
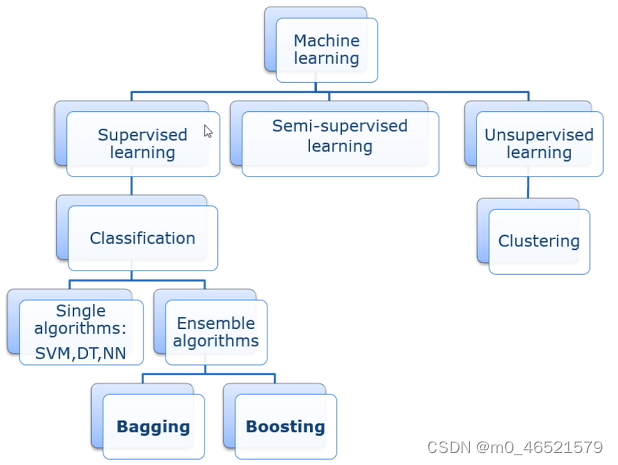
集成学习算法学习笔记
赞
踩
一、集成学习的基本思想
三个臭皮匠顶一个诸葛亮
集成学习会考虑多个评估器的建模结果,汇总后得到一个综合的结果,以此来获取比单个模型更好的回归或分类表现。
很多独立的机器学习算法:决策树、神经网络、支持向量机
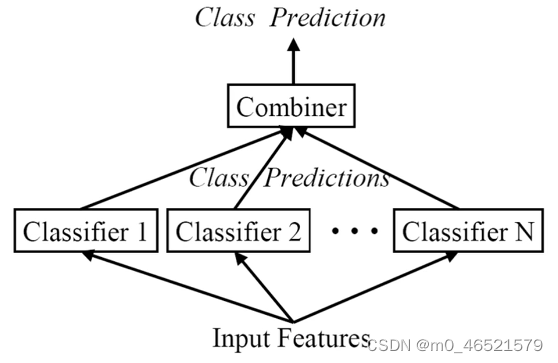
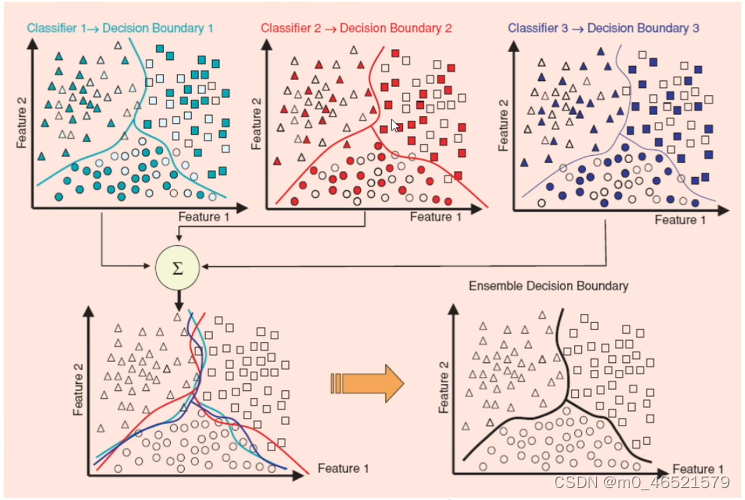
集成学习构建了一组基学习器,并将它们综合起来作为最终的模型。
在很多集成学习模型中,对基学习器的要求很低。
集成学习适用于机器学习的几乎所有领域:回归、分类、推荐和排序。
相同的多个基学习器不会带来任何提升,不同的模型取长补短,每个基学习器都会犯不同的错误,综合起来犯错的可能性不大。
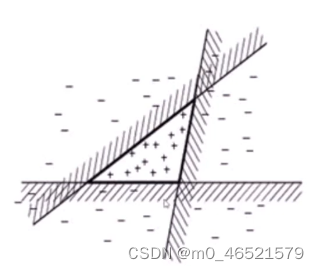
上述数据集中,每个线性模型都不能成功将该数据集分类,3个线性模型的简单综合可将该数据集成功分类。
如何构建不同的学习器?
(1)采用不同的学习算法
(2)采用相同的学习算法,但使用不同的参数
(3)不同的数据集:不同的样本子集,在每个数据集中使用不同的特征



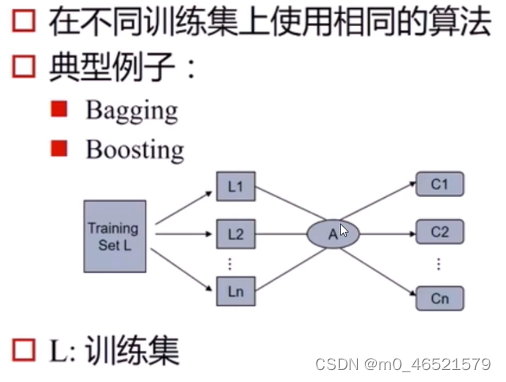
如何综合不同的基学习器?
(1)投票法(majority voting):每个基学习器具有相同的权重
(2)有权重的投票(weighted voting):可用不同的方法来确定权重
(3)训练一个新模型来确定如何综合:Stacking; 线性回归
主要的集成学习模式:
(1)Bagging:随机森林(random forest)
(2)Boosting:AdaBoost;Gradient Boosting Decision Tree
(3)Stacking
二、Bagging
boostrap aggregating 引导聚集算法
两个关键步骤:
(1)bootstrap取样
使用可重复取样从样本数为n的数据集中取出n个样本,假设每个样本被选中的概率是一样的
(2)模型综合


易于并计算
可以使用不在训练集Sj中的样本(out of bag sample, OOB)来估计基学习器的性能。
随机森林(Random Forests)

参数选择:
(1)决策数的数目m
(2)每个决策树的大小,由决策树叶节点所能包含的样本数的最大值决定
(3)每次选取最佳变量时随机选取的变量数d1
三、Boosting
boosting:提升
顺次建立一系列基学习器,后面的学习器分析当前已经建立的基学习器以更好的处理数据
(1)AdaBoost
(2)GBDT
基学习器的综合:一般使用有权重的线性组合;基学习器的权重一般由其性能决定



四、Stacking




