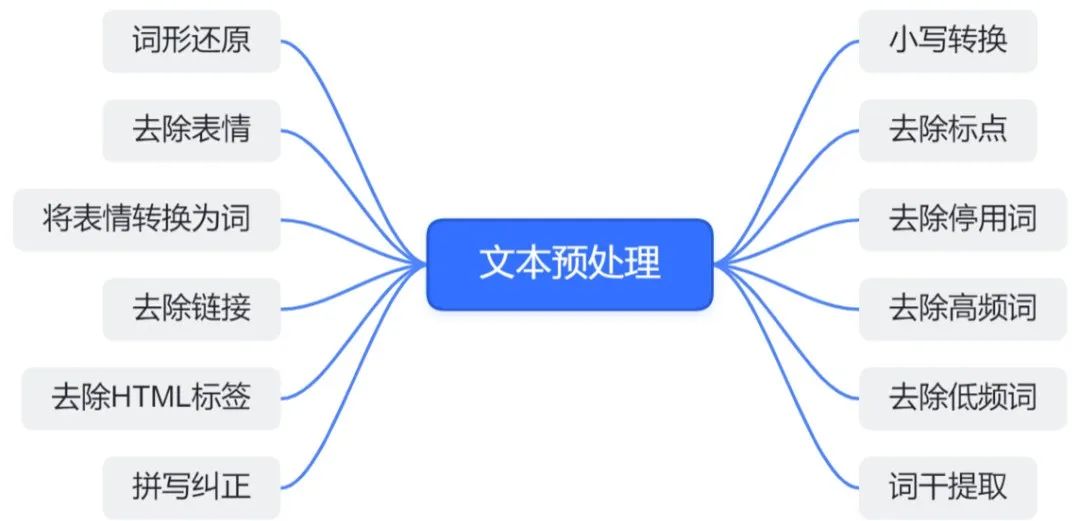
文本预处理涉及多个环节,主要包括数据清洗、文本标准化、分词、文本向量化等,旨在将原始、无结构化的文本数据转换为结构化的、数值化的形式,以便机器学习模型能够理解和处理。

文本预处理流程
- 数据清洗:
去除噪声,删除与文本分析任务无关的信息,如HTML标签、URL链接、特殊符号等。对缺失值进行处理,对于缺失或不完整的数据,可以选择填充(如使用特定标记、平均值或算法预测的值)或删除。同时,发现并纠正拼写错误、语法错误或其他文本错误。
- 文本标准化:
使用小写转换,将所有文本转换为小写,减少词汇的多样性。删除常见的但对文本意义贡献不大的词,如“的”、“是”、“在”等,这些词在大多数文本中频繁出现,但很少携带重要的语义信息。进行词干提取和词形还原,将单词简化为其基本形式(词干),或将屈折变化的词还原为原形(词形还原),进一步减少词汇的复杂性。
- 分词:
对于没有明显词边界的语言(如中文),将文本拆分成单个词语,分词算法可能基于规则、统计或深度学习。对于有空格分隔的语言(如英语、法语),虽然单词已经自然分开,但在处理缩写、复合词等可情况下能仍需要词语切分。
- 文本向量化:
进行特征提取,将文本转换为数值特征,以便机器学习模型能够处理。常见的方法包括词袋模型(Bag of Words)、TF-IDF(词频-逆文档频率)等。使用预训练的词嵌入模型(如Word2Vec、GloVe、FastText等)将单词转换为固定大小的向量,这些向量捕获了单词的语义信息。对于需要考虑词序的模型(如RNN、LSTM、Transformer),保持文本的序列信息很重要。这可以通过将文本转换为整数序列(每个整数代表一个单词在词汇表中的索引)来实现。
2.文本预处理的作用
文本预处理能将原始、无结构化的文本数据清洗、转换并标准化为适应机器学习模型输入的格式,从而提升模型性能并降低处理难度。
-
规范化文本数据:原始文本数据通常包含各种噪声,如拼写错误、无关字符、格式不一致等。通过预处理,可以清洗和标准化这些数据,去除噪声,使其更加规范、一致,便于后续处理。
-
降低处理难度:原始文本数据可能包含大量词汇和复杂语法结构,直接处理会很困难。预处理可以通过简化文本(如分词、去除停用词、词干提取等)来降低后续处理的难度。
-
提高模型性能:通过科学的文本预处理,可以更有效地指导模型超参数的选择,进而提升模型的评估指标和整体性能。
-
适应模型输入要求:不同的机器学习模型对输入数据有不同的要求。文本预处理可以将文本转换成模型所需的格式,如将文本转换为张量、规范张量的尺寸等。
3.文本预处理的原理
文本处理的基本方法包括分词、词性标注和命名实体识别。
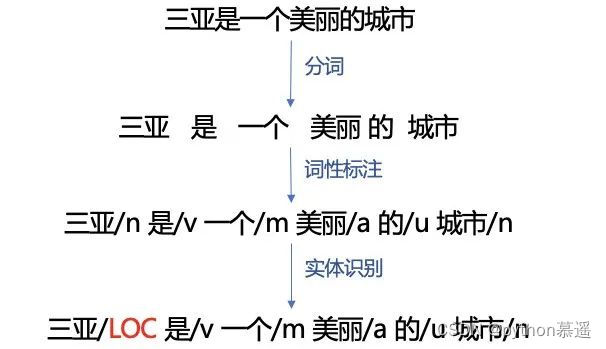
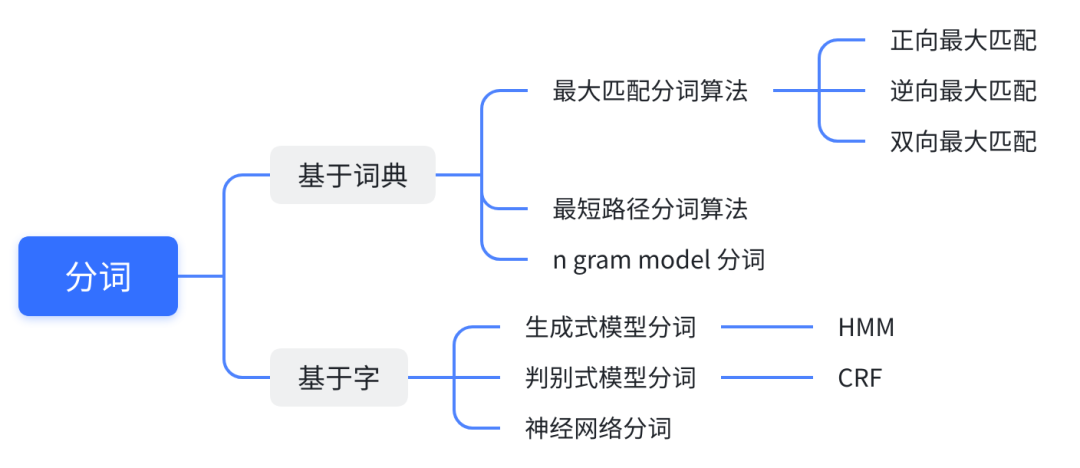
3.1 分词
分词是将连续的字序列按照特定的规则或算法重新组合成词序列的过程,有基于词典和字的两种分词方法。
对基于词典的分词方法,利用预先构建的分词词典,通过特定的算法(如逆向最大匹配、N-最短路径、N-Gram模型等)对句子进行切分。
对基于字的分词方法,利用各种机器学习算法对字序列进行状态标注。每个字在构造词时都有一个确定的状态(B(Begin)、E(End)、M(Middle)、S(Single)),通过对句子中的每个字赋予状态标签,完成分词。
3.2 词性标注
词性标注旨在为文本中的每个词分配其对应的词性标签。
基于统计模型的词性标注方法,其基本思想是将词性标注看作序列标注问题,利用统计模型确定给定词序列中每个词的最可能词性。常用模型有隐马尔可夫模型(HMM)、条件随机场(CRF)等,训练依赖于有标记数据的大型语料库,其中每个词都已正确标注词性。
基于深度学习的词性标注方法,一般的处理方法是将词性标注视为序列标注任务,常用模型有LSTM+CRF、BiLSTM+CRF等。深度学习模型能够自动学习文本中的复杂特征和模式,无需手动设计规则或特征。

3.3 命名实体识别
命名实体识别旨在从文本中识别出具有特定意义的实体,如人名、地名、组织名等,主要包含以下四种学习方法。
有监督的学习方法,依赖大规模的已标注语料库进行模型训练,常用模型有隐马尔可夫模型、语言模型、最大熵模型、支持向量机、决策树和条件随机场等。基于条件随机场的方法是命名实体识别中最成功的方法之一。
半监督的学习方法,其特点是利用少量标注的数据集(种子数据)进行自主学习。在标注资源有限的情况下,这种方法能够有效地利用未标注数据进行模型训练。
无监督的学习方法不依赖标注数据,而是利用词汇资源(如WordNet)等进行上下文聚类。由于缺乏明确的标注信息,无监督方法通常需要更复杂的算法和更多的计算资源来识别实体。
基于深度学习的方法常用模型有LSTM+CRF、BiLSTM+CRF等,将命名实体识别视为序列标注任务,利用深度学习模型自动学习文本中的复杂特征和模式。深度学习模型具有强大的表征学习能力,能够捕捉文本中的长期依赖关系和复杂模式,从而提高命名实体识别的性能。

4.文本预处理的应用
4.1 文本数据分析
文本数据分析能够有效帮助我们理解数据语料,快速检查出语料可能存在的问题,并指导之后模型训练过程中一些超参数的选择,有三种常用的文本数据分析方法。
-
标签数量分布:分析不同类别的样本数量,有助于发现类别不平衡问题,并制定相应的处理策略,如过采样或欠采样。
-
句子长度分布:统计句子长度的分布情况,可反映文本的复杂性和多样性,为模型输入和性能调优提供参考。
-
词频统计与关键词词云:统计词汇频率,识别主题和关键词,利用词云可视化展示高频词汇,有助于快速理解文本内容和后续任务处理。

词频统计与关键词词云
4.2 文本特征处理
文本特征处理通过为语料添加具有普适性的文本特征,并对加入特征后的文本进行必要的处理,可以有效地将重要的文本信息融入到模型训练中,从而提升模型的性能和评估指标。
n-gram算法通过捕捉文本中的连续词序列,为模型提供局部词序信息,增强文本处理能力。为确保模型输入文本长度的一致性,需要对原始文本进行截断或填充,以提高训练效率和模型性能。

