
- 14.3.2 Flink-流处理框架-Flink CDC数据实时数据同步-何为Flink CDC?_flink可以处理数据同步
- 2Python 爬虫代码,爬取淘宝网站上商品的评论_python爬取淘宝商品评论
- 3NLP 学习笔记 1:pytorch基础操作以及Perceptron 和 FF networks实现_perceptron pytorch
- 4毕业设计-基于大数据的房地产数据分析与预测-python_基于数据挖掘的房价预测分析
- 5【Linux驱动开发】011 gpio子系统
- 6在Vue中使用params方式传参导致参数丢失
- 7客户端和服务器不支持常用的SSL协议版本或密码套件_客户端和服务器不支持常用的 ssl 协议版本或密码套件。
- 8mysql连接数据库报错:1045 - Access denied for user ‘root‘@‘localhost‘ (using password:YES)_mysql1045 access denied
- 9opencv基础45-图像金字塔01-高斯金字塔cv2.pyrDown()
- 10分布式资源调度管理框架:YARN的架构及工作原理_yarn联邦配置
大语言模型入门介绍(附赠书)
赞
踩
自2022年底ChatGPT的震撼上线以来,大语言模型技术迅速在学术界和工业界引起了广泛关注,标志着人工智能技术的又一次重要跃进。作为当前人工智能领域的前沿技术之一,代表了机器学习模型在规模和复杂性上的显著进步。它们通常由深度神经网络构成,拥有大量参数(数十亿到数千亿)的机器学习模型,这些模型的设计和训练过程非常复杂,需要处理和学习海量数据,以期达到高级的认知和预测能力。大模型在自然语言处理(NLP)、计算机视觉(CV)、语音识别和推荐系统等多个领域都有广泛的应用。
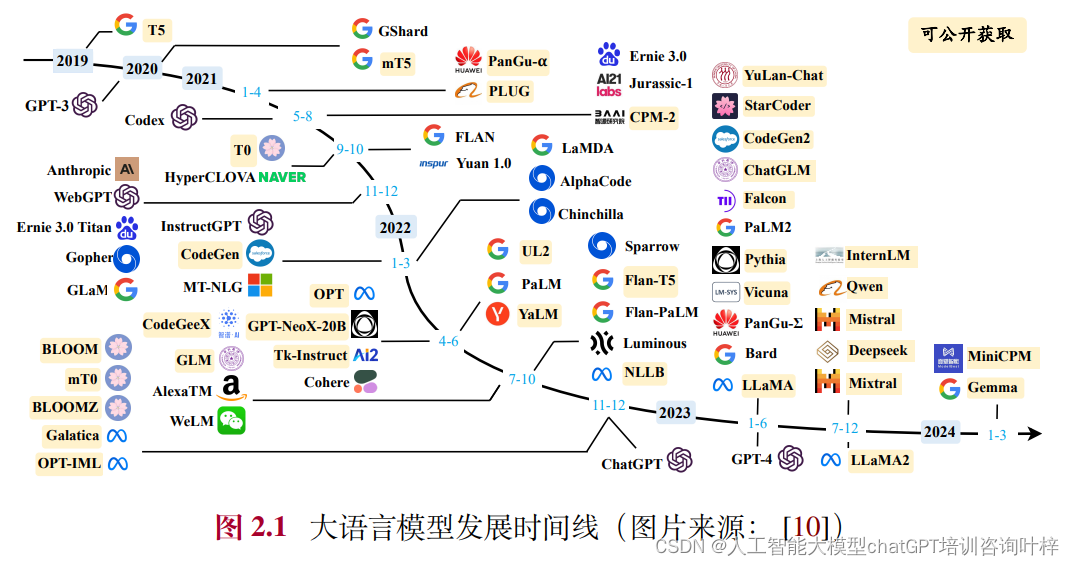
大语言模型的构建过程涉及多个关键步骤,旨在使模型能够理解和生成类似于人类的语言。构建大语言模型的一般流程如下:
-
设计架构:
- 大语言模型通常基于Transformer架构,这是一种专门为处理序列数据而设计的注意力机制模型。Transformer能够有效捕捉词与词之间的关系,无论它们在句子中的距离有多远。
-
预训练任务的选择:
- 预训练是构建大语言模型的关键步骤,涉及让模型在大量文本上学习语言的通用规律。常见的预训练任务包括掩码语言建模(Masked Language Modeling, MLM)和下一句预测(Next Sentence Prediction, NSP)。
-
数据收集与处理:
- 需要大量的文本数据来训练大语言模型,这些数据可能来自书籍、文章、对话等。数据需要经过清洗,去除噪声和不相关信息,同时进行分词处理,将文本转换为模型可以理解的格式。
-
模型训练:
- 使用预训练数据,通过迭代优化算法调整模型的参数。训练过程中,模型学习预测掩码部分的词(MLM任务),或判断两个句子是否连续(NSP任务)。这个过程需要大量的计算资源。
-
微调(Fine-tuning):
- 预训练完成后,大语言模型通常在特定任务上进行微调。这涉及在小规模的、有标签的数据集上进一步训练模型,使其更适应特定的应用场景。
-
评估与测试:
- 在模型训练和微调的每个阶段,都需要对模型的性能进行评估。这通常通过在独立的测试集上进行,以确保模型的泛化能力。
-
部署与应用:
- 经过充分的训练和测试,大语言模型可以部署到实际应用中,如聊天机器人、文本生成、语言翻译、内容推荐等。
-
持续迭代:
- 即使在部署后,大语言模型的构建过程也不是一成不变的。随着时间的推移,可能需要根据新的数据和反馈对模型进行更新和优化。
构建大语言模型是一个复杂的过程,涉及先进的机器学习技术、大量的数据和计算资源,以及对模型性能和伦理问题的深思熟虑。大模型的核心技术主要围绕以下几个关键领域:
-
深度学习框架:大模型依赖于先进的深度学习框架,如Tensorflow和PyTorch,这些框架提供了必要的工具和库来构建、训练和部署复杂的神经网络模型。
-
Transformer架构:这种架构通过自注意力机制,允许模型在处理序列数据时更有效地捕捉长距离依赖关系,极大地提升了模型的序列建模能力。
-
预训练和微调:大模型通常在大规模的数据集上进行预训练,学习通用的特征和模式,然后针对特定任务进行微调,以适应不同的应用场景。
-
多模态学习:一些大模型能够处理并整合来自不同模态(如文本、图像、声音)的信息,这要求模型具备跨模态的理解和生成能力。
-
自编码器和自回归模型:自编码器模型如BERT专注于理解语言,而自回归模型如GPT专注于生成文本。每种模型都有其特定的应用场景。
-
编码器-解码器架构:某些大模型采用编码器-解码器架构,适合于需要将一种类型的输入序列转换为另一种类型的输出序列的任务。
-
优化算法:为了有效训练具有数亿甚至数万亿参数的大模型,需要高效的优化算法,如随机梯度下降(SGD)及其变种。
-
硬件加速:大模型的训练和推理需要强大的计算资源,包括GPU、TPU等专用硬件加速器。
-
数据并行和分布式训练:为了处理海量数据和复杂模型,大模型的训练常常采用数据并行和模型并行技术,以及分布式训练策略。
-
模型压缩和加速:研究如何减少模型的大小和计算需求,使其能够在资源受限的设备上运行,包括量化、剪枝和知识蒸馏等技术。
-
模型可解释性:提高模型的透明度和可解释性,帮助用户理解模型的决策过程。
-
安全性和隐私保护:确保大模型的训练和应用过程中的数据安全和隐私保护。
关于大语言模型最新最全的介绍可以从近期赵鑫 李军毅 周昆 唐天一 文继荣《大语言模型》中了解,本书旨在深入探讨大语言模型的核心技术、发展历程以及其在现代社会中的广泛应用。从大语言模型的构建过程入手,详细阐述了自统计语言模型以来的多个发展阶段,并特别强调了OpenAI在这一领域的贡献,尤其是GPT系列模型的创新和影响。 在本书中,不仅回顾了大语言模型的早期探索,还深入分析了模型架构的可拓展性、数据质量与规模的重要性,以及这些因素如何共同塑造了大模型的性能。
可收藏+关注后私信小助理获得完整电子版《大语言模型》

